













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
この度、Resemble AIとTrueFoundry AI Gatewayの統合を発表いたします。これにより、音声クローン、同期型テキスト読み上げ、ストリーミングTTSが、チームがLLM、埋め込み、エージェントトラフィックにすでに使用しているのと同じゲートウェイパスに組み込まれます。
TrueFoundryのAI Gatewayを介してAIトラフィックをルーティングしているチームは、ゲートウェイのネイティブSDKパススルーを介して、Resemble AIをファーストクラスのテキスト読み上げプロバイダーとして接続できるようになりました。Resembleの/synthesizeエンドポイントおよび/streamエンドポイントへのリクエストは、一元化された認証、チームごとのアクセス制御、統合されたコスト追跡、および完全なリクエストトレースを備えたゲートウェイパスを介して流れます。ResembleのベースURLをゲートウェイに向け、TrueFoundryトークンで認証する以外に、クライアントコードの変更は必要ありません。
この記事では、この統合のアーキテクチャについて説明します。TrueFoundry AI GatewayがTTSプロバイダーをどのように公開するか、パススルーレイヤーを介してResembleのネイティブAPIサーフェスがどのように保持されるか、そして複数のTTSプロバイダー間でのフェイルオーバーが仮想モデルを介してどのように機能するかを解説します。
TrueFoundry は、本番AIシステムの制御レイヤーを提供します。AI Gatewayを介して、チームはLLM、埋め込み、画像、音声プロバイダー全体で、モデルルーティング、キー管理、アクセス制御、可観測性、コスト追跡を一元化します。すべてのリクエストは、IDが検証され、レート制限が適用され、トレースがキャプチャされる単一のプロキシレイヤーを介して流れます。
本番環境におけるTTSトラフィックは、3つの点でLLMトラフィックと似ています。単一のTTSベンダーがすべての側面で優れているわけではないため、通常、複数のプロバイダーが使用されます。音声エージェントがリアルタイムでユーザーに音声をストリーミングするため、レイテンシーが重要です。コストは文字ごとまたは秒ごとに急速に増加し、チームがチャット補完にすでに適用しているのと同じチャージバックおよび予算管理の恩恵を受けます。LLMプロバイダーの前にゲートウェイを置くことの利点は、そのまま当てはまります。
Resemble AI は、音声、動画、画像にわたる合成メディアの作成、検証、検出のための完全な生成AIセキュリティプラットフォームです。Resembleは、生成と検出の両方に対応する独自の基盤モデルも構築しており、AI生成コンテンツの識別において強力な優位性をもたらします。音声生成の場合、そのコア合成モデルはChatterbox、Chatterbox Multilingualであり、低レイテンシーとパラ言語タグサポートのためのChatterbox Turboバリアントも提供しています。Resembleが開発したすべてのTTSモデルには、 ウォーターマーク がデフォルトで搭載されています。このプラットフォームは、音声クローン、音声デザイン、オーディオ編集、SSMLおよびHD合成、ストリーミング出力もサポートしています。これら2つのプラットフォームを組み合わせることで、チームはAIスタックの他の部分と並行して、音声生成を管理および追跡するための一元的な場所を得ることができます。TrueFoundryはデプロイ、ルーティング、運用制御を処理し、Resembleは実際の合成を処理します。この統合は、TrueFoundryのネイティブSDKパススルーを使用しており、Resembleの完全なAPIサーフェスをOpenAI互換の形式に強制することなく保持します。

