

June 24, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 24, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
TL;DR TrueFoundry and Seldon are coming together into one platform. Seldon’s real-time ML serving joins TrueFoundry’s AI Deploy and AI Gateway, which gives enterprises a single control plane for both classic ML and agents. Your production models keep running on the same Kubernetes you use today, and you gain a clear path to LLMs and AI agents on top of them.
Most enterprise AI teams now operate on both sides of a single line. They run classic ML models in production for things like fraud scoring, churn prediction, and recommendations. At the same time they are building agentic applications that reason, call tools, and act on their own. Those two worlds used to move at different speeds. They don’t anymore. Both are becoming business-critical at once, and running them as two separate stacks, with two vendors and two governance models, gets expensive and brittle fast.
That is the gap TrueFoundry and Seldon are closing together. Seldon spent more than a decade perfecting real-time ML serving for some of the most demanding enterprises in the world. TrueFoundry built the control plane around modern AI, with deployment, an AI Gateway, and governance for LLMs and agents. We are merging the two into one platform, so teams get a single place to run predictive models and agents on the Kubernetes foundation they already trust.
This merge works because neither side has to give up its design. Seldon and TrueFoundry made the same architectural choice years ago. Both run as a control plane on the customer’s own Kubernetes, inside their VPC, on-prem, or air-gapped. Both are cloud-agnostic. Both lean on the same standard components for traffic, autoscaling, and telemetry, and both hand a team its own namespace instead of asking for cluster-wide admin.
