













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
概要: AIエージェントレジストリとは、自律型エージェントとその機能を一元的に集約したカタログであり、AIエージェントの「電話帳」のようなものです。企業は、マルチエージェントシステム全体でのエージェントの発見、ガバナンス、再利用のためにこれを利用します。
AIシステムは、データ取得、ワークフロー実行、自律的な意思決定など、特定のタスクを処理するために設計された専門エージェントによって、よりモジュール化され、協調的になっています。これらのエージェントが企業内やプラットフォーム間で増加するにつれて、それらを効率的に管理することが極めて重要になります。ここでAIエージェントレジストリが役立ちます。
AIエージェントは、推論し、行動し、タスクで協力できる自律型プログラムです。組織がより専門的なエージェント(例:履歴書解析ボット、スケジュールアシスタント、分析エージェントなど)を導入するにつれて、チームはこれらのエージェントが互いを発見し、機能を共有し、ワークフローに統合する方法を必要としています。
AIエージェントレジストリは、MLモデルのモデルレジストリと非常によく似ており、実行中のエージェントとそのメタデータの一元化された(またはフェデレーションされた)カタログとして機能します。このレジストリは、機能の発見とオーケストレーションを可能にします。エージェント(または人間)は、レジストリにクエリを実行して、タスクに適したエージェントを見つけ、その能力を検査し、接続の詳細を取得します。本質的に、それは自律型エージェントのための「電話帳」またはAIエージェント発見プラットフォームとして機能します。
エンタープライズAIおよびMLOpsチームにとって、エージェントレジストリはエージェントのデプロイメントに対する標準化とガバナンスを提供します。これは、スケーリングのために不可欠になりつつあります。 企業におけるエージェントAI 環境を安全に。TrueFoundryがモデルレジストリUIを提供しているのと同様に、エージェントレジストリはエージェントの閲覧、バージョン管理、制御のための単一のウィンドウを提供します。
各エージェントのID、バージョン、機能を共通の形式(例:「エージェントカード」やJSONスキーマなど)でインデックス化することで、レジストリはチームがエージェントを再利用し、デプロイされているものを追跡し、安全なインタラクションを確保することをはるかに容易にします。その結果、部門横断的なエージェントの相互運用性と自律型エージェントのガバナンスを可能にするための、重要なエンタープライズAIレジストリアーキテクチャコンポーネントとなっています。
AIエージェントレジストリは、エージェントエコシステムのためにいくつかの重要な機能を提供します。
1. エージェント登録: エージェントは、 メタデータペイロード をレジストリに(多くの場合RESTエンドポイント経由で)送信することで登録します。この エージェントカード には、エージェント名、説明、バージョン、エンドポイントURL、エージェントが宣言する機能やスキルなどのフィールドが含まれます。
例えば、FastAPIエンドポイントはJSONペイロードを受け入れ、AgentCardオブジェクトをレジストリのデータベースに保存するかもしれません。簡単なFastAPIスニペットは次のようになります。
@app.post("/agents/register", status_code=201)
def register_agent(registration: AgentRegistration):
agent_card = AgentCard(**registration.dict())
registry.register_agent(agent_card) # store in database or in-memory list
return {"status": "registered", "name": agent_card.name}
これはA2Aプロトコルの例に見られるパターンと一致します。そこでは、チームが「エージェントのAgent Cardをこのレジストリに公開し、他のエージェントがその能力を発見できるようにします」。
