













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
Vercel’s platform, especially its AI SDK and one-click deploy-on-push workflow makes it easy for frontend teams to get AI demos up and running in minutes. The Vercel AI SDK is a free, open-source toolkit that lets teams ship AI features quickly.
However, Vercel’s pricing was originally designed for static sites and short-lived web functions. Once an app’s AI workload becomes long-running, for example, streaming multi-step agent responses or heavy RAG pipelines, the Vercel AI pricing model changes dramatically.
Instead of fixed monthly rates, you start paying by the millisecond of serverless execution time and gigabytes of data transferred. In practice, teams find their predictable $20/month bills spike wildly as chatbots and agents hit Vercel’s resource limits.
This guide breaks down how Vercel AI pricing works, what hidden fees AI workloads incur, and why engineering teams eventually migrate to private cloud platforms like TrueFoundry to avoid these costs.
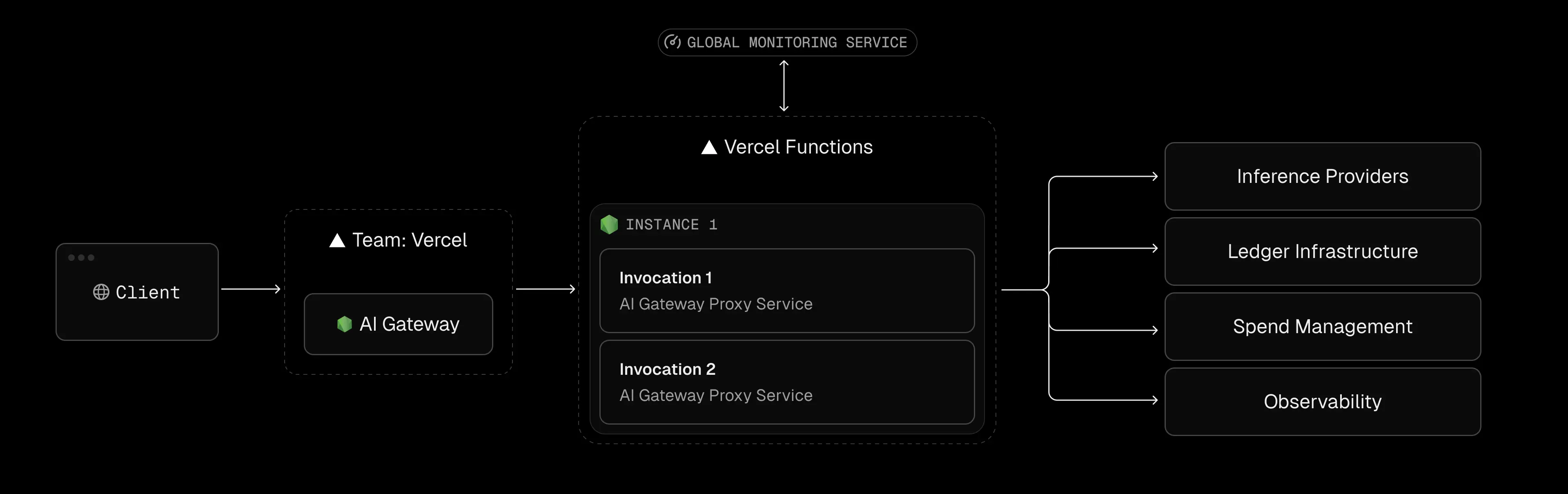
Vercel now uses a hybrid model combining user seats with usage quotas and overage charges. In plain terms: hobbyist use is free, but professional usage costs grow with your team size and compute needs. Below is a summary of each tier and its implications for AI applications.
The Hobby plan is “the perfect starting place for your web app or personal project” and is free forever. It is strictly limited to personal and non-commercial use – business or revenue-generating use of the Hobby plan violates Vercel’s terms. Hobby includes generous features (CDN, 1M edge requests/month, simple WAF) but very tight compute limits. In particular, functions on Hobby can only run for up to 60 seconds (default), because the function duration is capped (and only slightly tunable) on free plans. AI applications often need to stream responses or run agent loops longer than a minute. On Hobby, these long tasks will simply timeout with 504 errors. In short, if your AI demo needs any sustained computation (for example, a complex query or vector search), Hobby is likely to cut off before the result arrives. In practice, teams find that even moderately complex LLM calls or agent chains blow past Hobby’s duration limits. This makes the free tier good for prototypes and lightweight experiments, but unsuitable for production AI workloads that require extended compute or streaming outputs.
