













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
大規模言語モデル(LLM)は、現代のAIアプリケーションの基盤となり、チャットボットやバーチャルアシスタントから、研究ツールやエンタープライズソリューションまで、あらゆるものを支えています。しかし、すべてのLLMが同じように作られているわけではありません。それぞれに独自の強み、限界、コスト要因があります。推論に優れているものもあれば、クリエイティブな文章作成、コーディング、構造化されたクエリの処理に長けているものもあります。そこで登場するのが、 LLMルーター です。
LLMルーターは、インテリジェントな交通管制官のように機能し、目の前のタスクに基づいて、ユーザーのプロンプトを最も適切なモデルに自動的に振り分けます。単一のモデルに依存するのではなく、企業や開発者は、クエリをリアルタイムで適切なLLMにルーティングすることで、パフォーマンス、精度、コストを最適化できます。AIの導入が進むにつれて、LLMルーティングはスケーラブルで信頼性が高く、効率的なAIシステムを構築するための不可欠なレイヤーになりつつあります。
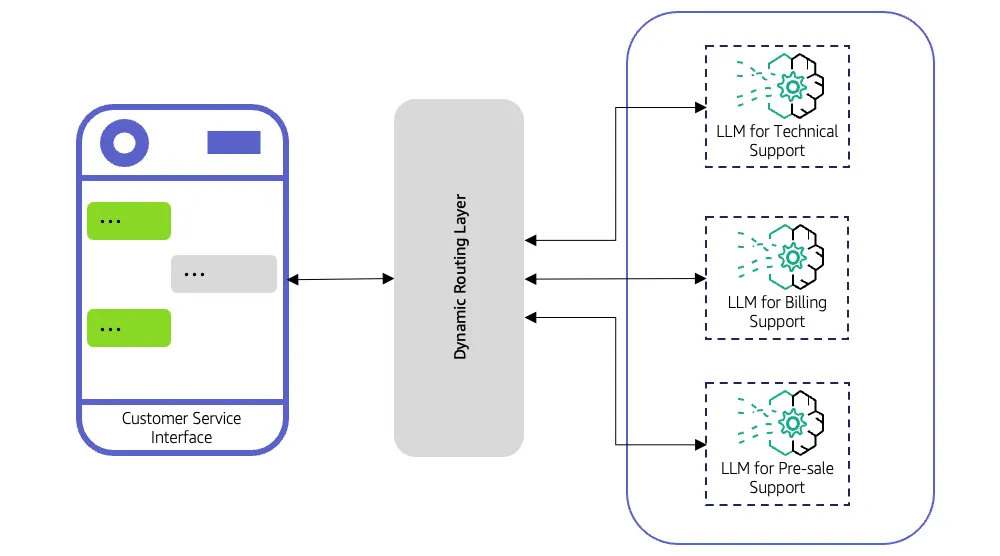
LLMルーターは、各リクエストをどの大規模言語モデルが処理すべきかを決定します。すべてのクエリを単一のモデルに送信するのではなく、入力内容を評価し、ルーティングロジックを適用して、最適なモデルに転送します。
ルーターは、例えばコード関連のクエリをプログラミングに特化したモデルに振り分けるなど、単純なルールに従うこともできますし、分類器、埋め込み、軽量な予測モデルなどの高度な戦略を使用して、どのLLMが最適な応答を生成するかを判断することもできます。
仕組み
このアプローチにより、「ワンサイズ・フィット・オール」の問題を解消します。軽量モデルは日常的なクエリを効率的に処理し、複雑なタスクや推論を多用するタスクは、より高性能なLLMに送られます。
実際には、ルーターはアプリケーションと複数のLLMの間に位置し、パフォーマンスを最適化し、コストを削減し、単一プロバイダーへの依存を最小限に抑えます。この設定により、すべてのリクエストが適切なモデルに到達し、AIシステムの信頼性と柔軟性が維持されます。
企業は、チャットボットやバーチャルアシスタントからコンテンツ作成、データ分析に至るまで、様々なタスクで大規模言語モデルをますます活用しています。
しかし、すべてのタスクに単一のLLMを使用すると、課題が生じます。一部のモデルは応答が速いものの深みに欠け、他方で高精度な結果を提供するモデルは、レイテンシーが高くコストもかかります。これらの違いを管理する方法がなければ、チームは常にパフォーマンス、精度、予算の間で妥協を強いられます。
LLMルーターは、リクエストをタスクに最適なモデルへインテリジェントに振り分けることで、この問題を解決します。
次のシナリオを考えてみましょう。
あるカスタマーサポートシステムは、2種類の問い合わせを受け付けます。
例えば、次のような簡単な問い合わせは 「営業時間は何時ですか?」 高度なモデルを必要としません。一方、製品のトラブルシューティングに関する複雑な技術的な質問には、高度なモデルが必要です。LLMルーターがなければ、すべての問い合わせが高性能で高価なモデルに送られる可能性があります。これにより、コストが増加し、応答時間が遅くなります。ルーターがあれば、簡単な問い合わせは高速で軽量なモデルに送られ、複雑な問い合わせはより高性能なLLMにルーティングされ、速度、コスト、精度が最適化されます。
