













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Healthcare, financial, and a few other sectors are deploying generative AI without ever touching the public internet. Air-gapped is not a configuration flag — it is an architecture where every dependency the system needs at runtime is already inside the enclave.
"Air-gapped" is not a marketing claim about the deployment shape. It is the deployment shape's foundational constraint. Everything else follows from "no route to the outside."
In a typical enterprise deployment, "isolated" means a private VPC, a NAT gateway, restricted egress, and an allowlist of approved external endpoints — package registries, model APIs, telemetry endpoints, identity providers. The system is segregated; it is not isolated. Egress exists, controlled but present. An auditor asking "what does the system phone home to?" gets a list of allowlisted destinations, not silence.
Air-gapped is a stronger claim. There is no NAT gateway. There is no DNS server that resolves external hostnames. There is no certificate authority chain that trusts anything outside the enclave. There is — depending on the regime — either no network connection to the outside at all, or only a one-way data diode for telemetry export. Code, data, and dependencies enter via signed physical media; nothing enters by network. The auditor asking the same question gets a definitive answer: nothing leaves, nothing enters, except on the controlled cadence the deployment was certified against.
This is the deployment posture for classified defense workloads (typical accreditation frameworks: DoD IL5 and IL6, FedRAMP High, sometimes CMMC Level 2 or Level 3 for the defense industrial base), for healthcare systems handling controlled clinical data (HIPAA with HITRUST CSF attestation, sometimes additional state-level requirements), for financial systems under stricter regulatory regimes (FFIEC and SR 11-7 for bank model risk, NYDFS Part 500 for cyber), and for industrial control environments where any outbound traffic is forbidden by policy. The distinction matters legally, not just operationally: an "isolated" deployment may still constitute a data transfer to a vendor under some regulatory frameworks; an air-gapped deployment, by construction, cannot.
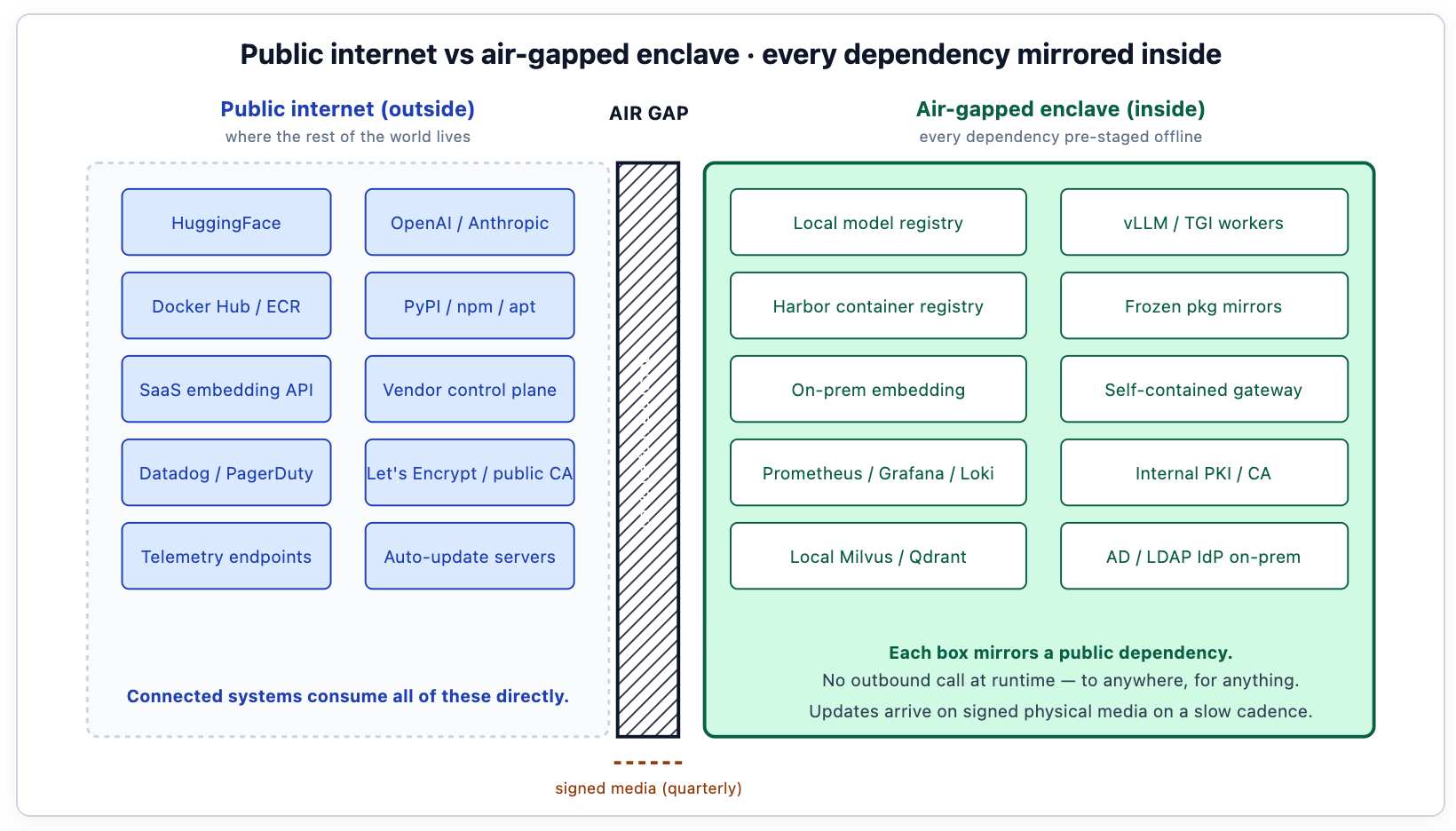
The diagram is the architecture. Every component that an internet-connected deployment would consume from somewhere external has to have a mirror inside the enclave. The mirror exists; the consumption is local. The integrity of the deployment depends on every byte of every dependency being accountable — versioned, signed, scanned, and frozen at staging time. The right side of the diagram is what a Helm-based install of an AI platform like TrueFoundry populates inside the enclave: the gateway data plane, the model registry, the serving workers, the vector store, the observability stack, the policy engine — all wired to the customer's on-prem IdP, internal CA, and SIEM via Helm values rather than vendor endpoints.
