



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
No início dos anos 2010, a revolução dos microsserviços atingiu um obstáculo. Tínhamos quebrado nossos monólitos em centenas de serviços, mas não havíamos chegado a um acordo sobre como eles deveriam se comunicar. Algumas equipes usavam REST, outras XML-RPC, outras TCP puro. O resultado foi uma "Torre de Babel"—um ecossistema fragmentado onde a integração era dolorosa e a observabilidade, impossível.
A indústria resolveu isso com a padronização: gRPC para o transporte, Protobuf para o esquema, e OpenTelemetry para a observabilidade.
Hoje, o IA Agente ecossistema está exatamente nesse caos pré-padronização.
Estes agentes não conseguem colaborar naturalmente. Têm diferentes representações de estado, diferentes mecanismos de tratamento de erros e nenhum conceito de identidade partilhado.
Para resolver isto, a TrueFoundry introduz o suporte para Protocolo A2A (Agente-para-Agente). É uma camada de transporte rigorosa que normaliza a comunicação, transformando uma coleção fragmentada de scripts numa Malha Cognitiva.
O erro fundamental em muitos designs iniciais de agentes é tratar a comunicação agente-para-agente como uma simples chamada de API (POST /chat { "prompt": "..." }). Isto é insuficiente porque carece de Metacognição.
Um agente não precisa apenas do texto da mensagem. Precisa de saber:
O Protocolo A2A resolve isso encapsulando cada interação em um formato padronizado Envelope. Tratamos a lógica de negócios do agente (o prompt) como a Carga Útil, mas o encapsulamos em um rígido Plano de Controle.
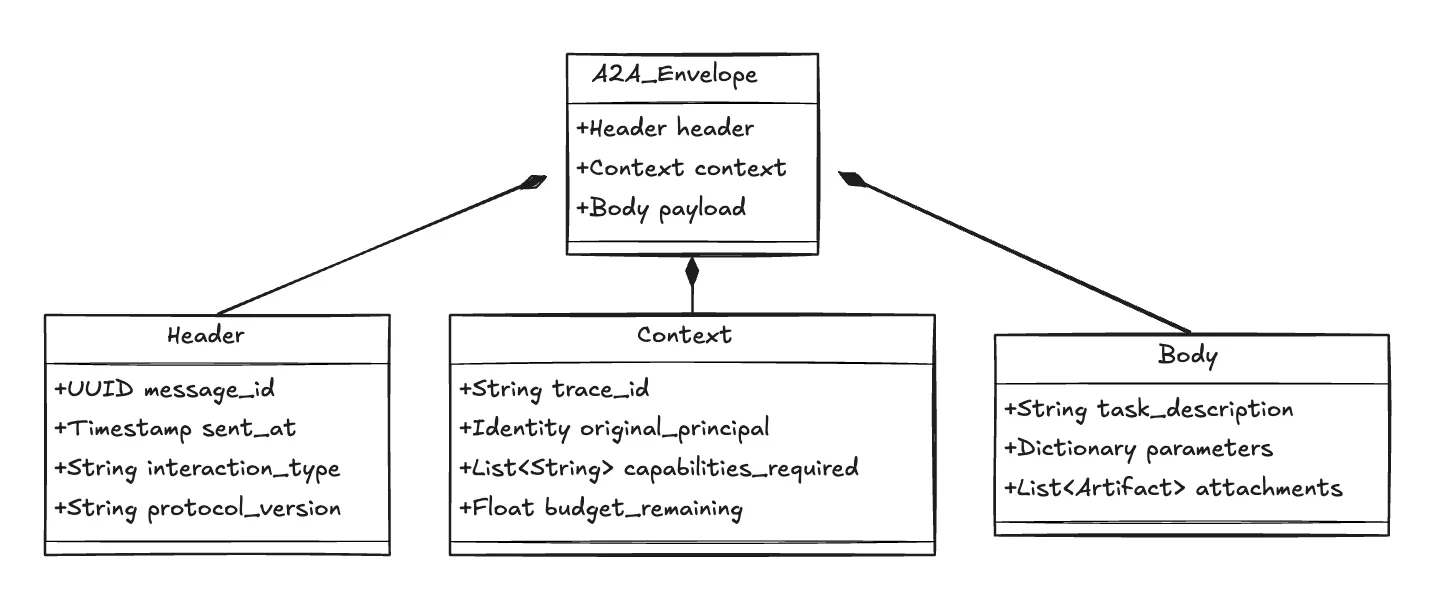
Fig 1: O Envelope A2A e sua Estrutura Subjacente
Leia também: MCP vs A2A
Para ilustrar o poder deste protocolo, vamos analisar um cenário complexo e multi-stack: Um Sistema de Due Diligence de F&A.
Este sistema requer três agentes altamente especializados, executando em pilhas de tecnologia completamente diferentes:
Sem um protocolo, o Python Manager não consegue acionar facilmente a equipe AutoGen. O AutoGen espera um formato específico de histórico de conversação, enquanto o LangChain espera uma "Chain". Se o Revisor Jurídico (Node) lançar um erro, o Python Manager pode interpretá-lo como uma alucinação em vez de uma falha do sistema.
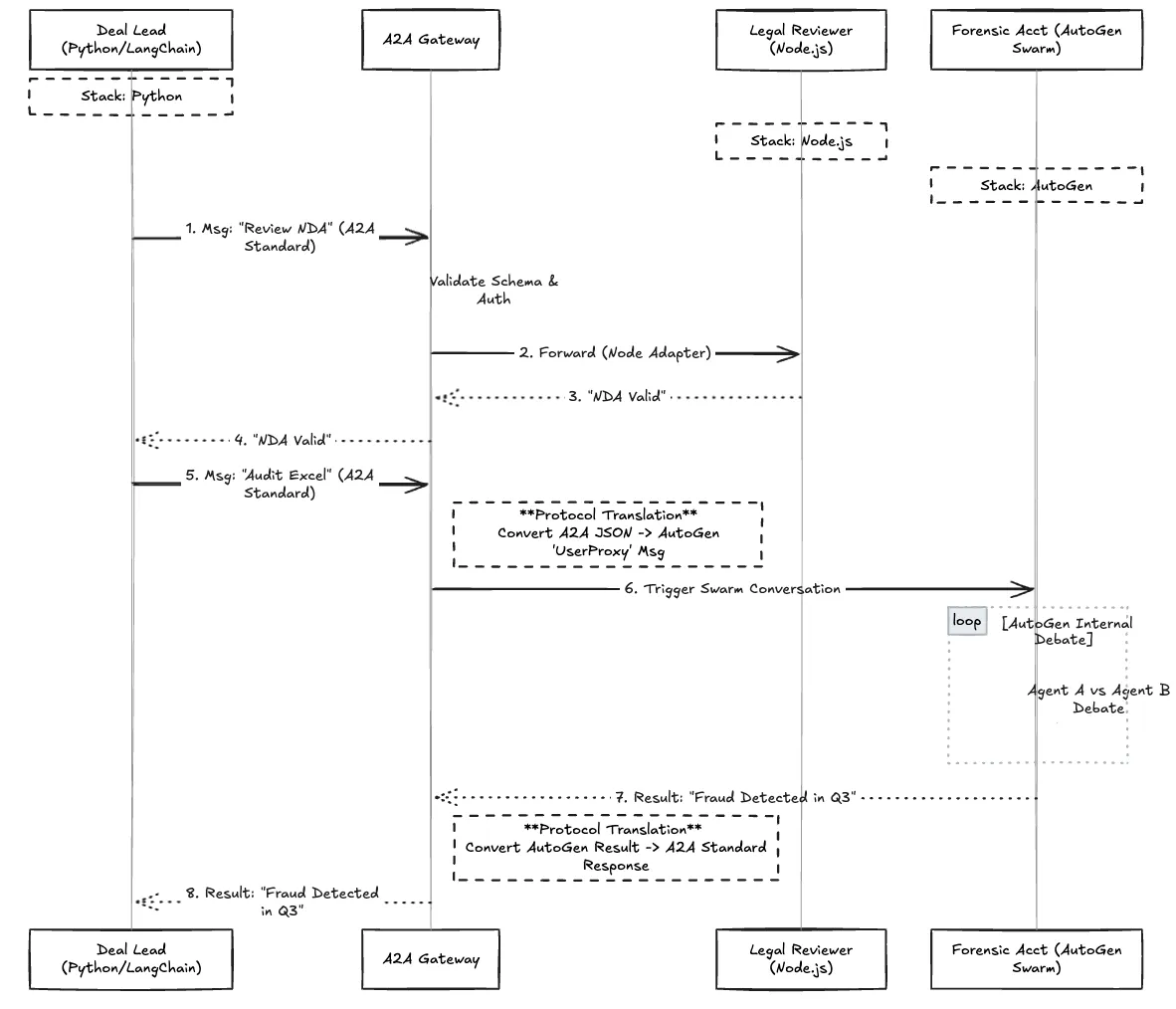
Fig. 2: O Fluxo Detalhado de um Processo de Revisão Legal
Numa malha de agentes peer-to-peer, o Agente A chama o Agente B diretamente. Isto é perigoso porque compromete a observabilidade e a segurança. Se o Agente A for comprometido, pode inundar o Agente B com pedidos, e ninguém saberá até que a fatura chegue.
O Protocolo A2A impõe um Hub-and-Spoke modelo.

