













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
質問に答える単一のAIエージェントはツールです。しかし、5つのエージェントが調査、意思決定、草稿作成、レビュー、そして稼働中のエンタープライズシステムでの実行を行う場合、それは全く異なる種類のAIシステムとなります。本番システムで稼働するようになると、異なるガバナンス要件が発生します。
マルチエージェントオーケストレーションは、後者のケースが有用であり続けるかを決定するレイヤーです。それがなければ、レバレッジを生み出す連携が、積み重なるエラー、不明瞭な監査証跡、そして後から誰も再構築できない推論コストを引き起こすことになります。
このガイドでは、マルチエージェントオーケストレーションの意味、ランタイムの仕組み、2026年にチームが選択するフレームワーク、そしてそれらのフレームワークがオペレーターに何を任せるのかについて解説します。最後に、TrueFoundryがオーケストレーションされたシステムに必要なガバナンスレイヤーをどのように管理しているかを紹介します。
マルチエージェントオーケストレーションとは、複数のAIエージェントを共通の目標に向かって連携させる実践です。個々のエージェントは、より大きなワークフロー内で定義された役割、機能、またはサブタスクを担います。
このパターンは、シングルエージェントAIとはいくつかの点で異なります。作業は、すべてを順次処理する単一のAIエージェントを介するのではなく、専門エージェント間で分割されます。自律型エージェントは、ワークフローの進行に合わせて互いに結果を渡し、サブタスクを引き継ぎ、出力を結合します。個々のエージェントの上位に位置するオーケストレーションレイヤーは、誰がいつ実行するか、どのようなコンテキストを受け取るか、何に触れることができるか、そしてシステム全体が障害時にどのように振る舞うかを決定します。
これは、エンタープライズAIの構造における根本的な変化を意味します。汎用的な機能を備えた単一のツールから、専門的な役割とより広範な目標を達成するための明確な構造を持つ、協調的なエージェントシステムへと移行するのです。
その仕組みを理解することで、チームは障害が発生する前に設計に組み込むことができます。適切に構築されたマルチエージェントオーケストレーションシステムが実際にどのように動作するかは、4つのランタイム動作によって定義されます。
オーケストレーターエージェントは最上位の目標を読み取り、それを専門エージェントに適した個別のサブタスクに分割します。これらのタスク間の順序と依存関係を管理するのは、中央オーケストレーターの責任です。
出力は同じオーケストレーターエージェントを介して戻されます。各専門エージェントの出力は評価され、オーケストレーターエージェントは、そのステップが成功したか、あるいは再試行が必要かを判断します。目標が十分に達成されたと判断した時点でループを停止し、最終出力を生成します。
サブエージェントは定義された役割内で動作します。アクセスは、その機能に必要な特定の外部ツール、データソース、モデル機能に限定されます。スコープを狭くすることで、何らかの問題が避けられずに発生した場合でも、エージェントシステムを管理しやすく保ちます。
結果はオーケストレーターエージェントに戻され、オーケストレーターエージェントはそれらの出力を後続のステップのコンテキストに組み込みます。ワークフロー全体にわたるこの継続的な情報のフィードバックループが、すべてを順次処理する単一のAIエージェントと比較して、オーケストレーションされたシステムに優位性をもたらします。
