













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
OpenCodeのようなAI支援型コーディングツールは、開発者がコードと対話する方法を根本的に変えます。これらのシステムは、個々のスニペットを操作するのではなく、ファイル、依存関係、履歴コンテキスト全体で推論します。その結果、生産性は大幅に向上しますが、多くのチームが見過ごしがちな新たなコストとスケーラビリティの課題も生じます。 トークン使用量。
予測可能なライセンス費用がかかる従来の開発ツールとは異なり、OpenCodeの使用量はトークンベースの料金体系によって管理されます。すべてのインタラクション、コード生成、リファクタリング、デバッグ、レビューにおいてトークンが消費されます。チームが開発者、リポジトリ、自動エージェント全体で利用規模を拡大するにつれて、トークン消費量が主要なコスト要因となります。
これを特に厄介にしているのは、トークン使用量がしばしば 直感的ではないことです。コンテキストサイズ、プロンプト構造、エージェントの動作におけるわずかな変更が、トークン消費量の大幅な変動につながる可能性があります。トークンがどのように使用されるかについて明確なメンタルモデルがなければ、チームはコストを予測したり、ワークフローを最適化したり、ガードレールを適用したりするのに苦労します。
このブログでは、OpenCodeにおけるトークン使用量の仕組みを技術的なレベルで解説し、コード関連のワークロードが特にトークンを大量に消費する理由、そしてプラットフォームチームが本番環境での使用を拡大する前に理解しておくべきことについて説明します。
根本的に、OpenCodeのトークン使用量は、ほとんどのLLM搭載システムと同じメカニズムに従います。 トークンは入力と出力の両方で消費されます。しかし、コーディングワークロードの性質上、さらなる複雑さが加わります。

OpenCodeのトークン使用量は、大きく2つのカテゴリに分けられます。
OpenCodeでは、プロンプトトークンには通常、以下が含まれます。
完了トークンには以下が含まれます。
コストの観点から見ると、 プロンプトトークンが主要な要因となることがよくあります OpenCodeの使用において、特にリポジトリやコンテキストサイズが大きくなるにつれて。
コード関連のタスクは、自然言語クエリとは大きく異なる動作をします。トークン消費量が増加する要因はいくつかあります。
チャットベースのユースケースとは異なり、OpenCodeはしばしば以下を送信します。
複数のファイルが含まれる場合、「小規模な」コードベースであっても、すぐに数万から数十万トークンに相当する量になります。
ソースコードは密度が高いです。構文、インデント、記号、書式設定のすべてがトークンとしてカウントされます。数千行のコードは、同量のプレーンテキストよりもはるかに多くのトークンを消費する可能性があります。
OpenCodeのワークフローでは、しばしば以下が含まれます。
各ステップでコンテキストや中間出力が再送信される可能性があり、1つのタスクにおけるトークン使用量を増加させます。
OpenCodeがエージェントや自動化を介して使用される場合(例えば、複数のファイルにわたるリファクタリングやCIパイプラインでの実行など)、トークン使用量は急速に増加します。
エージェント主導の利用は強力ですが、制限を設けないとコストがかさむ可能性があります。
OpenCodeのトークン使用量における最大の課題の一つは、 開発者がモデルに送信されている完全なコンテキストをほとんど見ることがない点です。エディタやツールは、以下の情報を抽象化しています。
その結果、一見似ている2つのタスクでも、トークンフットプリントは大きく異なる可能性があります。リクエストレベルでの明示的な追跡がなければ、チームは使用量が急増した後になって初めてコストの問題に気づくことがよくあります。
だからこそ、トークンの仕組みを理解するだけでは不十分です。チームには、 タスクごと、開発者ごと、ワークフローごとの実際のトークン消費量の可視性 を把握し、情報に基づいた最適化の決定を下す必要があります。
トークン使用量を理解することは、あらゆるAI搭載アプリケーションにとって重要ですが、開発者、エージェント、エンタープライズプラットフォーム全体でAIの導入が拡大するにつれて、特に重要になります。トークン消費量を監視し最適化することで、組織はコストを管理し、効率を向上させ、予測可能なAI支出を維持することができます。
OpenCode、Claude CodeなどのAIコーディングアシスタントや類似ツールは、大規模なコードベース、広範なコンテキストウィンドウ、複数ターンの会話を頻繁に処理します。開発者が一日を通してこれらのツールとやり取りするにつれて、トークン消費量は急速に増加する可能性があります。
トークン使用量を追跡することで、エンジニアリングチームは以下のことが可能になります。
AIエージェントは、計画、推論、ツール使用、情報検索、コード生成などを含む複雑なワークフローを実行することがよくあります。これらの多段階のやり取りは、従来のチャットアプリケーションよりも著しく高いトークン使用量を生成する可能性があります。
トークン消費量を監視することで、チームは以下のことが可能になります。
エージェントの導入が拡大するにつれて、予測可能な運用コストを維持するためにトークンの可視性が不可欠になります。
大規模な組織では、複数のチーム、製品、事業部門にわたってAIアプリケーションを頻繁に導入しています。一元的な可視性がなければ、トークンがどのように消費され、どこでコストが増加しているかを理解することは困難になります。
組織はトークン監視を利用して、以下のことを行います。
AIの導入が拡大するにつれて、トークン使用量はレイテンシー、信頼性、モデルパフォーマンスと並んで重要な運用指標となります。トークン消費量を積極的に監視し最適化する組織は、コストを抑えながらAIワークロードを効率的に拡張できる有利な立場にあることがよくあります。
OpenCodeのトークン使用量のほとんどの急増は、単一の明白な間違いによって引き起こされるものではありません。それらは、実際のエンジニアリングワークフローでOpenCodeがどのように使用されているか、特にツールやエージェントが開発および自動化パイプラインに深く統合されている場合に発生します。