企業にとってのメリット
クエリをインテリジェントにルーティングすることで、企業はより速く、より正確で、費用対効果の高いAIサービスを提供できます。LLMルーターは、AIの導入を画一的なアプローチから、柔軟で信頼性が高く、効率的なシステムへと変革し、現代のAIインフラストラクチャにとって不可欠なものとなっています。
LLMルーターは単なるトラフィックディレクター以上のものです。AIシステムをよりスマートに、より速く、より信頼性の高いものにするいくつかの主要機能を提供します。これらの機能を理解することで、組織は品質を維持しながら効率的にスケールするAIワークフローを設計できるようになります。
ルーティングが行われる前に、ルーターは受信クエリを分析します。メタデータ、タグ、クエリの種類、複雑さ、場合によっては意図や感情を調べます。この分析により、ルーターはどのモデルがリクエストの処理に最適かを判断するためのコンテキストを得られます。例えば、請求に関する顧客の質問は軽量な汎用LLMにルーティングされ、技術的なトラブルシューティングのクエリはドメイン固有のモデルに送信されます。
ルーターは、以下の複数の基準に基づいて最適なモデルを選択します。
これらの要素を考慮することで、ルーターは各リクエストが速度、精度、コストの最適なバランスを得られるようにします。
複数のモデルが同じタスクを処理できる場合、ルーターは単一のモデルに過負荷がかかるのを避けるために、リクエストをインテリジェントに分散します。これにより、システム全体の応答性が向上し、ピーク時の使用中でも一貫したパフォーマンスが保証されます。
最も優れたモデルでさえ、失敗したり、タイムアウトしたり、信頼性の低い応答を返したりすることがあります。ルーターはフォールバックメカニズムを実装し、クエリを自動的にバックアップモデルに再ルーティングします。これにより、ユーザーの中断なしに継続性と信頼性が確保されます。
高度なルーターは、使用パターン、モデルのパフォーマンス、クエリ結果を追跡します。これらの洞察は、チームがルーティング戦略を最適化し、より良いモデルを選択し、長期的にコストを削減するのに役立ちます。
LLMルーターは、マルチモデルAIシステムの意思決定ハブとして機能します。リクエストの分析、適切なモデルの選択、負荷分散、障害処理、洞察の提供を通じて、すべてのクエリが効率的、正確、かつ信頼性高く処理されることを保証します。これらの機能の組み合わせにより、LLMルーターは堅牢でスケーラブルかつ費用対効果の高いAIソリューションを構築する上で不可欠なコンポーネントとなります。
LLMルーターとAIゲートウェイは、どちらもAIアプリケーションと言語モデルの間に位置するため、しばしば一緒に議論されます。しかし、これらは異なる問題を解決し、AIスタックの異なる層で動作します。
An LLM Router は、コスト、レイテンシー、パフォーマンス、可用性、タスク要件などの要因に基づいて、最も適切な言語モデルにリクエストを選択し、誘導することに重点を置いています。その主な目的は、モデルの利用を最適化し、アプリケーションのパフォーマンスを向上させることです。
An AI Gateway は、AIトラフィックのためのより広範なコントロールプレーンを提供します。モデルルーティングに加えて、AIゲートウェイは認証、認可、レート制限、可観測性、ガバナンス、コスト追跡、セキュリティ制御などの機能を提供します。これらは、組織が複数のモデル、チーム、環境にわたるAIワークロードを管理し、保護するのに役立ちます。
