April 22, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Actualizado: April 7, 2026




¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
TrueFoundry AI Gateway registra Databricks Model Serving como un proveedor de primera clase y dirige el tráfico de inferencia hacia él a través del mismo punto final compatible con OpenAI que gestiona todos los demás proveedores de su pila. La integración va más allá del enrutamiento basado en modelos. El MCP Gateway de TrueFoundry se encuentra frente a los servidores MCP gestionados por Databricks para garantizar la autenticación, el control de acceso a nivel de herramienta y el registro de auditorías en los flujos de trabajo de los agentes que consultan Unity Catalog.
Esta publicación describe cuatro puntos de integración: la capa de registro y enrutamiento de proveedores de AI Gateway para los puntos finales de Databricks Model Serving. La capa de gobierno de MCP Gateway para los servidores MCP gestionaba los servidores MCP de Databricks. El plano de enrutamiento del modelo virtual que permite la conmutación por error de varios proveedores entre los modelos alojados de Databricks y las API comerciales. Y la capa de orquestación del flujo de trabajo que activa los trabajos de Databricks como tareas nativas dentro de las canalizaciones de TrueFoundry. Cada sección incluye la configuración funcional y suficientes detalles arquitectónicos para evaluar si esta integración se ajusta a su oferta.
TrueFoundry AI Gateway utiliza una arquitectura dividida. Un plano de control administra la configuración, incluidos los modelos y los usuarios, así como las reglas de enrutamiento y los límites de velocidad. Un plano de puerta de enlace procesa las solicitudes de inferencia reales. El plano de control almacena su estado en PostgreSQL y ClickHouse y sincroniza toda la configuración con los pods de la puerta de enlace a través de un HORMIGAS cola de mensajes. Las actualizaciones se propagan en tiempo real sin necesidad de reiniciarse.
El plano de puerta de enlace se basa en el Marco Hono y realiza todas las comprobaciones de autenticación, autorización y limitación de velocidad en la memoria. Un único pod de puerta de enlace con 1 vCPU y 1 GB de RAM gestiona más de 250 solicitudes por segundo con aproximadamente 3 ms de latencia adicional. El pod se amplía a más de 350 RPS antes de la saturación de la CPU. El escalado horizontal mediante módulos adicionales amplía el rendimiento a decenas de miles de solicitudes por segundo.
Cuando una solicitud llega a la puerta de enlace, el procesamiento sigue una secuencia estricta sin llamadas externas en la ruta activa:
La única llamada externa en esta ruta es la llamada real del proveedor de LLM. Los registros y las métricas se escriben en NATS de forma asincrónica una vez finalizada la respuesta. La puerta de enlace nunca falla en una solicitud, incluso si la cola de NATS está temporalmente inaccesible.
Usted registra Databricks Model Serving como proveedor en AI Gateway proporcionando las credenciales de autenticación y la URL de su espacio de trabajo. TrueFoundry admite dos métodos de autenticación.
Autenticación de Service Principal es el enfoque recomendado para la producción. Usted proporciona el ID de cliente y el secreto de OAuth generados en la configuración de su espacio de trabajo de Databricks, en Service Principals. Esto utiliza el flujo de credenciales de cliente de OAuth 2.0.
Autenticación mediante token de acceso personal funciona para el desarrollo y las pruebas. Usted proporciona una PAT de Databricks directamente.
En ambos casos, también proporciona la URL base del espacio de trabajo (por ejemplo <workspace_id>https://.cloud.databricks.com).
Una vez que el proveedor esté registrado, añada modelos individuales. El ID del modelo en TrueFoundry debe coincidir exactamente con el nombre del punto final de servicio en su espacio de trabajo de Databricks. Cualquier modelo ofrecido por Databricks se puede enrutar a través del Gateway. Esto incluye los modelos básicos disponibles a través de Databricks y los modelos personalizados y ajustados de Mosaic AI y los modelos de terceros a los que se puede acceder a través de Databricks Model Serving.