ステップ間で永続する状態は、オーケストレーションされた複雑なワークフローを、連鎖的なシングルエージェント呼び出しから区別します。以前の出力が後の決定に影響を与え、ユーザーは各段階でコンテキストを再供給する必要がありません。この継続性こそが、エージェントAIをこのように構築する主な理由の一つです。
永続性は、その代わりに新たな障害モードをもたらします。ステップ2で状態に書き込まれた誤った事実が、それ以降のすべてのステップを破損させる可能性があります。このパターンにより、マルチエージェントオーケストレーションの障害のデバッグは、単一のAIエージェントの障害のデバッグよりもはるかに困難になります。そのため、定義されたエラー処理が最初から重要となるのです。
本番システムでは、プロトタイプ作成中に誰も考えたくないような障害ケースに対して、明確な動作が求められます。エージェントの失敗、サブエージェントのタイムアウト、サブエージェントからの不正な出力などです。リトライポリシーと手動介入への経路は、事前に定義しておく必要があります。
オーケストレーション層で明示的なエラー処理がない場合、2つの問題が発生します。1つのサブエージェントにおける単一障害点がシステム全体を停止させてしまうか、あるいは、オーケストレーターエージェントが不完全な情報のまま処理を進め、一見もっともらしいが、後になって初めて誰も気づかないような誤った出力を生成してしまいます。
.webp)
マルチエージェントオーケストレーションシステムを構築するためのフレームワークはいくつかあります。それぞれが異なる方法でオーケストレーションの調整問題を解決します。ビジネスニーズに合った適切なフレームワークを選択するには、複雑性、チームの専門知識、本番システムの信頼性要件を考慮する必要があります。
LangGraphのワークフローは有向グラフの形をとります。ノード、条件付きエッジ、およびすべての遷移は、開発者が明示的に制御できます。エージェントのステップをまたいだタイムトラベルデバッグ機能が組み込まれています。これはデモで聞くよりも、本番システムではるかに重要になります。
最適な用途: 条件分岐のある複雑なワークフロー、ヒューマン・イン・ザ・ループのチェックポイント、そして予測可能で監査可能な実行パスを必要とする耐障害性要件を持つシステム。
Microsoftの主要なマルチエージェント製品は、2025年10月1日にパブリックプレビューでリリースされたMicrosoft Agent Frameworkです。マルチエージェントオーケストレーションパターン向けのAutoGenと、テレメトリーやAzure統合などのエンタープライズAIの懸念事項向けのSemantic Kernelという2つの製品が統合されました。
統合期間中、両方の前身フレームワークはメンテナンスモードに入りました。今後のすべての開発は、統合されたプラットフォームに集中しています。AutoGenが先駆けて開発したグループチャット、ディベート、リフレクションなどのマルチエージェントオーケストレーションパターンは、現在Semantic Kernelのエンタープライズ基盤上で動作します。
AG2は別物です。AG2プロジェクトは、オリジナルのAutoGen 0.2のコミュニティフォークであり、Microsoft外でフレームワークのオリジナル作成者の一部によってメンテナンスされています。古いドキュメントで頻繁に混同されていますが、AG2はMicrosoft Agent Frameworkではありません。
CrewAIの中心的な抽象化は、役割を演じるエージェントの「クルー(乗組員)」です。各AIエージェントは、定義された役割、目標、ツールセットを持っています。このクルーの比喩は、ビジネスリーダーが顧客サポートやカスタマーサービスワークフローにおける複雑なタスクやワークフロー設計について既に考えている方法と一致します。