Model weights are imported once via signed package, SHA-256 verified against the published hash from the model author, and then sealed inside the enclave. Subsequent inference workers pull from the local registry, never from HuggingFace. Updates follow the same path: a new model version arrives on physical media, gets signature-verified, and is staged into the registry under a new version label.
This sounds onerous for teams used to pip install, and it is. The reason it is worth it is that the integrity of the deployment depends on every byte of every weight being accountable. The signed-import process is the audit trail. When the auditor asks "where did this model come from, and how do you know it hasn't been tampered with?", the deployment answers with a chain of signatures: the model author signed the release, the security team verified the signature on import, the registry recorded the version under a custodial process. That chain is what makes the model usable in a regulated context.
The registry's metadata schema matters as much as the storage. Each model version is recorded with its source, its hash, its import date, its responsible engineer, and the eval results that qualified it for production. This is the same versioned-artefact discipline the team applies to code, applied to model weights. On TrueFoundry the Model Registry holds these fields as first-class metadata, so the auditor's question has a structured answer in the platform itself rather than living in a spreadsheet owned by one person. Teams that treat models as ad-hoc files struggle in audits; teams that treat them as code-class artefacts have the answers ready.
Token generation happens entirely inside the enclave, on the customer's H100, A100, or MI300 cluster (or whatever the regime allows; some classified environments restrict hardware choice as part of supply-chain controls). No provider API call ever leaves the boundary. The serving stack is the same vLLM, TGI, or SGLang the rest of the world uses; what changes is that it runs in an environment where it cannot phone home for telemetry, model auto-updates, or external embedding services.
The serving engines themselves usually need patches for air-gapped operation. vLLM by default checks HuggingFace for tokenizer files if they aren't pre-staged; that check must be disabled, or the tokenizer must be on the local registry path. Some engines reach for telemetry servers on startup; those calls must be stubbed out or pointed at a local sink. The patching is one-time work but it matters: teams that skip it discover the failure modes at runtime, when a worker pod refuses to start because it can't reach the internet for a metadata check. TrueFoundry's serving stack ships with these air-gapped patches in place — tokenizer sources point at local registry paths, telemetry endpoints point at the on-prem observability stack, and auto-update is off by default in the air-gapped Helm values. The same vLLM, TGI, and SGLang backends that teams use in connected deployments run in the enclave; the difference is which values file the deployment loads.
