

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: May 20, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
En 2026, las empresas ya no pueden permitirse el lujo de modificar una puerta de enlace de LLM en una puerta de enlace de IA improvisada. La IA no hará más que integrarse cada vez más en los flujos de trabajo orientados a los clientes, lo que hará que una capa de puerta de enlace dedicada no sea negociable para aplicaciones confiables impulsadas por la inteligencia artificial. La infraestructura de IA empresarial típica suele ser multimodelo, multiequipo y multinube, lo que conlleva un cumplimiento complejo y una rendición de cuentas de costes.
Gartner define una puerta de enlace de IA como una tecnología o plataforma que actúa como intermediaria entre las aplicaciones y varios servicios o modelos de inteligencia artificial (IA). Su propósito es simplificar y gestionar el acceso a las capacidades de la IA, proporcionando un punto central que permita la seguridad, la gobernanza y la observabilidad de las cargas de trabajo de la IA. Lea el texto completo Guía de mercado de Gartner para pasarelas de IA 2025 para obtener más información.
Durante el último año, hemos visto surgir tres categorías amplias para abordar el problema de la gobernanza y la resiliencia de GenAI:
Cada categoría se optimiza para una fase diferente de adopción de la IA. Los problemas surgen cuando las herramientas optimizadas para una fase se utilizan para gestionar otra.
En este blog, reunimos todas las investigaciones sobre la competencia en un panorama definitivo y explicamos dónde encaja cada plataforma, dónde se desglosa y qué deben tener en cuenta las empresas al elegir el proveedor que mejor se adapte a sus requisitos.
1. Kong AI: puerta de enlace de API tradicional adaptada a la IA
Kong es una puerta de enlace de API que se usa con frecuencia en arquitecturas de microservicios basadas en Kubernetes. Kong AI se basa en esta base al introducir complementos e integraciones diseñados para dirigir el tráfico a modelos lingüísticos de gran tamaño.
Qué hace bien Kong AI
Dónde se estropea la IA de Kong
A medida que aumenta el uso de la IA, estas brechas se hacen más visibles. La atribución de costes, las estrategias de selección de modelos y la gobernanza específica de la IA deben gestionarse fuera de la pasarela, a menudo dentro del código de la aplicación.
En pocas palabras: Kong AI es eficaz como puerta de enlace de API, pero la IA sigue siendo una preocupación secundaria más que una abstracción nativa.
2. Portkey: puerta de enlace LLM a nivel de aplicación
Portkey es una puerta de enlace de IA diseñada específicamente para aplicaciones de LLM. En lugar de tratar las solicitudes de IA como llamadas HTTP genéricas, Portkey presenta un enrutamiento y una capacidad de observación rápidos y compatibles con el modelo.
Qué hace bien Portkey
Donde Portkey se queda corto
El diseño de Portkey se centra intencionalmente en las aplicaciones, lo que introduce restricciones a escala empresarial
A medida que la IA se convierte en una capacidad interna compartida en lugar de en una función de aplicación única, estas limitaciones suelen requerir capas de infraestructura adicionales.
Ideal para: Las aplicaciones de LLM de un solo equipo pasan a la fase inicial de producción.
3. LitELLM: puerta de enlace de código abierto centrada en los desarrolladores
LitellM es una pasarela de LLM de código abierto que proporciona una API unificada y compatible con OpenAI para acceder a docenas de proveedores de modelos.
Qué hace bien LitellM
Donde LitellM se queda corto
Ideal para: LitellM es un punto de entrada eficaz, pero requiere un aumento significativo para los entornos regulados o de varios equipos.
Lea también: Portkey contra LitellM
4. AWS Bedrock: API de modelos sin servidor
AWS Bedrock ofrece acceso administrado y sin servidor a los modelos básicos de proveedores como Anthropic y Amazon. Abstrae la infraestructura por completo y factura únicamente en función del uso de fichas.
