
.webp)
July 2, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 26, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Lorsque Moonshot AI a rendu Kimi K2 open source, la communauté de l'IA l'a remarqué. Lorsqu'ils ont enchaîné avec Kimi K2 Thinking, un modèle capable de raisonner à travers des centaines d'appels d'outils avec une cohérence remarquable, les professionnels ont commencé à y prêter une attention sérieuse. Maintenant, avec Kimi K2.6, Moonshot est allé encore plus loin : un modèle open source de pointe qui se classe au sommet des benchmarks de codage et d'agents à long terme, rivalisant avec les meilleures offres propriétaires au monde.
Cet article explore en profondeur ce qui rend K2.6 remarquable, ce que les chiffres des benchmarks signifient réellement pour les charges de travail réelles, et comment vous pouvez le mettre en œuvre sans un projet de déploiement de six semaines.
Kimi K2.6 est le modèle multimodal de nouvelle génération de Moonshot AI, disponible sur Hugging Face et via l'API Kimi. Comme ses prédécesseurs, il est basé sur une architecture de type « Mixture-of-Experts » (MoE) avec une fenêtre contextuelle de 262 144 tokens. Mais K2.6 est plus qu'une amélioration incrémentale — il représente un changement de conception significatif vers trois aspects que la génération précédente gérait de manière incohérente : le codage à long terme, la conception pilotée par le code, et la coordination d'essaims d'agents.
Voici une illustration rapide de ce que signifie « à long terme » en pratique. Dans une démonstration de benchmark, K2.6 a déployé de manière autonome un modèle Qwen3.5-0.8B localement sur un Mac, a implémenté l'inférence en Zig (un langage de programmation système de niche), et sur plus de 4 000 appels d'outils et plus de 12 heures d'exécution continue, a amélioré le débit de ~15 à ~193 tokens par seconde (environ 20 % plus rapide que LM Studio). Ce n'est pas un chatbot qui répond à une question ; c'est une IA agissant comme un ingénieur de performance senior sur un engagement soutenu.