LLMルーターは、クエリを最も適切な言語モデルに効率的に誘導するために、さまざまな戦略を使用します。これらの戦略は、一般的に静的、動的、ハイブリッドの3つのカテゴリに分類され、高度なシステムでは強化学習が組み込まれることもあります。
静的ルーティングは、事前定義されたルールに基づいて、どのモデルがクエリを処理するかを決定します。一貫したルーティング動作を保証し、実装が容易です。
動的ルーティングは、現在のシステムパフォーマンスとクエリのコンテキストに基づいてモデルを選択し、リアルタイムで適応します。
ハイブリッド戦略は、静的アプローチと動的アプローチを組み合わせることで、より高い柔軟性と効率性を実現します。
一部の高度なシステムでは、強化学習を使用してルーティングの決定を継続的に改善します。これらのルーターは、過去のクエリとモデルのパフォーマンスから学習し、複雑なワークロードや進化するワークロードに対応するために、時間の経過とともにルーティングを最適化します。
LLMルーターは、AIシステムをより効率的、信頼性が高く、費用対効果の高いものにするいくつかの重要なメリットを提供します。主要な利点の1つは、パフォーマンスの最適化です。
各クエリをタスクに最適なモデルにインテリジェントにルーティングすることで、ルーターは強力で推論能力のあるモデルが複雑な質問を処理し、軽量で高速なモデルがより単純なリクエストを処理することを保証します。このアプローチは速度と精度を両立させ、全体的なユーザーエクスペリエンスを向上させます。
もう1つの重要なメリットは、コスト効率です。ルーターがない場合、企業はすべてのクエリを高性能モデルで実行する可能性があり、これにより運用コストが不必要に増加します。ルーターは、高価なモデルが高価値または複雑なクエリのために予約されることを保証し、一方、定期的または反復的なタスクは、リソース集約度の低いモデルによって処理されるため、計算コストが削減され、ROIが最大化されます。
LLMルーターを使用すると、信頼性も向上します。高度なルーターにはフォールバックメカニズムが含まれており、モデルが失敗したり、タイムアウトしたり、信頼度の低い結果を返したりした場合に、クエリを自動的にリダイレクトします。これにより、一貫した信頼性の高いパフォーマンスが保証され、カスタマーサポートやバーチャルアシスタントなどのリアルタイムアプリケーションでの中断を防ぎます。
さらに、LLMルーターは柔軟性を提供します。企業は、異なるプロバイダーの複数のモデルを統合し、各タスクに最適なものを選択できます。
これにより、単一ベンダーへの依存度が低減され、新しい機能が登場するにつれて、チームはさまざまなモデルを試すことができます。
最後に、ルーターはスケーラビリティをサポートします。クエリ量が増加しても、ルーターはリクエストをモデル間でインテリジェントに分散させ、過負荷を防ぎ、スムーズなシステムパフォーマンスを維持します。
最適化されたルーティング、コスト削減、信頼性、柔軟性、スケーラビリティを組み合わせることで、LLMルーターは、AIデプロイメントを厳格な単一モデルのアプローチから、動的で効率的、かつ回復力のあるシステムへと変革します。
LLMルーターは、AIのパフォーマンス、信頼性、効率を最適化するために、企業全体でますます利用されています。これらはインテリジェントなクエリルーティングを可能にし、複雑さ、ドメイン、コンテキストに基づいて、適切なモデルが各タスクを処理することを保証します。
カスタマーサポートの自動化
