
.webp)
July 2, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 26, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
La passerelle IA TrueFoundry est une couche d'exécution unifiée pour l'infrastructure LLM. Elle gère l'authentification, le routage entre les fournisseurs, la limitation de débit, l'application des politiques, la gestion des appels d'outils MCP, et — élément crucial pour cette intégration — le traçage conforme à OpenTelemetry. Chaque requête via la passerelle génère un span contenant des attributs standard gen_ai.* (nom du modèle, nombre de jetons, raison de la fin) ainsi que des attributs spécifiques à TrueFoundry tels que tfy.input, tfy.output, et tfy.span_type. Ces spans sont publiés de manière asynchrone vers une file d'attente de messages NATS une fois la requête terminée, ce qui signifie que le chemin d'exportation ne bloque jamais une requête en cours. Un service d'exportation OTEL dédié lit cette file d'attente et transmet les spans à tout point de terminaison OTLP configuré via HTTP ou gRPC.
Pydantic Logfire est une plateforme d'observabilité développée par l'équipe à l'origine de Pydantic — la couche de validation intégrée aux SDK d'OpenAI, aux SDK d'Anthropic et à la plupart des frameworks d'IA actuellement en production. Logfire ingère les données OTLP standard et applique un rendu natif de l'IA par-dessus : lorsqu'il détecte gen_ai.* sur un span, le LLM Panel s'active automatiquement, affichant l'historique complet de la conversation, les arguments d'appel d'outils, le nombre de jetons par requête et les coûts calculés — sans aucune intégration de SDK côté émetteur. Les requêtes Logfire sont écrites en SQL compatible PostgreSQL, de sorte que les traces de production sont accessibles aux humains comme aux agents de codage. Il est disponible en tant que service cloud géré avec des points de terminaison régionaux aux États-Unis et dans l'UE.
L'intégration se connecte à un seul point : la Configuration OTELde TrueFoundry, qui accepte un point de terminaison HTTP OTLP et un en-tête d'autorisation. Accédez à Passerelle IA → Contrôles → Paramètres → Configuration OTEL et cliquez sur le bouton de modification pour ouvrir le panneau de configuration.