Qué hace bien AWS Bedrock
Las ventajas y desventajas ocultas de AWS Bedrock
Estas compensaciones suelen sorprender a los equipos a medida que las cargas de trabajo pasan de la experimentación al uso sostenido en la producción.
En pocas palabras: Bedrock optimiza en función de la velocidad y la simplicidad, no de la rentabilidad o el control a largo plazo.
5. AWS SageMaker: infraestructura de aprendizaje automático administrada
SageMaker proporciona un conjunto completo para entrenar, ajustar e implementar modelos de aprendizaje automático. A diferencia de Bedrock, expone las opciones de infraestructura directamente a los usuarios.
Qué hace bien AWS Sagemaker
Inconvenientes de AWS Sagemaker
En pocas palabras: SageMaker ofrece control, pero a costa de la simplicidad operativa.
6. Databricks: la plataforma ML de Lakehouse
Databricks aborda la IA desde una perspectiva que prioriza los datos, integrando las capacidades de ML y GenAI en su arquitectura Lakehouse.
Qué hace bien Databricks
Donde Databricks se queda corto
En pocas palabras: Databricks se destaca en la ingeniería de datos, no en el servicio de inteligencia artificial.
El hilo conductor: pasarelas sin gobernanza
Al otro lado Kong contra LitellM, Portkey e incluso Bedrock, surge el mismo problema: gestionan las solicitudes, no los sistemas de IA.
En las pasarelas y los servicios gestionados, aparece un problema recurrente: la mayoría de las herramientas se centran en las solicitudes, no en los sistemas.
Responden a preguntas como:
Luchan con:
Estas son preocupaciones a nivel de infraestructura.
TrueFoundry ocupa una capa diferente en la pila. En lugar de centrarse únicamente en el enrutamiento de las API o en los servicios gestionados, trata las cargas de trabajo de la IA (modelos, agentes, servicios y trabajos) como objetos de infraestructura de primera clase. Esto traslada la responsabilidad del código de la aplicación a la propia plataforma.
La puerta de enlace de IA de TrueFoundry está diseñada con los siguientes principios básicos:
Esto significa que AI Gateway es un componente de un sistema más grande, lo que permite a las empresas escalar sus casos de uso de IA sin problemas.
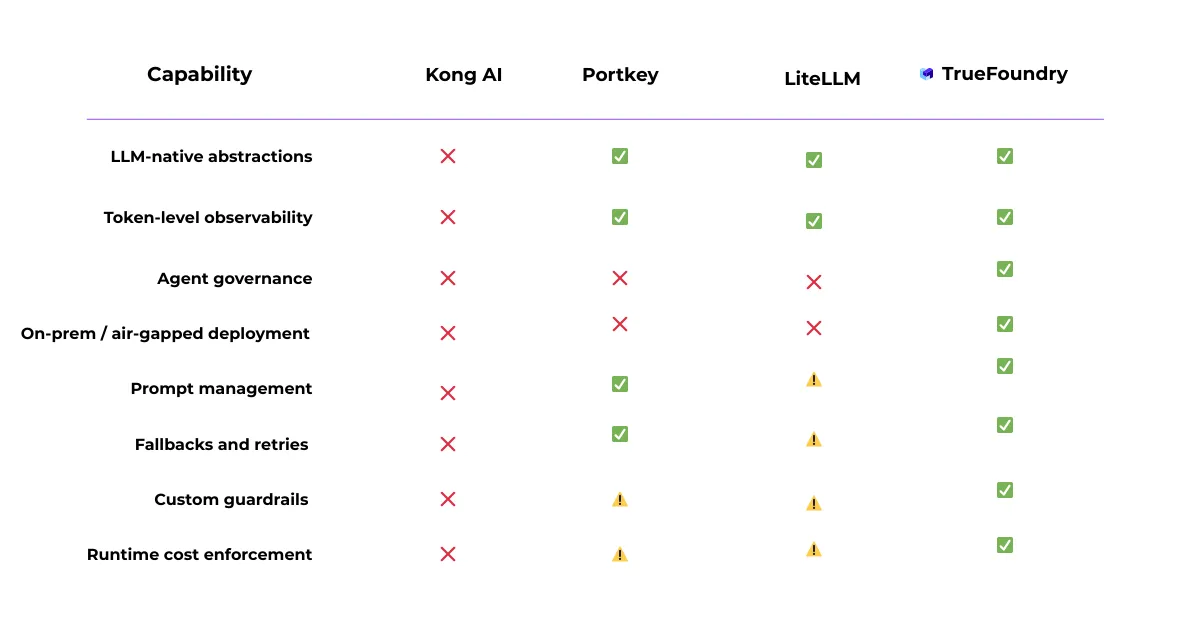
La puerta de enlace de IA de TrueFoundry se vuelve fundamental cuando el uso de la IA va más allá de las aplicaciones aisladas y se convierte en una capacidad compartida y crítica para la producción. En esa etapa, los desafíos suelen estar menos relacionados con las llamadas a modelos individuales y más con la coherencia operativa en todos los equipos y entornos.
