













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
単一のモデルがすべてのタスクで優れているわけではありません。GPT-4oは複雑な推論をうまく処理しますが、より小さな言語モデルは、分類、ルーティング、抽出をより低コストで処理することがよくあります。すべてのリクエストを最も高価なモデルにルーティングすると、不必要な費用が発生し、本番AIチーム全体のリソース配分が弱まります。
マルチモデルオーケストレーションは、この区別を実用化します。すべてのワークロードを単一のプロバイダーに固定するのではなく、タスクの種類、コスト、レイテンシー、品質要件に基づいて、異なるモデルにリクエストをルーティングします。本番チームにとって、これはもはや狭い最適化ではありません。これはエンタープライズAIの運用レイヤーになりつつあります。
企業は現在、OpenAI、Anthropic、Google、Azure、AWS Bedrock、および自己ホスト型モデル全体でAIアプリケーションを実行しています。マルチLLMオーケストレーションは、有用なルーティングパターンからコアインフラストラクチャ要件へと移行しました。このガイドでは、その仕組み、それ自体では解決できないこと、そしてTrueFoundryがエンタープライズゲートウェイレイヤーを介してガバナンスを追加する方法について説明します。
マルチモデルオーケストレーションとは、アプリケーション、単一のAIエージェント、またはワークフローを複数のAIモデルに接続する実践です。オーケストレーションレイヤーは、特定のタスク、コスト目標、レイテンシー要件、または品質しきい値に最も適したモデルに各リクエストをルーティングします。
この用語は、静的ルーティングと動的ルーティングの両方をカバーしています。静的ルーティングは、異なるタスクを事前定義されたモデルに割り当てます。要約はコスト効率の良いモデルに、コード補完はコーディングモデルに、詳細な調査はより強力な推論モデルに送ることができます。
動的ルーティング は、実行時にユーザー入力を評価します。オーケストレーションエンジンは、ディスパッチ前に複雑さ、プロバイダーの健全性、レイテンシー、コスト、および利用可能なルーティングポリシーを検査できます。ほとんどの実際のシステムでは、速度、品質、回復力、コストのバランスを取るために両方のアプローチを使用します。
どちらの場合も、中央のオーケストレーターは、アプリケーションと基盤となるモデルの間に位置します。プロバイダー固有のAPIを抽象化し、ルーティングを処理し、応答を正規化し、フェイルオーバーを管理します。アプリケーションは単一のエントリポイントを持ち、ゲートウェイがモデルの選択とプロバイダーの動作を管理します。
マルチモデルオーケストレーションが不可欠になったのは、AIワークロードが現在、コスト、リスク、複雑さ、レイテンシーによって大きく異なるためです。簡単な顧客の問い合わせに答えるチャットボットは、規制された決定や複雑なコード生成を処理するエージェントと同じモデルを必要としません。
フロンティアモデルは、推論の品質と幅広さを最適化します。より小さな言語モデルは、明確に定義されたタスクにおいて速度とコストを最適化します。すべてのワークロードを1つの層に固定すると、両端で真の価値が未実現のままになります。