企業は、簡単なFAQから複雑な技術的問題まで、毎日何千もの顧客からの問い合わせに対応しています。LLMルーターは、定型的な質問を高速で軽量なモデルに振り分け、複雑な問題はより高性能なモデルにルーティングします。これにより、迅速、正確、かつ一貫した応答が保証され、顧客満足度が向上し、運用上の負担が軽減されます。
ナレッジマネジメントとエンタープライズ検索
企業は、社内文書、マニュアル、ポリシーの大規模なリポジトリを維持しています。ルーターはクエリを分析し、推論、要約、またはドメイン固有の知識に最適化されたモデルにルーティングします。従業員は、高コストのモデルに過負荷をかけることなく、正確で文脈に関連性の高い情報を受け取ることができます。
ワークフローとタスクの自動化
LLMは、レポート生成、データ分析、意思決定支援タスクに広く使用されています。ルーターは、複雑度の高いクエリを強力なモデルに、定型的なタスクを軽量なモデルに動的に割り当て、企業ワークフロー全体で速度、精度、計算コストのバランスを取ります。
マルチモデルオーケストレーション
組織は、プロバイダーやドメインをまたいで複数のLLMをデプロイすることがよくあります。ルーターは、モデルの選択、負荷分散、フォールバックメカニズムを管理し、大規模なAIシステムにおける信頼性、柔軟性、スケーラビリティを確保します。
製品レコメンデーションとパーソナライゼーション
EコマースまたはSaaSプラットフォームの場合、LLMルーターは、パーソナライゼーションタスクをユーザー行動とコンテキストに基づいてトレーニングされたモデルに割り当て、一般的なレコメンデーションはよりシンプルなモデルに委任できます。これにより、コストを抑えながらレコメンデーションの精度とパフォーマンスが向上します。
コンプライアンスとリスク分析
金融、法務、またはヘルスケア企業では、クエリが規制やドメイン固有のガイドラインに厳密に準拠する必要がある場合があります。ルーターは、機密性の高いクエリや重要なクエリをドメイン専門知識を持つモデルに誘導し、コンプライアンスを確保しつつ、一般的なタスクは標準モデルで処理できます。
コンテンツ生成と要約
マーケティング、ナレッジ共有、またはドキュメント作成の場合、LLMルーターは、複雑なコンテンツ作成タスクを高品質モデルに割り当て、よりシンプルな要約やドラフト作成タスクを高速モデルに割り当てることができます。これにより、出力品質を損なうことなく効率が最適化されます。
これらの多様なシナリオにLLMルーターを適用することで、企業は複数のワークフローやアプリケーション全体でパフォーマンス、信頼性、費用対効果を維持しながら、AIをインテリジェントにスケールさせることができます。
LLMルーターが幅広いエンタープライズアプリケーションをどのように強化しているかを探った後、マルチモデルAIシステムにおけるもう一つの重要なコンポーネントとどのように異なるかを理解することが重要です。
LLMルーター は、インテリジェントなリクエストルーティングに焦点を当てています。その主な機能は、受信クエリを分析し、コンテキスト、複雑さ、メタデータを評価し、各リクエストを最適なモデルに誘導することです。ルーターは、精度、速度、コストを最適化するために、動的ルーティング、コンテキスト認識型意思決定、フォールバックメカニズムなどの高度な戦略をしばしば組み込みます。
これらは、クエリの種類、ドメイン、または計算要件が大きく異なる環境で特に重要であり、企業が負荷を分散し、高いパフォーマンスを維持することを可能にします。