El código de la aplicación llega a una URL independientemente del proveedor subyacente. El Gateway traduce entre el formato compatible con OpenAI y lo que el proveedor intermedio espere.
desde openai importar OpenAI
cliente = OpenAI (
base_url=» https://your-truefoundry-gateway.com/api/llm «,
api_key="su-clave-api-truefoundry-»
)
# Esta solicitud se enruta a través de Gateway to Databricks Model Serving.
# El código de la aplicación no sabe ni le importa qué proveedor lo atiende.
respuesta = client.chat.completions.create (
model="databricks-main/custom-finetuned-llama»,
messages= [{"role»: «user», «content»: «Analice las tendencias de abandono del tercer trimestre"}]
)
El modelo el campo usa el formato <provider-account-name>/<model-id> donde el ID del modelo coincide con el nombre del punto final de servicio de Databricks que configuró.
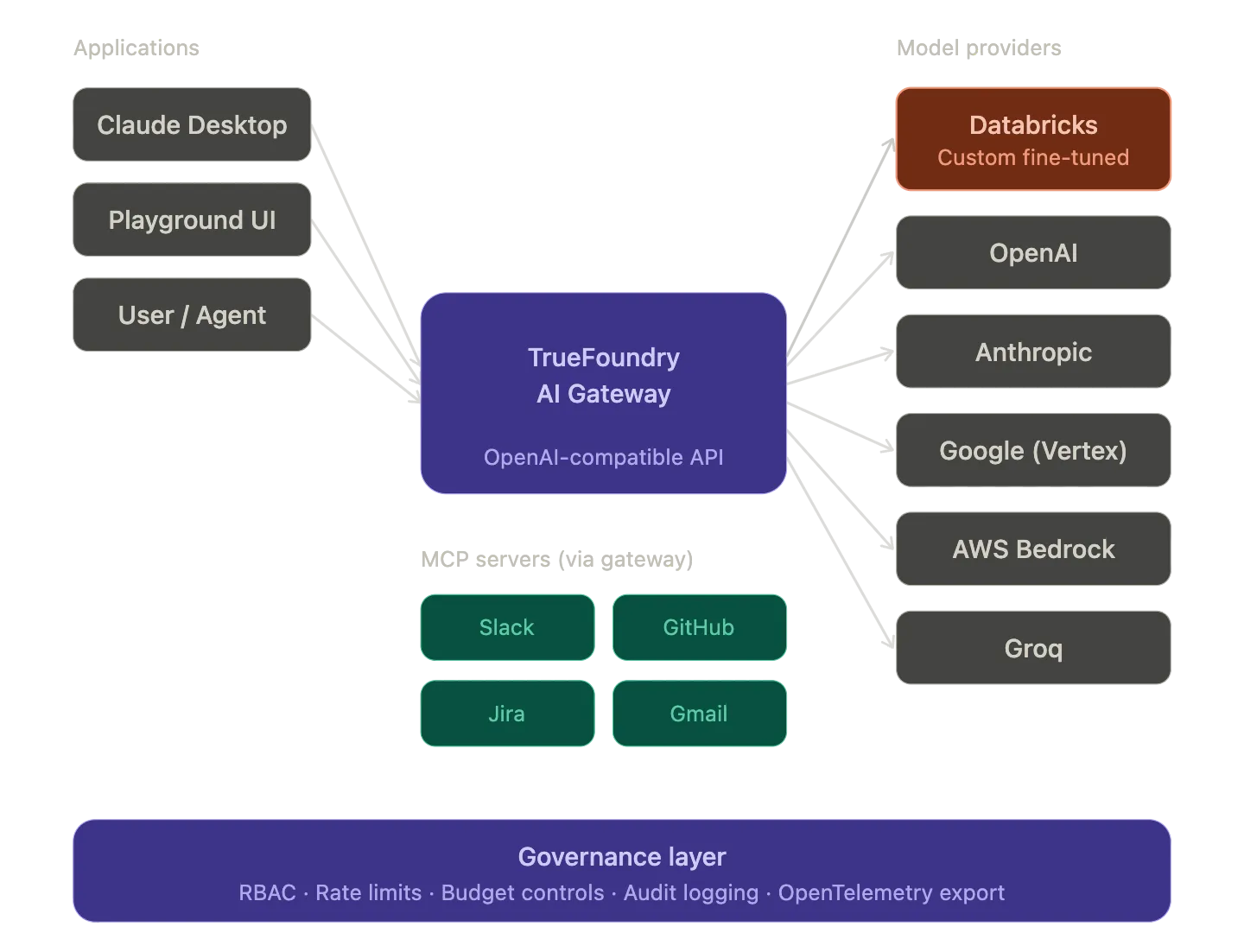
UN Modelo virtual es un identificador de modelo lógico que se asigna a varios proveedores físicos con reglas de enrutamiento. La aplicación utiliza un único nombre de modelo y la puerta de enlace gestiona automáticamente la selección de objetivos y la conmutación por error.