RAG over classified documents requires that the embedding model also runs inside the enclave. Sending text to a remote embedding API, even one provided by a major cloud, is the move that breaks the air gap most often in practice. Teams discover the leak when network monitoring shows DNS queries to api.openai.com originating from the supposedly air-gapped retrieval pipeline; the embedding step was using an SDK that defaulted to the cloud provider.
The deployment uses an on-prem embedding model — typically a smaller open-source model that's fast on CPU or runs efficiently on the same GPUs as the serving workers. Common choices: a 384- or 768-dimensional embedding model like bge-small, nomic-embed, or a domain-tuned variant for specialised content. The vector index is encrypted at rest with customer-managed keys, accessed only from inside the enclave, and backed up to the same media regime the rest of the deployment uses.
The vector store choice — Milvus, Qdrant, pgvector — matters less than the deployment hygiene around it. The store needs the same versioned-artefact treatment as the model registry: the corpus snapshots are recorded, the embedding model version is recorded, the index build process is reproducible. When the corpus changes, the re-embedding job runs on a controlled cadence and the auditor can trace any retrieval result back to a specific corpus snapshot. TrueFoundry's deployment manifest pins the on-prem embedding model and the vector store as part of the same Helm install, so the team isn't sourcing them separately at staging time — the choice of embedding model and vector backend is a values-file knob; the air-gap posture is not.
TrueFoundry's AI Gateway, in air-gapped deployments, runs as a containerized workload deployed via Helm into the customer's Kubernetes cluster inside the enclave. There are no outbound network dependencies for any of its runtime operations: identity comes from the local IdP (typically Active Directory or LDAP, sometimes a customer-operated SAML provider), policy lives on local disk under version control, audit logs go to the local SIEM (Splunk on-prem in most defense deployments, sometimes a customer-built equivalent). There is no telemetry to a vendor control plane; aggregate health metrics, if exported at all, go through a one-way data diode to a separately accredited monitoring environment.
The gateway's feature set is the same in air-gapped as in connected deployments. The same tokens-per-hour rate limiting per project, team, or workflow. The same per-project budget enforcement with hard caps that block new requests when a budget is reached. The same priority-based fallback routing across local model targets. The same input and output guardrails — PII / PHI redaction on inputs before the model sees them, secrets detection on outputs before they reach the client, prompt-injection detection for agent-shaped workloads. The features run; they emit their telemetry to the on-prem stack rather than to a vendor's observability cloud. The configuration that drives them is the same YAML.
This matters in practice because a platform team that operates a connected dev environment and an air-gapped production environment isn't operating two platforms — they're operating one platform with two values files. The gateway image is the same; the chart is the same; the API surface is the same. The engineering investment in the gateway pays off across every deployment shape simultaneously.
Every container image the deployment uses has to come from somewhere. In a connected environment, that somewhere is Docker Hub or ECR. Inside the enclave, it is a local Harbor or equivalent registry, populated at staging time from external mirrors and then frozen. The same is true for PyPI, npm, apt, and any other language package manager the system depends on. Snapshots get scanned for vulnerabilities at staging, then pinned.
The discipline is that nothing the system needs at runtime can be a moving target. The world outside changes; the inside of the enclave does not, except on a controlled cadence. A CVE published yesterday in a Python dependency does not automatically propagate into the enclave; it propagates on the next scheduled update, after the security team has reviewed it. This is sometimes uncomfortable for teams used to apt-get upgrade; it is the trade the deployment posture requires.
TrueFoundry's air-gapped install workflow publishes all container images and Helm charts to an OCI-compatible registry under the customer's control. The customer either replicates from TrueFoundry's upstream registry (tfy.jfrog.io/tfy-images for the container images, tfy.jfrog.io/tfy-helm for the Helm charts) at staging time, or works from the customer's existing Harbor or Artifactory if the customer's release-engineering team already owns the upstream-mirror discipline. The container registry's catalogue becomes the dependency inventory — when an auditor asks "what software is running in this enclave?", the answer is the registry's manifest. Teams that don't keep their registry tidy fail this question; teams that treat the registry as a curated, accountable inventory pass it.