Below are the most common scenarios that disproportionately increase token consumption.
One of the biggest contributors to high token usage is overly broad context inclusion. Many OpenCode workflows include entire directories or large subsets of a repository to “be safe,” even when only a small portion of the code is relevant.
Examples include:
Because prompt tokens scale linearly with context size, this pattern alone can multiply costs quickly.
OpenCode often operates iteratively: generate code, review, adjust, regenerate. In many setups, each iteration resends the full context, including files and previous outputs.
This leads to:
Without caching or intelligent context reuse, iteration becomes one of the most expensive patterns.
When OpenCode is used via agents or automated workflows, token usage can escalate rapidly if execution is not explicitly bounded.
Common causes include:
Because these processes often run in the background, teams may not notice runaway usage until costs spike.
Refactoring and review tasks tend to be more token-intensive than code generation because they require:
When these tasks are applied across large codebases or multiple pull requests, token usage increases significantly.
OpenCode usage embedded into CI pipelines or automation workflows introduces a different risk profile. These systems:
Even modest per-run token usage can become expensive when multiplied across many builds or deployments.
Finally, one of the most overlooked drivers of high token usage is the absence of visibility. When teams cannot see:
Optimization becomes guesswork. Teams often respond by restricting usage globally, rather than addressing the specific workflows that drive costs.
Once teams understand where token usage comes from, the next step is optimization. Importantly, optimization is not about limiting usage arbitrarily, it’s about using tokens intentionally so that productivity gains don’t turn into uncontrolled costs.
Below are practical best practices that consistently reduce OpenCode token usage without degrading output quality.
The most effective optimization lever is controlling what context is sent to the model. More context is not always better, especially when it’s irrelevant.
Practical techniques include:
A good rule of thumb: if a file is not required to reason about the change, it should not be part of the prompt.
Instead of sending large amounts of code upfront, teams should move toward on-demand retrieval.
Examples:
This approach reduces prompt size while often improving reasoning quality, since the model receives more targeted information.
Generic prompts tend to encourage broader reasoning and larger outputs, which increases both prompt and completion tokens.
Better patterns:
Task-scoped prompts not only reduce token usage but also improve determinism.