デフォルトですべてのトラフィックをフラッグシップの大規模言語モデルにルーティングすると、多くのリクエストで過払いが発生します。より小さなモデルは、多くの日常的なプロンプトに同じ精度で、より速い応答時間で答えることができます。その逆は別の問題を引き起こします。なぜなら、より安価なモデルに標準化すると、本当に難しいプロンプトに対して浅い、または不正確な応答が返される可能性があるからです。
明確な要因なしに支出グラフが上昇するのを見たことがあるなら、その原因はしばしば単純です。1つのデフォルトモデル、1つのルーティングルール、そしてより簡単な作業をより安価な場所に送る方法がないこと。マルチモデルオーケストレーションは、各特定のタスクを適切なモデルに一致させるため、構造的な解決策となります。
LLM APIプロバイダーは、本番アプリケーションに直接影響を与える停止、レート制限、およびパフォーマンスの低下を経験します。TrueFoundry自身のゲートウェイドキュメントは、2025年2月から5月までのOpenAIとAnthropicのステータスページを引用しており、4か月にわたる繰り返しのインシデントを示しています。
それはエッジケースではありません。それは本番の生成AIシステムの運用環境です。
マルチモデルオーケストレーションは、自動フェイルオーバーにより、プライマリエンドポイントが劣化した場合に本番ワークロードを稼働中のプロバイダーにルーティングします。これにより、人手による介入やオンコールエンジニアによる緊急の変更なしに、アプリケーションの可用性が維持されます。このパターンは、他の重要な依存関係と同様に、冗長性、ヘルスチェック、自動フォールバックに基づいています。
規制対象企業は、すべてのリクエストをすべてのモデルに送信できるわけではありません。一部のワークロードには、機密データ、機密情報、顧客記録、または地域的なデータ制限が関わります。このような場合、ルーティングの決定は、コストやレイテンシだけでなく、ポリシー規則も考慮する必要があります。
ガバナンスされた制御レイヤーは、メタデータ、地理、チーム、環境、またはデータクラスに基づいてリクエストをルーティングできます。これは、外部データ、プライベートデータセット、または制限されたワークフローが承認された境界内に留まる必要がある場合に重要です。
TrueFoundryの場合、ターゲットにmetadata_matchルールをアタッチすることで、リクエストメタデータ(またはゲートウェイ独自のtfy_gateway_regionタグ)が設定された値と一致する場合にのみトラフィックを受信するようにできます。明示的にマッピングされていないすべてのリージョンに対しては、キャッチオールターゲットが用意されています。
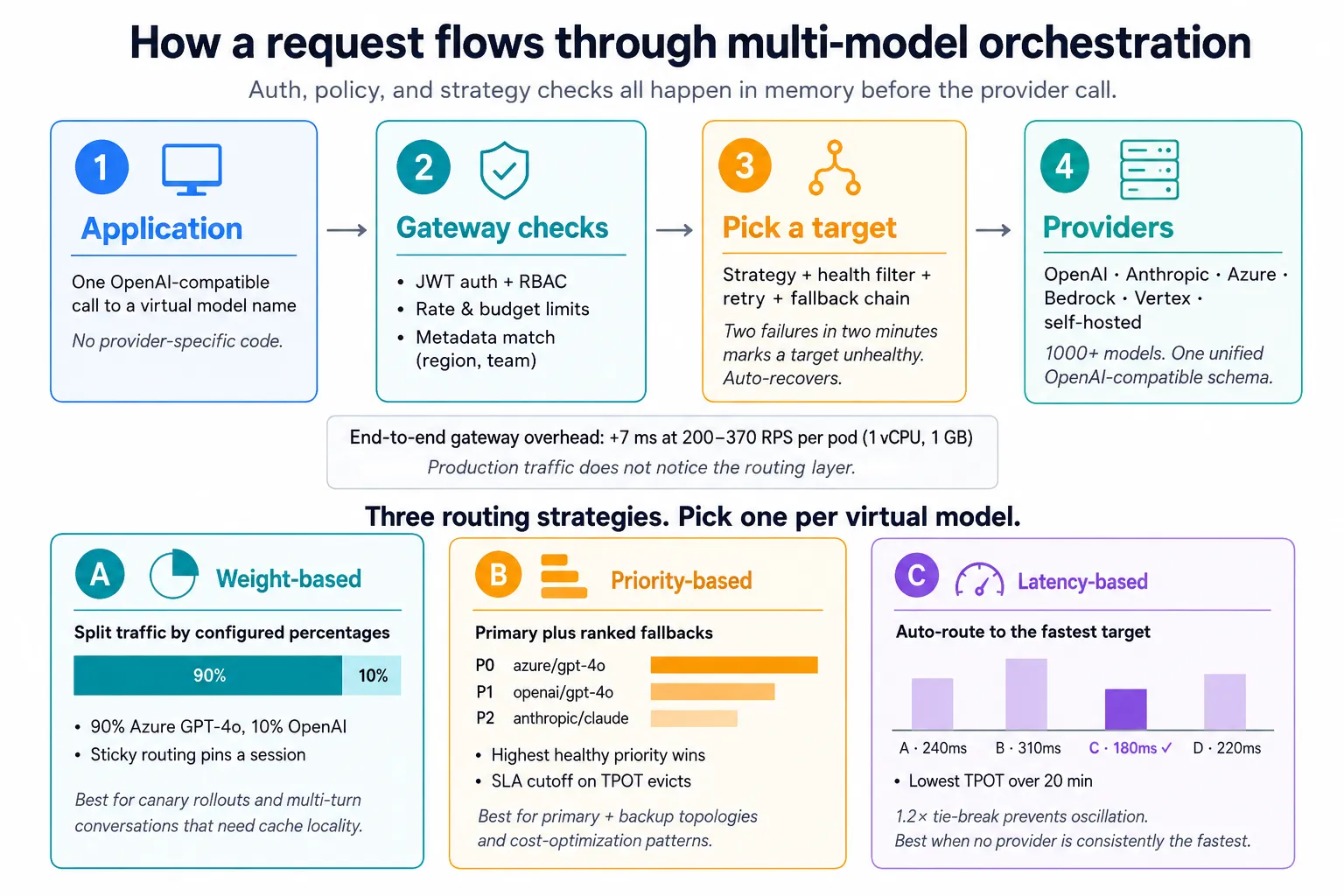
マルチモデルオーケストレーションは通常、統合APIレイヤー、ルーティングロジック、フェイルオーバーチェーン、レスポンス正規化という4つの主要コンポーネントに依存しています。これらを組み合わせることで、チームはアプリケーションコード内にすべての統合をハードコーディングすることなく、複数のプロバイダーを利用できます。
各プロバイダーは、異なるリクエスト形式、パラメータ名、エラーコード、およびレスポンス構造を使用します。AIオーケストレーションフレームワークは、これらの違いを単一のAPIの背後で正規化します。これにより、アプリケーションはホスト型、オープンソース、およびセルフホスト型モデル全体で一貫したインターフェースを得ることができます。
