













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
AI systems are no longer passive tools. They are increasingly agentic - operating autonomously across workflows, APIs, and sensitive enterprise data. In traditional systems, data residency was defined by where data was stored. Once databases and storage lived in approved regions, compliance was considered solved.
Agentic AI breaks that model. Every interaction generates new data surfaces - prompts, agent memory, logs, traces, and transient inference data, that are processed and observed at runtime, often across regions, even when nothing is persisted.
As a result, data residency is no longer a compliance checkbox. It is a core infrastructure concern now discussed at the board level. The question enterprises must answer is simple: Where does AI-generated data move at runtime and who controls those paths?
In TrueFoundry, data residency is enforced at the AI Gateway, where inference, agents, and tools converge. Residency is treated as a system property, enforced under normal operation, failures, and scale. This blog explains how data residency is defined, enforced, and verified in the TrueFoundry AI Gateway.
Data residency was simpler when applications had predictable data paths. Requests flowed from users to services to databases, usually within a single region, and compliance controls were largely static.
AI systems break this model at runtime.
In modern AI architectures, data movement is dynamic and decision-driven, not fixed. A single user request can trigger multiple execution paths, all orchestrated by the AI Gateway. This is where data residency becomes fragile.
At runtime, an AI Gateway may:
Each of these decisions can introduce implicit data movement, often without the application being aware of it.
The most common data residency failures in AI systems occur:
Critically, these failures happen even when:
These failures all have one thing in common: they occur at runtime, driven by routing, retries, agent execution, and logging behavior.
The AI Gateway is the only layer that:
This is why data residency in AI systems cannot be guaranteed through deployment configuration alone. It must be enforced at the AI Gateway, where execution paths are decided in real time.
In platforms like TrueFoundry, residency is treated as a hard runtime constraint, not a best-effort preference ensuring that no execution path, including failure scenarios, can violate regional boundaries.