Agent-based workflows amplify token usage if left unchecked. Every agent should operate within clearly defined limits.
Key guardrails include:
Without these bounds, agents can unintentionally reprocess large contexts multiple times, driving up usage.
Many OpenCode workflows repeat similar tasks across iterations or users. Caching can significantly reduce redundant token consumption.
Applicable scenarios:
Even partial caching at the workflow level can yield meaningful savings.
While prompt tokens often dominate, completion tokens matter too, especially in refactoring or explanation-heavy workflows.
Techniques include:
明確な出力制約により、不要な冗長性が削減されます。
最終的に、最適化は事後対応的であるべきではありません。チームはトークン使用量を計測する必要があります 初日から。
最低でも、以下の項目を追跡する必要があります。
このデータがなければ、チームは生産的な使用と無駄を区別することができません。
ほとんどのチームは、OpenCodeのトークン使用量で最初から苦労することはありません。問題は、使用が開発者、リポジトリ、自動化されたワークフロー全体に広がるにつれて徐々に顕在化します。個人の生産性向上ツールとして始まったものが、すぐに共有インフラとなり、トークン使用量は予測や管理が困難な形で拡大していくのです。
大規模になると、OpenCodeはもはやエディタで一人の開発者によって使用されるだけではありません。以下のような主体によって使用されます。
これらの各利用者は、個別にトークン使用量を発生させます。一元的な可視性がなければ、以下のような基本的な質問に答えることが困難になります 誰がトークンを使用しているのか、 どのような目的で、そして どのくらいのコストで。
初期の最適化の取り組みは、カスタムプロンプトの制限、コンテキストのトリミング、リトライロジックなど、多くの場合、アプリケーションまたはツールレベルで実装されます。これらは局所的には役立ちますが、以下のような場面ではスケールしません。
その結果、ポリシーは断片化され、一貫性がなくなります。あるチームは積極的に最適化を進める一方で、別のチームは知らず知らずのうちにコストを押し上げてしまいます。
自動化によって状況は一変します。1回の実行で控えめな数のトークンを消費するワークフローも、以下のような場合に高価になる可能性があります。
これらのジョブは人間の直接的な監視なしで実行されるため、非効率性は急速に蓄積されます。トークン使用量の急増は、インタラクティブな使用よりも自動化に起因することがよくあります。
きめ細かな帰属がなければ、チームは集計された使用量しか把握できません。これにより、最適化は場当たり的で鈍いものになります。
一般的な失敗パターンは次のとおりです。
効果的な管理には、 どのワークフローが価値を生み出し、どのワークフローが無駄を生み出しているかを把握することが不可欠ですが、 これは集計された指標からは明らかになりません。
多くの組織では、AIツールの導入ペースがガバナンスの整備を上回っています。OpenCodeの利用は、以下の状況よりも早く広まります。
トークン使用量が懸念事項になる頃には、ツールはすでにワークフローに深く組み込まれており、後付けの管理は困難で、混乱を招きます。
根本的な問題は誤用ではなく、 中央集権的な管理を伴わない分散的な利用です。. OpenCodeが共有インフラとなるにつれて、トークン使用量は、チームがコンピューティング、ストレージ、CIリソースを管理するのと同じ方法で管理される必要があります。
これには以下が必要です。
この転換がなければ、トークンの使用量は予測不能なままであり、最適化の取り組みも後手に回ってしまいます。
OpenCodeの使用量が本番環境の規模に達すると、場当たり的な追跡や手動での最適化は機能しなくなります。この段階では、トークン使用量は他の共有インフラリソースと同様に扱われる必要があります。 継続的に測定され、一元的に管理され、所有者に紐付けられるべきです。.