The Pro plan starts at $20 per deploying user per month. (Each developer seat is $20/mo; you can add unlimited free “viewer” seats.) Pro converts those hobby quotas into higher limits, but at a cost. For example, Pro includes 1 TB of bandwidth per month (about $350 of value) – ten times the 100 GB included on Hobby. Beyond that 1 TB, outbound traffic is billed at $0.15/GB. Pro also raises the included function compute: by default you get around 1,000 GB-hours of serverless execution per month (across all functions) – roughly what one developer running small tasks would consume – before paying overage.
However, AI workloads chew through those limits extremely fast. Every open stream or long inference ties up memory and CPU time. In practice, developers report exhausting Pro quotas in days: one example showed a deployed screenshot service using 494 GB-hours in just 12 days of testing, projecting 1,276 GB-hours in a month. Because Vercel bills by execution time, that worker’s 1,276 GB-hours would incur an extra $160/month (at roughly $0.18/GB-hr) beyond the base plan. In short, the Vercel AI cost on the pro plan can easily balloon to hundreds or thousands once you start long-running AI streams, heavy RAG fetches, or large data transfers.
Key takeaways for Pro: it can support production apps, but every developer you add costs $20+/mo, and unpredictable usage (AI streaming, large models) can drive steep averages. The included free credits only defer billing; streaming 45-second responses means servers stay alive 45 seconds, incurring 45× more cost than a 1-second API call.
The Enterprise tier is customized and aimed at large organizations. Officially, details are by quote, but in practice, entry starts around $25,000 per year for baseline features.
This tier unlocks advanced compliance and scaling tools, such as:
For example, only the Enterprise contract gets hundreds of WAF rule slots (up to 1,000 IP block rules). In terms of Vercel AI pricing, Enterprise removes some usage caps and allows bigger functions, but the per-Gigabyte memory-hour and data rates remain.
Many startups find the jump from Pro to Enterprise a “cliff” as the extra features are enterprise-oriented, but the price is an order of magnitude higher. As one developer noted, the Pro tier might be “all you need”, but the cost at scale is in the usage, not the license.
Vercel AI pricing is optimized for web apps (lots of short, stateless requests). AI apps behave differently. The core cost drivers for AI on Vercel are: execution duration, data egress, and concurrency constraints.
On Vercel, you pay for every millisecond a function is active. Idle waiting for I/O or streaming counts as billable time. The docs explicitly state: “Function Duration generates bills based on the total execution time of a Vercel Function.”. For a normal web API call (10–100 ms) this is negligible, but an LLM chat could stream for 30–60 seconds. In that case, a single request can cost orders of magnitude more.
Consider a typical scenario:
A Next.js edge function opens a streaming response to the browser until the LLM finishes. During that stream, the serverless instance is busy the whole time, incurring continuous memory (and some CPU) billing. In practice, teams have reported shockingly high usage. In one case study, a developer migrated a heavy Puppeteer screenshot service to Vercel. The Pro plan included 1000 GB-hr, but in 12 days that service had already consumed 494 GB-hours. Extrapolated to a full month, that’s 1,276 GB-hours, meaning roughly $160 of extra Vercel charges for that single function. (That developer ultimately switched to AWS Lambda because the same workload on AWS was only about 101 GB-hours/month.)
The lesson: lengthy AI streams are fundamentally “heavy” on serverless billing. A one-minute chat response could burn 20–50 MB of memory for 60 seconds, costing ~$0.001 per request. Multiply that by heavy usage, and it adds up fast.
AI applications often involve retrieval-augmented generation (RAG) or data pipelines that move megabytes of text and embeddings around. Each time your Vercel function fetches a document or model from a remote store, that data leaves the Vercel network.
Heavy RAG usage means large overages. For example, fetching a 100 MB document ten times would burn 1 GB of bandwidth. If a RAG pipeline shuffles hundreds of gigabytes monthly, that could tack on hundreds of dollars to the bill.