Agentic AI systems don’t just use data, they continuously generate new data surfaces at runtime. These surfaces did not exist in traditional applications, and they fundamentally change what data residency must account for.
In AI systems, data residency is no longer limited to data at rest. It extends to every piece of data created, processed, or observed during inference and agent execution, even if that data exists only briefly.
The most important of these new data liabilities are often the least visible.
Inference requests carry prompts and responses through the AI Gateway, frequently containing proprietary logic, customer data, or sensitive internal context. Unlike traditional APIs, this data is free-form and unsanitized, making it particularly high risk.
Agentic workflows introduce persistent context and memory across interactions. If this state is processed or replayed outside approved regions, residency is violated, even when individual inference calls appear compliant.
AI systems also generate logs, traces, embeddings, and execution metadata that can encode sensitive information. If observability pipelines export this data across regions, violations occur silently.
Crucially, data does not need to be stored to be non-compliant. Transient inference data, processed only in memory for milliseconds, still falls under residency requirements if it crosses a jurisdictional boundary.
Traditional residency controls were designed for static systems, not for dynamic routing, retries, failover, and agent-driven execution. In AI systems, residency must be enforced at runtime, where these data paths are created.
In platforms like TrueFoundry, this enforcement happens at the AI Gateway, where prompts, agent context, retries, and telemetry converge, making residency a system property rather than an assumption.
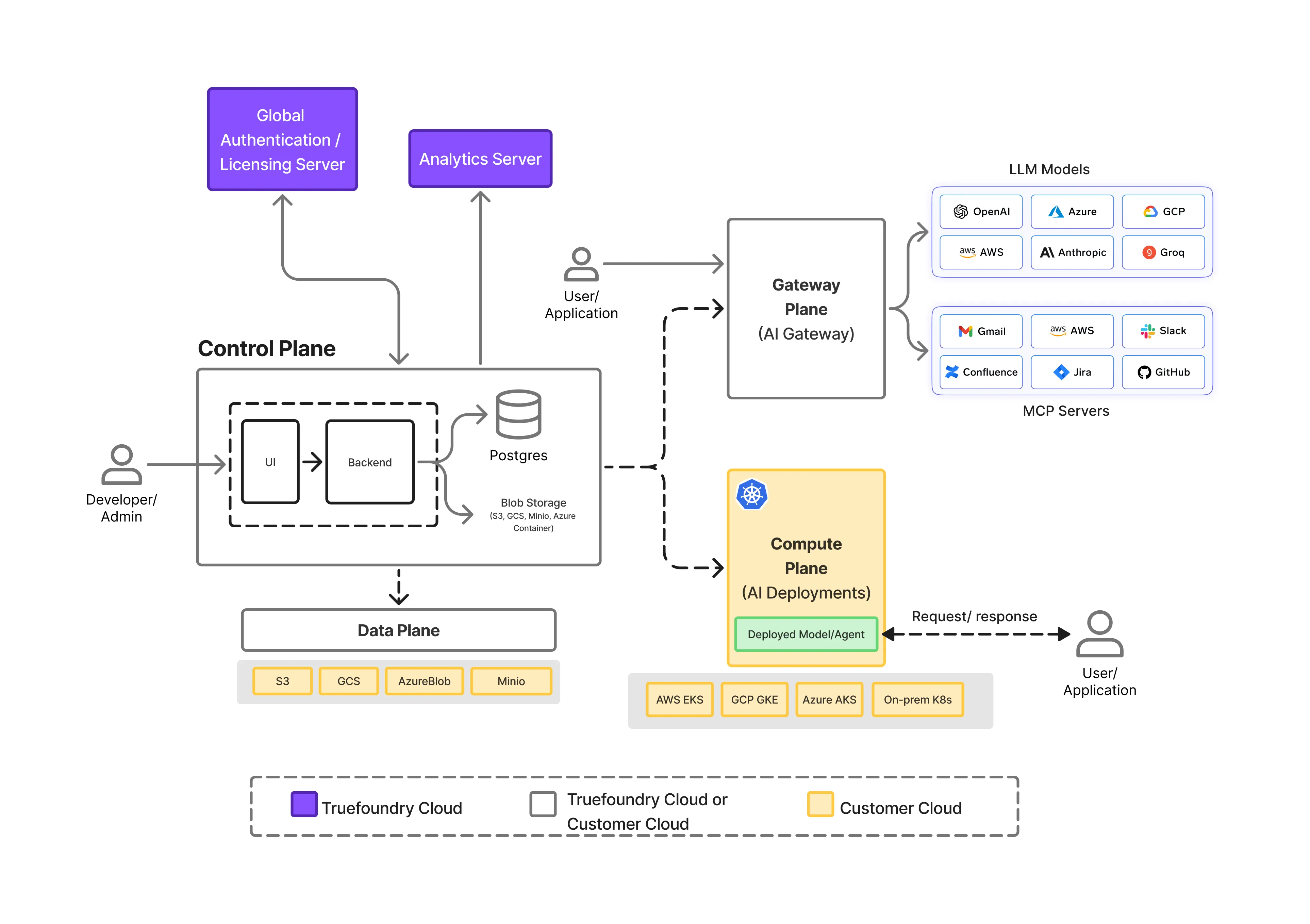
Enforcing data residency in AI systems requires more than regional deployment. It requires clear separation of responsibilities across the AI stack, so that execution, control, and data paths can be governed independently.
TrueFoundry is designed around a split-plane architecture that makes this possible.
At a high level, the platform is composed of three distinct planes:
This separation is foundational to how data residency is enforced reliably at runtime.
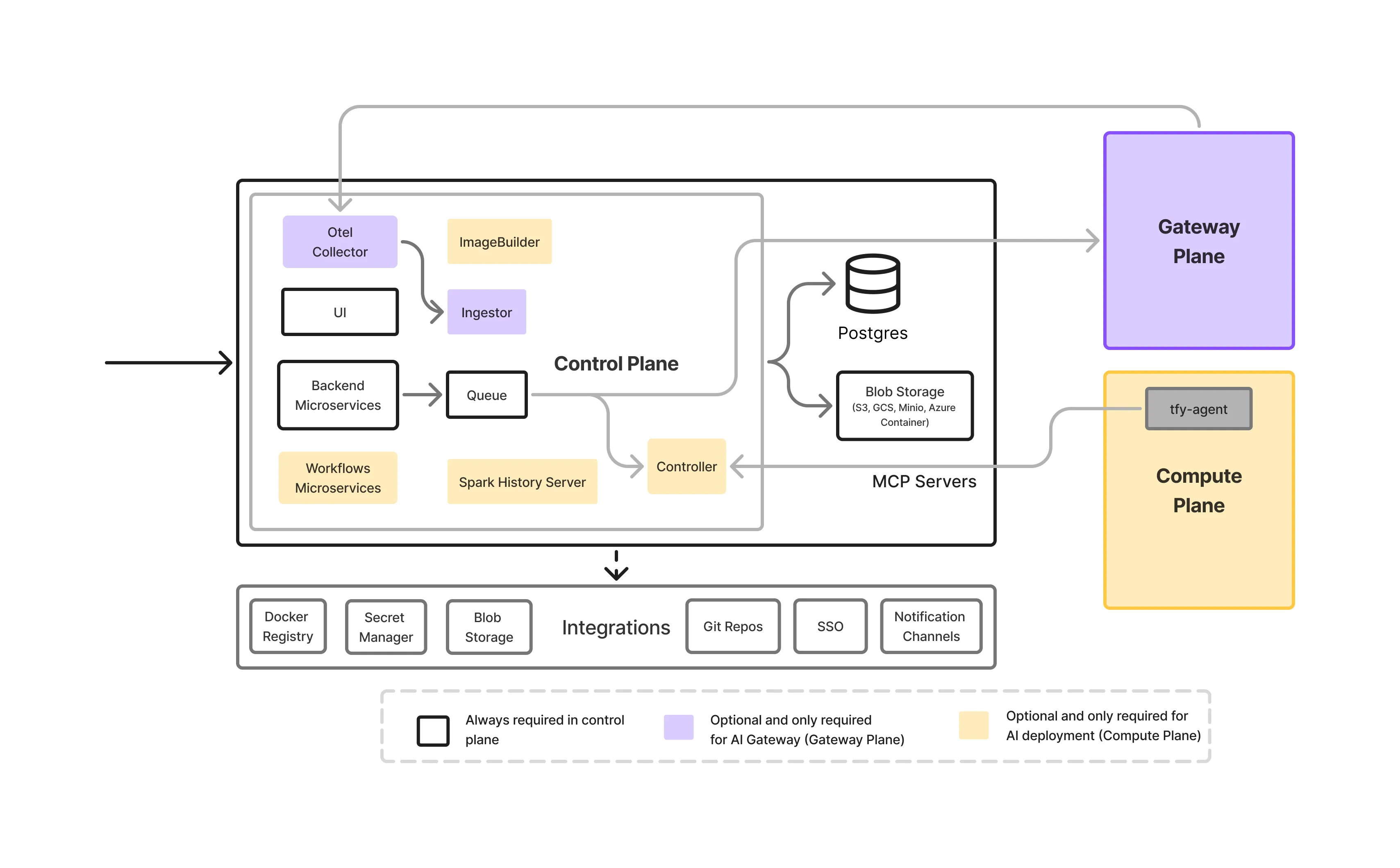
The control plane is the orchestration layer of the TrueFoundry platform. It is responsible for:
Critically, the control plane does not process inference traffic and does not execute workloads. It defines what should happen, not where data flows at runtime.
