

June 25, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 4, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Nos complace anunciar la integración de Resemble AI con TrueFoundry AI Gateway, que lleva la clonación de voz y la conversión de texto a voz síncrona y TTS en streaming al mismo camino de gateway que los equipos ya utilizan para LLMs, embeddings y tráfico de agentes.
Los equipos que enrutan tráfico de IA a través del AI Gateway de TrueFoundry ahora pueden conectar Resemble AI como un proveedor de texto a voz de primera clase a través del paso directo nativo del SDK del gateway. Las solicitudes a los endpoints /synthesize y /stream de Resemble fluyen a través de la ruta del gateway con autenticación centralizada, control de acceso por equipo, seguimiento unificado de costos y trazabilidad completa de las solicitudes. No se requieren cambios en el código del cliente más allá de apuntar la URL base de Resemble al gateway y autenticarse con un token de TrueFoundry.
Esta publicación cubre la arquitectura de la integración. Explica cómo el AI Gateway de TrueFoundry expone a los proveedores de TTS, cómo la superficie API nativa de Resemble se preserva a través de la capa de paso directo y cómo funciona la conmutación por error entre múltiples proveedores de TTS a través de Modelos Virtuales.
TrueFoundry proporciona la capa de control para sistemas de IA en producción. A través del AI Gateway, los equipos centralizan el enrutamiento de modelos, la gestión de claves, el control de acceso, la observabilidad y el seguimiento de costos en LLMs, embeddings y proveedores de imágenes y audio. Cada solicitud fluye a través de una única capa de proxy donde se verifica la identidad, se aplican límites de tasa y se capturan trazas.
El tráfico de TTS en producción tiende a parecerse al tráfico de LLM de tres maneras. Múltiples proveedores suelen estar en juego porque ningún proveedor de TTS individual destaca en todas las dimensiones. La latencia importa porque los agentes de voz transmiten audio a los usuarios en tiempo real. El costo se acumula rápidamente a nivel de carácter o por segundo y se beneficia de los mismos controles de contracargo y presupuesto que los equipos ya aplican a las finalizaciones de chat. Los argumentos para colocar un gateway delante de los proveedores de LLM se aplican directamente.
Resemble AI es una plataforma de generación de voz e inteligencia de audio. Su motor de síntesis principal es el modelo Chatterbox, con una variante Chatterbox Turbo para menor latencia y soporte de etiquetas paralingüísticas. La plataforma soporta clonación de voz, SSML, síntesis HD y salida en streaming. Resemble también expone productos adyacentes, incluyendo Resemble Detect para la detección de deepfakes de audio, y Audio Edit, Voice Design y Watermark, que pueden integrarse junto con el flujo de trabajo de TTS.
Juntas, las dos plataformas ofrecen a los equipos un único lugar para gobernar y rastrear la generación de voz junto con el resto de su pila de IA. TrueFoundry gestiona el despliegue, el enrutamiento y el control operativo. Resemble se encarga de la síntesis real. La integración utiliza el paso directo nativo del SDK de TrueFoundry, que preserva la superficie API completa de Resemble sin forzarla a una forma compatible con OpenAI.

El endpoint de texto a voz síncrono de Resemble toma un pequeño conjunto de campos y devuelve audio junto con metadatos de temporización. El endpoint de síntesis acepta un voice_uuid que selecciona qué voz entrenada o preconstruida usar y un campo de datos que contiene texto o SSML de hasta 3000 caracteres. Los campos opcionales controlan la selección del modelo a través de model (por ejemplo, chatterbox-turbo), la precisión del audio a través de precision (uno de MULAW o PCM_16 o PCM_24 o PCM_32), el formato de salida a través de output_format (wav o mp3), la frecuencia de muestreo, el modo HD a través de use_hd y el manejo de pronunciaciones personalizadas a través de apply_custom_pronunciations.