In short, Vercel’s bandwidth quotas feel generous for regular web traffic, but AI apps that routinely send large payloads or embed batches will exceed them quickly and trigger expensive overages.
Vercel functions auto-scale up to a point, but there are limits. By default, the platform allows up to ~30,000 concurrent executions on Hobby/Pro (and 100,000+ on Enterprise). For most apps, that seems high, but AI workloads can push concurrency in unexpected ways.
For instance, an AI chat service might open dozens of simultaneous function streams to many users at once. Once you hit the concurrency cap, new requests get queued or throttled. At that point, you either need to upgrade (e.g., Enterprise) or implement external scaling.
In effect, Vercel puts a ceiling on bursty AI traffic unless you pay significantly more. Anecdotally, teams have seen chatbots start to fail (504/429 errors) during traffic spikes, because the underlying serverless pool was saturated.
.webp)
A common misconception is that using the Vercel AI SDK Vercelのインフラ利用を強制するものではありません。実際には、AI SDKはNext.js/TypeScriptでAI機能を構築するための単なるツールキット(オープンソース、無料)です。
SDKを使えば、自己ホスト型モデルを含むあらゆるLLMプロバイダーにルーティングできます。これは、比較する際に重要な考慮事項となります。 Vercel AI gateway vs OpenRouter プロバイダーの柔軟性とコスト管理の観点から。 要件はありません Vercelのサーバーでコードを実行する必要はありません。実際、SDKのほとんどの部分(UIコンポーネント、プロバイダー、クライアントライブラリ)はどこでも動作します。例えば、あるチームはAI SDKを使ったNext.jsアプリをコンテナ化し、Kubernetes(EKS/GKE)や任意のクラウドVMにデプロイできます。コードはVercel以外の環境で動作していることを「知りません」。
チームが立ち往生する理由:
通常は利便性のためです。VercelのホスティングはSDKと密接に統合されており、コードをコミットすると、Vercelがビルド、デプロイし、組み込みのAI Gatewayタブまで提供します。多くのチームはデフォルトで「Deploy to Vercel」をクリックします。
そのトレードオフは、利便性がサーバーレスのコストモデルを隠してしまうことです。エンジニアはVercelで喜んでプロトタイプを作成するかもしれませんが、請求書が届くまで、すべてのモデル呼び出しがVercelの(しばしば高額な)サーバーレス料金で請求されていることに気づきません。
Vercelを利用したAIプロジェクトが成長するにつれて、Vercel AIの料金問題と並行して、いくつかの運用上の問題点が発生します:
有料プランでも、Vercelは厳格な実行制限を課しています。デフォルトでは、ProプランのHTTP関数は 5分 (「Fluid Compute」を使用すると最大13分まで設定可能)でタイムアウトします。Hobbyプランではわずか60秒です。
実際には、数分以上実行されるAIエージェントや研究ワークフローは強制終了されます。例えば、データベースのクエリ、ドキュメントの要約、レポートの出力に10~15分かかる多段階エージェントは、確実に制限を超過して失敗します。
これらの上限を超えると、チームはAIタスクで頻繁に504エラーが発生すると報告しています。対照的に、独自のクラウドインフラでは、必要に応じて関数やコンテナを無期限(または少なくとも数時間)実行させることができます。
Vercelのエッジミドルウェア(Next.js Edge Functionsなど)はパフォーマンスを向上させることができますが、ロックインを伴います。