For enterprises with strict compliance requirements, TrueFoundry supports both:
This allows organizations to choose the appropriate balance between operational simplicity and sovereignty requirements, without changing how residency enforcement works downstream.
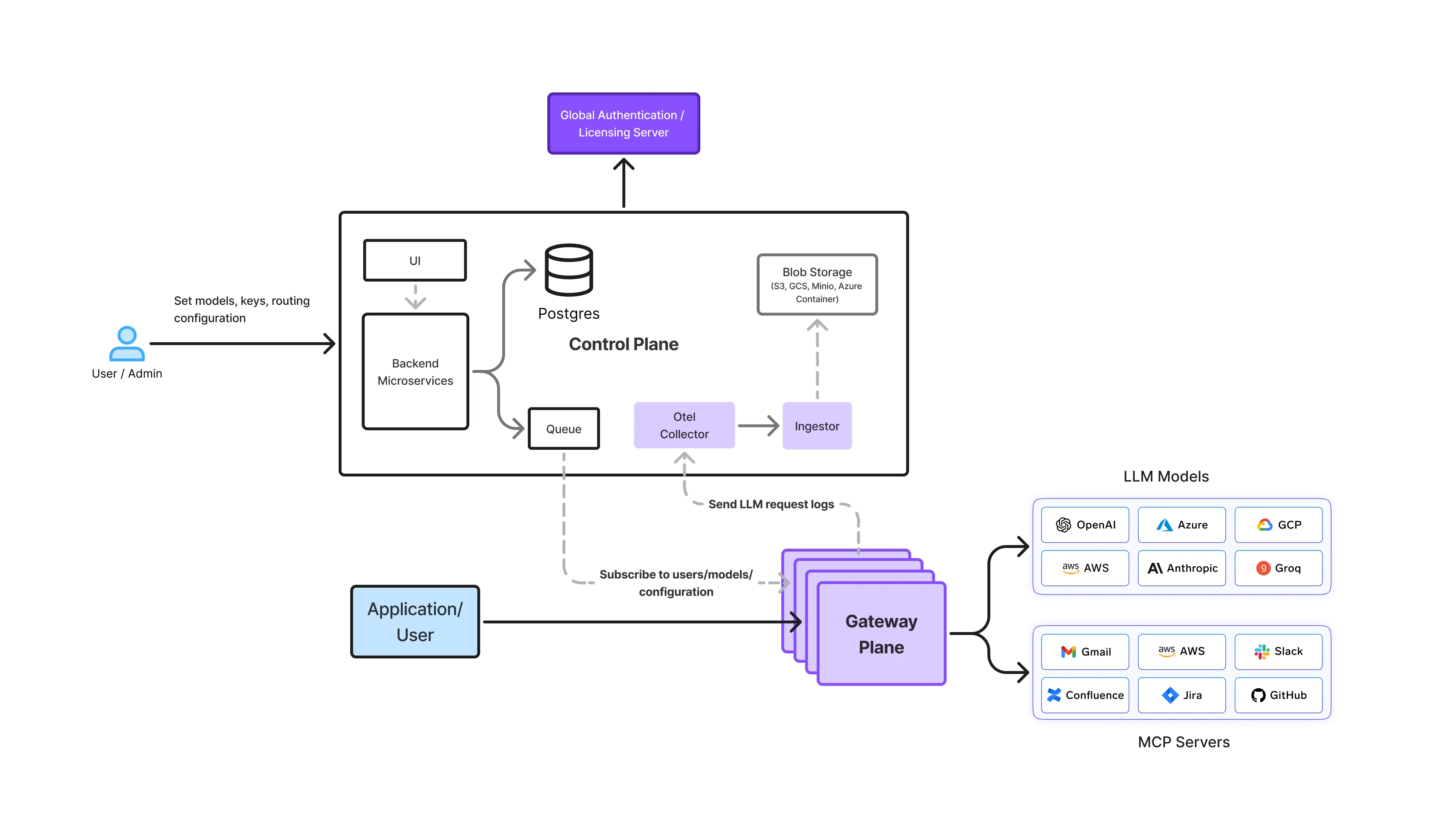
The gateway plane is where data residency is actively enforced.
TrueFoundry AI Gateways sit between applications and all model providers, acting as:
Every inference request, retry, failover, agent invocation, and observability event passes through the gateway. This gives it full visibility into:
Because of this, the gateway plane is the only layer capable of enforcing data residency as a hard constraint.