La carga útil de la respuesta devuelve éxito y un campo audio_content codificado en base64 que contiene los bytes de audio sintetizado. Los metadatos de temporización llegan en audio_timestamps con caracteres de grafema y tiempos de grafema, y caracteres de fonema y tiempos de fonema para casos de uso de alineación posteriores como la sincronización labial y el subtitulado. La respuesta también informa la duración (la longitud del audio en segundos), la synth_duration (el tiempo de síntesis en bruto), el output_format, la sample_rate y cualquier problema que el sintetizador haya señalado durante la generación.
Un segundo endpoint en /stream soporta la síntesis en streaming a través de HTTP para casos de uso de agentes de voz donde el tiempo hasta el primer fragmento de audio es importante. La forma de la solicitud es la misma. La respuesta es un flujo de fotogramas de audio en lugar de una única carga útil base64. La autenticación para ambos endpoints es un token de portador emitido desde la consola de la cuenta de Resemble.
El AI Gateway de TrueFoundry se ejecuta en el framework Hono y un único pod de gateway maneja más de 250 solicitudes por segundo en 1 vCPU y 1 GB de RAM con aproximadamente 3 ms de latencia añadida. Los pods del gateway son sin estado, están limitados por la CPU y escalan horizontalmente a decenas de miles de RPS mediante pods adicionales. El plano de control y el plano del gateway están separados. La configuración del proveedor, incluyendo credenciales, reglas de enrutamiento y límites de tasa, reside en el plano de control y se sincroniza con los pods del gateway a través de NATS. La ruta de solicitud real permanece en memoria sin llamadas externas más allá de la propia llamada al proveedor.
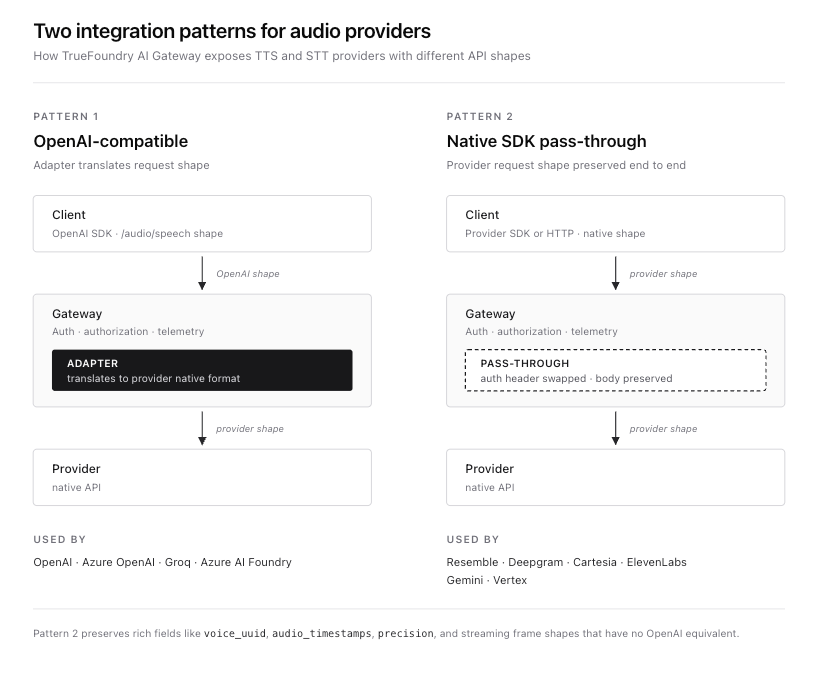
Para TTS, el gateway expone dos patrones de integración.
El primero es el API compatible con OpenAI patrón en la URL base del gateway. Los proveedores que utilizan la forma /audio/speech de OpenAI (OpenAI, Azure OpenAI, Azure AI Foundry y Groq) se conectan aquí. Los clientes utilizan el SDK estándar de OpenAI y el gateway traduce la solicitud al formato nativo del proveedor a través de una capa adaptadora.