TrueFoundryの LLMゲートウェイ は、1,000以上のモデルでOpenAI互換のスキーマを公開しています。これにより、チームはすべてのダウンストリームサービスを変更することなく、プロバイダーを追加または交換できます。また、チーム間のプロンプトエンジニアリング、テスト、ロールアウト管理も簡素化されます。
この統合APIレイヤーは、開発者とプラットフォームチームの使いやすさも向上させます。さまざまなアプリケーションにおけるプロンプトエンジニアリング、統合テスト、およびロールアウト管理を簡素化します。サービスごとに個別のプロバイダー固有のロジックを構築する代わりに、チームはモデルアクセスに一貫した単一のエントリポイントを使用できます。
ここにマルチモデルオーケストレーションの真価があります。TrueFoundryの仮想モデルは3つのルーティング戦略をサポートしており、仮想モデルごとに1つを選択できます。
TrueFoundryでは、一般的なプライマリとフォールバックを組み合わせた仮想モデルの設定は次のようになります。
routing_config:
type: priority-based-routing
load_balance_targets:
- target: azure/gpt-4o
priority: 0
retry_config:
attempts: 3
delay: 200
on_status_codes: ["429", "500", "503"]
fallback_status_codes: ["429", "500", "502", "503"]
- target: openai/gpt-4o
priority: 1
retry_config:
attempts: 2
delay: 100
- target: anthropic/claude-sonnet
priority: 2
fallback_candidate: false
この設定では、リクエストはまずazure/gpt-4oに送られます。そのretry_configブロックに従い、ゲートウェイはレート制限エラーが発生した場合、openai/gpt-4oに切り替える前に、200ミリ秒の遅延を伴って最大3回リトライします。Anthropicターゲットは、最も優先順位の高い健全なターゲットである場合にのみ実行され、他の2つのフォールバックとしては使用されません。
これらはすべてメモリ内で処理されます。
リクエストパスでの外部呼び出しはありません。
これらのルーティングパターンは、顧客サービス、カスタマーサポート、紛争解決、コーディングアシスタント、コンプライアンスワークフロー、社内エンタープライズコパイロットなど、さまざまなアプリケーションをサポートします。
フェイルオーバーチェーンは、各ルーティングルールに対して、優先順位付けされたプロバイダーのリストを定義します。プライマリがフォールバックステータスコード(TrueFoundryのデフォルト:401, 403, 404, 429, 500, 502, 503)を返した場合、ゲートウェイはエラーをアプリケーションに伝播させる代わりに、次に利用可能なターゲットを試行します。