LLMゲートウェイ一方、は、1つまたは複数のLLMと対話するための集中アクセスポイントとして機能します。その主な役割は、統合を簡素化し、標準化されたAPIを提供し、認証を管理し、レート制限を処理し、使用状況を監視することです。
ルーターとは異なり、ゲートウェイは通常、インテリジェントなモデル選択の決定を行いません。これらは、マルチモデル展開を容易にするための統一されたアクセスと運用制御を提供します。ゲートウェイは、クエリレベルの最適化よりも、インフラレベルの管理、セキュリティ、スケーラビリティに重点を置いています。
主要な違い
ルーターとゲートウェイは、しばしば階層型アーキテクチャで連携して動作します。ゲートウェイはアプリケーションに安全で標準化されたエントリーポイントを提供し、ルーターはその背後でインテリジェントなモデル選択の決定を行います。この組み合わせにより、企業は運用制御と最適化されたクエリ処理の両方を実現できます。
LLMルーターとLLMゲートウェイの区別を理解することは、組織がマルチモデルAIシステムを効果的に展開するのに役立ちます。
ルーターはインテリジェントでコンテキスト認識型のパフォーマンスを推進し、ゲートウェイは安全でスケーラブルかつ信頼性の高いアクセスを保証することで、エンタープライズAIの堅牢な基盤を構築します。
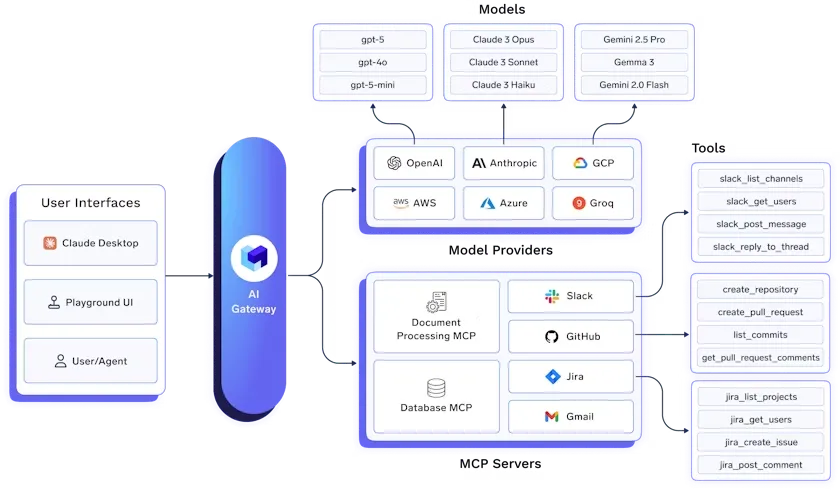
TrueFoundry LLMゲートウェイは、単一の安全で高性能なAPIを通じて、すべての主要な大規模言語モデル(LLM)へのアクセスを統合するエンタープライズ対応のプラットフォームです。
コード変更を必要とせずに、OpenAI、Anthropic Claude、Gemini、Groq、Mistral、オープンソースフレームワークを含む250以上のモデルを統合することで、GenAIインフラストラクチャを簡素化します。チームは、認証とAPIキー管理を一元化しながら、チャット、補完、埋め込み、再ランキングのワークロードに一貫したAPIを使用できます。
主要機能:
企業が複数の大規模言語モデル(LLM)にますます依存するようになるにつれて、LLMルーターやLLMゲートウェイのようなツールは、AIを大規模に管理するために不可欠なものとなっています。LLMルーターはシステムにインテリジェンスをもたらし、各クエリを分析して、そのタスクに最適なモデルに到達するようにします。これにより、特に複雑で大量のワークフローにおいて、パフォーマンスが向上し、コストが削減され、信頼性が高まります。
一方、ゲートウェイは、モデルへの安全で標準化されたアクセスの基盤を提供し、統合を簡素化し、使用状況を監視し、運用管理を強化します。
これらのコンポーネントは連携して、インテリジェンスと運用効率のバランスを取る階層型AIアーキテクチャを形成します。ルーターの意思決定能力とゲートウェイの構造的信頼性を組み合わせることで、組織はスケーラビリティと制御を維持しながら、複数のLLMの価値を最大化できます。
LLMルーターの導入はもはや選択肢ではなく、迅速、正確、かつ費用対効果の高いAIサービスを提供することを目指す企業にとって必要不可欠なものです。ゲートウェイとともにその役割を理解することで、チームは多様なビジネスニーズに対応できる堅牢なAIインフラストラクチャを設計する準備が整います。
AIモデルが進化し、増え続けるにつれて、インテリジェントなルーティングと構造化されたアクセスを習得することは、急速に進歩するAIの状況で競争力を維持しようとする企業にとって重要になります。
