




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
Blazingly fast way to build, track and deploy your models!
Na nossa série de blogs sobre Kubernetes, falámos sobre a construção de MLOps escalável no Kubernetes, arquitetura para MLOps, e resolução de problemas de desenvolvimento de aplicações. Neste blog, falaremos sobre como hospedar um serviço GRPC em um cluster AWS EKS. O processo será aproximadamente o mesmo para todos os clusters Kubernetes — no entanto, tivemos que fazer algumas configurações específicas no balanceador de carga da AWS para que isso funcionasse.
gRPC é um framework RPC de código aberto que pode ser executado em qualquer ambiente. É capaz de conectar serviços de forma eficiente dentro e entre data centers, com a capacidade de integrar suporte para balanceamento de carga, rastreamento, verificação de saúde e autenticação.
O nosso caso de uso: Hospedar modelos Tensorflow como APIs que aceitavam um payload de cerca de 100MB. O GRPC tem um desempenho muito melhor para payloads maiores — por isso, expusemos a porta GRPC na porta 5000.
Hospedamos o serviço no Kubernetes usando o YAML de Implantação abaixo:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ml-api
namespace: ml-services
spec:
replicas: 1
selector:
matchLabels:
truefoundry.com/component: ml-api
template:
metadata:
labels:
truefoundry.com/application: ml-api
spec:
containers:
- name: ml-api
image: >-
XXXX.dkr.ecr.us-east-1.amazonaws.com/ml-services-ml-api:latest
ports:
- name: port-8500
containerPort: 8500
protocol: TCP
resources:
limits:
cpu: '4'
ephemeral-storage: 2G
memory: 4G
requests:
cpu: '1'
ephemeral-storage: 1G
memory: 500M
imagePullPolicy: IfNotPresent
restartPolicy: Always
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
securityContext: {}
imagePullSecrets:
- name: ml-api-image-pull-secret
schedulerName: default-scheduler
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 0
Isso iniciará o pod. Precisamos criar o objeto Service usando o YAML abaixo:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
labels:
argocd.argoproj.io/instance: tfy-istio-ingress
name: tfy-wildcard
namespace: istio-system
spec:
selector:
istio: tfy-istio-ingress
servers:
- hosts:
- 'ml.example.com'
port:
name: http-tfy-wildcard
number: 80
protocol: HTTP
tls:
httpsRedirect: true
- hosts:
- 'ml.example.com'
port:
name: https-tfy-wildcard
number: 443
protocol: HTTP
Estamos usando o Istio como camada de ingresso no Kubernetes. O Istio provisiona um Load Balancer quando o istio-ingress é instalado. A configuração do balanceador de carga pode ser personalizada usando anotações no gateway do Istio. A especificação para criar o Gateway do Istio é a seguinte:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
labels:
argocd.argoproj.io/instance: tfy-istio-ingress
name: tfy-wildcard
namespace: istio-system
spec:
selector:
istio: tfy-istio-ingress
servers:
- hosts:
- 'ml.example.com'
porta:
nome: http-tfy-wildcard
número: 80
protocolo: HTTP
tls:
redirecionamentoHttps: true
- hosts:
- 'ml.example.com'
porta:
nome: https-tfy-wildcard
número: 443
protocolo: HTTP
Estamos realizando a terminação SSL no Balanceador de Carga AWS. Para isso, precisamos anexar o certificado ao Balanceador de Carga. Isso pode ser alcançado usando as anotações abaixo no gráfico do gateway istio (https://istio-release.storage.googleapis.com/charts).
"service.beta.kubernetes.io/aws-load-balancer-type": "nlb"
"service.beta.kubernetes.io/aws-load-balancer-backend-protocol": "tcp"
"service.beta.kubernetes.io/aws-load-balancer-ssl-cert": "<certificate-arn>"
"service.beta.kubernetes.io/aws-load-balancer-ssl-ports": "https"
"service.beta.kubernetes.io/aws-load-balancer-alpn-policy": "HTTP2Preferred"
A política ALPN é importante para especificar e permitir o tráfego GRPC. Nosso serviço ml-api pode ser exposto criando um VirtualService que aponta para o serviço Kubernetes. O YAML para o Virtual Service é o seguinte:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
labels:
argocd.argoproj.io/instance: ml-services_ml-api
name: ml-apiport-8500-vs
namespace: ml-services
spec:
gateways:
- istio-system/tfy-wildcard
hosts:
- ml.example.com
http:
- route:
- destination:
host: ml-api
port:
number: 8500
Uma vez que o serviço virtual é exposto, podemos fazer requisições ao nosso serviço em ml.example.com. Em seguida, queríamos adicionar uma autenticação à API para que nem todos pudessem chamá-la. Poderíamos ter adicionado a autenticação no código, mas decidimos adicioná-la na camada do Istio para que pudesse ser uma camada unificada em todos os serviços.
Para adicionar autenticação na camada istio-ingress, decidimos prosseguir com um Plugin IstioWasm. O YAML para o plugin é algo como:
apiVersion: extensions.istio.io/v1alpha1
kind: WasmPlugin
metadata:
name: ml-services-ml-api-0
namespace: istio-system
spec:
phase: AUTHN
pluginConfig:
basic_auth_rules:
- credentials:
- username:password
hosts:
- ml.example.com
prefix: /
request_methods:
- GET
- PUT
- POST
- PATCH
- DELETE
seletor:
rótulosCorrespondentes:
istio: tfy-istio-ingress
url: oci://ghcr.io/istio-ecosystem/wasm-extensions/basic_auth:1.12.0
Depois de aplicar a especificação acima ao cluster, o aplicativo solicitará o nome de usuário e a senha assim que você o abrir no navegador.
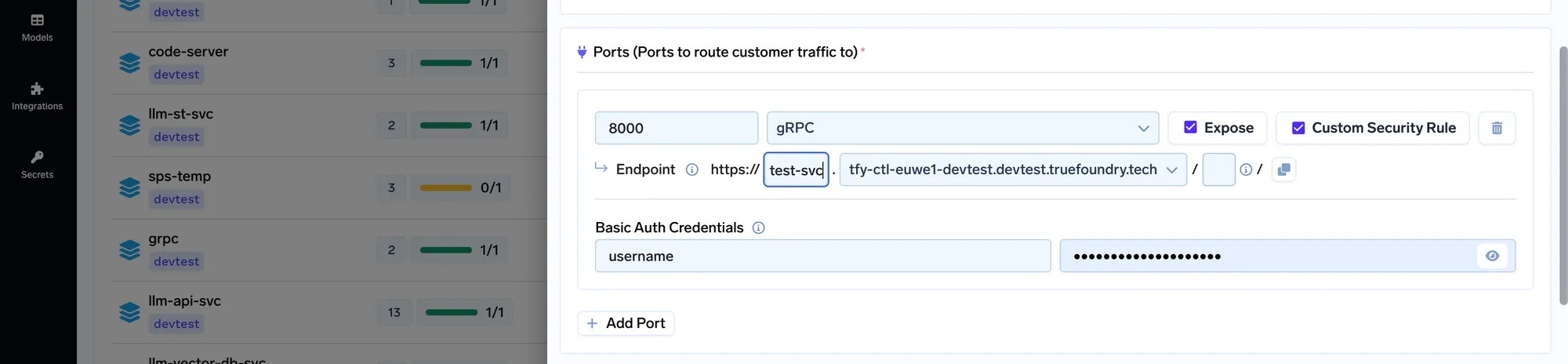
Para tornar o processo acima muito mais fácil, decidimos simplificá-lo bastante na Truefoundry plataforma.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