このパターンは、複雑なワークフローや自律型エージェントにとって特に有用です。エージェントが複数のモデル呼び出しに依存している場合、単一のプロバイダー障害がワークフローを中断させる可能性があります。自動フェイルオーバーは、人間の介入なしにエクスペリエンスを保護します。
フォールバックが開始される前に、同じターゲットに対するリトライロジックも存在します。ゲートウェイのデフォルトは、429、500、502、503のエラーに対して100ミリ秒の遅延を伴う2回のリトライです。各ターゲットは、独自のretry_configブロック内でこれらのデフォルトを上書きできます。上記のYAMLでは、azure/gpt-4oはこれらのデフォルトを200ミリ秒で3回のリトライに上書きし、openai/gpt-4oは明示的に100ミリ秒で2回のリトライ(デフォルトと一致)に設定しています。anthropic/claude-sonnetにはretry_configブロックがないため、デフォルトを継承します。そして、ゲートウェイは継続的に障害を追跡します。ターゲットが2分間のローリングウィンドウ内で2回以上の障害を発生させた場合、それは異常とマークされ、エラーが解消されるまでスキップされ、自動的に回復します。人間の介入は不要で、障害が解消された際の手動での設定編集も不要です。
異なるモデルは、異なる形式、異なるメタデータ、終了理由、トークンカウント形式でレスポンスを返します。オーケストレーションレイヤーは、それらすべてを正規化します。リクエストがOpenAI、Anthropic、または自己ホスト型Llamaのいずれに送られたとしても、あなたのコードは同じレスポンス構造を読み取ります。
デバッグのために、TrueFoundryはリクエストを処理した実際のターゲットをx-tfy-resolved-modelレスポンスヘッダーで返します。これにより、仮想モデル名が10個の可能なターゲットをカバーしている場合でも、どのモデルが特定の出力を生成したかを追跡できます。この可視性は、品質低下を調査し、スティッキールーティング設定がユーザーを同じプロバイダーに維持したのか、それともセッションの途中で切り替わったのかを知る必要がある場合に重要です。
マルチモデルオーケストレーションは、チームがルーティングの決定をビジネス成果と結びつけるときに価値を生み出します。目標は、より多くのモデルを使用することではありません。目標は、コスト、品質、可用性、コンプライアンス、ガバナンスを向上させながら、各リクエストに適切なモデルを適用することです。
例えば、サポートワークフローは、定型的な顧客からの問い合わせをより小さなモデルにルーティングできます。複雑な請求に関する紛争や技術サポートのケースは、より強力なモデルに送ることができます。これにより、回答の品質を損なうことなくコスト管理が向上します。
別のユースケースでは、企業向けリサーチアシスタントが、自然言語理解に1つのモデル、データ検索に別のモデル、自然言語生成にさらに別のモデルを使用できます。オーケストレーションロジックは、どのモデルまたはエージェントが最終的な回答に貢献するかを決定します。
このアーキテクチャは、モデルの選択が運用可能になるため、企業に競争優位性をもたらします。チームは、すべてのAIアプリケーションを再構築することなく、ルーティングルールを調整し、プロバイダーをテストし、コストを削減し、レスポンス品質を向上させることができます。