多くのチームは、個々のツールやワークフロー内でトークン使用量を追跡することから始めます。これは局所的な洞察を提供しますが、次のような場合にすぐに破綻します。
各統合は使用量を異なる方法で報告し、全体像を提供しません。その結果、プラットフォームチームはトークン消費に関する信頼できる唯一の情報源を欠いています。
大規模な場合、監視は リクエストレベルで行われる必要があり、ツールレベルだけではありません。効果的な設定では、以下を捕捉します。
これにより、チームは次のような疑問に答えることができます。
この粒度がなければ、最適化の取り組みは粗く、しばしば見当違いなものになるでしょう。
ガバナンスは帰属から始まります。トークンの利用状況は、それに対して行動できる所有者に紐付けられる必要があります。
一般的な帰属モデルには以下が含まれます。
所有権が明確になれば、コストに関する議論は、抽象的な予算編成から、どのワークフローが十分な価値を提供しているかについての具体的な意思決定へと移行します。
モニタリングだけではコスト超過を防ぐことはできません。本番システムには 強制メカニズム リアルタイムで機能するものが求められます。
一般的なガードレールには以下が含まれます。
これらの制御は一元的に適用され、OpenCodeを利用するすべてのワークフローが自動的にそれらを継承するようにすべきです。
効果的なガバナンス体制に共通する要素は 一元化。トークンの利用ポリシー、制限、可視性は、ツールごとに再実装されるのではなく、共有の制御ポイントで管理される必要があります。