Seldon took that shared foundation and went deep on one layer, serving classic ML in real time at scale. We took the same foundation and went wide, from deployment up through a gateway that governs models, agents, and tools. So the two platforms were never on a collision course. They were solving neighbouring parts of the same problem, the same way. Bringing them together just connects two layers that already speak the same language.
Seldon has been the backbone for real-time ML inference at banks, telecoms, insurers, retailers, and healthcare companies for over a decade. That reputation comes from going deep on the hardest parts of production ML serving:
Together that is a mature serving and monitoring layer with deep roots in regulated, low-latency settings, the kind where a bad prediction turns into a customer problem within minutes.
TrueFoundry built the control plane around the model, the layers that turn a served model into a governed, cost-aware, agent-ready application:
Our customers already run business-critical AI through the Gateway at the scale of more than a trillion tokens a day.
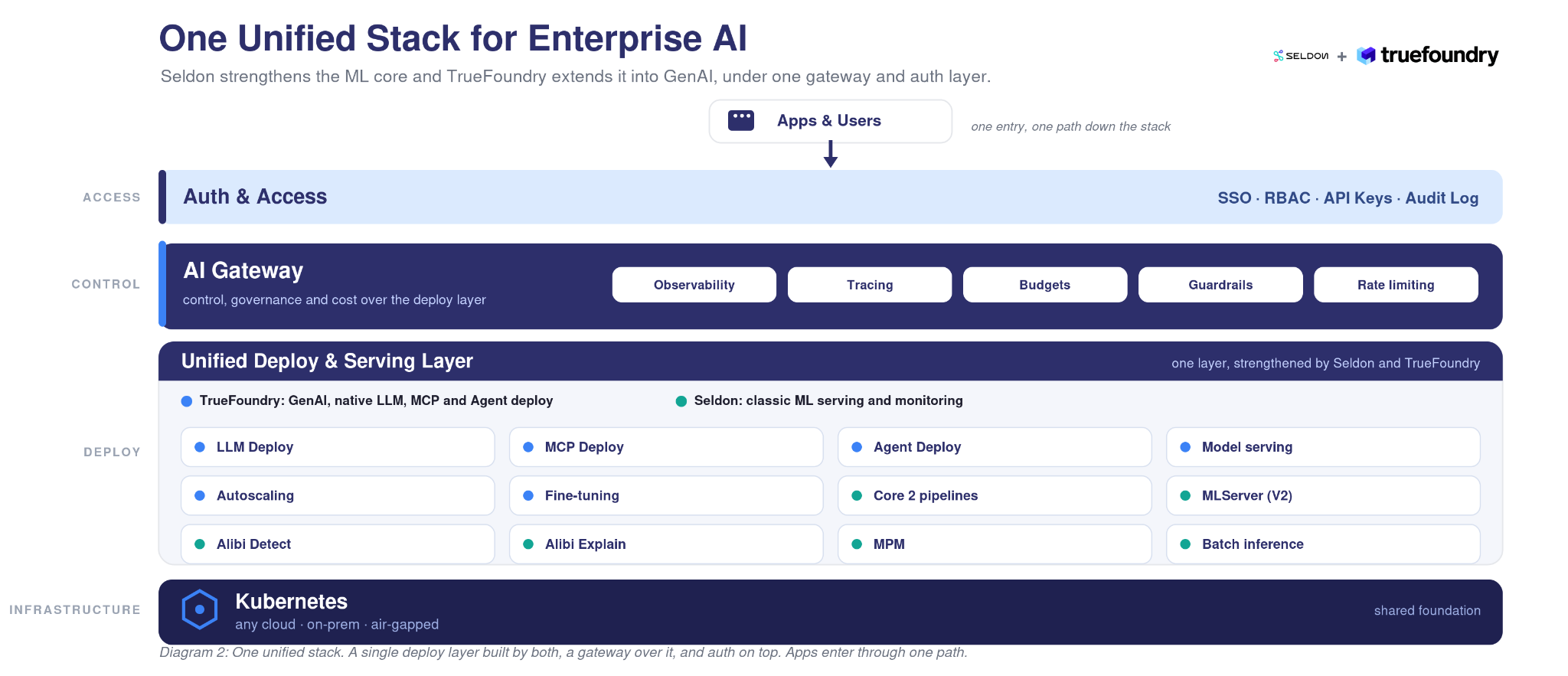
Here is the part that matters. When Seldon’s serving layer and TrueFoundry’s deploy and gateway layers come together, an enterprise gets one control plane that covers both halves of its AI.
Deploy runs the workloads. The Gateway governs and routes them. Your classic ML models and your agents sit on the same Kubernetes, under one set of access controls, one observability stack, and one view of cost. A single request can hit a fraud model, an LLM, and an agent that calls a tool, and every hop is logged and governed the same way.
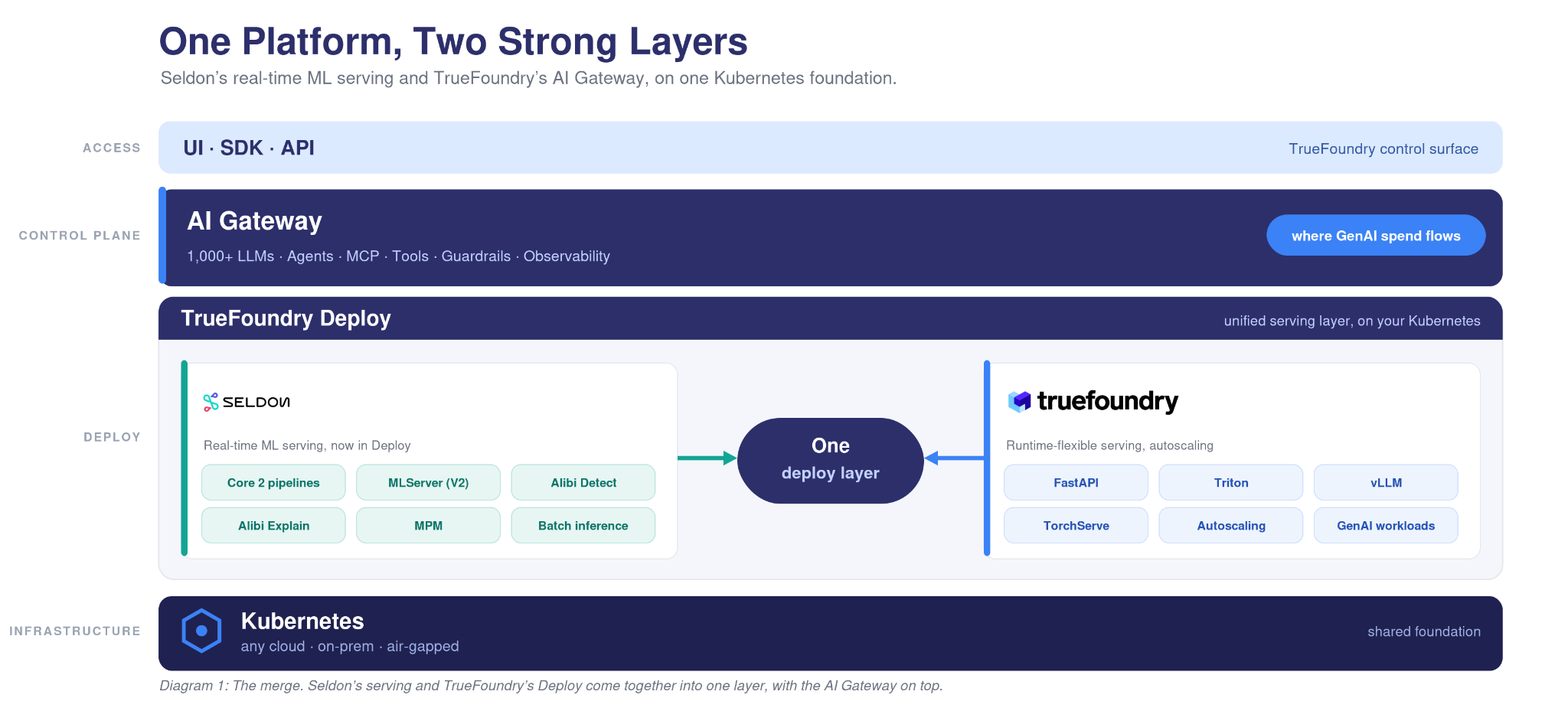