Resembleの同期型テキスト読み上げエンドポイントは、少数のフィールドを受け取り、タイミングメタデータとともに音声を返します。/synthesizeエンドポイントは、使用するトレーニング済みまたは事前構築済みの音声を選択するvoice_uuidと、最大3000文字のテキストまたはSSMLを含むdataフィールドを受け入れます。オプションフィールドでは、model(例:chatterbox-turbo)を介したモデル選択、precision(MULAW、PCM_16、PCM_24、PCM_32のいずれか)を介したオーディオ精度、output_format(wavまたはmp3)を介した出力形式、サンプルレート、use_hdを介したHDモード、およびapply_custom_pronunciationsを介したカスタム発音処理を制御します。
レスポンスペイロードは、成功と、合成されたオーディオバイトを含むbase64エンコードされたaudio_contentフィールドを返します。タイミングメタデータは、リップシンクやキャプションなどのダウンストリームのアライメントユースケースのために、書記素文字と書記素時間、音素文字と音素時間を含むaudio_timestampsで提供されます。レスポンスには、duration(音声の長さ(秒))、synth_duration(生の合成時間)、output_format、sample_rate、および合成中にシンセサイザーが検出した問題も報告されます。
/streamにある2番目のエンドポイントは、最初のオーディオチャンクまでの時間が重要な音声エージェントのユースケース向けに、HTTP経由でのストリーミング合成をサポートします。リクエストの形式は同じです。レスポンスは、単一のbase64ペイロードではなく、オーディオフレームのストリームです。両方のエンドポイントの認証には、Resembleアカウントコンソールから発行されたベアラートークンを使用します。
TrueFoundry AI GatewayはHonoフレームワーク上で動作し、単一のゲートウェイポッドは、1 vCPUと1 GB RAMで、約3ミリ秒の追加レイテンシーで毎秒250以上のリクエストを処理します。ゲートウェイポッドはステートレスでCPUバウンドであり、追加のポッドによって水平方向に数万RPSまでスケールします。コントロールプレーンとゲートウェイプレーンは分離されています。資格情報、ルーティングルール、レート制限を含むプロバイダー設定はコントロールプレーンに存在し、NATSを介してゲートウェイポッドに同期されます。実際のリクエストパスは、プロバイダー呼び出し自体以外の外部呼び出しなしでメモリ内に保持されます。
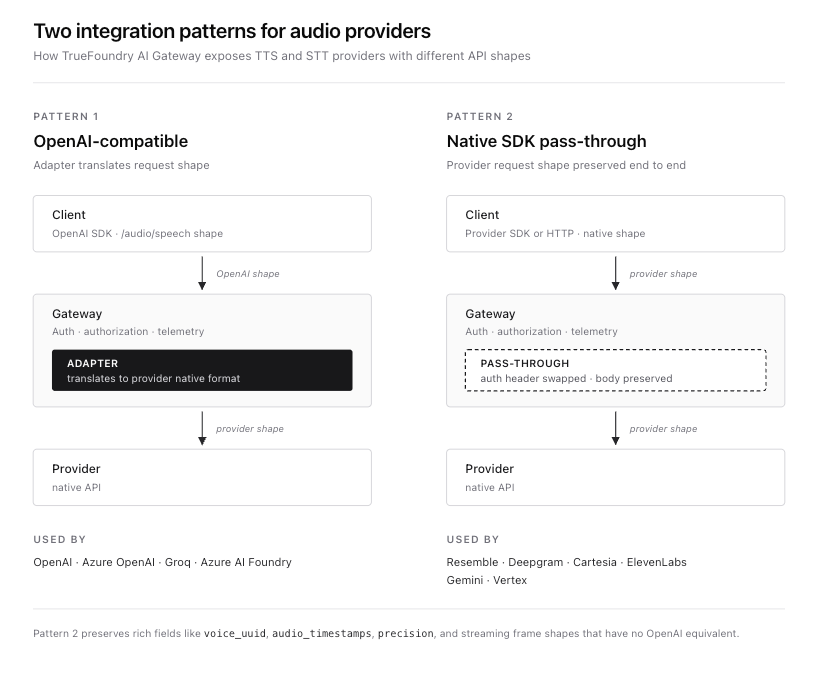
TTSの場合、ゲートウェイは2つの統合パターンを公開します。