2. 検出と検索: クライアント(他のエージェント、オーケストレーションサービス、またはユーザーインターフェース)は、能力、タグ、またはキーワードによってエージェントを検索するためにレジストリにクエリを実行します。例えば、検索APIは、メタデータがクエリに一致するエージェントをフィルタリングできます。標準化された検出では、既知のURL(例:エージェントの.well-known/agent.jsonファイルの取得)または中央検索エンドポイント(例:GET /agents?skill=document-extraction)を使用できます。これにより、プラットフォームは「AIエージェント発見プラットフォーム」として機能し、タスクを適切なエージェントに自動的にルーティングできるようになります。
3. メタデータ管理: レジストリは、各エージェントの豊富なメタデータを維持します。名前とバージョンに加えて、メタデータには認証情報、サポートされる対話プロトコル(A2A、RESTなど)、データ型(テキスト、画像、ファイル)、および信頼証明書が含まれる場合があります。例えば、研究提案では、信頼性を確保するために「暗号的に検証可能な」AgentFactsまたはPKI証明書の使用が推奨されています。レジストリは、最終ハートビートやヘルスなどのライフサイクル情報も追跡する場合があります。
4. ヘルスモニタリングとハートビート: レジストリの正確性を保つため、エージェントは定期的にハートビートを送信します。エージェントがチェックインに失敗した場合(例:30秒以内)、レジストリはそれを古いものとしてマークするか、削除することができます。これにより、アクティブなエージェントのみが検出可能になり、不健全なエージェントやオフラインのエージェントを検出することで、自律型エージェントのガバナンスに役立ちます。
5. アクセス制御とガバナンス: レジストリは、誰がどのエージェントを登録または呼び出すことができるかを強制します。すべてのユーザーがすべてのAIツールを見るべきではないのと同様に、すべてのエージェントがすべての呼び出し元にアクセス可能であるべきではありません。レジストリはRBACポリシーを実装し、 特定のAgent Card クライアントの権限に基づいて返します。例えば、内部エージェントはプライベートエンドポイントにアクセスできる一方、外部エージェントは公開された機能のみを参照できます。エージェントのエンドポイントとそのACLを一元化することで、プラットフォームはエージェントのインタラクションが企業セキュリティポリシーに準拠することを保証します。
6. 監査ログと可観測性: 各登録、検出クエリ、または呼び出しを記録することで、監査証跡が提供されます。企業チームは、エージェントがいつ、誰によって、どのような目的で使用されたかをログに記録できます。レジストリ駆動型オーケストレーション(例: TrueFoundryのAI Gateway)は、LLMツール呼び出しと応答をUIにストリーミングできます。同様に、エージェントレジストリは、可観測性のためにログとメトリクスを監視ツールに供給し、チームが使用パターンを理解し、統合の問題をデバッグするのに役立ちます。例えば、Kagentのようなフレームワークは、「すべてのツール呼び出しに対するメトリクス、ロギング、トレーシング」を強調し、「AIエージェントが外部APIとどのように対話しているかについてより深い洞察」を提供します。エージェントレジストリは、このデータをプラットフォームレベルで集約できます。
これらの機能が一体となることで、エージェントレジストリは単なるデータベース 以上のものとなり、企業ガバナンスの下でエージェントが互いを確実に見つけて利用できるようにする統合の基盤となります。
以下は、ある エンタープライズAIレジストリの概念アーキテクチャです。自律型エージェントは中央サービスに登録し、そのサービスがメタデータを保存し、検索/発見APIを提供します。プラットフォームのUIやオーケストレーション層は、エージェントを見つけるためにこのレジストリと連携します。
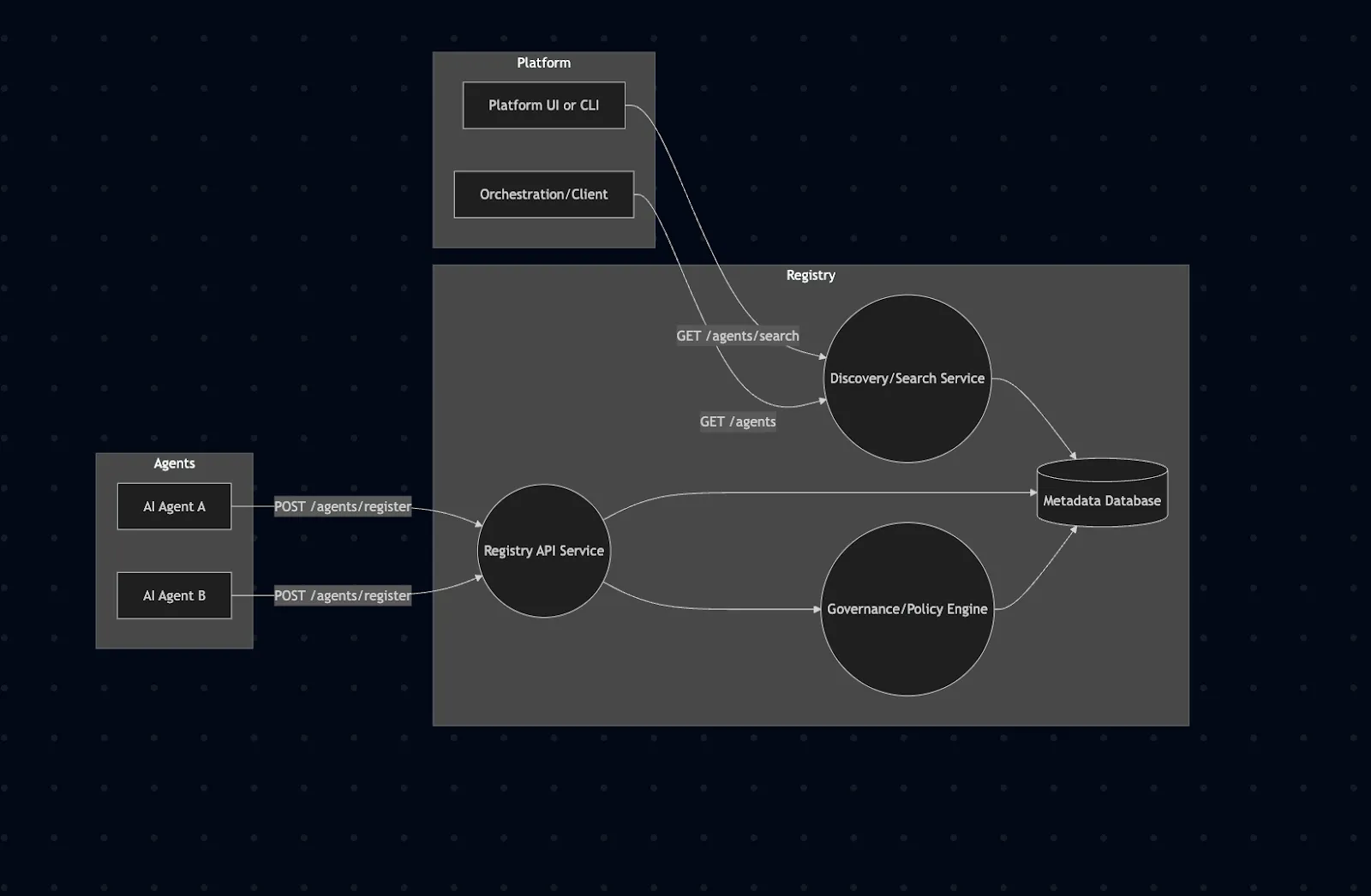
このエンタープライズAIレジストリのアーキテクチャでは、エージェント(A、B)はRegistry APIを呼び出して登録し、そのAPIがAgentCardをメタデータデータベースに保存します。ポリシー/ガバナンスモジュールは、登録と検索に対するアクセス制御を適用します。発見/検索サービスは、クライアントとUIがDBをクエリすることでエージェントを見つけられるようにします(例えば、全文検索や機能タグによるフィルタリングなど)。管理UI(TrueFoundryのモデルレジストリインターフェースなど)は、登録されているすべてのエージェント、そのバージョン、およびアクセスルールを視覚化できます。