Prometheus, Grafana, and Loki cover most metrics, dashboards, and logs. All on-prem. Dashboards export to a local SOC console, not to a SaaS vendor. Alert routing goes through internal email or Slack-on-prem equivalents, not Twilio or PagerDuty. The observability stack itself is one of the larger workloads inside the enclave; it's not unusual for the monitoring infrastructure to consume more compute than the AI workloads it monitors during quiet periods.
TrueFoundry's gateway is OpenTelemetry-native; in air-gapped deployments, the OTEL pipeline emits to the local Prometheus and Loki rather than to a vendor's observability cloud. Same instrumentation, same trace schema, different destination. Per-request observability includes the identity, the workload tag, the resolved model, the policy decisions applied, the guardrail verdicts, and the trace ID — everything the audit needs to reconstruct who asked what, of which model, under which policy, and how the gateway responded. Audit log retention is configurable for the long retention periods (seven years is common in defense and regulated-finance environments) that audit regimes require.
The alert routing is the place where most teams discover their on-prem assumptions are wrong. Sending an SMS via Twilio when the gateway saturates is the right behaviour in a connected deployment and a violation of the air gap in an enclaved one. The team's incident response runbook needs to be rewritten for the enclave: the on-call gets the alert via internal channels, the SOC gets a parallel notification through internal escalation, the external vendor support escalation (if any) happens through a different, accredited channel.
Public CAs (Let's Encrypt, DigiCert) are not reachable. The deployment uses the customer's internal PKI, with trust anchors loaded at install time. mTLS between gateway and workers, between gateway and IdP, between every internal service: all verified against the internal CA. This sounds like a footnote; it is the reason most "isolated" deployments are actually not air-gapped, because somebody left certbot reaching for a public endpoint to renew a certificate.
The internal CA is the customer's responsibility, not the platform's. The platform consumes the CA's trust anchors at install time — for TrueFoundry, via Helm values that point at the trust-anchor file mounted into the gateway pods. The customer's PKI team runs the CA, issues certificates, and rotates them. The certificate lifecycle is one of the operational loads the customer's PKI team needs to plan for. Short-lived certificates (90-day or shorter) are best practice but require automation that the team needs to provision before the deployment goes live.
Updates are the operational reality that distinguishes air-gapped from theoretically air-gapped. The model gets better; the gateway gets new features; vLLM ships a critical fix. None of these can be applied via git pull.
The discipline is a signed bundle workflow. The vendor publishes a release as a signed tarball — manifests, container images, Helm chart, and (if applicable) weight artifacts, with an integrity hash. The bundle is loaded onto physical media (typically a USB stick or removable hard drive, depending on the regime's media policy), walked across the air gap, and staged on a holding server inside the enclave. Integrity is verified, signatures are checked against pre-loaded vendor public keys, and the bundle is installed under a new version label. The previous version remains available for rollback for a configurable window — typically 30 days — so that a problematic update can be reverted without another bundle import cycle.
TrueFoundry's air-gapped releases ship in exactly this shape: signed bundles containing the chart, the manifests, the gateway and worker images, and the integrity hashes. Verification happens against pre-loaded TrueFoundry public keys; the bundle is staged in the customer's registry under a new version label; rollback is a Helm rollback to the previous chart revision. The customer's accreditation review applies to the bundle, not to a continuous stream of changes — every update is a discrete accreditation event with a clear before-and-after, which is the property the bundle workflow exists to provide.
Cadence depends on the regime. Some defense environments accept quarterly updates; some healthcare environments allow monthly. Some environments accept nothing without a separate accreditation review per release — every bundle is a fresh accreditation event. The platform has to support all of these without changing shape; the configuration of "how often we update" is the customer's, not the vendor's.

The four tiers represent a continuum of trust between the deployment and the outside world. The connected tier (most workloads, most enterprises) accepts vendor connectivity as a routine part of operation. The BYOC tier accepts vendor connectivity for the control plane but not for data — payloads stay inside the customer's cloud account. The air-gapped + diode tier accepts only one-way export, typically for SOC monitoring of aggregate health metrics. The fully air-gapped tier accepts no network connectivity of any kind. Most classified defense work runs in the bottom two tiers; most healthcare and finance work runs in BYOC; most general enterprise work runs in connected.