最初のパターンは OpenAI互換API ゲートウェイのベースURLでのパターンです。OpenAIの/audio/speech形式に対応するプロバイダー(OpenAI、Azure OpenAI、Azure AI Foundry、Groq)はここに接続されます。クライアントは標準のOpenAI SDKを使用し、ゲートウェイはアダプター層を介してリクエストをプロバイダーのネイティブ形式に変換します。
2つ目は、 ネイティブSDKパススルー {GATEWAY_BASE_URL}/tts/{providerAccountName}でのパターンです。OpenAIの形式にきれいにマッピングできない豊富なネイティブAPIを持つプロバイダーはここに接続されます。プロバイダーの完全なリクエストおよびレスポンス形式は保持されます。ゲートウェイは認証、アクセス制御、トレース、ルーティングを処理しますが、ペイロードを書き換えません。Resembleは、voice_uuid、audio_timestamps、精度レベル、chatterbox-turboモデルセレクターを含むResembleのリクエストボディがOpenAI TTS契約に相当するものを持たないため、このパターンを使用します。
リクエストがゲートウェイポッドに到達すると、パスは次のようになります。Authorizationヘッダー内のTrueFoundryトークンは、キャッシュされたIdP公開鍵に対して検証されます。チームIDはインメモリマップに対して解決され、Resembleプロバイダーアカウントへの認証がチェックされます。リクエストボディは、Resembleベアラートークンがサーバー側で添付された状態で、Resembleの合成またはストリームエンドポイントに転送されます。レスポンスはクライアントにストリーミングで返されます。完全なインタラクションは、モデル名、プロバイダーアカウント、入力文字数、レスポンス時間、合成時間、レイテンシーとともにトレーススパンにキャプチャされます。実際のプロバイダー呼び出し以外に余分なラウンドトリップはありません。
Resembleは、Resembleベアラートークンがシークレットとして保存されたプロバイダーアカウントとして、TrueFoundryコントロールプレーンに登録されます。アカウントが追加されると、ゲートウェイは2つのTTSルートを公開します。{GATEWAY_BASE_URL}/tts/{providerAccountName}/synthesizeにあるネイティブSDKルートは、同期エンドポイントにプロキシします。{GATEWAY_BASE_URL}/tts/{providerAccountName}/streamにあるストリーミングルートは、ストリーミングエンドポイントにプロキシします。どちらのルートもResembleのリクエストおよびレスポンス形式を正確に保持します。
最小限のクライアント呼び出しは以下のスニペットのようになります。直接Resembleを呼び出す場合との唯一の違いは、ベースURLと認証ヘッダーであることに注意してください。
curl -X POST {GATEWAY_BASE_URL}/tts/resemble-prod/synthesize \ -H "Authorization: Bearer ${TFY_API_KEY}" \ -H "Content-Type: application/json" \ -d '{ "voice_uuid": "55592656", "data": "Hello from the gateway.", "model": "chatterbox-turbo", "output_format": "mp3", "use_hd": false }'Resembleを直接ターゲットとする既存のアプリケーションコードは、ベースURLとベアラートークンを交換することで移行できます。音声UUID、SSMLペイロード、精度設定、HDモードはすべて変更なしで引き継がれます。Resembleの公式クライアントライブラリも、ベースURLを上書きすることで同様に設定できます。