実際には、チームは速度を重視して重要なロジックをEdge Functionsに組み込むことがありますが、その結果、 Vercelからの移行が大規模な書き換え作業になることがあります。
現在、VercelにはAIワークロード向けのネイティブGPUインスタンスがありません。これは、高速化が必要なモデル推論や埋め込み処理は、プラットフォーム外で行う必要があることを意味します。
チームはしばしば、GPTスタイルのモデルやベクトル検索をGPUを備えたAWS/GCP/Render/Azureでホストし、それらをVercelの関数から呼び出すことになります。この分割された設定は レイテンシーを増加させ(すべての呼び出しが外部サービスを経由するため)、運用上の複雑さを増します。
対照的に、Kubernetes上に構築されたインフラストラクチャ(TrueFoundryなど)は、同じクラスター内でCPUのみのウェブコードとGPU推論を並行して実行でき、そのような分断を解消します。
これらの注意点にもかかわらず、Vercelは 特定の AIシナリオにおいて悪い選択肢ではありません。その強みが発揮されるのは次のような場合です。
まとめると: VercelのAI料金体系は、AIを軽く利用するフロントエンドアプリに適しています、または市場投入までの時間を何よりも重視するチームに適しています。損益分岐点は、AIワークロードが単なる目新しいデモではなく、アプリケーションの「本当の」一部になったときに訪れます。
AI機能が製品の中心になるにつれて、多くのチームが転換期を迎え、代替案を探しています。TrueFoundryは、サーバーレスの容易さと生のクラウドの経済性を兼ね備えたソリューションとして位置づけられています。以下は、AIワークロードにおける主要な要素の比較です。
これは実際には何を意味するのでしょうか?多くのチームは、Vercelでの月額料金が 不釣り合いに 実際のコンピューティング量と比較して上昇することに気づいています。ある実例では、Vercelで約1,276GB-hr(年間約2000ドルの費用)を消費したサービスが、同じ負荷で生のAWS Lambda(無料枠)ではわずか約101GB-hrしか消費しませんでした。簡単に言えば、 同等のAIワークロードは、自己管理型のクラウドインフラストラクチャではるかに安価に実行できます。TrueFoundryを使用すると、請求額は基本的に「バニラ」クラウドコンピューティング(EC2、GKEノードなど)にプラットフォーム料金が加算されたものになり、サーバーレスが課す乗数ではありません。
.webp)
TrueFoundryはハイブリッドアプローチを提供します。開発者に優しいサーバーレスモデル(自動スケーリング、シンプルなAPI)を維持しつつ、自身のクラウドアカウントで実行できます。主な側面は次のとおりです。
TrueFoundryを使用すると、Next.js(およびその他の任意のアプリ)を、自身のクラウドアカウント内のKubernetes(EKS、GKE、またはAKS)上に標準のDockerサービスとしてデプロイできます。あるブログが説明しているように、 「TrueFoundryを使えば、自身のクラウドプロバイダーアカウント内のKubernetesクラスターにアプリケーションを非常に簡単にデプロイできます。」。内部的には、あなたのNext.jsエンドポイントは、あなたが制御するポッド/ノードで実行されます。
これは、お客様が クラウドの基本料金で CPUとメモリに対して課金され、隠れたサーバーレスプレミアムは一切ありません。アイドル状態のWebSocketや開かれたストリームはノード上のRAMを消費しますが、そのRAMの料金はサーバーレスのGB-hrコストのほんの一部です。
Kubernetesノードを管理するため、関数のタイムアウトとライフタイムを制御できます。必要に応じて、長時間実行されるPodやジョブを数分または数時間実行できます。TrueFoundryは5分または15分の制限を課しません。それはお客様のインフラストラクチャが決定します。
複雑なエージェントパイプラインや研究タスクは、(通常のPodの最大ライフタイムがある場合のみそれに従い)完了まで実行されます。これにより、Vercelでよくある、途中で発生する504エラーという問題点が解消されます。AIエージェントが完了までに20分かかる場合、TrueFoundryではそれが可能ですが、Vercelでは5分で失敗してしまいます。
AIにおけるTrueFoundryの大きな利点は、組み込みのGPUサポートです。内部でKubernetesを使用しているため、GPUノードプールをアタッチし、Webサービスと並行して推論ワークロードをスケジュールできます。これにより、フロントエンドAPIと重いML推論を同じクラスターで実行でき(レイテンシとデータ転送を削減します)、実際、TrueFoundryのクラウドネイティブアーキテクチャは明示的に 「異なるクラウドプロバイダーが提供する様々なハードウェア、特にGPUにアクセスできるようにします」。