こうした状況で、インフラ志向のプラットフォーム、例えば TrueFoundry が自然に適合します。AIトラフィック、可観測性、ポリシー適用を一元化することで、プラットフォームチームは、個々のチームの速度を落とすことなく、開発者、エージェント、自動化システム全体でOpenCodeトークンの利用状況を一貫して管理できます。
AIの導入が進むにつれて、トークンの利用状況を追跡し、制御することがますます重要になります。個々の開発者はトークンの消費を手動で管理できることが多いですが、複数のアプリケーション、チーム、モデルを運用する組織では、通常、一元的な可視性とガバナンスが必要です。
手動での監視は小規模なデプロイメントでは機能しますが、AIワークロードが拡大するにつれて、支出の追跡、非効率性の特定、利用制御の適用が困難になることがよくあります。AIゲートウェイは、組織全体でトークンの利用状況を監視し、コストを管理し、モデルの利用を最適化するための一元的なレイヤーを提供します。
プラットフォームの観点から見ると、OpenCodeトークンの利用における核心的な課題は、 どのように トークンが消費されるか、ということではなく、 制御と可視性がどこに存在すべきか。
TrueFoundryは、AIおよびLLMの利用(OpenCodeのような開発者向けツールを含む)を、デフォルトで可観測性、ガバナンス、コスト意識を備えているべき共有インフラストラクチャとして扱うことでこの問題に取り組みます。このアプローチの中心にあるのは AI Gateway。これは組織全体のLLMトラフィックの制御プレーンとして機能します。