Section de configuration OTEL de TrueFoundry — le point de terminaison des traces est dirigé vers l'URL d'ingestion EU de Logfire avec l'en-tête Authorization défini.
Définissez le point de terminaison sur l'URL d'ingestion régionale de Logfire, sélectionnez HTTP avec l'encodage proto, et ajoutez le jeton d'écriture Logfire comme Autorisation valeur d'en-tête. Le même jeton d'écriture couvre à la fois les exportateurs de traces et de métriques.
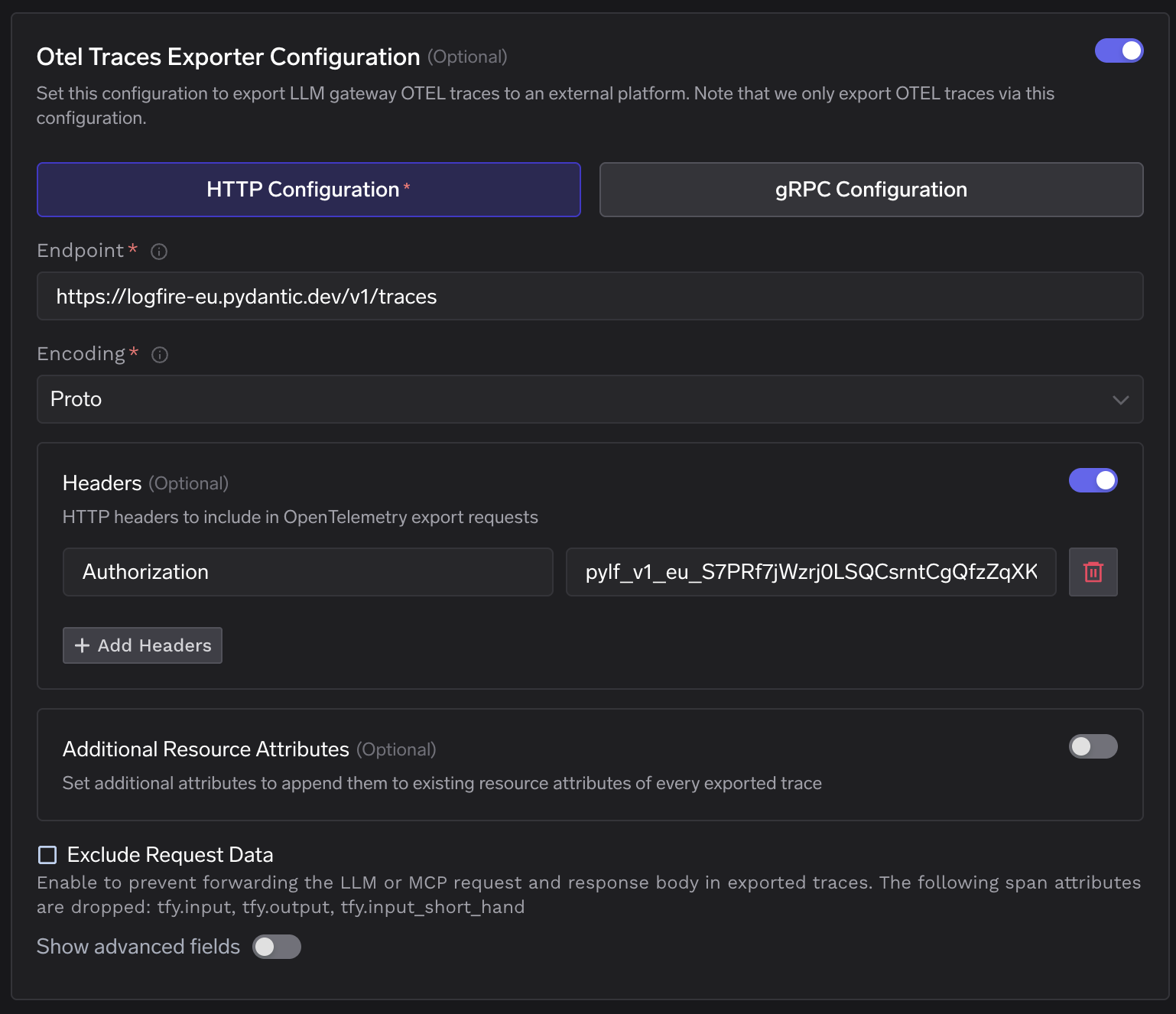
Le formulaire de l'exportateur de traces rempli — point de terminaison défini sur https://logfire-eu.pydantic.dev/v1/traces, encodage Proto, et le jeton d'écriture Logfire dans l'en-tête Authorization.
Aucune modification de code n'est requise dans les applications envoyant des requêtes via la passerelle. Le pipeline de traçage fonctionne entièrement au niveau de la couche d'infrastructure. Une requête de n'importe quelle équipe, utilisant n'importe quel modèle, via n'importe quel fournisseur, génère une portée (span) qui transite vers Logfire, transportant le contexte complet de ce qui s'est passé au niveau de la passerelle.
Lorsqu'une requête arrive à la passerelle, la séquence est la suivante :
Une fois configurées, les traces de tfy-llm-gateway commencent à apparaître dans la vue en direct de Logfire en temps réel. L' tfy.span_type attribut distingue les traces ChatCompletion, AgentResponseet MCPGateway — permettant aux équipes de filtrer par type d'opération ou de les interroger en SQL.

Vue en direct de Logfire affichant les traces de tfy-llm-gateway — les opérations AgentResponse, ChatCompletion et MCPGateway apparaissent avec un horodatage complet, un statut et des traces enfants imbriquées.
Au-delà des traces individuelles, l'exportateur de métriques présente des données d'utilisation agrégées pour les fournisseurs, les modèles et les équipes. La vue d'ensemble de l'utilisation de Logfire les regroupe par portée et nom de span, offrant aux responsables de plateforme une vue d'ensemble de la destination du trafic et de son volume.