Depurar um único LLM é difícil. Depurar uma cadeia recursiva de 5 agentes é impossível sem rastreamento distribuído.
Quando o "Líder de Negócios" não consegue fechar o negócio de M&A, você precisa saber o porquê. Foi um tempo limite no agente Jurídico? O Contador Forense ficou sem tokens?
O Protocolo A2A exige Propagação de Cabeçalhos. Quando o Gateway recebe a requisição inicial, ele gera um TraceID. Ele força cada agente a jusante a incluir este ID em suas subchamadas.
Isso nos permite visualizar a "Pilha de Pensamento"—um gráfico de Gantt temporal da cognição. Podemos ver que o Agente Jurídico levou 45 segundos (gargalo de latência) enquanto o Contador levou 2 segundos.

Fig. 3: Gráfico de Gantt deste Negócio de M&A
A peça final do Protocolo A2A é o Adaptador Universal.
Reconhecemos que os desenvolvedores sempre usarão ferramentas diferentes. Alguns adoram o LangGraph pelo seu controle; outros preferem o CrewAI pelas suas funcionalidades de interpretação de papéis.
O Gateway atua como uma Camada de Tradução.
Isso permite que você construa uma Malha de Agentes Heterogêneos. Você não está preso a uma única biblioteca Python. Você pode escolher a melhor ferramenta para o trabalho de cada agente específico e deixar que o Protocolo lide com a comunicação.
A padronização é o pré-requisito para a escala. Assim como o TCP/IP permitiu que a internet conectasse diferentes computadores, o Protocolo A2A mais as capacidades de IA da TrueFoundry de gateway de agente permitem que a empresa conecte diferentes inteligências. Ele transforma uma coleção de "Chatbots" em uma coordenada, observável e segura Força de Trabalho Digital.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.







.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