TrueFoundry supports all four tiers from the same codebase — the same gateway image, the same Helm chart, the same configuration schema. The Helm values change between tiers; the gateway primitives do not. The control plane and the gateway data plane are deployable independently, which is what makes this work: in connected SaaS, both planes run in TrueFoundry's environment; in BYOC, the control plane is SaaS and the data plane runs in the customer's VPC; in air-gapped, both planes run inside the customer's enclave. A platform team that runs SaaS in dev and air-gapped in classified production doesn't operate two platforms — it operates one platform configured differently. Engineering investment in the gateway pays off across every deployment shape simultaneously.
Most "air-gapped" deployments that fail their first audit fail not because the architecture was wrong but because a specific dependency leaked the gap. Five patterns recur across teams' first attempts; knowing them in advance is what produces deployments that pass review.
Default SDK telemetry. Cloud-provider SDKs (boto3, google-cloud, azure-sdk) routinely emit telemetry to vendor endpoints on initialisation. The application code looks innocent — it imports a library, instantiates a client — and the library calls home before the team's code does anything. The fix is auditing every dependency's network behaviour at staging time, disabling telemetry through configuration where the SDK supports it, and patching where it doesn't. Egress monitoring during staging is what surfaces these calls before production.
Tokenizer auto-download. Many ML libraries default to downloading tokenizer files from HuggingFace on first use. The serving engine that loaded the model successfully fails three weeks later when a worker pod restarts and the cached tokenizer is gone. The fix is pre-staging tokenisers in the local registry and pointing the engine at the local path through configuration, not relying on its default download behaviour.
Container image pulls at runtime. Kubernetesデプロイメントが image: vllm/vllm:latest の代わりに image: harbor.internal.example.mil/vllm/vllm:v0.6.3 を参照している場合、エアギャップ環境では実行時に失敗します。解決策はレジストリミラーポリシーです。つまり、すべてのマニフェスト内のすべてのイメージ参照がローカルのHarborを指すようにし、外部レジストリを参照するマニフェストは一切ありません。アドミッションコントローラーはデプロイ時にこれを強制できます。
証明書の更新が外部にアクセスする。 デプロイメントは内部証明書でインストールされましたが、更新の自動化はデフォルトでLet's Encryptまたは同様の公開CAを使用します。3か月後、更新ジョブが実行され失敗します。さらに悪いことに、公開エンドポイントへのアクセスに成功し、監査体制を損なうこともあります。解決策は、証明書の更新を後付けではなく、最初から顧客の内部PKIに接続することです。