ルーティングだけではガバナンスとは言えません。
多くのチームが独自のルーターを構築し、ロードバランシングの計算を正しく行っても、予期せぬ4つの問題に直面することになります。
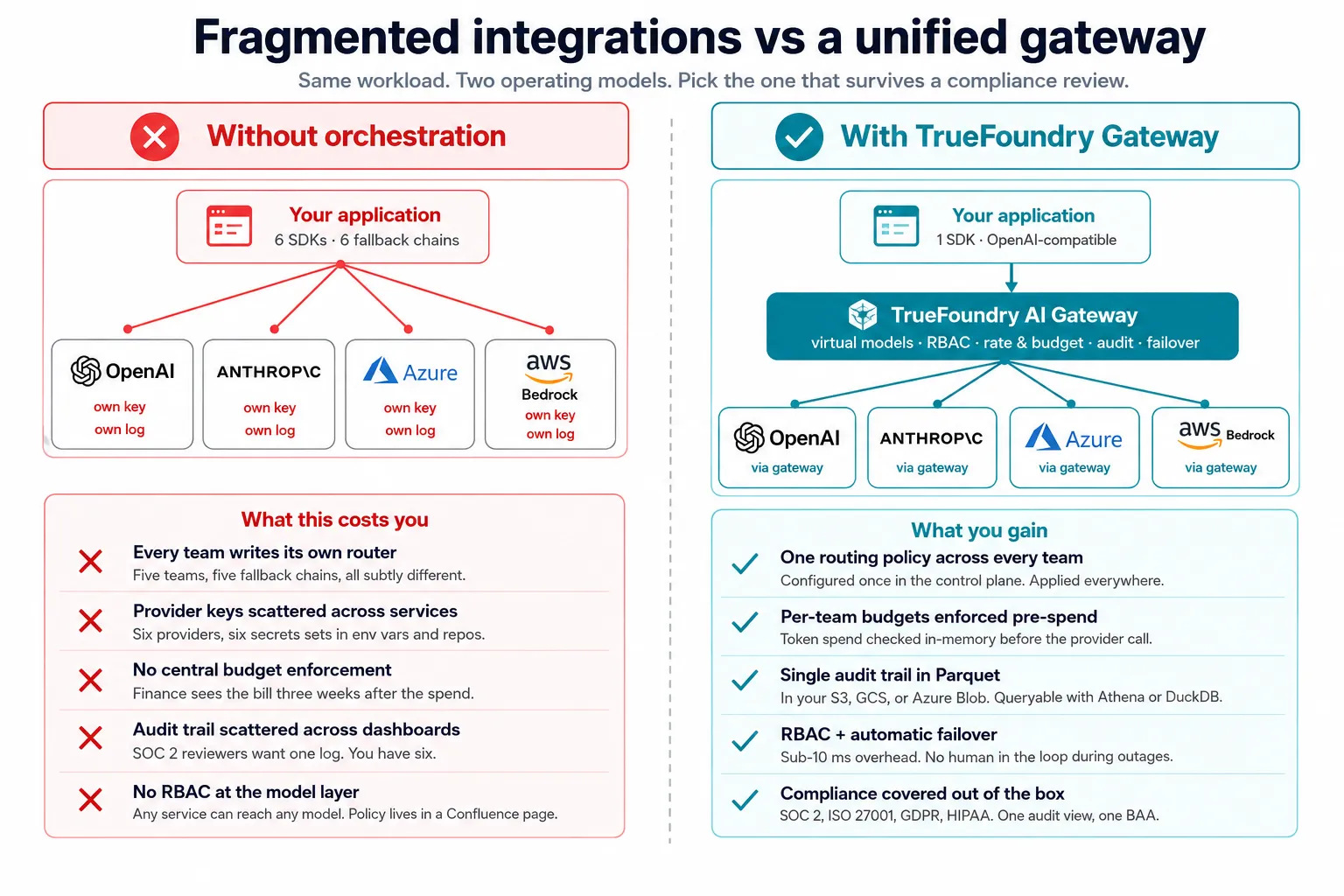
アプリケーションごとのルーティングは、各チームが同じロジックの独自のバージョンを作成することを意味します。5つのチームがあれば、5つの微妙に異なるフォールバックチェーン、環境変数に散らばる5組のプロバイダーキーが存在することになります。この不整合は組織規模で増大し、「マルチモデルオーケストレーションがある」という状態を「各チームがマルチモデルオーケストレーションを持っている」という状態に変えてしまいます。
リクエストが実行される前に、チームごとの予算制限を強制するルーティングフレームワークはありません。トークンの使用量は、ルーティングされたすべてのプロバイダーで蓄積されます。財務部門がOpenAIの請求額が3倍になった理由を尋ねる頃には、予算に関する話し合いはすでに3週間遅れで終わっています。
マルチプロバイダーのルーティングは、マルチプロバイダーの監査問題を引き起こします。OpenAIのダッシュボードのログ、Anthropicのコンソールのログ、Azureのポータルのログ。それらのどれも、統一されたユーザー属性付きの監査証跡としてまとめられることはありません。 SOC 2およびHIPAA の審査が実際に求めているものです。
可用性はアクセス制御と同じではありません。フェイルオーバーとは、健全なプロバイダーであればどのプロバイダーでもリクエストを処理できることを意味します。 ゲートウェイでのRBACなしでは、健全なプロバイダーは、アクセスすべきではないエンジニアやAIエージェントからも到達可能になる可能性があります。マーケティングプロンプトが臨床ワークフローのみに承認されたモデルに決して到達してはならない場合、そのポリシーはConfluenceページではなく、ゲートウェイに存在する必要があります。
ここで、コンテキストエンジニアリングと状態管理も運用上の懸念事項となります。システムは、データソース、ナレッジベースシステム、ベクトルデータベース、および外部データソースから関連情報を取得する場合があります。統制された制御層がなければ、システム全体が情報を公開したり、リクエストを誤ってルーティングしたりする可能性があります。
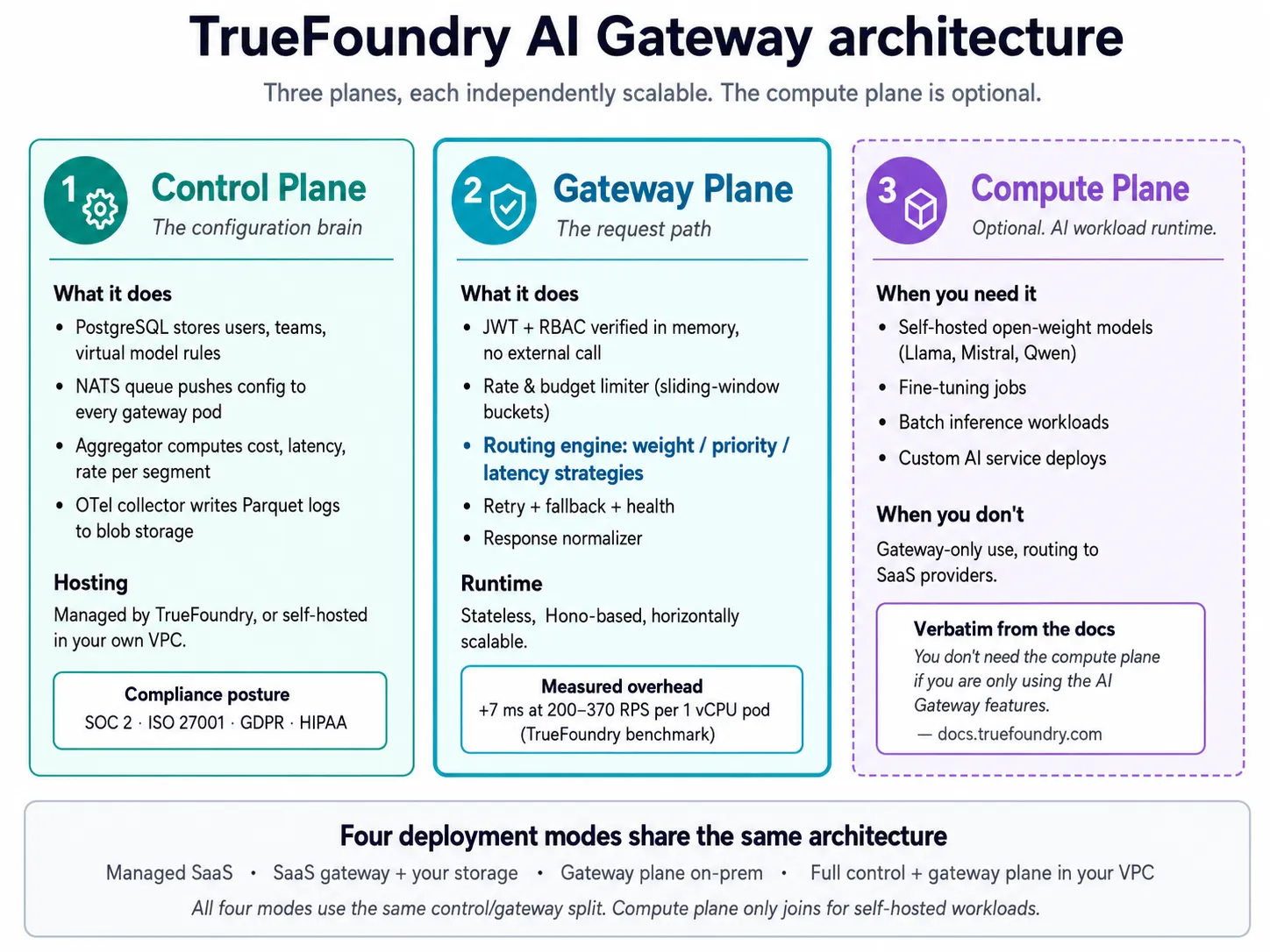
TrueFoundryの LLM Gateway は、 マルチモデルオーケストレーション を、マネージドSaaS、ハイブリッド、または独自のVPC内で完全に実行できる、コントロールプレーンによって管理されるルーティング層として提供します。本番環境でのデプロイには4つの特性が重要です。
AIゲートウェイは、本番AIワークロード全体にわたるより広範なガバナンス、レート制限、予算、ガードレール、および可観測性を追加します。 MCP Gateway は、モデル駆動型アプリケーションのツールアクセス、認証、およびMCPサーバーの可視性を管理します。 Agent Gateway は、自律エージェント、スペシャリストエージェント、および単一のAIエージェントが複数のモデルまたはツール呼び出しを行うことができる複雑なワークフローを制御します。