Dans une démonstration distincte, K2.6 a entièrement révisé un moteur de rapprochement financier open source vieux de 8 ans au cours d'une session de 13 heures, en effectuant plus de 1 000 modifications de code ciblées pour atteindre un gain de 185 % du débit moyen et un gain de 133 % du débit de pointe — sans aucune intervention humaine après la spécification initiale de la tâche.
Les chiffres sont importants, mais le contexte l'est encore plus. Voici comment K2.6 se comporte sur les benchmarks les plus pertinents pour les systèmes agentiques en production :
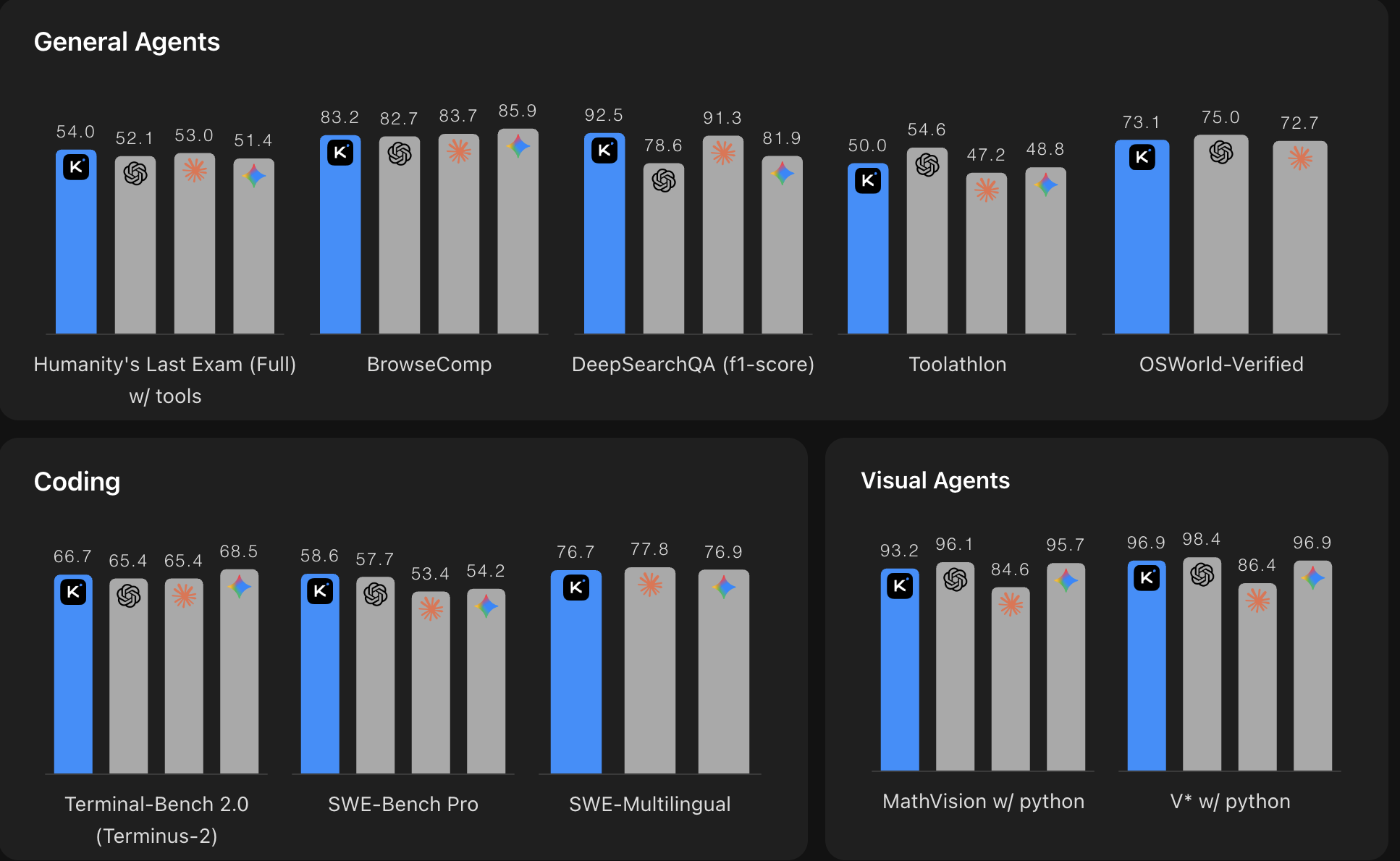
*Source : Comparaison des benchmarks Moonshot AI Kimi K2.6. Plus le score est élevé, mieux c'est. Le graphique compare Kimi K2.6 aux principaux modèles propriétaires sur des benchmarks d'agents généraux, de codage et d'agents visuels.*
K2.6 est compétitif avec les meilleurs modèles propriétaires, y compris Claude Opus 4.6 et GPT-5.4, sur pratiquement toutes les dimensions importantes pour le codage agentique et les tâches à long terme. Et il le fait en tant que modèle à poids ouverts à 0,74 $ / 3,50 $ par million de jetons d'entrée/sortie, ce qui représente une fraction du coût des alternatives propriétaires comparables.
Le bond par rapport à Kimi K2.5 est également significatif : une amélioration de près de 80 % sur Toolathlon, environ 8 points de pourcentage sur BrowseComp et SWE-Bench Pro. Ce ne sont pas des gains marginaux.
Les partenaires d'entreprise ayant eu un accès anticipé rapportent des résultats tout aussi convaincants : le CTO d'Augmentcode a souligné la "précision chirurgicale de K2.6 dans les grandes bases de code" ; Vercel a constaté une amélioration de plus de 50 % sur son benchmark Next.js par rapport à K2.5 ; et CodeBuddy a mesuré une amélioration de 12 % de la précision de la génération de code, le succès de l'invocation d'outils atteignant 96,6 %.
La plupart des LLM conviennent à la génération de code ponctuelle. K2.6 est conçu pour les tâches qui prennent des heures : refactorisations multi-fichiers, optimisations inter-langages, améliorations des pipelines de build et boucles de débogage itératives où le modèle doit lire la sortie du compilateur, ajuster son hypothèse et réessayer.