スケールが大きくなると限界が見えてきます。複雑な分岐シナリオでは、きめ細かな競合解決が難しくなります。厳格な本番システム、信頼性、状態管理の要件を持つチームは、プロトタイプを継続的に稼働させる必要が生じると、LangGraphに移行することがよくあります。
Google ADKでは、階層型エージェントツリーがモデルとなっています。中央のオーケストレーターがサブエージェントに委任し、そのサブエージェントがさらにサブエージェントを持つこともあります。A2Aプロトコルのネイティブサポートにより、フレームワーク間のAIエージェント通信が可能になります。これは、複数のフレームワークにわたる生成AIプロバイダーからの新しいエージェントを構築するチームにとって重要です。
.webp)
オーケストレーションフレームワークは調整問題を解決します。しかし、エージェントAIがプロトタイプから、顧客の問い合わせや顧客履歴ワークフローのために機密性の高い顧客データ上で動作するエンタープライズシステムに移行する際に生じる、ガバナンス、コスト、または監査性の問題は解決しません。
どのオーケストレーションフレームワークも、どの自律エージェントまたはユーザーがどの外部ツール、大規模言語モデル、またはデータにアクセスできるかを強制しません。セキュリティポリシーは個々のアプリケーションコードに委ねられます。そのコードはチーム間で一貫性のないスケーリングとなり、時間の経過とともに乖離が生じ、エージェントの数が増えるにつれて問題が複雑化するギャップを生み出します。
トークンコストはあっという間に膨れ上がります。5つのエージェントが関わるワークフローで、AIエージェント1つにつき1ステップで3回のモデル呼び出しが発生すると、顧客サポートリクエスト1件あたり15回以上の推論呼び出しが発生します。フレームワーク層にネイティブなコスト上限がないため、暴走したフィードバックループが請求書に載るまで捕捉されません。
オーケストレーションフレームワークが生成する監査証跡は、実行ログであり、コンプライアンスの成果物ではありません。各エージェントがいつ、誰の権限で何にアクセスしたかという証拠を生成するには、フレームワークが出力するものの上に外部ロギングインフラストラクチャを重ねる必要があります。これは競争上の優位性のギャップです。ガバナンスを最優先事項として扱う組織は、後回しにする組織よりも早く目標を達成します。
フレームワークのロックインは、モデルプロバイダー層で顕在化します。AIエージェントの役割間で大規模言語モデルを切り替えることは、設定変更ではなく、フレームワークレベルのリファクタリングを意味することがよくあります。それが、ほとんどのエンタープライズAIチームがモデルコンテキストプロトコルやプロバイダーからの新機能を通じて追求したいマルチクラウドおよびマルチベンダー戦略を制約します。
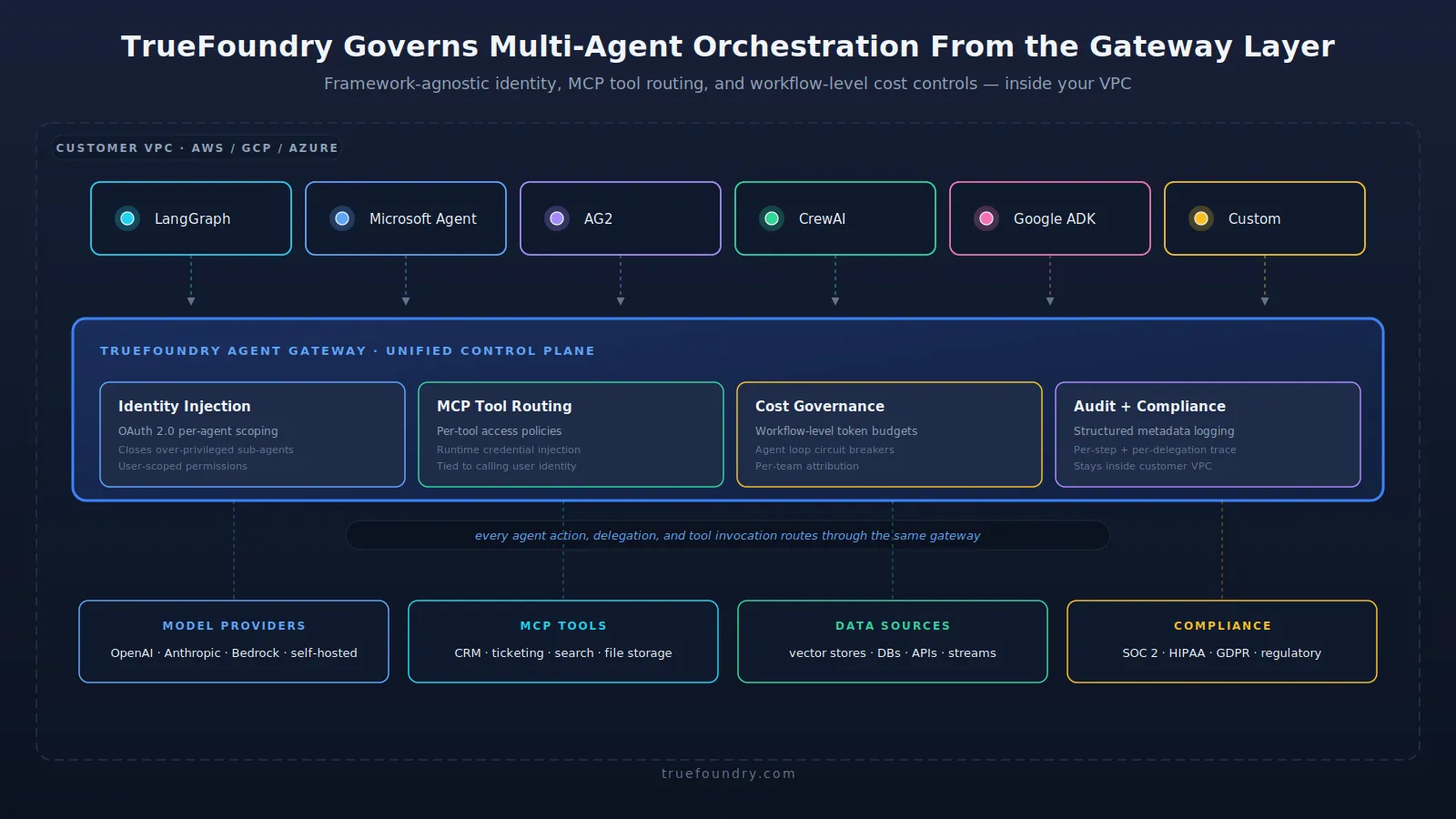
The TrueFoundry Agent Gatewayは、あらゆるマルチエージェントオーケストレーションフレームワークの上に位置します。オーケストレーション層のロジック自体を変更することなく、オーケストレーションされたシステムが何を実行できるか、何にアクセスできるか、そしてそれらの実行にどれくらいのコストがかかるかを統制します。
ゲートウェイが、フレームワークに依存しないID、MCPツールルーティング、ワークフローレベルのコスト管理を、マルチエージェントオーケストレーションワークロード向けに、自身のVPC内でどのように処理するかを解説します。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