If a request cannot be satisfied within configured residency boundaries, the gateway fails the request closed rather than silently routing it to a non-compliant region.
This is the key difference between runtime enforcement and best-effort configuration.
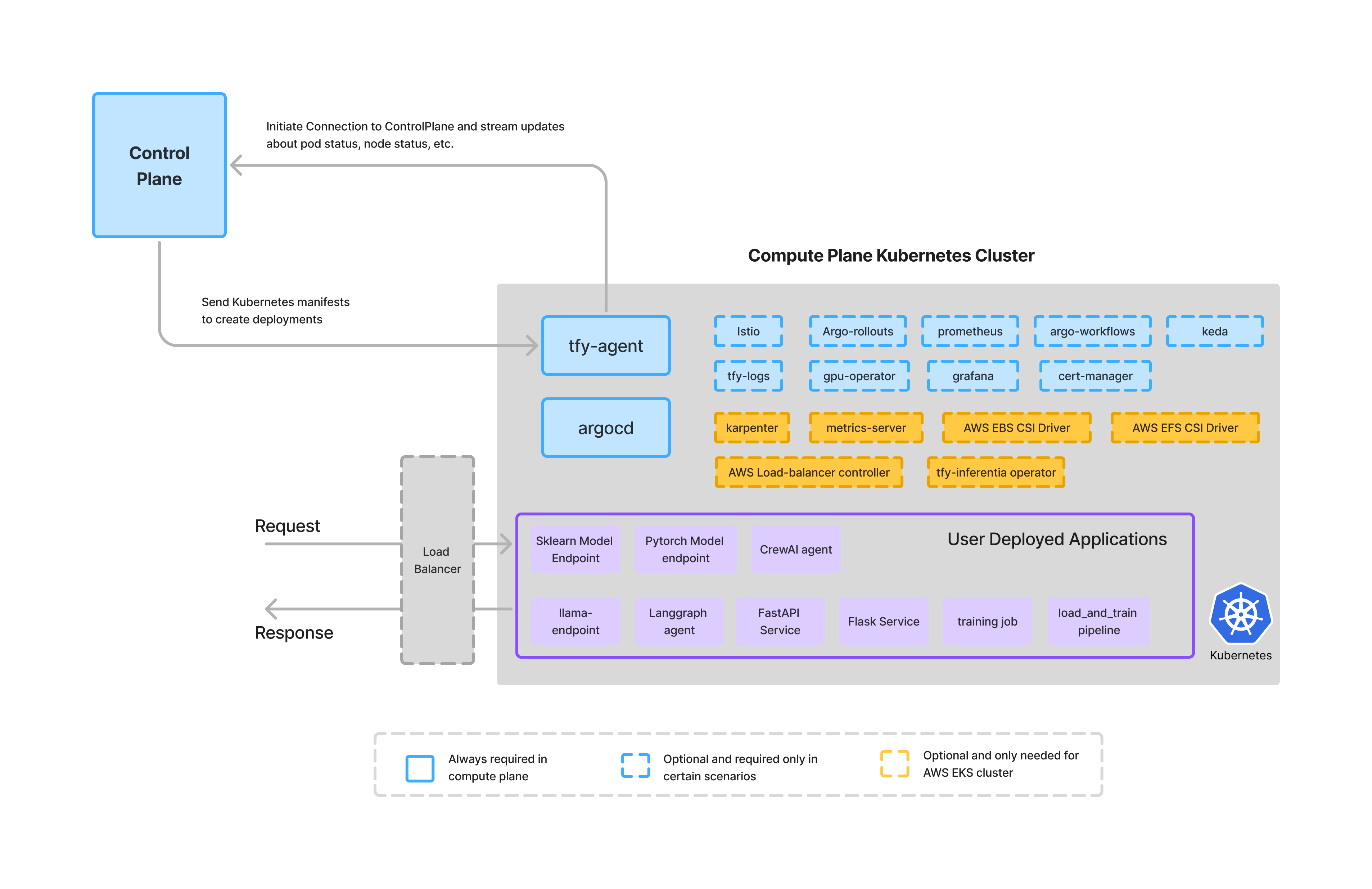
The compute plane is where applications, agents, and workloads actually run.
In TrueFoundry, the compute plane:
This design ensures that:
TrueFoundry does not execute customer workloads on shared compute. Instead, it integrates with the customer’s existing clusters or helps provision new ones, keeping execution firmly within the organization’s trust boundary.
This separation of planes enables TrueFoundry to enforce data residency without compromise:
Because enforcement happens at the gateway—where routing, retries, agents, and logs converge, data residency holds even under:
This is what allows data residency to become a system property, not an assumption tied to deployment diagrams.
Data residency in AI systems is not a single switch—it must be enforced across execution, routing, and storage. In TrueFoundry, this is achieved through three complementary enforcement modes that together cover the full lifecycle of AI data.
Each mode addresses a different class of residency risk and can be used independently or in combination, depending on enterprise requirements.
For organizations with the strictest residency and compliance needs, TrueFoundry enables a deployment model where data never leaves the customer’s environment.
In this mode:
This applies across both:
By ensuring that execution and data paths remain entirely within customer-controlled infrastructure, this mode provides the strongest possible residency guarantees and simplifies regulatory audits.