La segunda es el paso directo de SDK nativo patrón en {GATEWAY_BASE_URL}/tts/{providerAccountName}. Los proveedores con APIs nativas ricas que no se ajustan limpiamente al formato de OpenAI (Deepgram, Cartesia, ElevenLabs, Gemini y Vertex) se conectan aquí. Se conserva la forma completa de la solicitud y respuesta del proveedor. La pasarela gestiona la autenticación, el control de acceso, el rastreo y el enrutamiento, pero no reescribe la carga útil. Este es el patrón que utiliza Resemble porque el cuerpo de la solicitud de Resemble, con voice_uuid, audio_timestamps, niveles de precisión y el selector de modelo chatterbox-turbo, no tiene un equivalente en el contrato TTS de OpenAI.
Cuando una solicitud llega a un pod de la pasarela, la ruta es la siguiente. El token de TrueFoundry en el encabezado de Autorización se valida contra las claves públicas de IdP en caché. La identidad del equipo se resuelve contra un mapa en memoria y se verifica la autorización a la cuenta del proveedor Resemble. El cuerpo de la solicitud se reenvía al endpoint de síntesis o streaming de Resemble con el token de portador de Resemble adjunto en el lado del servidor. La respuesta se transmite de vuelta al cliente. La interacción completa se captura en un span de traza con el nombre del modelo, la cuenta del proveedor, el recuento de caracteres de entrada, la duración de la respuesta, la duración de la síntesis y la latencia. No hay viajes de ida y vuelta adicionales más allá de la llamada real al proveedor.
Resemble se registra en el plano de control de TrueFoundry como una cuenta de proveedor con el token de portador de Resemble almacenado como un secreto. Una vez añadida la cuenta, la pasarela expone dos rutas TTS para ella. La ruta del SDK nativo en {GATEWAY_BASE_URL}/tts/{providerAccountName}/synthesize actúa como proxy para el endpoint síncrono. La ruta de streaming en {GATEWAY_BASE_URL}/tts/{providerAccountName}/stream actúa como proxy para el endpoint de streaming. Ambas rutas conservan la forma de la solicitud y respuesta de Resemble exactamente.
Una llamada de cliente mínima se ve como el fragmento de código a continuación. Tenga en cuenta que el único cambio con respecto a una llamada directa a Resemble es la URL base y el encabezado de autenticación.
curl -X POST {GATEWAY_BASE_URL}/tts/resemble-prod/synthesize \
-H "Authorization: Bearer ${TFY_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "voice_uuid": "55592656",
"data": "Hello from the gateway.",
"model": "chatterbox-turbo",
"output_format": "mp3",
"use_hd": false }'El código de aplicación existente que apunta directamente a Resemble migra intercambiando la URL base y el token de portador. Los UUID de voz, las cargas útiles SSML, la configuración de precisión y el modo HD se transfieren sin modificaciones. Las bibliotecas cliente oficiales de Resemble se pueden configurar de la misma manera sobrescribiendo su URL base.