LLMルーティングは、事前定義されたロジック、セマンティック埋め込み、または分類ルールに対して受信リクエストを評価することで機能します。システムは、コンテキスト、必要な精度、またはアップストリームプロバイダーのレイテンシーに基づいてトラフィックをルーティングします。一元化されたゲートウェイがこれらの複雑な構成を管理し、モデルの選択とフェイルオーバーを自動化するため、モデルが更新されるたびに手動でコードを変更する必要はありません。
LLMルーティング分類は、推論実行前にプロンプトを分類するために非常に効率的なモデルを使用します。このステップでは、簡単な挨拶と複雑なコーディングタスクのような意図を識別します。自動分類により、複雑度の低いクエリをより小さく、高速で、費用対効果の高い代替モデルにフィルタリングすることで、高価なフロンティアモデルの過剰な利用を防ぎます。
TrueFoundryは、トラフィックオーケストレーションとガバナンス、セキュリティを融合させることで、LLMルーティング機能とAIゲートウェイ機能を統合します。このプラットフォームは、単一の集中管理プレーン内で、モデルのフェイルオーバー、レート制限、コストを考慮したルーティングを処理します。このインフラストラクチャにより、企業AIのデプロイメントは、大規模な本番環境において高い回復力と費用対効果を確保できます。
主要なLLMルーターには、エンタープライズグレードのオーケストレーションにはTrueFoundry、統合プロキシAPIにはLiteLLM、自動モデル選択にはMartianが含まれます。その他の主要な業界オプションとしては、高度なガードレールにはPortkey、超高速な可観測性にはHelicone、数百ものオープンソースおよびクローズドソースモデルへの簡単なアクセスにはOpenRouterがあります。
LLMルーターは、クエリのメタデータ、タイプ、コンテキストを分析してモデルを選択します。選択要因には、ドメインの専門知識、推論能力、レイテンシー、コストなどが含まれます。単純なクエリは軽量モデルに、複雑なタスクは高性能モデルに送られます。高度なルーターは、リアルタイムでインテリジェントなモデルルーティングのために、埋め込みや予測分類器を使用する場合があります。
LLMルーターの主要機能には、リクエスト分析、インテリジェントなモデル選択、負荷分散、フォールバック処理、監視が含まれます。ルーターは複数のLLMにクエリを分散し、失敗したリクエストを再ルーティングし、パフォーマンスを追跡します。これにより、タスクが効率的に処理され、モデルが最適に利用され、企業AIワークフローにおいてシステムが信頼性と拡張性を維持することが保証されます。
一般的なLLMルーターの種類には、ルールベースルーティング、コストベースルーティング、パフォーマンスベースルーティング、タスクベースルーティングなどがあります。ルールベースルーターは事前定義された条件に従い、コストベースルーターはより安価なモデルを選択し、パフォーマンスベースルーターはより高い精度や速度を持つモデルを選び、タスクベースルーターは、コーディング、チャット、要約などのタスクに特化したモデルにリクエストを送信します。
LLMルーティングは、ユーザーのリクエストを分析し、最も適切なモデルに誘導することで行われます。開発者は、タスクの種類、コスト、レイテンシー、モデルの能力などの要因を考慮したルールを定義したり、アルゴリズムを使用したりします。ルーティング層が入力内容を評価し、適切なLLMにクエリを自動的に送信します。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