ネットワーク経由でのNTPとDNS。 時刻同期はデフォルトで公開NTPプールを使用し、DNS解決はデフォルトで公開サーバーを使用します。デプロイメントのネットワークは「隔離」されているにもかかわらず、ワーカーポッドはまだ pool.ntp.orgにアクセスしています。解決策は、顧客の内部NTPおよびDNSインフラストラクチャをクラスターレベルで構成することです。これにより、アプリケーションコードが意図していなくても、どのポッドも誤って外部にアクセスできなくなります。
よくあるパターンとして、障害はAIワークロード自体ではなく、AIワークロードの下にあるプラットフォーム層で発生します。チームはRAGパイプラインを正しく記述していますが、推移的な依存関係が外部に接続してしまいます。防御策は、段階的なエグレス監視です。つまり、デプロイメントを接続されたサンドボックスで実行し、完全なエグレスログを記録し、予期せぬ外部接続をすべて発見事項として扱い、サンドボックスがクリーンになってからエアギャップ環境へのインストールに進みます。TrueFoundryの接続モードステージング環境は、まさにこの目的のために存在します。エンクレーブで実行されるのと同じゲートウェイイメージとHelmチャートが、まずすべての外部接続が監視可能なサンドボックスで実行されるため、規制された環境に到達する前に障害モードが表面化します。エアギャップデプロイメントの整合性は、主にステージング時に確保されます。
エアギャップ環境への展開はBYOC環境への展開よりも遅く、BYOC環境への展開はSaaSの導入よりも遅いです。以下に示すのは、一般的な数か月にわたる計画です。これを急ぐと、認定審査に不合格となるデプロイメントが生まれます。
1~2か月目 — 認定への取り組み。 顧客のセキュリティチームと認定機関は、プラットフォームのドキュメント、データインベントリ、更新ワークフロー、および暗号化の状況をレビューします。その結果として、デプロイメントがどのようなものになるか、どのような制御が適用されるかを正確に定義する認定パッケージが作成されます。これは後でデプロイメントが評価される基準となる成果物であり、これを正しく行うことで数週間の修正作業を省くことができます。TrueFoundryのデプロイメントエンジニアリングチームは通常このフェーズに参加し、アーキテクチャドキュメント、FIPS 140-3暗号化の状況(デプロイメントが AWS GovCloud or Azure Government内で実行される場合)、および認定機関がレビューするバンドル署名プロセスを提供します。
3~4か月目 — ステージング環境。 顧客は、本番環境のトポロジーをミラーリングするが機密データを含まないステージングエンクレーブを構築します。プラットフォームはローカルレジストリミラーに対してHelm経由でインストールされ、統合(IdP、SIEM、内部CA、オンプレミス監視)が接続され、更新ワークフローはサンプル署名バンドルを使用して実行されます。ステージングデプロイメントは、シミュレートされた負荷の下で少なくとも1か月間実行され、完全なエグレスログが有効にされるため、予期せぬ外部接続は本番環境に移行する前に発見事項として表面化します。
5~6ヶ月目 — 本番環境へのインストールと認定。 プラットフォームは本番環境のエンクレーブにインストールされます。認定機関は、事前に合意されたパッケージに対して正式なレビューを実施します。発見事項は修正され、デプロイメントは適切な認証フレームワーク(機密防衛向けにはDoD IL5/IL6、連邦政府機関向けにはFedRAMP High、医療・金融向けにはセクター固有のフレームワーク)の下で認定されます。
7ヶ月目以降 — 定常運用。 プラットフォームは規制対象のワークロードに対応します。更新ワークフローは、認定されたサイクル(四半期ごと、毎月、または認定イベントごと)で実行されます。顧客のセキュリティチームが運用コンプライアンス体制を管理し、顧客のSREチームが日常業務を管理します。TrueFoundryは、インシデントサポートと四半期ごとのリリースサイクルについては、認定されたエスカレーションチャネルに後退します。この時点では、デプロイメントはベンダーのものではなく、顧客のものです。
エアギャップは、単にオンプレミスで実行することと同じではありません。一般的なオンプレミスデプロイメントは、依然としてパッケージマネージャーにアクセスし、外部レジストリからコンテナイメージをプルし、SaaSの可観測性ベンダーにテレメトリを送信します。そのデプロイメントは企業のデータセンター内にありますが、エアギャップではありません。この2つは日常的に混同されており、その混同こそが規制当局が監査で注目する点です。
また、運用コストがかからないわけではありません。ミラーリングされたレジストリの維持、内部PKIの運用、四半期ごとのリリースサイクルに合わせたリリースエンジニアリング — これらは、接続されたデプロイメントには存在しない実際のエンジニアリング負荷です。エアギャップシステムを運用するチームはこれを理解していますが、これから引き継ぐチームは通常そうではありません。この両者のギャップが、ほとんどのデプロイメント失敗の原因となっています。エアギャッププラットフォームの調達レビューでは、顧客の継続的な運用負荷を2倍または3倍過小評価することがよくあります。
そして、コンプライアンスの実践の代替にはなりません。このアーキテクチャはネットワークに起因するリスクは排除しますが、人間に起因するリスクは排除しません。内部脅威、設定ミス、ポリシー違反、運用上のエラーは、依然として顧客のセキュリティチームが管理しなければならないリスクです。エアギャップは強力な物理的制御ですが、多層防御体制の残りの部分の代替にはなりません。