# Esto afecta a un modelo virtual. The Gateway lo resuelve de la mejor manera
# proveedor físico según su configuración de enrutamiento.
respuesta = client.chat.completions.create (
model="asistente de producción»,
messages= [{"role»: «user», «content»: «Resuma este contrato"}]
)
TrueFoundry admite tres estrategias de enrutamiento para los modelos virtuales.
Enrutamiento basado en el peso distribuye el tráfico según los porcentajes asignados entre los objetivos. Puede configurar el 80% para su modelo ajustado alojado en Databricks y el 20% para Claude para las pruebas comparativas. El enrutamiento basado en el peso también admite el enrutamiento fijo que vincula las sesiones a un objetivo mediante encabezados de solicitud o metadatos para mantener la coherencia de las conversaciones en varios turnos.
Enrutamiento basado en prioridades envía todo el tráfico al objetivo en buen estado de mayor prioridad (la prioridad 0 es la más alta). Si ese objetivo falla o no está disponible, la puerta de enlace vuelve a la siguiente prioridad. Esto admite una opción límite de SLA que monitorea el tiempo promedio por token de salida durante un período continuo de 3 minutos y marca los objetivos en mal estado cuando superan un umbral configurado.
Enrutamiento basado en latencia se dirige automáticamente al objetivo con la latencia reciente más baja. La puerta de enlace usa tiempo por token de salida (latencia entre tokens) como métrica. Considera las solicitudes de los últimos 20 minutos con un máximo de 100 muestras. Si hay menos de 3 solicitudes para un objetivo, se considera que es el más rápido en recopilar más datos. Los objetivos se consideran igual de rápidos si su latencia es igual de rápida si su latencia es igual de alta que la del destino más rápido para evitar un cambio rápido.
La puerta de enlace monitorea continuamente cada objetivo y marca los objetivos como insalubres cuando las fallas cruzan un umbral. Las respuestas de error rastreadas incluyen los códigos de estado 5xx y 429 y 401 y 403. El umbral de error predeterminado es de 2 o más errores en un período de evaluación continua de 2 minutos. Cuando un objetivo se marca en mal estado, pasa al final de la lista de enrutamiento y los objetivos en buen estado siempre se prueban primero. La recuperación es automática una vez que los errores desaparecen de la ventana de evaluación.
Cada objetivo también admite la configuración de reintentos por destino. Los valores predeterminados son 2 reintentos con un retraso de 100 ms entre los reintentos. El reintento se activa en los códigos de estado 429 y 500 y 502 y 503. Si optas por un objetivo diferente, se activan los números 401 y 403 y 404 y 429 y 500 y 502 y 503.
Cada solicitud a través del Gateway se rastrea con una atribución completa: qué usuario y qué modelo y qué proveedor y solicitud, latencia, recuento de tokens y costo estimado. La pasarela cumple con las normas de OpenTelemetry y exporta los rastros de forma asincrónica mediante NATS a un punto final OTEL configurable (gRPC o HTTP). Puedes dirigirlos a cualquier pila de observabilidad que ejecutes. Esto le brinda un panel de control único para todos los proveedores, en lugar de unir las métricas específicas de los proveedores.
Databricks lanzó el soporte de servidores MCP gestionados a mediados de 2025. Estos servidores permiten a los agentes acceder de forma segura a los recursos de Unity Catalog a través del protocolo Model Context. Databricks proporciona servidores gestionados para Genio (acceso a datos estructurados mediante lenguaje natural) y Búsqueda vectorial (datos no estructurados de índices vectoriales) y Funciones UC (funciones personalizadas registradas en Unity Catalog). Los permisos de Unity Catalog se aplican automáticamente para que los agentes solo puedan acceder a las herramientas y los datos cuya identidad esté autorizada.