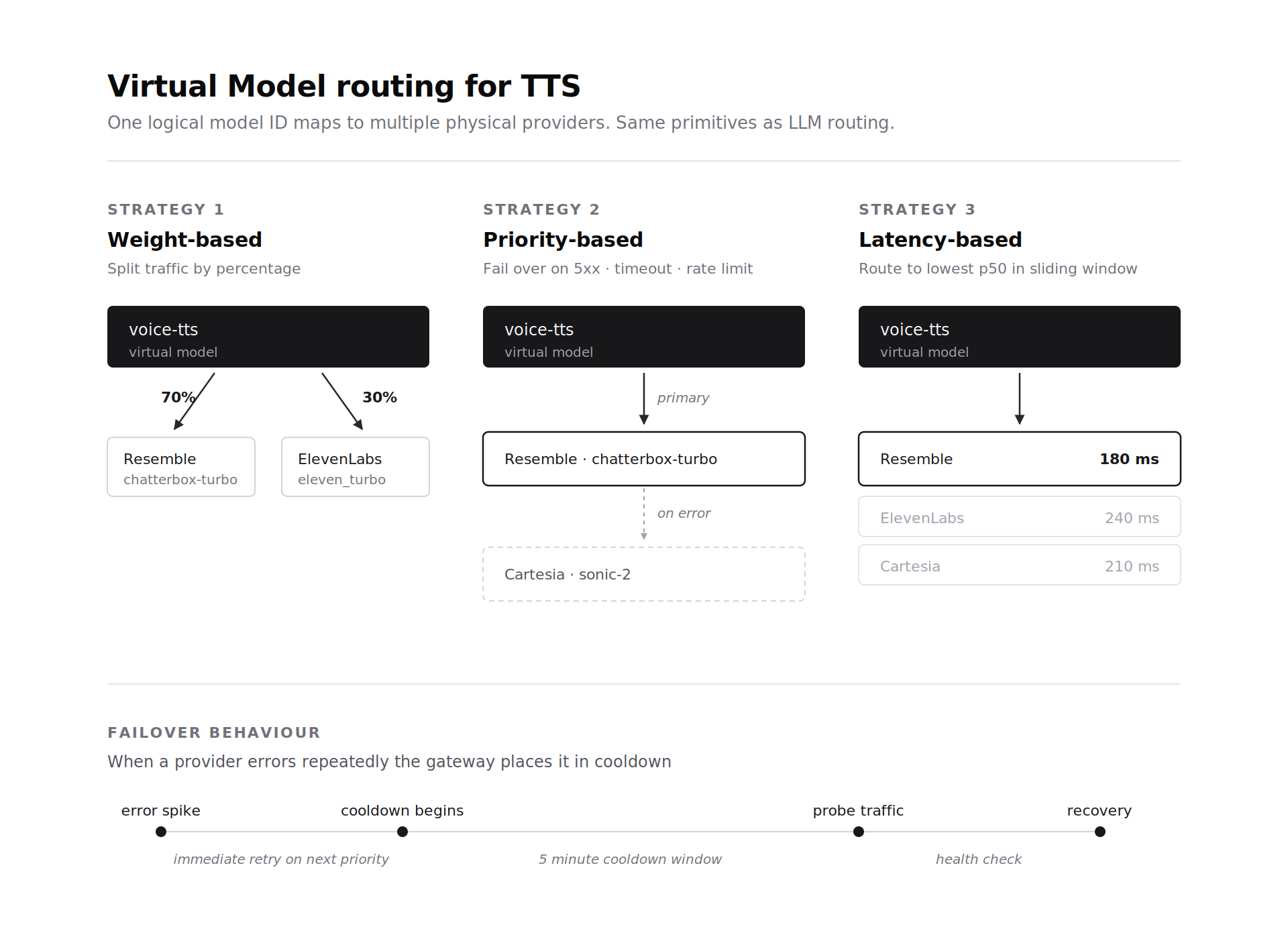
音声エージェントスタックは、コストとレイテンシーの理由から、本番環境で複数のTTSプロバイダーを実行することがよくあります。ゲートウェイの仮想モデル抽象化は、LLMプロバイダーと同様にTTSプロバイダーにも適用されます。仮想モデル識別子は、ルーティングルールを持つ1つ以上の物理TTSデプロイメントにマッピングされます。 重みベースの ルーティングは、プロバイダー間でトラフィックを割合に基づいて分散します。 優先度ベースの ルーティングは最初のプロバイダーを試行し、5xxエラー、タイムアウト、またはレート制限が発生した場合にフェイルオーバーします。 レイテンシーベースの ルーティングは、スライディングウィンドウ内でp50レイテンシーが最も低いプロバイダーにトラフィックを送信します。
TTSのフェイルオーバーは、LLMのフェイルオーバーと同じプリミティブで機能します。再試行不可能なエラーは、次の優先プロバイダーでの即時再試行をトリガーします。エラーの急増はプロバイダーを5分間のクールダウン状態にし、プローブトラフィックが回復をチェックします。Resemble Chatterbox Turboを主要な低レイテンシーパスとして実行しているチームは、クライアントコードを変更することなくCartesiaまたはElevenLabsにフェイルオーバーできます。仮想モデルが選択を処理します。
コスト追跡は、LLMの使用状況と同じ粒度でTTSの使用状況をキャプチャします。ゲートウェイは、各リクエストに対して入力文字数、合成時間、モデル、チーム、ユーザーを記録します。アグリゲーターサービスは、チームごとおよびユーザーごとの支出を計算し、チャット補完と埋め込みをすでにカバーしているのと同じダッシュボードと予算強制プリミティブにフィードします。レート制限は、ユーザー、チーム、またはモデルにスコープされた1分ごとのウィンドウを持つスライディングウィンドウトークンバケットアルゴリズムを介して適用されます。TTSの場合、単位はトークンではなく文字またはリクエストですが、アルゴリズムは変更されません。
すべてのTTSリクエストはトレーススパンを出力します。スパントリビュートには、プロバイダーアカウント、モデル識別子(例:resemble-prod/chatterbox-turbo)、入力文字数、応答時間(秒)、生の合成時間、出力形式、サンプルレート、ゲートウェイ側のレイテンシーが含まれます。トレースはNATSを介して非同期に発行され、OTEL経由でチームが設定した任意の可観測性バックエンド(Arize、Langfuse、LangSmith、またはサポートされているターゲットのいずれか)にエクスポートされます。「リクエストデータを除外」トグルは、データプライバシーが必要な場合に、チャット補完の場合と同様に、入力テキストがエクスポートされたトレースに含まれないように適用されます。