内部的には、メタデータには高性能なキーバリューストアやグラフデータベースを、APIの実装には標準的なWebフレームワーク(例:FastAPI)を使用することができます。例えば、Agent Name Service (ANS) の提案では、IDにPKIを使用したDNSに似たディレクトリが示されています。TrueFoundryのAI Gatewayも同様に、レジストリとOAuthフローを使用して「AI開発ツールへのアクセス」を一元化し、安全なトークン管理を実現しています。当社のアーキテクチャは、これらのエンタープライズグレードのパターンを反映しています。発見のための集中型レジストリサービス、認証(OAuth/PKI)との統合、エージェントワークフローのためのオーケストレーション層、そして可視性のためのUX層です。
AIエージェントレジストリの相互運用性、標準化、セキュリティを向上させるために、いくつかのオープンなフレームワークとプロトコルが登場しています。
from python_a2a.discovery import AgentRegistryregistry = AgentRegistry(name="Enterprise Registry")agents = list(registry.get_all_agents()) # returns registered AgentCardsこれはA2Aの「電話帳」設計を実装しています。エージェントは、enable_discoveryヘルパーを介して自己登録し、ハートビートを送信することもできます。
これらのフレームワークは、レジストリの課題における主要な側面、すなわち検出(A2A、NANDA)、相互運用性(Agent Protocol、LangGraph)、アイデンティティ(LOKA)、ガバナンス(Kagent、TrueFoundryのようなゲートウェイ)に対処します。これらの標準の1つ以上と連携することで、企業はセキュリティとスケーラビリティを念頭に置きながら、スムーズなエージェントの相互運用性を確保できます。
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

AIエージェントレジストリを導入することは、企業のAIチームに多くの利点をもたらします。
これらの利点それぞれが、企業が堅牢なAI運用へと移行するのを助けます。レジストリ内でエージェントを第一級アセットとして扱うことで、組織は次のものを得られます。 ガバナンス、発見可能性、監査 これらはデータやモデルでは長らく標準であったものであり、自律型エージェントにまで拡張されます。
エンタープライズグレードのエージェントレジストリを構築することは容易ではありません。チームはいくつかの課題を乗り越える必要があります。
これらの課題にもかかわらず、現代の提案や事例研究の多くはこれらの課題に対処しています。例えば、ANSはセキュアな解決アルゴリズムを備えたDNSのような命名スキームを使用しており、A2Aコミュニティはエージェントカードセキュリティに関するベストプラクティスを公開しています。エンタープライズレジストリの実装では、フェデレーションディスカバリ、強力なID、堅牢なガバナンス層といった複数の戦略を組み合わせることになるでしょう。
Here's The Evaluation Framework for Proposal Template
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Gateway & Developer Experience | |||
| Unified model access | Does the platform provide one consistent interface for hosted models, self-hosted models, and provider-native requests? | Must have | ✅ Supported: unified access to 1000+ LLMs. |
| OpenAI-compatible API | Can teams keep existing OpenAI, Anthropic, or provider-compatible client code while moving traffic behind a governed gateway? | Must have | ✅ Supported: OpenAI-compatible API plus native SDK support. |