デモを予約する TrueFoundryがお客様のVPC内でマルチモデルルーティング、エージェント、MCPツール、および監査証跡をどのように管理するかをご覧ください。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


Multi-model orchestration is the architectural pattern of connecting an application to multiple AI models and dynamically routing each request to the model best suited for it, based on factors like task type, latency, cost, or provider availability. The orchestration layer abstracts the underlying providers behind a single API, handles failover when a model is unavailable, and normalizes responses so applications don’t need provider-specific code. In production, it’s how teams keep AI features running through provider outages and keep costs predictable as usage grows.
Multi LLM orchestration is the same pattern applied specifically to large language models. An orchestration layer sits between applications and several LLM providers (OpenAI, Anthropic, Google, Bedrock, self-hosted), routes each request to the appropriate model, manages failover and retries, and gives the application a consistent interface no matter which provider serves the response. The term is often used interchangeably with multi-model orchestration when the underlying models are all LLMs rather than a mix of model types.
The purpose is to match every workload to the right model on three axes: capability, cost, and reliability. Frontier models cost more but handle hard tasks better. Smaller models are cheap and fast for routine work. Multi-model orchestration routes intelligently between them, fails over when providers degrade, and gives operations teams one place to enforce cost, rate, and access policies. It’s the difference between running AI as a collection of provider integrations and running AI as a governed platform.
The orchestration layer normalizes them. Each provider has its own response shape, token count format, error codes, and finish reason conventions. The gateway translates everything into a single, consistent format (typically the OpenAI-compatible schema) before returning to the application. Provider-specific handling stays inside the gateway, not in the application code. In TrueFoundry’s case, the resolved target model is also returned in the x-tfy-resolved-model response header so you can trace which provider served any given request.
In a system like TrueFoundry’s gateway, you define a virtual model that points to a list of real targets and choose a routing strategy: weight-based (split traffic by percentages), priority-based (primary plus ranked fallbacks), or latency-based (pick the fastest healthy target automatically). You can layer in retry policies, fallback status codes, SLA cutoffs on time-per-output-token, sticky routing for multi-turn sessions, and metadata-based filters per target. Rules live in the gateway config and apply to every team that uses the virtual model name, with updates propagating in seconds.






最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