El desafío de la gobernanza es lo que ocurre entre el agente y esos servidores MCP. Sin un plano de control, cada desarrollador configura sus propias conexiones, administra sus propias credenciales y crea sus propias políticas de herramientas. No hay un registro de auditoría centralizado que indique qué agente llamó a qué herramienta. No hay forma de imponer el acceso con privilegios mínimos en todos los equipos. No hay un lugar central para revocar el acceso cuando alguien se va.
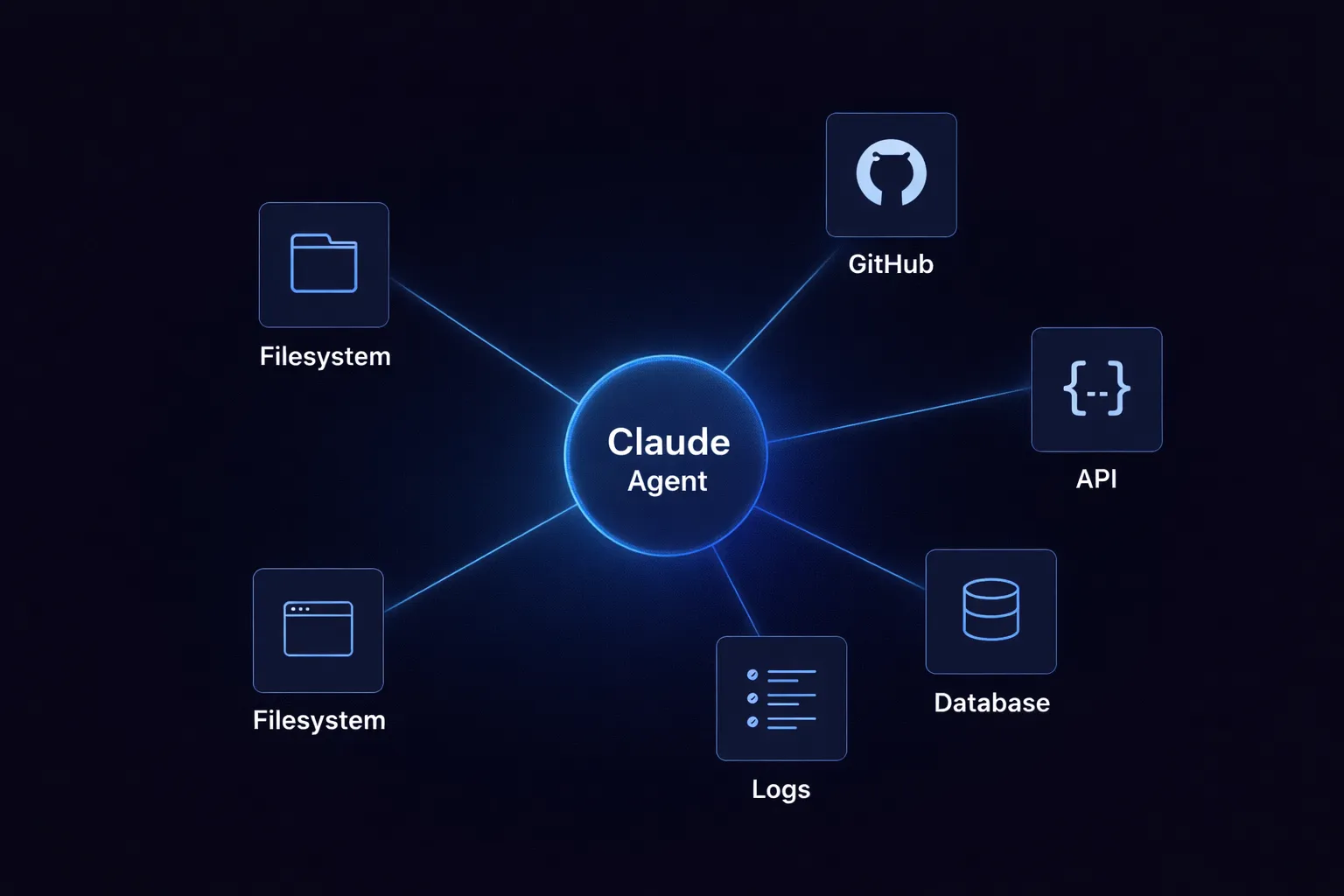
TrueFoundry MCP Gateway se encuentra entre sus agentes (Claude Code and Cursor y marcos de agentes personalizados) y sus servidores MCP (incluidos los servidores MCP gestionados por Databricks). Actúa como un proxy inverso con autenticación, autorización y registro de auditoría.