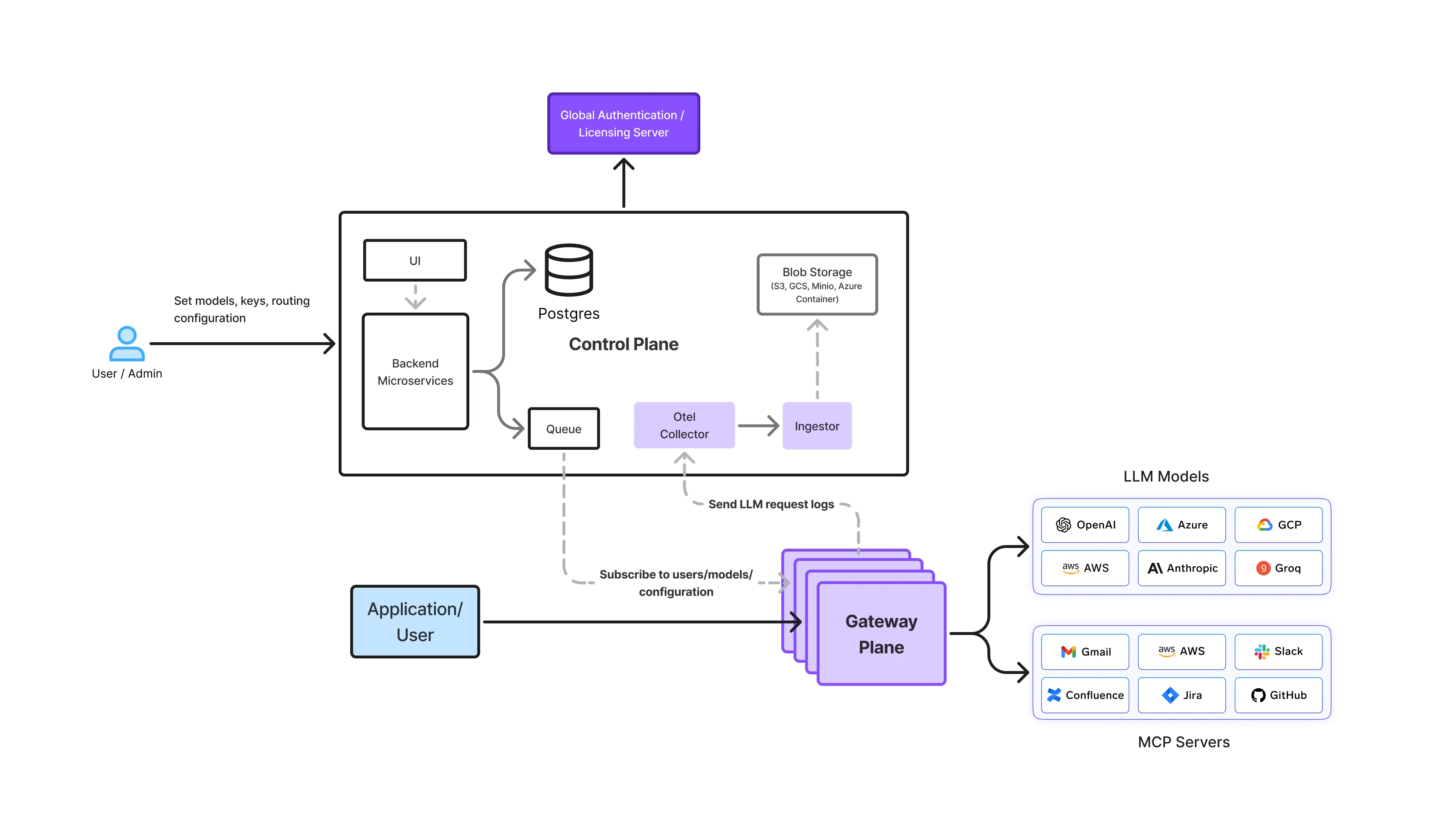
TrueFoundryのセットアップでは、OpenCodeは基盤となるLLMプロバイダーと直接やり取りしません。その代わりに、すべてのリクエストはAI Gatewayを介して流れ、AI Gatewayは推論のための単一で一貫したインターフェースを提供します。
アーキテクチャ的には、これにより以下のことが可能になります。
個々のツールからモデルへの直接アクセスをなくすことで、プラットフォームチームは開発者、エージェント、自動化全体でOpenCodeが実際にどのように使用されているかを完全に可視化できます。
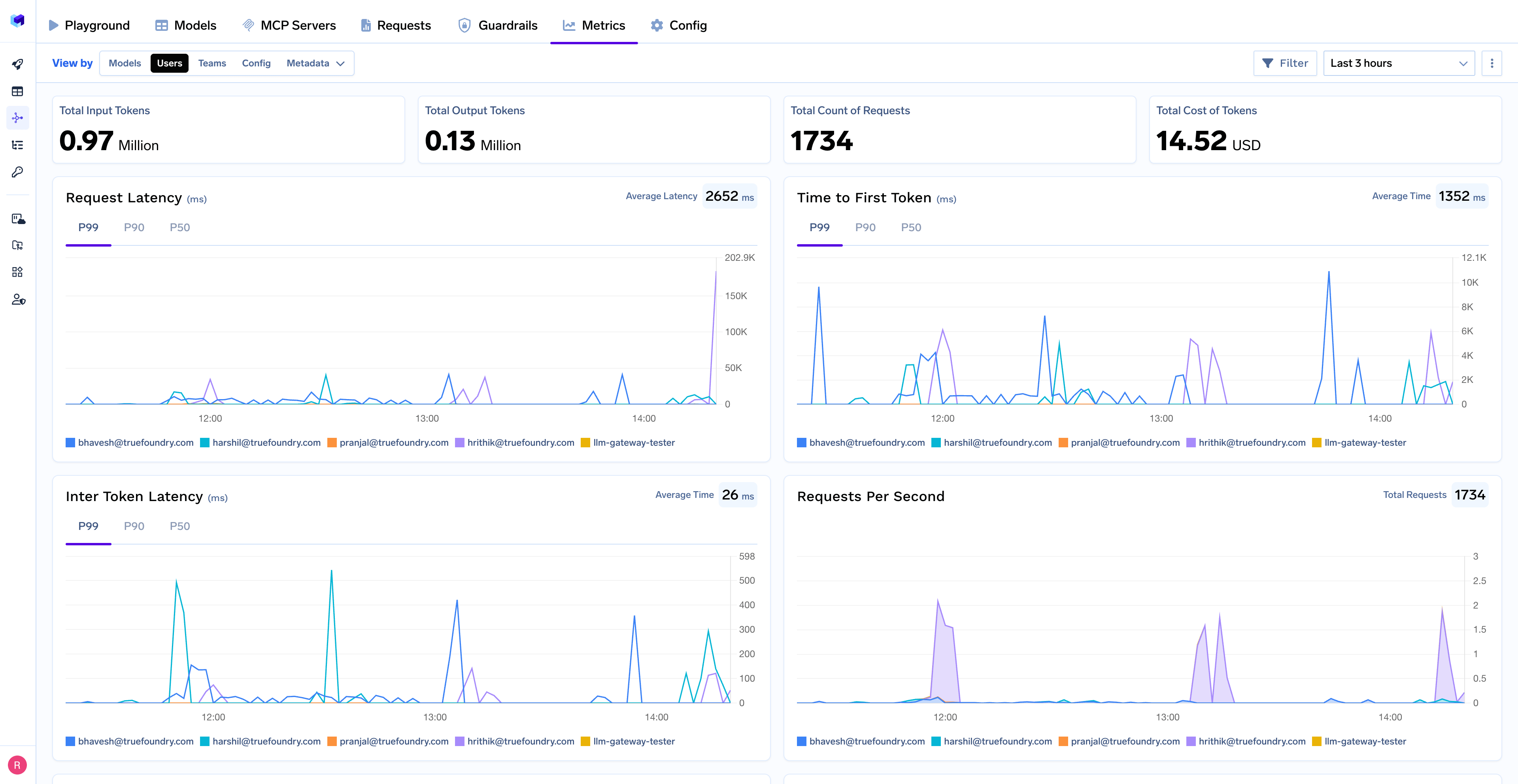
TrueFoundryのAI Gatewayは、 リクエストレベルでのトークン使用量を捕捉します。内訳は以下の通りです。
重要なことに、このテレメトリーはベンダー管理システムにロックされません。ログとメトリクスは顧客自身のクラウドとストレージに永続化され、これによりチームは以下のことが可能になります。
これにより、AIツールによくある「ブラックボックス」問題を回避し、長期的な最適化が可能になります。
すべてのOpenCodeトラフィックがゲートウェイを通過するため、コスト管理を適用できます 一貫してリアルタイムで.