そして、すべてのチームにとって正しい答えではありません。ワークロードが実際にエアギャップの体制を必要としない組織は、規制上のメリットを得ることなく運用コストを支払うことになります。そのようなワークロードの場合、BYOCは運用コストのごく一部でデータ主権のメリットのほとんどを提供し、接続されたティアはさらに大幅に簡単です。独自の認定実績を持つ成熟したエアギャッププラットフォームをすでに構築している組織は、認定環境での移行コストに直面し、それを正当化するのが難しい場合があります。エアギャップは、規制体制が外部接続を一切要求しないワークロードのためのデプロイメント形態です。それ以外のすべての場合、よりシンプルなティアが存在するのには理由があります。
プラットフォームの役割は、運用負荷を管理可能にすることであり、存在しないふりをすることではありません。
顧客はエンクレーブ内にOCI互換レジストリ(通常はHarbor、時にはJFrog Artifactoryまたはクラウド相当のもの)をプロビジョニングします。リリースエンジニアリングチームは、TrueFoundryのコンテナイメージとHelmチャートをミラーリングします。例えば、以下から取得されたものです。 tfy.jfrog.io/tfy-images および tfy.jfrog.io/tfy-helm — レジストリに、接続されたステージング環境からの直接レプリケーション、または物理メディアでエアギャップを越えて運ばれた署名付きバンドルを介して。その後、Helmインストールはローカルレジストリ、ローカルイメージマニフェスト、および顧客のKubernetesクラスターに対して実行されます。Helmの値は、顧客のIdP、内部CA、SIEM、および可観測性スタックを指します。接続された開発環境にインストールされるのと同じチャートが、エアギャップのある本番環境にもインストールされます。異なるのは値ファイルのみです。
署名付きバンドルワークフローを通じて。モデル作成者がリリースを公開し、顧客のリリースエンジニアリングチームは、認定されたサイクル(四半期ごと、毎月、または認定イベントごと)でそれをインポートします。バンドルは署名検証され、ローカルレジストリにステージングされ、カナリアサブセットにデプロイされ、監視後に本番環境に昇格されます。以前のバージョンは、設定可能な期間内であればロールバック可能です。
いいえ、フロンティアホスト型モデルは定義上エンクレーブの外部に存在するため、それらを呼び出すとエアギャップが破られます。エアギャップ環境でのデプロイメントでは、ローカルGPU上で自己ホスト型のオープンソースモデル(Llama、Mistral、Qwen、Phi-3)を使用します。その品質は、ワークロードクラス(抽出、要約、分類、内部コーパスに対するRAGなど)には十分な場合が多いです。真にフロンティア推論を必要とするワークロードは、通常、エアギャップの姿勢には適合せず、より制限の少ないティア向けに設計する必要があります。
重要なセキュリティアップデートには帯域外パスがあります。それは、標準的なサイクルよりも迅速に認証され、同じ物理メディアワークフローを通じて配布される緊急署名済みバンドルです。顧客のセキュリティチームが、あるCVEが緊急事態に該当するかどうかを決定します。プラットフォームのリリースプロセスは、必要なケースに対してより迅速なサイクルをサポートします。トレードオフとして、緊急バンドルは通常の認定審査の一部を迂回するため、事後検証が必要となります。
同じワークロードの接続されたデプロイメントよりも大きく、平均して約2〜3倍です。顧客は、PKI運用、ミラーメンテナンス、リリースエンジニアリング、認定リエゾン、および通常のSREローテーションを必要とします。単一のワークロードの場合、これは3〜5人の専任エンジニアを意味する可能性があります。複数のワークロードをホストするデプロイメントの場合、運用インフラストラクチャが共有されるため、ワークロードあたりの限界コストは低くなります。
GPU自体は同じですが、異なるのはサプライチェーンとファームウェアポリシーです。機密環境では、どのベンダーのハードウェアが許容されるか、特定のファームウェアバージョンが必要か、検証済みのサプライチェーンの出所が必要か、といった制限がある場合があります。プラットフォームは、その体制のハードウェアポリシーが許可するものであれば何でも動作します。ハードウェアの調達は顧客の調達チームが担当します。
ダイオード層の場合、はい、テレメトリーは継続的にエクスポートできますが、一方向のみです。ダイオードは、エクスポートチャネルを介してデータがエンクレーブに入ることはないという物理的な保証です。流出するデータは、顧客の認定によって承認されたものです。集計メトリクス、構造化された運用テレメトリー、場合によっては匿名化されたパフォーマンスデータなどです。リクエストごとのペイロードは、いかなる状況でも流出しません。
接続されたデプロイメントと同一ですが、すべてがローカルで行われます。ゴールデンセットはローカルストレージに保存されます。リプレイジョブはローカルのサービングフリートに対して実行されます。判定モデルは、ローカルにデプロイされたオープンソースモデルの1つです。スライシングダッシュボードはオンプレミスのGrafanaにあります。自動ロールバックはローカルのプロンプトバージョンレジストリにフックします。評価の規律は同じですが、宛先のみが異なります。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