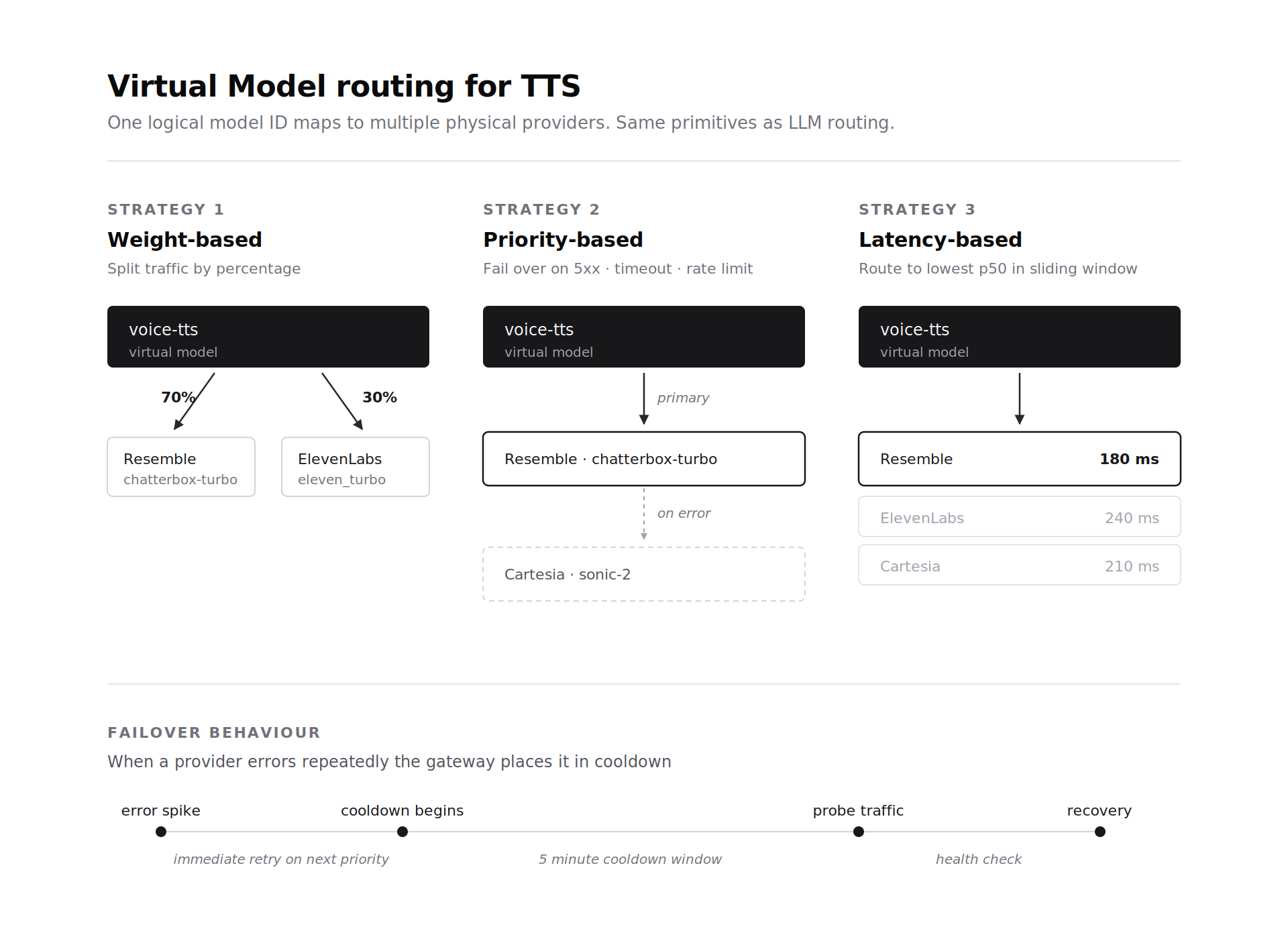
Las pilas de agentes de voz a menudo ejecutan más de un proveedor de TTS en producción por razones de costo y latencia. La abstracción de Modelo Virtual de la pasarela se extiende a los proveedores de TTS de la misma manera que a los proveedores de LLM. Un identificador de modelo virtual se asigna a una o más implementaciones físicas de TTS con reglas de enrutamiento. Basado en ponderación el enrutamiento distribuye el tráfico por porcentaje entre los proveedores. Basado en prioridad el enrutamiento intenta con el primer proveedor y conmuta por error ante un 5xx, un tiempo de espera o un límite de tasa. Basado en latencia el enrutamiento envía el tráfico al proveedor que tenga la latencia p50 más baja en la ventana deslizante.
La conmutación por error para TTS funciona con las mismas primitivas que la conmutación por error de LLM. Los errores no reintentables activan un reintento inmediato en el siguiente proveedor de prioridad. Los picos de error ponen a un proveedor en un período de enfriamiento de 5 minutos y el tráfico de sondeo verifica la recuperación. Un equipo que ejecute Resemble Chatterbox Turbo como la ruta principal de baja latencia puede conmutar por error a Cartesia o ElevenLabs sin cambiar el código del cliente. El Modelo Virtual gestiona la selección.