Flujo de autenticación. Los agentes se autentican una vez en MCP Gateway mediante una clave de API de TrueFoundry o un token de IdP externo (se admiten Okta y Azure AD y Auth0). La puerta de enlace gestiona la autenticación saliente en cada servidor MCP descendente. Para Databricks, esto significa que la puerta de enlace contiene las credenciales OAuth o PAT del principal del servicio y los agentes individuales nunca tocan las credenciales de Databricks sin procesar.
Control de acceso a nivel de herramienta. El Gateway le permite activar o desactivar de forma selectiva herramientas individuales por equipo. También puede agregar herramientas de varios servidores MCP en un Servidor MCP virtual que expone solo un subconjunto seleccionado. Por ejemplo, su equipo de ciencia de datos podría tener acceso a Genie y Vector Search desde Databricks, además de a un servidor de búsqueda web, mientras que su equipo de ingeniería tendría un conjunto de herramientas diferente.
Barandas. El Gateway sostiene barandas en cuatro ganchos. Herramienta MCP Pre las barandas se ejecutan antes de que se llame a la herramienta y pueden validar las consultas SQL, comprobar la existencia de datos confidenciales y hacer cumplir las políticas de permisos. Si alguna de las barandillas anteriores a la herramienta falla, la herramienta nunca se ejecuta. Herramienta MCP Post las barandillas inspeccionan y, opcionalmente, reescriben los resultados de la herramienta antes de devolver los resultados al modelo. Puede configurarlos para buscar información de identificación personal y información confidencial en los resultados. Los flujos de trabajo de aprobación de los usuarios se pueden configurar para operaciones de alto riesgo. Hay tres estrategias de cumplimiento disponibles: Hacer cumplir (bloquear en caso de infracción o error de barandilla) y Aplicar pero ignorar en caso de error (bloquear en caso de infracción pero permitir un error en el servicio de barandilla) y Auditoría (solo iniciar sesión y nunca bloquear).
Registro de auditoría. Cada invocación de la herramienta se rastrea con el usuario que llama y el servidor MCP y la carga útil y la latencia específicas de la herramienta y la solicitud y la carga útil de respuesta. Esto se exporta a través de OpenTelemetry junto con el seguimiento de sus solicitudes de LLM, lo que le brinda un registro unificado de todo lo que hacen sus agentes.
Si sus desarrolladores usan Claude Code, usted configura el MCP Gateway como un servidor MCP remoto. La gobernanza empresarial requiere dos archivos de configuración independientes que se implementen mediante MDM en los dispositivos corporativos.
El configuración-administración.json el archivo controla los servidores MCP a los que Claude Code puede conectarse:
{
«Servidores MCP permitidos»: [
{«URL del servidor»: "https://mcp-gateway.your-company.com/ *»}
],
«Mercados conocidos estrictos»: []
}
Configuración Mercados conocidos estrictos a una matriz vacía bloquea todas las instalaciones de MCP de origen comercial. Combinado con Servidores MCP permitidos esto crea una configuración bloqueada en la que los agentes solo pueden acceder a las herramientas a través de su puerta de enlace gobernada.
El mcp.json administrado el archivo define las conexiones reales del servidor MCP. Implemente esto mediante MDM en la ruta a nivel del sistema (/Biblioteca/Soporte de aplicaciones/ClaudeCode/Managed-MCP.json en macOS o /etc/claude-code/managed-mcp.json en Linux):
{
«catálogo unitario de databricks»: {
«tipo»: «http»,
«url»: "https://mcp-gateway.your-company.com/mcp/v1/databricks-uc/mcp»
},
«databricks-sql»: {
«tipo»: «http»,
«url»: "https://mcp-gateway.your-company.com/mcp/v1/databricks-sql/mcp»
}
}
Cuándo mcp.json administrado se implementa a través de MDM y toma el control exclusivo. Los desarrolladores no pueden agregar ni usar servidores MCP más allá de lo definido en este archivo. Las decisiones de control de acceso se toman en la puerta de enlace, por lo que solo es necesario actualizar el archivo MDM implementado al agregar o eliminar integraciones de servidores completas.