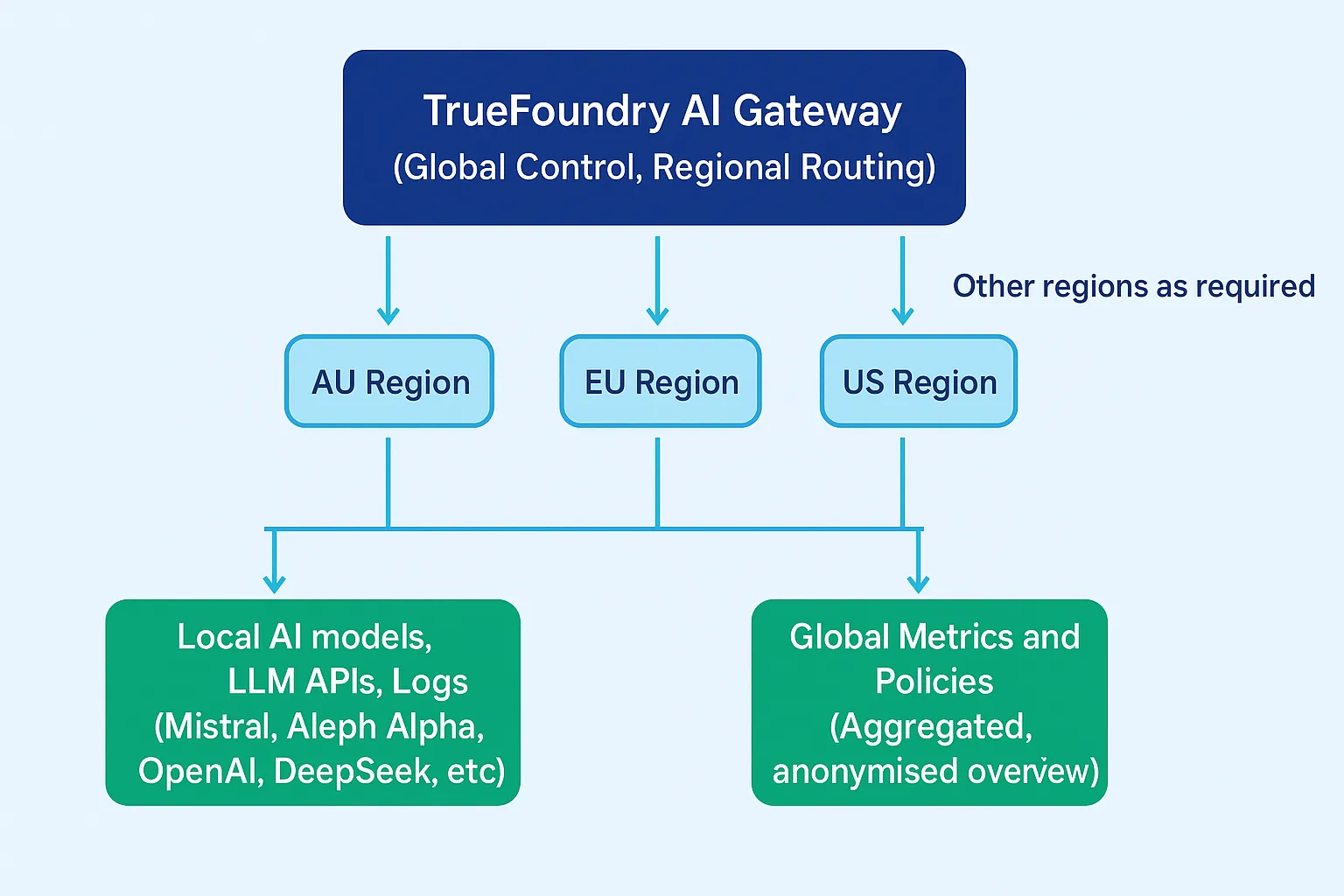
Many enterprises need to operate globally while ensuring that data for a given geography never crosses jurisdictional boundaries.
TrueFoundry enforces this through region-specific AI Gateway deployments:
Applications explicitly choose which regional gateway endpoint to use. This makes data residency:
If no residency-compliant execution path exists for a request, the gateway fails the request closed rather than routing it to another region. This ensures that availability mechanisms never override compliance intent.
Inference and execution are only part of the data residency story. Logs, traces, prompts, and telemetry often carry equally sensitive information and must follow the same residency rules.
TrueFoundry allows enterprises to enforce residency at the storage layer by:
This makes it possible to:
Because these storage choices are integrated directly into the AI Gateway and SDK configuration, observability data follows the same residency guarantees as inference traffic.
Each enforcement mode solves a different problem:
Together, they ensure that data residency is enforced:
This layered approach is what allows TrueFoundry to turn data residency from a best-effort configuration into a verifiable, runtime-enforced system property.
In TrueFoundry, data residency is enforced through multiple, explicit layers inside the AI Gateway, each addressing a different class of runtime risk.
These layers work together to ensure that residency guarantees hold under real-world conditions.
In AI systems, data residency guarantees only hold if they are enforced at runtime, across every execution path not just during steady-state operation. In TrueFoundry, the AI Gateway is the enforcement point where routing decisions, retries, agent execution, and observability converge.
The following mechanisms explain how data residency is enforced deterministically inside the TrueFoundry AI Gateway.