El seguimiento de costos captura el uso de TTS con la misma granularidad que el uso de LLM. La pasarela registra el recuento de caracteres de entrada, la duración de la síntesis, el modelo, el equipo y el usuario para cada solicitud. El servicio agregador calcula el gasto por equipo y por usuario y alimenta los mismos paneles y primitivas de aplicación de presupuesto que ya cubren las finalizaciones de chat y los embeddings. Los límites de tasa se aplican mediante el algoritmo de cubo de tokens de ventana deslizante con ventanas por minuto delimitadas por usuario, equipo o modelo. Para TTS, la unidad son caracteres o solicitudes en lugar de tokens, pero el algoritmo no cambia.
Cada solicitud de TTS emite un span de traza. Los atributos del span incluyen la cuenta del proveedor, el identificador del modelo (por ejemplo, resemble-prod/chatterbox-turbo), el recuento de caracteres de entrada, la duración de la respuesta en segundos, el tiempo de síntesis en bruto, el formato de salida, la tasa de muestreo y la latencia del lado de la pasarela. Las trazas se emiten asincrónicamente a través de NATS y se exportan vía OTEL a cualquier backend de observabilidad que el equipo haya configurado (Arize, Langfuse, LangSmith o cualquiera de los objetivos compatibles). El interruptor 'Excluir datos de solicitud' se aplica de la misma manera que para las finalizaciones de chat para mantener el texto de entrada fuera de las trazas exportadas cuando la privacidad de los datos lo requiere.
Esto significa que las llamadas TTS aparecen en la misma línea de tiempo de seguimiento que la llamada LLM ascendente que produjo el texto y la acción del agente descendente que consumió el audio. Para la depuración de agentes de voz, esta consolidación es importante. Un turno fallido se puede rastrear desde la finalización del LLM que seleccionó la respuesta, pasando por la síntesis TTS que la generó, hasta la acción que el agente realizó a continuación.
De principio a fin, el flujo de la solicitud es el siguiente. Un cliente envía una solicitud TTS a la pasarela en {GATEWAY_BASE_URL}/tts/{providerAccountName}/synthesize o a su contraparte de streaming con un token de portador de TrueFoundry. La pasarela autentica al llamante contra las claves IdP en caché, resuelve la cuenta del proveedor y verifica la autorización del equipo y del usuario en memoria. Si se utiliza un Modelo Virtual, la lógica de enrutamiento selecciona un proveedor físico basándose en el peso, la prioridad o la latencia. El cuerpo de la solicitud se reenvía a Resemble con el token de portador de Resemble del lado del servidor adjunto. La respuesta se transmite de vuelta al cliente, conservando la forma completa de la carga útil de Resemble, incluyendo el contenido de audio y los metadatos de marcas de tiempo y duración. Cada paso se captura en un tramo de seguimiento emitido asincrónicamente a NATS y exportado a través de OTEL.
No es necesario cambiar nada más en la aplicación. No se requiere reescribir el SDK, ni manejar la autenticación por proveedor en el cliente, ni una tubería de observabilidad separada para el tráfico de voz. La pasarela ya está en la ruta de solicitud para el resto de la pila de IA y Resemble se conecta a esa ruta a través de un paso nativo. El código cliente existente de Resemble sigue funcionando con un simple cambio de URL base.
Más información sobre el TrueFoundry AI Gateway y la plataforma de IA Resemble. Añada Resemble como cuenta de proveedor en el plano de control de la pasarela y llame al punto final de síntesis o de streaming en la ruta /tts/{providerAccountName} desde el código de aplicación existente.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada
© 2026 Todos los derechos reservados.



.webp)
.webp)











.webp)
.webp)