October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 10, 2026

Blazingly fast way to build, track and deploy your models!
Anthropic launched Claude Fable 5 on June 9, 2026 - its most capable generally available model to date, and the first "Mythos-class" model offered to the public. Starting today, you can call Fable 5 through the TrueFoundry AI Gateway using the same unified, OpenAI-compatible API you already use for every other model - with full governance, cost controls, and automatic fallbacks built in.
No new SDK. No separate integration. Point your existing requests at your TrueFoundry gateway and set the model to Claude Fable 5.
Try Claude Fable 5 on the TrueFoundry AI Gateway →
Fable 5 sits a tier above Anthropic's Opus class. It's built for ambitious, long-running, asynchronous work — large code migrations, multi-day agentic sessions, deep analytical research - the kind of tasks where models previously lost the thread. A few headline facts from Anthropic's launch:
Calling a brand-new frontier model directly is easy - until you need to run it in production across a team. That's where a gateway earns its place:
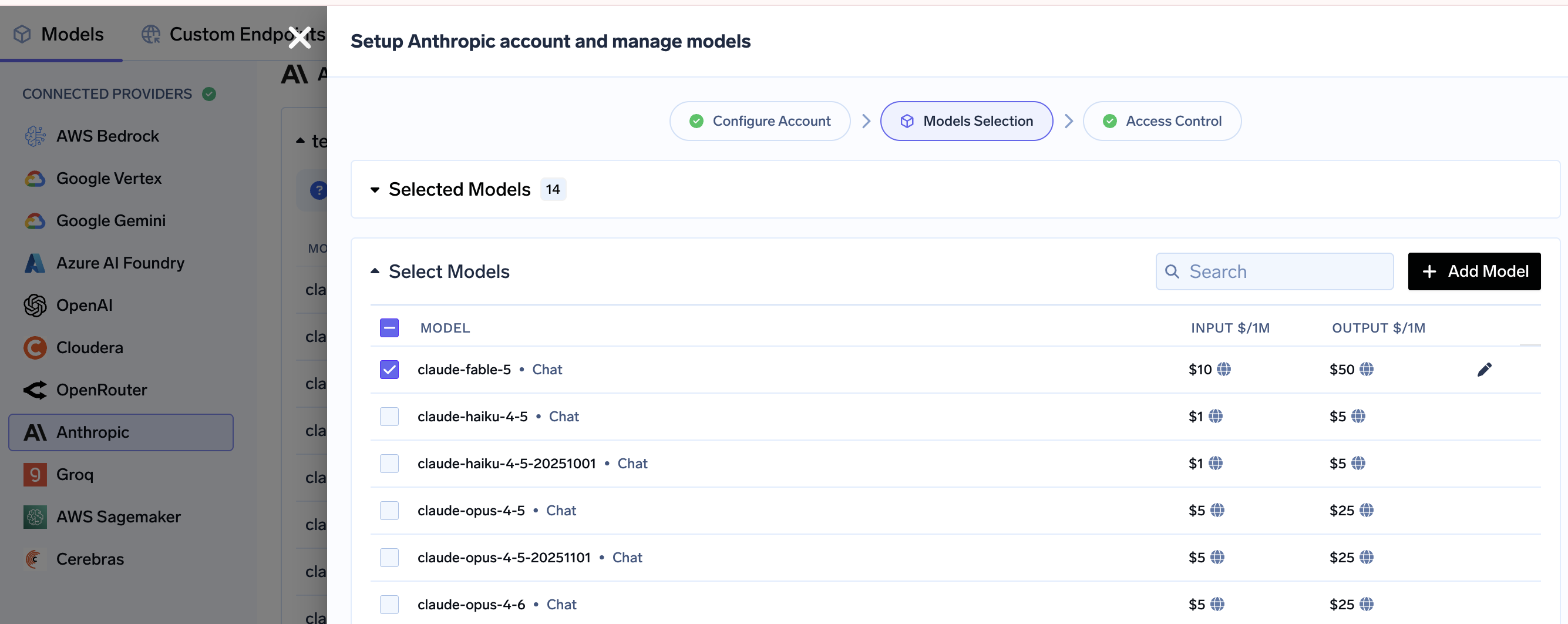
In the TrueFoundry AI Gateway, open your connected Anthropic provider under Models → Setup Anthropic account and manage models. The setup walks through three steps — Configure Account → Models Selection → Access Control. On the Models Selection screen, search for claude-fable-5 and check it (you'll see it listed at $10 input / $50 output per 1M tokens, alongside the rest of the Claude lineup like claude-opus-4-6, claude-opus-4-5, and claude-haiku-4-5). Then use Access Control to decide which teams and virtual keys can use it — so a premium model like Fable 5 is governed from the moment it goes live.