プラットフォームチームは以下を実行できます:
これらのポリシーはゲートウェイで一度適用されると、エディター、プラグイン、または内部ツールに変更を加えることなく、すべてのOpenCodeを活用したワークフローに自動的に適用されます。
TrueFoundryのアーキテクチャは、OpenCodeの使用がIDEを超えて広がる環境向けに設計されています。CIパイプライン、バックグラウンドジョブ、およびエージェントは、しばしば最大かつ最も見えにくいトークン消費を生成します。
これらのワークロードを同じAIゲートウェイ経由でルーティングすることで、チームは以下を実行できます:
これにより、予測可能性や制御を失うことなく、組織全体でOpenCodeの使用をスケールすることが可能になります。
OpenCodeのトークン使用量は、AI支援型コーディングにおける真のスケーリング上の制約です。開発者、リポジトリ、自動化、エージェント全体に利用が広がるにつれて、一元的な可視性とガバナンスがなければ、トークン消費量の予測と制御は困難になります。
これをツールやアプリケーションレベルで管理することは、スケーラビリティがありません。トークン使用量には、リクエストレベルでの可観測性、明確な帰属、リアルタイムでの強制力が必要です。AI支援型コーディングは、孤立した機能ではなく、共有インフラとして扱うべきです。
のようなプラットフォームは TrueFoundry AIゲートウェイを通じてOpenCodeのトラフィックを一元化することで、このアプローチを反映しており、チームはトークン使用量を一貫して監視、管理、最適化できます。プラットフォームおよびエンジニアリングリーダーにとっての教訓はシンプルです。OpenCodeがソフトウェア構築の中核であるならば、トークン使用量は他の重要なインフラリソースと同様の厳格さで管理されなければなりません。
OpenCodeのトークン使用量を正確に確認するには、リクエストレベルでの明示的な追跡と計測が必要です。ツールはモデルに送信される完全なコンテキストを抽象化することが多いため、タスク、開発者、ワークフローごとの実際のトークン消費量を可視化することは、コストを予測し、使用量を効果的に最適化するために不可欠です。
OpenCodeのトークン使用量とは、OpenCodeのようなAI支援型コーディングツールにおけるトークンベースの料金モデルのことです。入力プロンプトやコードコンテキストから、生成されたコードや説明に至るまで、すべてのインタラクションがトークンを消費します。このOpenCodeのトークン使用量を管理することは、米国の開発チームにとって主要なコスト要因となるため、非常に重要です。
OpenCodeのトークン使用量を削減するには、コンテキストの注入を必要不可欠なファイルのみに限定し、広範なリポジトリを含めることを避けてください。イテレーション間で出力をインテリジェントに再利用することで、コンテキストの繰り返し再構築を防ぎます。複雑なタスクをより小さなステップに分解し、正確なプロンプトを使用してください。各タスクのトークン消費量を監視することは、コストと効率を最適化するための重要な洞察を提供します。
OpenCodeのトークン使用量を削減するには、プロンプトの長さを最適化し、不要なコンテキストを制限し、タスクに適したモデルを使用することが有効です。長いプロンプト、広範な会話履歴、過大なコードコンテキストは、トークン消費量を大幅に増加させる可能性があります。使用パターンを定期的に見直すことで、効率を向上させ、コストを削減する機会を見つけることができます。
OpenCodeでトークン使用量が増加する要因はいくつかあり、以下が含まれます。
これらの要因を理解することで、チームはAIの使用を最適化し、支出をより効果的に管理できるようになります。
組織は通常、一元化されたダッシュボード、分析ツール、またはAIゲートウェイプラットフォームを通じてトークン使用量を監視します。これらのソリューションは、ユーザー、チーム、アプリケーション、モデル全体にわたるトークン消費量の可視性を提供し、組織が支出を追跡し、異常を特定し、AI予算をより効果的に割り当てるのに役立ちます。
チームレベルでトークン使用量を監視することで、最適化の機会を特定し、予期せぬコスト増加を防ぐことも容易になります。
はい。AIゲートウェイは、使用パターンの可視化、予算とレート制限の適用、インテリジェントなモデルルーティングを可能にすることで、組織がトークン消費を最適化するのに役立ちます。
例えば、AIゲートウェイは、より単純なリクエストを低コストのモデルに自動的にルーティングし、より複雑なタスクにはプレミアムモデルを予約することができます。使用状況分析とガバナンス制御と組み合わせることで、これにより組織はパフォーマンスと信頼性を維持しながらAIコストを削減できます。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.







最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