| Prompt lifecycle management | Can prompts be created, versioned, A/B tested, and reused with a built-in playground for rapid iteration? | Should have | ✅ Supported: versioned prompts, playground, and experimentation. |
| Playground and experimentation | Is there a playground UI for non-developers to test prompts, models, and tools without code? | Should have | ✅ Supported: playground with model and tool experimentation. |
エージェントレジストリを成功裏にデプロイし、管理するためには、チームは以下の推奨事項に従うべきです。
requests.post("http://registry/v1/agents/register", json=agent_card)
これらのベストプラクティスに従うことで、チームはAIエージェントレジストリをMLOpsまたはModelOpsプラットフォームの堅牢でスケーラブルなコンポーネントにすることができます。時間が経つにつれて、これはエンタープライズAI発見プラットフォームの中核部分へと進化するでしょう。これは、モデルレジストリがMLライフサイクル管理に不可欠になったのと同様です。
AIエージェントレジストリは、エンタープライズAIインフラストラクチャの基盤要素となる態勢が整っています。自律型エージェントが普及するにつれて、標準化された発見メカニズムを持つことで、エージェントが衝突するのではなく連携できるようになります。研究のコンセンサスは明確です。「発見、ID、および機能共有をサポートするための標準化されたレジストリシステムの必要性は不可欠になっている」エージェントのメタデータ、登録、ガバナンスを一元化することで、企業はシームレスなエージェントの相互運用性と強力な自律型エージェントのガバナンスを実現します。
今後、プロトコル(例:A2A、Agent Protocol、AgentFacts)やツール(TrueFoundryのツール用ゲートウェイなど)のさらなる収束が期待されます。最終的には、エージェントレジストリは今日のモデルレジストリと同じくらい一般的になり、監査証跡、バージョン管理、AI機能の検索可能なカタログを提供するでしょう。エンタープライズAIチームにとって、今エージェントレジストリに投資することは、複雑なAIワークフローをオーケストレーションするためのスケーラブルなプラットフォームを獲得し、統合の摩擦を減らし、本番環境でのエージェントAIの可能性を最大限に引き出すことを意味します。
AIエージェントレジストリは、自律型エージェントがエージェントカードを介してメタデータと機能を登録する、集中型の「電話帳」として機能します。このシステムにより、他のエージェントやユーザーは、標準化された発見プロトコルを通じて、特定のスキルを検索し、IDを確認し、接続の詳細を取得できます。
AIエージェントレジストリは、企業がモジュール型AIシステムの増大する複雑さを大規模に管理するために不可欠です。これはガバナンスのための単一の管理画面を提供し、チームがセキュリティポリシーを適用し、バージョン管理を追跡し、エージェントの健全性を監視すると同時に、異なる部門間で既存のエージェントの再利用を促進することを可能にします。
モデルレジストリが静的なMLアーティファクトを追跡するのに対し、エージェントAIレジストリは推論し行動するライブの自律型プログラムに焦点を当てます。モデルレジストリがバージョンと重みを管理するのに対し、エージェントレジストリはリアルタイムの発見、ハートビート監視、および複数の専門エージェント間のアクティブなワークフローの動的なオーケストレーションを処理します。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