Models in TrueFoundry are registered with explicit region affinity. The AI Gateway evaluates residency constraints before routing any request and only selects model endpoints that are eligible for the workload’s allowed region.
This prevents:
Because residency is treated as a hard routing constraint, not a preference, non-compliant models are never considered—even if they are available or faster.
Retries and failover paths are the most common source of silent data residency violations in AI systems.
TrueFoundry’s AI Gateway enforces:
This ensures that availability mechanisms never override compliance intent. If a compliant path is unavailable, the system fails explicitly rather than routing data across regions.
For agentic workloads, data residency must remain consistent across model inference and downstream tool invocation.
TrueFoundry enforces:
This eliminates a common failure mode where inference remains compliant, but agents leak data indirectly through tools or MCP servers deployed in other regions.
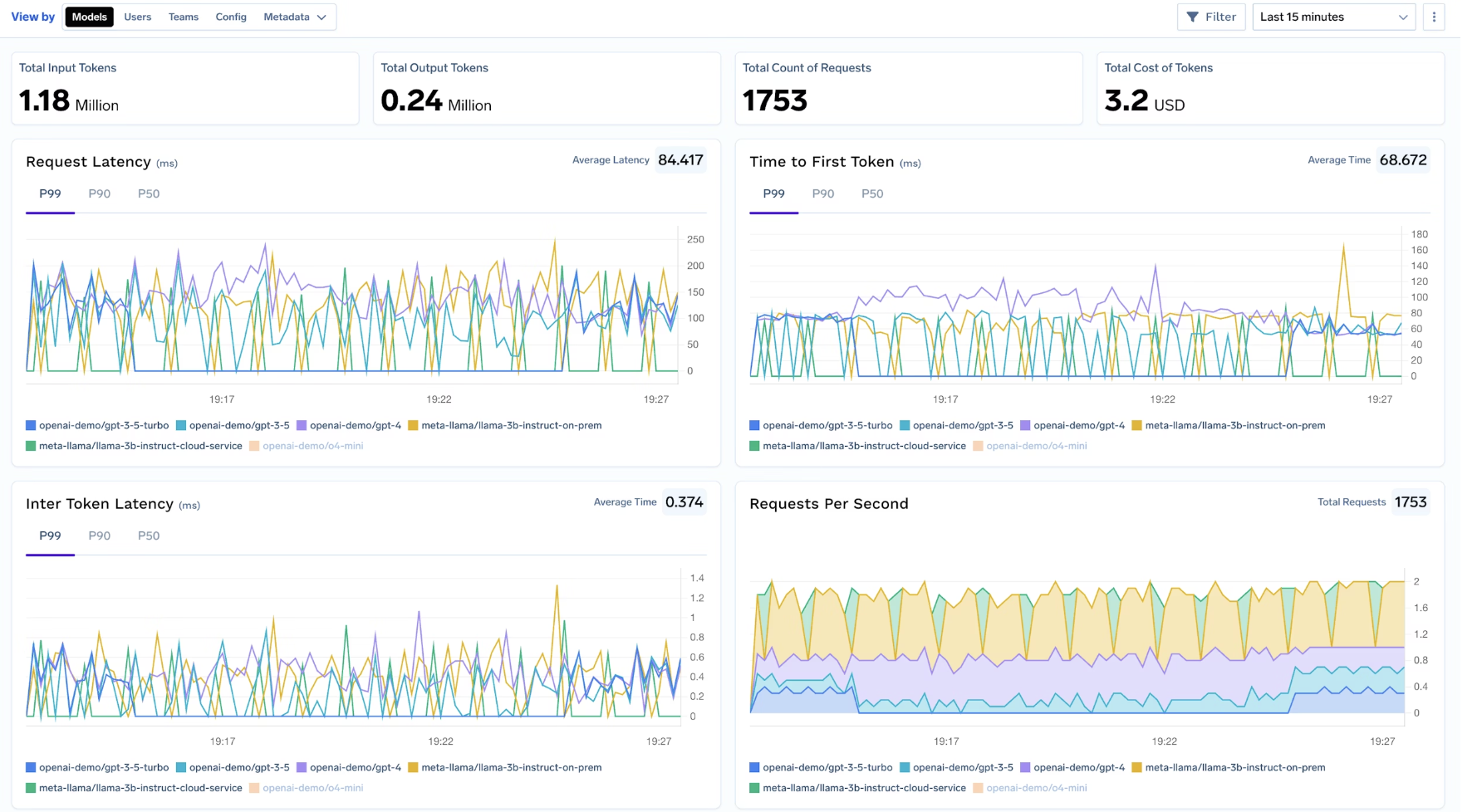
Observability pipelines are frequently overlooked in data residency designs, despite often containing highly sensitive data.
TrueFoundry’s AI Gateway ensures that:
This closes one of the most persistent residency gaps in AI systems, where inference is compliant but logs and traces are not.
These enforcement mechanisms apply uniformly across:
Because enforcement happens before execution, data residency becomes a verifiable system property, not a best-effort configuration tied to infrastructure placement.
Most data residency violations in AI systems are not caused by obvious misconfigurations. They emerge from edge cases and exception paths that are rarely tested until something goes wrong.
Below are the most common failure scenarios enterprises encounter and how the TrueFoundry AI Gateway is designed to prevent them.
What happens in many systems
A regional model endpoint becomes unavailable. The AI Gateway automatically retries or fails over to the next available endpoint often in another region.