これにより、TTS呼び出しは、テキストを生成したアップストリームのLLM呼び出しや、音声を消費したダウンストリームのエージェントアクションと同じトレースタイムラインに表示されます。音声エージェントのデバッグにおいて、この統合は重要です。失敗したターンは、応答を選択したLLM補完から、それをレンダリングしたTTS合成を経て、エージェントが次に行ったアクションまでトレースできます。
エンドツーエンドのリクエストフローは次のようになります。クライアントは、TrueFoundryベアラートークンを使用して、{GATEWAY_BASE_URL}/tts/{providerAccountName}/synthesize またはそのストリーミング版にTTSリクエストを送信します。ゲートウェイは、キャッシュされたIdPキーに対して呼び出し元を認証し、プロバイダーアカウントを解決し、メモリ内でチームとユーザーの認証を確認します。仮想モデルが使用されている場合、ルーティングロジックは重み、優先度、またはレイテンシーに基づいて物理プロバイダーを選択します。リクエストボディは、サーバー側のResembleベアラートークンを付けてResembleに転送されます。応答は、オーディオコンテンツ、タイムスタンプ、期間メタデータを含むResembleのペイロード形状全体を保持したまま、クライアントにストリーミングで返されます。すべてのステップは、NATSに非同期で発行され、OTEL経由でエクスポートされるトレーススパンにキャプチャされます。
アプリケーションで他に何も変更する必要はありません。SDKの書き換えは不要で、クライアント側でのプロバイダーごとの認証処理も不要、音声トラフィック用の個別の可観測性パイプラインも不要です。ゲートウェイはすでにAIスタックの他の部分のリクエストパスにあり、Resembleはそのパスにネイティブなパススルーを介して接続します。既存のResembleクライアントコードは、ベースURLを交換するだけで引き続き機能します。
このクリーンな設計を可能にするアーキテクチャ原則は、デュアル統合パターンです。OpenAIコントラクトに対応するプロバイダーは、OpenAI互換アダプターを介して接続し、同じクライアントSDKを再利用します。豊富なネイティブAPIを持つプロバイダーは、パススルー経路を介して接続し、翻訳を強制することなくプロバイダーの全機能を保持します。TTSの場合、プロバイダー間の違いは表面的なものではないため、これは重要です。音声UUID、オーディオタイムスタンプ形式、精度レベル、ストリーミングフレーム形状は、OpenAIスタイルのアダプターでは平坦化せざるを得ないような形で異なります。パススルーパターンは、ResembleのChatterboxモデル選択、オーディオタイムスタンプ、精度制御をそのまま維持しつつ、ゲートウェイが認証、ルーティング、可観測性、コスト追跡といった横断的な懸念事項を処理します。
詳細については、 TrueFoundry AI Gateway と Resemble AI platformをご覧ください。ゲートウェイコントロールプレーンでResembleをプロバイダーアカウントとして追加し、既存のアプリケーションコードから、/tts/{providerAccountName} ルートにある synthesize または stream エンドポイントを呼び出します。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