Para obtener una guía completa sobre la protección de Claude Code en entornos empresariales, incluidos los scripts de implementación de MDM y la aplicación de entornos aislados, y el esquema completo de configuración gestionada, consulte Seguridad empresarial para Claude documentación.
Este punto de integración es específico para los equipos que perfeccionan los modelos en Databricks mediante Mosaic AI Training y desean ofrecerlos junto con los modelos de API comerciales a través de un único punto final.
La configuración es la siguiente. El modelo se ajusta e implementa a través de Databricks Model Serving para que esté disponible como punto final de servicio. Usted registra Databricks como proveedor en AI Gateway tal y como se describe anteriormente. Creas un modelo virtual con un enrutamiento basado en prioridades que primero prueba tu modelo hospedado en Databricks y recurre a una API comercial:
configuración_de enrutamiento:
tipo: enrutamiento basado en prioridades
objetivos de equilibrio de carga:
- objetivo: databricks-main/custom-finetuned-llama-3
prioridad: 0
- objetivo: anthropic-main/claude-sonnet-4-5
prioridad: 1
Todo el tráfico va a su modelo personalizado alojado en Databricks de forma predeterminada. Si Databricks devuelve un error en el servidor, se agota el tiempo de espera o alcanza un límite de velocidad, el Gateway vuelve a intentarlo automáticamente en Claude Sonnet. Los códigos de estado alternativos que activan este comportamiento son 401 y 403 y 404 y 429 y 500 y 502 y 503. El código de la aplicación nunca sabe que se ha producido la conmutación por error. Obtiene una respuesta correcta del identificador del modelo virtual.
Este patrón es útil durante la evaluación del modelo. Puede gestionar ambos proveedores en paralelo mediante un enrutamiento basado en la ponderación dividido en partes iguales y registrar las respuestas y comparar la calidad antes de optar por un modelo ajustado para todo el tráfico. Los rastreos por solicitud de Gateway incluyen el proveedor resuelto que entregó cada respuesta (devuelta en el x-tfy-modelo resuelto encabezado de respuesta) para que puedas filtrar y analizar por proveedor en tu pila de observabilidad.
Los flujos de trabajo de TrueFoundry se basan en Flyte y proporcionan una forma de organizar canalizaciones de varios pasos según gráficos acíclicos de tareas dirigidos. Cada tarea se ejecuta en su propio contenedor con recursos y dependencias definidos. La integración de Databricks añade un tipo de tarea nativo que activa los trabajos de Databricks existentes desde estos flujos de trabajo, de modo que el procesamiento de datos y el entrenamiento de modelos basados en Spark puedan combinarse con las tareas nativas de TrueFoundry, como la implementación y la evaluación de modelos.
Una tarea de Databricks usa el estándar @task decorador con un Configuración de DataBricks JobTask que especifica el espacio de trabajo de Databricks y el trabajo que se va a activar. En primer lugar, la tarea llama a la API Databricks Jobs ejecutar_ahora () punto final con un token de idempotencia derivado del ID de ejecución de Flyte. Esto garantiza que la misma ejecución de flujo de trabajo lógico nunca envíe trabajos duplicados de Databricks, incluso si el pod de tareas se vuelve a intentar.
desde la importación de truefoundry.workflow (
Configuración de DataBricks JobTask,
Task Python Build,
tarea,
flujo de trabajo,
)
@task (
TASK_CONFIG=DataBricksJobTaskConfig (
image=taskPythonBuild (
pip_packages= ["truefoundry [flujo de trabajo]"],
),
<your-workspace>workspace_host="https://.cloud.databricks.com»,
service_account="flyte-databricks-es»,
job_id="123",
timeout_seconds=2000,
)
)
def run_databricks_training ():
print («Trabajo de capacitación en Databricks completado»)
@task
def deploy_model ():
# Implemente el modelo entrenado como punto final de la API
pase
@workflow ()
def train_and_deploy ():
run_databricks_training ()
deploy_model ()
El proceso de la tarea en sí mismo se ejecuta en un contenedor ligero definido por imagen campo. La ejecución real del trabajo ocurre completamente en Databricks. De forma predeterminada, la tarea sondea hasta que finalice la ejecución de Databricks o hasta segundos de tiempo de espera transcurre. Si se alcanza el tiempo de espera, la ejecución de Databricks se cancela y un Error de tiempo de ejecución está levantado. Si configuras salte_espera_finalización_ a Cierto la tarea regresa inmediatamente después de activar el trabajo sin esperar a que finalice.