Le modèle montre une forte généralisation à travers Python, Rust, Go, et même des langages rares comme Zig, ce qui est remarquable car cela suggère que le modèle a internalisé les concepts de programmation suffisamment profondément pour les transférer, plutôt que de simplement mémoriser des schémas à partir des données d'entraînement.
K2.6 peut transformer une simple invite en langage naturel en un frontend complet et de qualité production — pas seulement une maquette statique, mais une interface dotée d'éléments interactifs, d'animations de défilement et d'une authentification basée sur une base de données. Sur le Kimi Design Bench interne de Moonshot, K2.6 surpasse Google AI Studio pour les tâches d'entrée visuelle, la construction de pages de destination, le développement d'applications full-stack et la programmation créative générale.
Pour les équipes qui développent des flux de travail assistés par l'IA, cela signifie concrètement un modèle unique qui gère l'ensemble de la pile : architecture, logique, interface utilisateur et échafaudage de déploiement.
K2.6 introduit une expansion architecturale majeure du système d'essaims d'agents présenté pour la première fois dans K2.5. L'essaim peut désormais gérer jusqu'à 300 sous-agents exécutant simultanément 4 000 étapes coordonnées, contre 100 agents et 1 500 étapes dans K2.5. Ce n'est pas seulement une amélioration d'échelle ; c'est un changement qualitatif dans les types de tâches qui deviennent réalisables.
Une tâche qui nécessitait auparavant une orchestration humaine (par exemple, "rechercher 100 entreprises de semi-conducteurs, élaborer cinq stratégies d'investissement quantitatives et produire une présentation de style McKinsey") peut désormais être donnée comme une seule instruction à K2.6 et retournée comme un livrable complet.
C'est là que la conversation s'arrête généralement : une équipe lit les chiffres de référence, s'enthousiasme, puis passe les trois semaines suivantes à trouver comment servir le modèle de manière fiable.
K2.6 est un grand modèle MoE. Sa fenêtre de contexte de 262K signifie que les exigences en mémoire sont importantes. Les charges de travail agentiques — par définition — génèrent des schémas de trafic très variables : calmes pendant des heures, puis soudainement des centaines de sous-agents parallèles effectuant tous des requêtes simultanément. Les stratégies de déploiement naïves s'effondrent sous cette charge.
C'est le problème d'infrastructure que TrueFoundry AI Gateway est conçue pour résoudre.
Plutôt que de provisionner votre propre cluster GPU, de construire un équilibreur de charge personnalisé et d'ajuster manuellement les paramètres d'inférence, TrueFoundry vous permet de pointer votre application vers un point d'accès unique — et gère le reste. La passerelle achemine intelligemment les requêtes entre les fournisseurs, gère la concurrence pour les charges de travail en rafale (comme un essaim déclenchant 300 sous-agents simultanés) et vous fournit les outils d'observabilité — traces, histogrammes de latence, utilisation des jetons par équipe — que vous auriez autrement à construire vous-même.
Lors de nos tests internes avec Kimi K2 Thinking, la passerelle de TrueFoundry a géré plus de 350 RPS sur un seul vCPU avec environ 10 ms de surcoût. Pour les charges de travail agentiques où une seule tâche initiée par l'utilisateur peut se ramifier en des dizaines ou des centaines d'appels API, cette marge de manœuvre est cruciale.
Il y a aussi une dimension organisationnelle pratique. Les équipes d'entreprise utilisant K2.6 ont généralement plusieurs équipes — science des données, ingénierie produit, plateforme — toutes souhaitant expérimenter le même modèle. La passerelle fournit un plan de contrôle unique pour la limitation de débit, l'attribution des coûts et les politiques d'accès, sans que chaque équipe n'ait besoin de gérer ses propres clés API.
La voie la plus rapide pour exécuter K2.6 dans un environnement géré et prêt pour la production :
1. Via la passerelle IA (API) de TrueFoundry
Si vous utilisez déjà le SDK OpenAI ou tout client compatible OpenAI, vous pouvez passer à K2.6 en modifiant une seule chaîne de modèle :
from openai import OpenAI
client = OpenAI(
api_key="<your-truefoundry-api-key>",
base_url="https://llm-gateway.truefoundry.com/api/inference/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.6",
messages=[
{"role": "user", "content": "Refactor this codebase for better performance..."}
]
)La passerelle gère de manière transparente la sélection du fournisseur, le routage de secours et la limitation de débit.