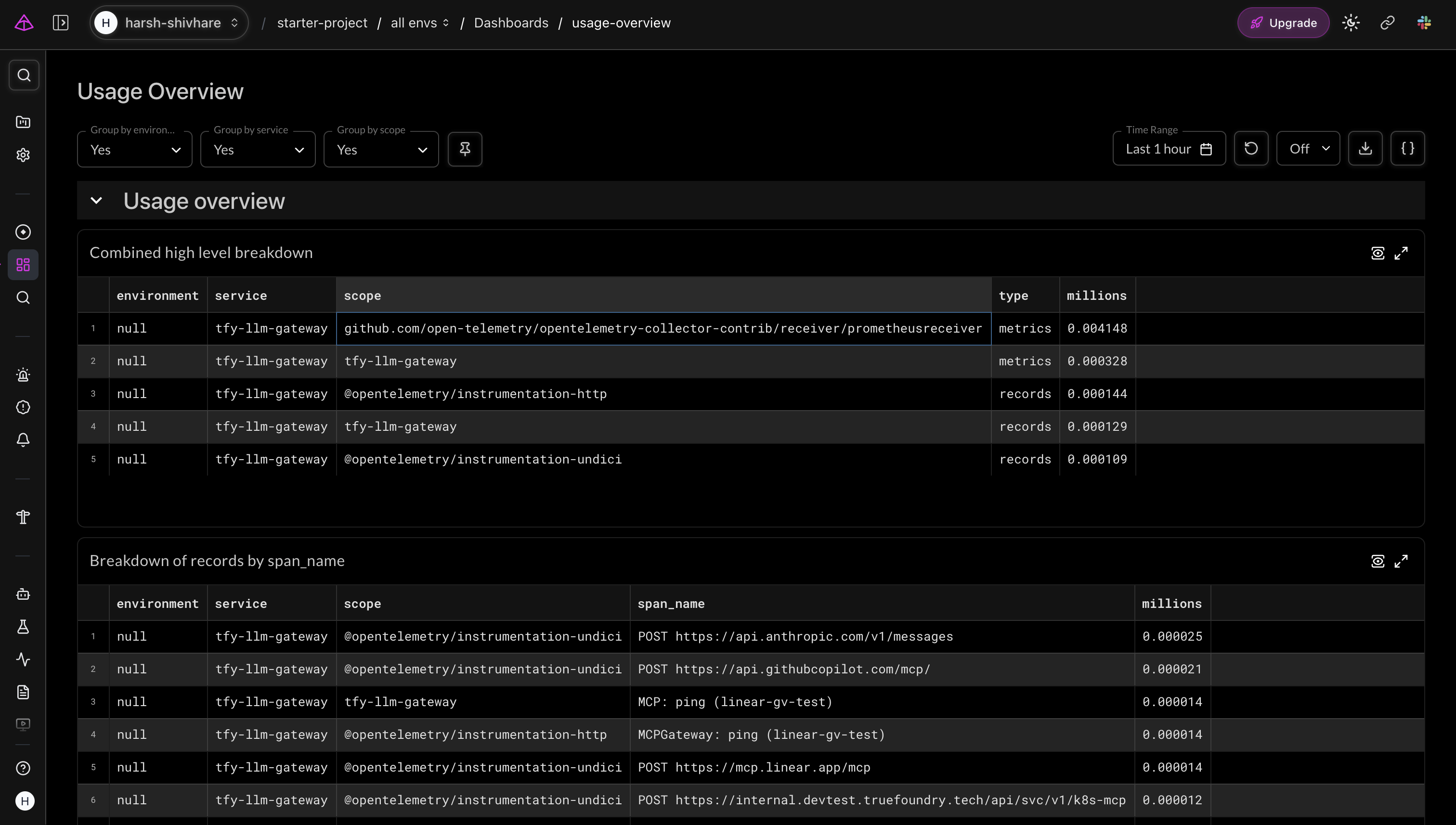
Vue d'ensemble de l'utilisation de Logfire — métriques de tfy-llm-gateway ventilées par portée d'instrumentation, affichant le trafic ChatCompletion et MCPGateway pour les différents fournisseurs.
Commencez par créer un jeton d'écriture dans Logfire. Accédez à votre projet, ouvrez Paramètres du projet → Jetons d'écriture, et cliquez sur Nouveau jeton d'écriture. Copiez le jeton immédiatement — Logfire n'affichera plus la valeur complète.

La page des jetons d'écriture Logfire — créez un jeton dédié pour TrueFoundry et stockez-le en toute sécurité avant de fermer la boîte de dialogue.
Ensuite, allez à Passerelle IA → Contrôles → Paramètres → Configuration OTEL dans TrueFoundry et configurez les exportateurs de traces et de métriques avec le point d'accès régional de Logfire et le jeton d'écriture. La référence complète des points d'accès et le guide de configuration sont disponibles dans la documentation TrueFoundry. Logfire propose un niveau gratuit permanent, avec une option d'entreprise auto-hébergée pour les équipes ayant des exigences de résidence des données.
L'enseignement à tirer de cette intégration est d'ordre architectural : TrueFoundry et Logfire n'ont jamais eu besoin de se coordonner directement. La passerelle émet des spans OpenTelemetry standard avec des attributs gen_ai.* ; Logfire lit cette même norme et active automatiquement ses vues adaptées aux LLM. OpenTelemetry est le contrat qui les lie — la passerelle régit l'exécution et génère la télémétrie, Logfire enregistre et visualise le comportement, et la norme les connecte sans qu'aucun des systèmes ne dépende des mécanismes internes de l'autre.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception
© 2026 Tous droits réservés.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