El Configuración de DataBricks JobTask acepta los siguientes campos.
La tarea admite dos métodos de autenticación. Token de acceso personal la autenticación funciona cuando TOKEN DE ACCESO PERSONAL DE DATABRICKS_ se establece en el entorno de la tarea. La PAT se inyecta a través del env campo en la configuración de la tarea utilizando una referencia secreta para que el token nunca esté codificado.
Federación de tokens de OAuth es la alternativa cuando no hay ningún PAT establecido. Esto requiere DATABRICKS_SERVICE_PRINCIPAL_CLIENT_ID en el entorno y en un Kubernetes cuenta_servicio en el panel de tareas. El token de la cuenta de servicio de Kubernetes se cambia por un token de acceso a Databricks a través del punto final OIDC del espacio de trabajo. El espacio de trabajo de Databricks debe tener configurada la federación OIDC para que esta ruta funcione.
La federación de tokens de OAuth evita almacenar por completo las credenciales de Databricks de larga duración. El token de la cuenta de servicio de Kubernetes es de corta duración y está limitado al módulo de tareas. El intercambio de OIDC se produce en tiempo de ejecución, por lo que no hay secretos que rotar o administrar.
El caso de uso típico es un proceso en el que la preparación de datos y el entrenamiento de modelos se ejecutan en Databricks (porque ahí es donde residen los datos de Delta Lake y donde se aprovisionan los clústeres de Spark) y los pasos posteriores, como el registro, la implementación y la evaluación de modelos, se ejecutan en TrueFoundry. La tarea de Databricks une los dos entornos en una única definición de flujo de trabajo. Obtiene la resolución de dependencias de Flyte y vuelve a intentar utilizar la semántica y el almacenamiento en caché en todo el proceso, en lugar de unir sistemas de orquestación independientes.
La integración entre Databricks y TrueFoundry funciona en tres capas. La capa AI Gateway registra el modelo de servicio de Databricks como proveedor y dirige el tráfico de inferencias a través del mismo punto final unificado que gestiona todos los demás proveedores. Los modelos virtuales permiten el enrutamiento entre múltiples proveedores con una conmutación por error automática entre los modelos alojados de Databricks y las API comerciales. La capa MCP Gateway se encuentra frente a los servidores MCP gestionados por Databricks y centraliza la autenticación y el control de acceso a nivel de herramienta y el registro de auditorías para los flujos de trabajo de los agentes. La capa de flujo de trabajo activa los trabajos de Databricks como tareas nativas dentro de las canalizaciones basadas en Flyte, de modo que las cargas de trabajo de Spark se compongan con los pasos de implementación y evaluación de TrueFoundry en un solo DAG.
No se requieren sidecars. No es necesario realizar cambios en el SDK en el código de la aplicación. La capa adaptadora del Gateway se traduce entre el formato compatible con OpenAI y el formato Databricks Model Serving de forma transparente. La única configuración requerida es el registro del proveedor con las credenciales de autenticación y el mapeo de puntos finales modelo.
El diseño que hace que esta integración sea limpia es la arquitectura sin llamadas externas del plano de puerta de enlace. Todas las decisiones de autenticación, autorización y enrutamiento se toman en función del estado de la memoria sincronizado mediante NATS. El único salto de red que se añade a cualquier solicitud es el propio módulo de puerta de enlace, que añade aproximadamente 3 ms de latencia. Todo lo demás, como la limitación de tarifas y la aplicación del presupuesto, el seguimiento del estado y la recopilación telemétrica, se realiza de forma asincrónica sin tocar la ruta de la solicitud.
Para ver la documentación completa de AI Gateway, consulte la Documentos de TrueFoundry. Para ver la configuración del proveedor de Databricks, consulte Modelos Databricks. Para ver la configuración de MCP Gateway, consulte Descripción general de MCP Gateway. Para la integración del flujo de trabajo, consulte Creación de una tarea de Databricks.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.







Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada
© 2025 Todos los derechos reservados.





.png)


.webp)


.webp)