From an availability standpoint, this looks like success.
From a compliance standpoint, it is a silent violation.
How TrueFoundry prevents this
This ensures that availability mechanisms never override residency policy.
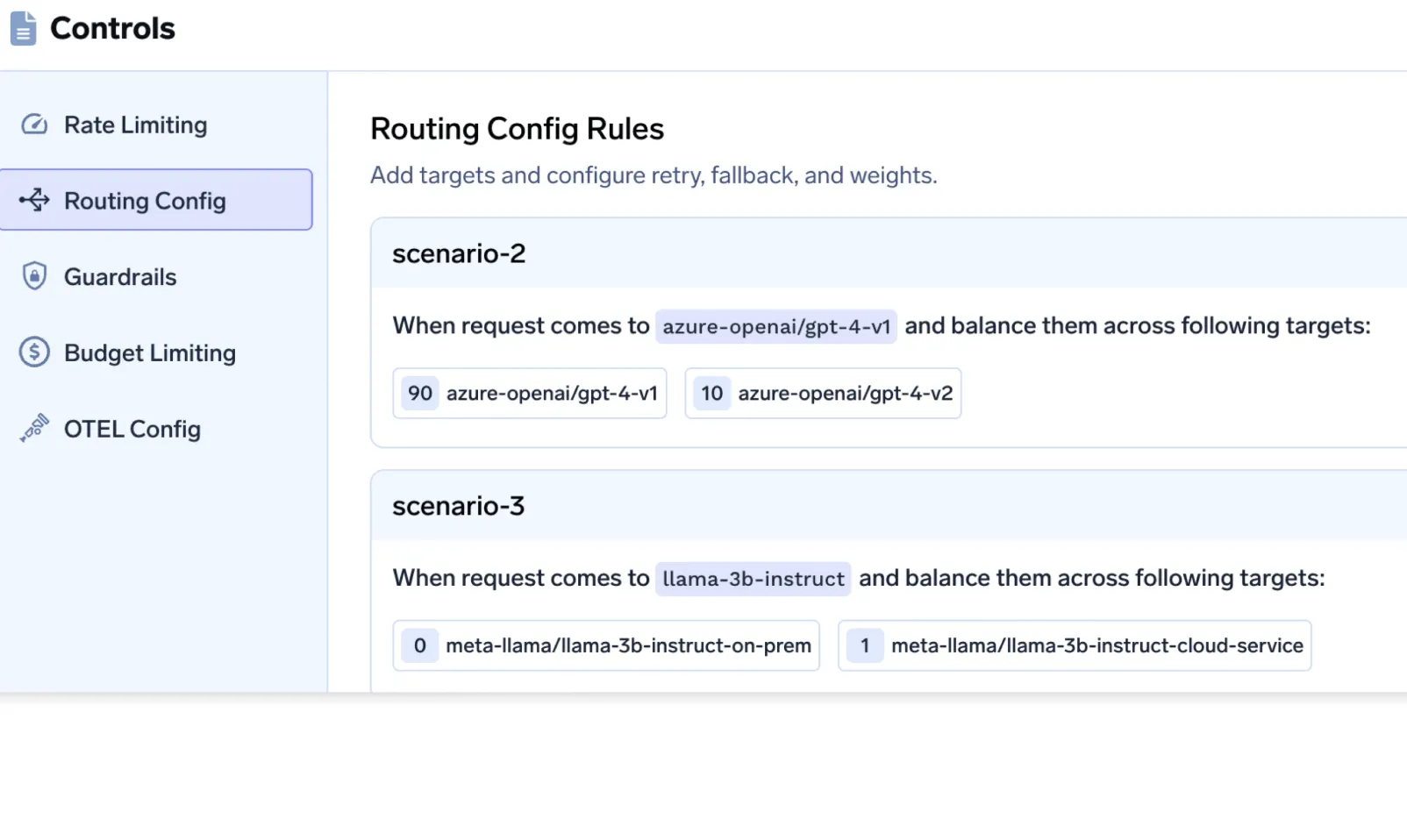
What happens in many systems
Some models are deployed in-region, while others (often backups or newer models) are globally hosted. Routing policies unintentionally select non-resident models.
How TrueFoundry prevents this
This makes residency guarantees resilient to model churn and experimentation.
What happens in many systems
Inference runs locally, but agents invoke tools or MCP servers deployed in other regions, creating indirect data movement.
How TrueFoundry prevents this
This keeps residency consistent across inference and downstream execution.
What happens in many systems
Prompts, responses, and traces are exported to centralized logging or monitoring services outside the region often by default.
How TrueFoundry prevents this
This closes one of the most frequently overlooked compliance gaps in AI systems.