実際には、プラットフォームを離れることなく、GPUアクセラレーションノードでLLM推論や埋め込み生成を実行できます。別個のGPUサービスを連携させる必要はなく、リージョン間のトラフィックに料金を支払う必要もありません。
Vercelはフロントエンドのデリバリーには優れたプラットフォームであり続けます。しかし、AIコンピューティングがバックエンドを形成するとすぐに、経済性が変わります。重要なポイントは次のとおりです。 重いAIタスクに対してVercelの期間ベースのプレミアム料金を支払うのを避けることです。
単純なHTTPトラフィックとは異なり、AIバックエンドはリクエストごとに実行時間がはるかに長く、大量のデータを移動させることがよくあります。VercelのAI料金モデルでは、コンピューティングの毎秒と、出力されるすべてのギガバイトに対して料金を支払うことになります。対照的に、TrueFoundryでは、基本ノードと稼働秒数に対して料金を支払います。これは、EC2やGKEでコンテナを実行した場合と同じコストモデルです。
その結果、スケーリングコストはよりスムーズになります。チームは、月々の支出が 線形に 実際に使用されたコンピューティング量に比例して増加し、関数の実行時間のミリ秒ごとではありません。多くの場合、Vercelで月に数百ドルかかっていたものが、自社のクラウドでは数十ドルで済むことがあります。
チームがVercelの請求額の急増に直面している、あるいは常にタイムアウトと格闘している場合、インフラストラクチャの移行を検討する価値があります。 TrueFoundry は、サーバーレスの生産性(簡単なデプロイ、スケーリング)を維持しつつ、そのデメリットを解消するように設計されています。簡単なデモで、AIワークロードをTrueFoundryに移行することで、速度を犠牲にすることなくコストを大幅に削減できることをお見せできます。
Vercel AI Gatewayは、 無料枠を提供しています。Vercelの各チームアカウントには、 毎月5ドルのAI Gatewayクレジット が、最初のリクエストを行った時点で付与されます。この無料クレジットは、Vercelを通じてLLMを試すために無期限で利用できます(30日ごとに更新されます)。それを超えると、従量課金制に移行し、追加のクレジットを購入する必要があります。この5ドルのクレジットはゲートウェイの使用料のみであり、 プラットフォーム上でのファンクションの計算費用や帯域幅の費用は 含まれません。これらはアカウントのプランに基づいて別途請求されます。
VercelのHobbyプランは、 無料 で利用できます。 Pro プランは 開発者1シートあたり月額20ドルからで、加えて従量課金制のアドオンが適用されます。実際には、3人の開発者からなる小規模チームの場合、基本料金として月額約60ドルを支払うことになります。より多くの機能(SSO、稼働保証など)が必要な場合、Enterpriseティアは年間で5桁の料金からとなります。これらの基本料金に加えて、Vercelの利用料金体系に基づき、追加のGB時間、エッジリクエスト、データ転送に対して料金が発生します。
この 20ドルプラン はVercelの Proティア (「Proアカウント」と呼ばれることもあります)を指し、ユーザーあたり月額20ドルです。Hobbyの全機能に加え、チームコラボレーションツールとより高いクォータが含まれています。例えば、Proには月間1TBのエッジ帯域幅と、関数用のより大きなGB時間割り当てが含まれます。Proチームがこれらのクォータを超過した場合、追加の使用量にはVercelの超過料金が適用されます。要するに、20ドルプランはプロフェッショナルチーム向けの(無料のHobbyティアを超える)エントリーレベルの有料プランです。
Vercelのプラットフォームには、AIアプリに影響を与えるいくつかの制約があります。デフォルトでは、サーバーレス関数は すぐにタイムアウトします (Hobby/Proでは60~300秒)。AI応答のストリーミングは完全なアクティブ時間としてカウントされるため、長いクエリは高額になります。同時実行数とリクエストペイロードサイズ(最大4.5MBのボディ)には厳格な制限があります。また、Vercelは GPUをサポートしていません、そのため、重いモデル推論はプラットフォーム外で実行する必要があります。AI Gateway自体には月額5ドルの無料クレジットしかなく、それを超えるとトークンに対してプロバイダーの定価を支払うことになります。実際には、Vercelを利用するチームは、予期せぬ504エラー、GB時間に対する高額な請求、そしてVercelのエッジ環境に過度に依存するとアーキテクチャのロックインが発生すると報告しています。これらの理由から、高度なAIワークロードはVercelでは限界に達することが多く、TrueFoundryのようなプラットフォームへの移行を促しています。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