2. Pour les charges de travail basées sur des agents
L'interface d'appel d'outils de K2.6 suit le schéma standard d'appel de fonctions d'OpenAI. Pour les tâches à long terme, vous voudrez :
- Définir `max_tokens` généreusement (le modèle peut utiliser de manière productive un budget de génération important)
- Activer le streaming pour obtenir des sorties incrémentielles à partir de longues chaînes d'outils
- Utiliser le tableau de bord de traçage de TrueFoundry pour visualiser quels appels d'outils prennent du temps et où le contexte est consommé
3. Pour l'orchestration d'essaims d'agents
Si vous construisez des systèmes multi-agents, la passerelle de TrueFoundry fournit des métadonnées au niveau de la requête — vous pouvez étiqueter les requêtes de chaque sous-agent avec un ID de tâche parent, puis reconstituer la trace d'exécution complète après coup. C'est inestimable pour déboguer le comportement de l'essaim et comprendre où le parallélisme aide (ou nuit).
Les équipes d'ingénierie qui développent des outils de codage basés sur des agents: K2.6 est le premier modèle open source qui rivalise sérieusement avec GPT-5.4 et Claude Opus sur SWE-Bench Pro. Si vous attendiez un modèle à poids ouverts capable de gérer des tâches de base de code de niveau production, le voici.
Les équipes de plateforme ML qui gèrent l'accès aux modèles: une entreprise qui évalue K2.6 aux côtés d'autres modèles de pointe bénéficie de l'exécution de tout via une seule passerelle. L'approche de catalogue de modèles de TrueFoundry vous permet de tester K2.6 en A/B contre Claude ou GPT-5.4 sur vos charges de travail réelles, avec un suivi des coûts et de la latence côte à côte.
Les équipes ayant des exigences de résidence des données: Les poids ouverts de K2.6 signifient qu'il peut être déployé sur une infrastructure que vous contrôlez. La plateforme de déploiement de TrueFoundry gère l'orchestration, vous obtenez ainsi une gouvernance de modèle d'entreprise sans qu'un fournisseur propriétaire ne se trouve sur votre chemin d'inférence.
Quiconque en a marre de payer les prix des modèles propriétaires: à 0,74 $ / 3,50 $ par million de jetons et des performances de référence qui égalent ou dépassent les alternatives propriétaires sur la plupart des tâches basées sur des agents, l'argument coût-performance pour K2.6 est difficile à ignorer.
Kimi K2.6 est un véritable modèle de pointe. Non pas « bon pour l'open source » — mais véritablement compétitif avec les meilleurs modèles au monde sur les benchmarks qui comptent pour un travail d'ingénierie réel. Sa fiabilité à long terme, son architecture d'essaim d'agents et son prix compétitif en font le modèle open-weight le plus convaincant disponible aujourd'hui pour les systèmes agentiques en production.
La question pratique n'est pas de savoir si K2.6 vaut la peine d'être utilisé. Il l'est. La question est de savoir à quelle vitesse et avec quelle fiabilité vous pouvez le mettre en production. TrueFoundry AI Gateway répond à cette question — afin que votre équipe consacre son temps à construire avec le modèle, et non à construire l'infrastructure qui l'entoure.
Essayez-le maintenant: Accédez à Kimi K2.6 via le [TrueFoundry AI Gateway](https://www.truefoundry.com/ai-gateway), ou [réservez une démo](https://www.truefoundry.com/book-demo) pour voir comment il s'intègre au flux de travail de votre équipe.
*Tous les chiffres de référence sont cités du blog technique officiel de Kimi K2.6 et des évaluations tierces vérifiées sur OpenRouter. Les chiffres de performance de l'infrastructure proviennent des tests internes de TrueFoundry.*
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception
© 2026 Tous droits réservés.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