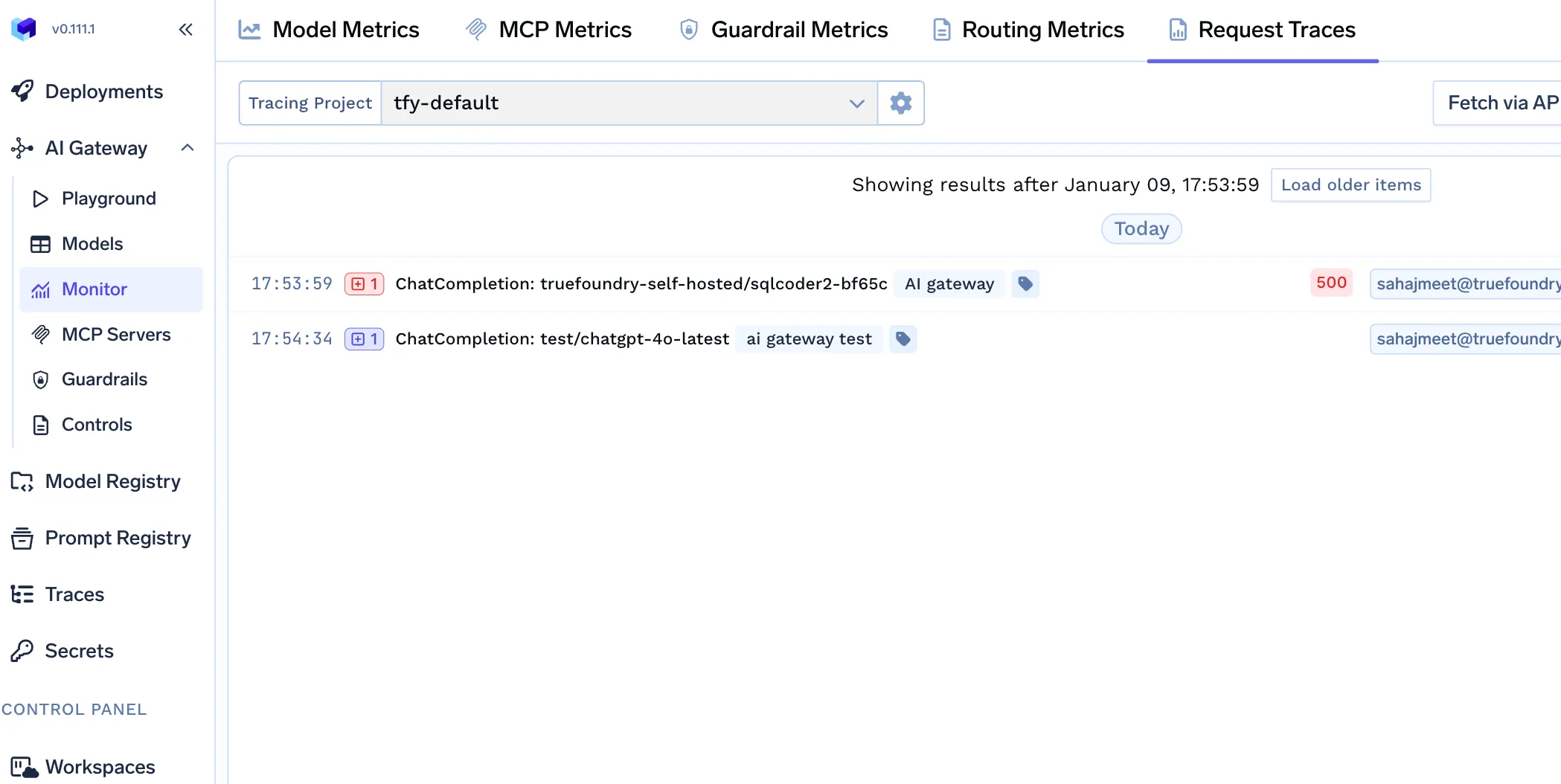
Residency guarantees are only meaningful if they can be verified and demonstrated. TrueFoundry enables enterprises to validate data residency through runtime visibility and auditability, not post-hoc assumptions.
The AI Gateway provides visibility into:
これにより、チームは以下のことを確認できます。 すべての実行パスがコンプライアンスに準拠していたこと.
コンプライアンスおよびセキュリティレビューのために、TrueFoundryは以下を提供します。
これにより、以下のことが可能になります。 監査中にレジデンシーを証明すること、アーキテクチャ図のみに頼るのではなく。
ゲートウェイレベルの強制の主な利点は、テスト可能性にあります。
企業は以下のことができます。
これにより、データレジデンシーは静的な要件から 継続的に検証可能なシステムプロパティへと変わります。
現代のAIシステムでは、データレジデンシーはデプロイメントの選択だけでは保証できません。動的ルーティング、リトライ、エージェントワークフロー、オブザーバビリティパイプラインはすべて、データが密かに地域境界を越える可能性のある実行パスを生み出します。
この AIゲートウェイ こそが、これを防ぐのに十分なコンテキストを持つ唯一のレイヤーです。AIゲートウェイは、すべての推論リクエスト、すべてのリトライ、すべてのエージェントアクション、そしてシステムによって発行されるすべてのトレースを把握しています。ここでレジデンシーが強制されない場合、他のどこでも一貫して強制することはできません。
TrueFoundry TrueFoundryでは、データレジデンシーは ランタイムシステムプロパティとして扱われます。実行パスは設計によって制約され、例外ケースはフェイルクローズし、実施状況は監視可能で監査可能です。これにより、レジデンシーの保証は、定常状態だけでなく、障害発生時、規模拡大時、変更時においても堅牢になります。
規制された環境やマルチリージョン環境でAIをデプロイする企業にとって、その違いは重要です。データレジデンシーはもはや単なるチェックボックスではなく、アーキテクチャ上のコミットメントです。そして、AIゲートウェイこそが、そのコミットメントが現実のものとなる場所です。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