It helps to look at where the money is moving. Predictive ML is mostly built and runs steadily. The new investment in enterprise AI is going into LLMs and agents, and that spend flows through the Gateway. Every model call, every agent step, every tool invocation passes through it, which is why our customers already push more than a trillion tokens a day across it.
So the combined platform does two useful things at once. It keeps the ML you have already built running, with no disruption. And it puts you on the surface where the next wave of AI spend lands, without standing up a separate platform to get there.
If you run Seldon today, your real-time ML keeps running on the Kubernetes you already operate. Models served over the V2 protocol stay portable, and Core 2 pipelines map onto Deploy’s own primitives rather than being rewritten. On top of that, you gain the AI Gateway and the agent layer without standing up anything new.
If you run TrueFoundry today, nothing in your stack changes, and Deploy gets stronger. It picks up Seldon’s serving and monitoring lineage, including drift and outlier detection, model explanations, and performance monitoring that feed straight into the platform you already use.
For both, it is one stack instead of two. One place to deploy a model, route a call, watch for drift, govern an agent, and account for the cost, across classic ML and GenAI, on the infrastructure you already run.
Enterprises should not have to run one platform for their models and another for their agents. With TrueFoundry and Seldon together, they don’t have to. Seldon’s real-time ML serving and TrueFoundry’s AI Gateway now sit on one control plane for enterprise AI, on the Kubernetes you already run. Your production ML keeps going, and the path to agents and LLMs is right there on top of it.
See how TrueFoundry’s AI Gateway unifies ML and agents → Explore the AI Gateway
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception
© 2026 Tous droits réservés.




.webp)

.webp)





.webp)
.webp)
.webp)
.webp)
.webp)