Open the Playground, pick claude-fable-5, and grab the ready-made Usage code snippet - TrueFoundry generates it for OpenAI, LangChain, Node.js, cURL, LlamaIndex, CrewAI, Pydantic AI, and more, in both streaming and non-streaming modes. The OpenAI Python version looks like this:
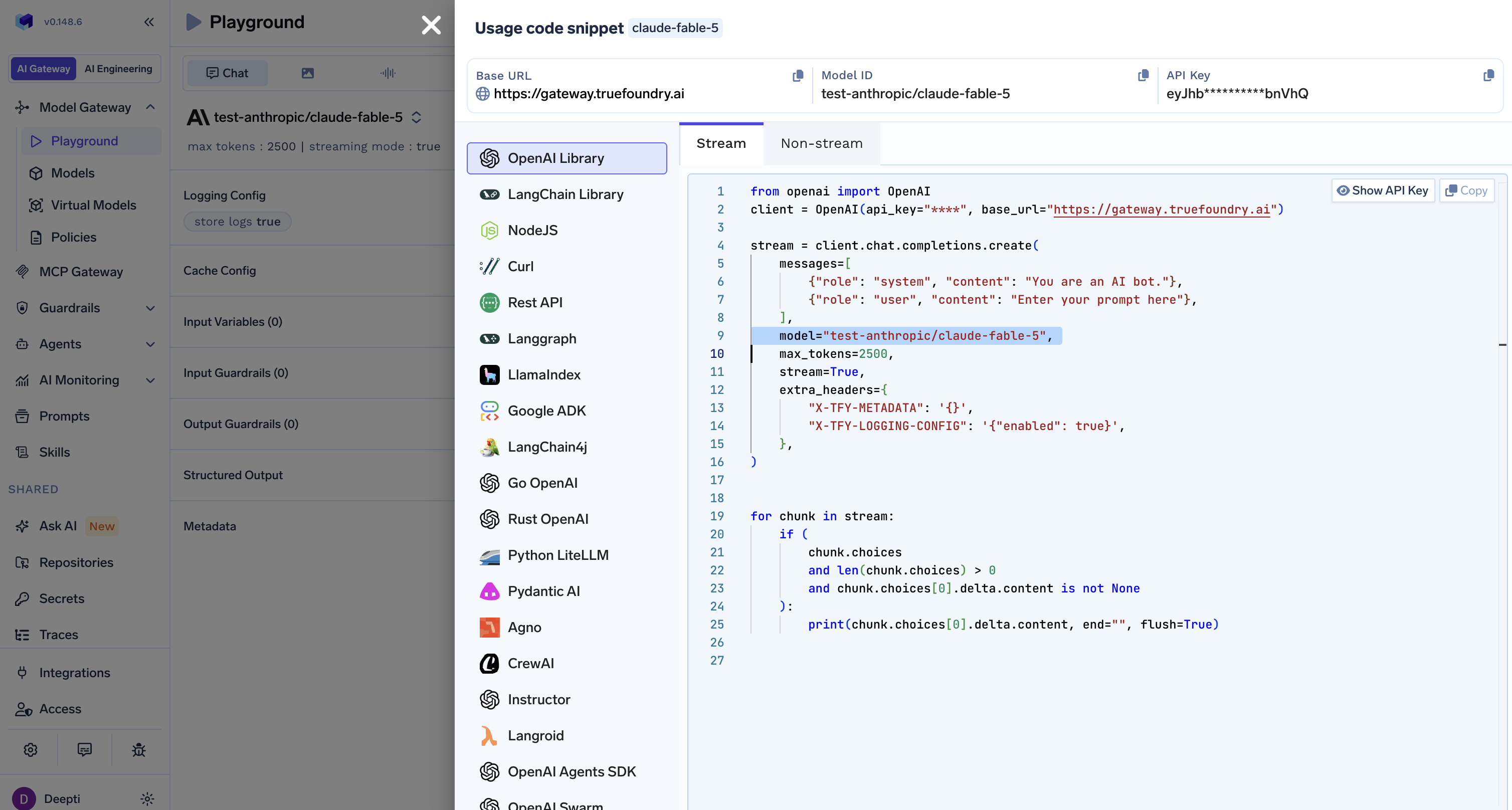
A few things worth noticing in that snippet — and why the gateway is doing more than proxying a request:
https://gateway.truefoundry.ai. Every model you've enabled is reachable from this one endpoint.test-anthropic/claude-fable-5 (<your-provider-account>/<model>). Swap to test-anthropic/claude-opus-4-6 and you've switched models with a one-line change; everything else stays identical.X-TFY-LOGGING-CONFIG turns on request logging and X-TFY-METADATA lets you tag each call (team, feature, environment) so spend and usage are attributable per request.client.chat.completions.create — drop it into any existing OpenAI-compatible codebase as-is.From here you can layer on caching, guardrails, and fallback policies from the same gateway dashboard — without touching your application code.
Fable 5 is the model you reach for when the task is too big, too long, or too complex for anything else. Run it through TrueFoundry and you get frontier capability with production-grade control from the first request.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada



.webp)