Así es como AI Gateway de TrueFoundry se diferencia de otras soluciones:
Muchas herramientas de IA se centran en problemas a nivel de solicitud, como el enrutamiento, los reintentos y la observabilidad básica. Esto suele ser suficiente en las primeras etapas.
Sin embargo, a medida que aumenta el uso, los modelos y los agentes comienzan a comportarse más como servicios de larga duración. Los equipos necesitan una propiedad, una gestión del ciclo de vida y unos límites operativos más claros. TrueFoundry está diseñado para gestionar las cargas de trabajo de la IA (modelos, servicios y trabajos) como componentes de infraestructura con características de implementación y tiempo de ejecución definidas.
En muchas pilas, los controles de acceso y las políticas de uso se configuran a nivel de la aplicación o del SDK. Con el tiempo, esto puede generar incoherencias a medida que aumenta la cantidad de servicios.
TrueFoundry aplica controles a nivel de entorno, separando el desarrollo, la puesta en escena y la producción de forma predeterminada. Las políticas definidas en esta capa se aplican de manera uniforme a todas las cargas de trabajo implementadas en un entorno, lo que reduce la dependencia de la configuración por aplicación.
Los costos de la IA suelen aumentar debido a la concurrencia, los reintentos o las cargas de trabajo en segundo plano, más que a las solicitudes individuales. TrueFoundry aborda este problema imponiendo límites a la simultaneidad, el rendimiento y el uso de recursos durante la ejecución.
Esto permite a las organizaciones administrar la infraestructura compartida de manera más predecible a medida que aumenta el uso.
Si bien las métricas a nivel de token son útiles, no explican completamente el comportamiento del sistema en producción. TrueFoundry correlaciona las señales a nivel de solicitud con las métricas de la infraestructura, como la utilización de la CPU/GPU y el comportamiento del escalado automático, lo que ayuda a los equipos a comprender los factores que impulsan el rendimiento y los costos en su contexto.
Algunas organizaciones operan con restricciones que requieren redes privadas, implementaciones locales o una residencia estricta de los datos. TrueFoundry está diseñado para ejecutarse en estos entornos, lo que permite que las cargas de trabajo de IA se rijan mediante los mismos estándares de infraestructura que se aplican en otras partes de la organización.
Conclusión
El panorama actual de las plataformas de IA refleja la velocidad a la que ha evolucionado la IA generativa. Muchas herramientas abordan problemas reales (el enrutamiento, el acceso a modelos, la observabilidad o la capacitación), pero lo hacen desde diferentes puntos de partida. Como resultado, ninguna categoría cubre de forma natural el conjunto completo de requisitos operativos que surgen una vez que la IA se convierte en algo fundamental para la producción.
TrueFoundry ofrece el máximo valor cuando las cargas de trabajo de IA deben operarse con la misma disciplina que otros sistemas de producción: en todos los entornos, con políticas compartidas y con un comportamiento predecible de los recursos.
Las empresas que comparan proveedores suelen empezar por buscar mejor puerta de enlace LLM, pero el verdadero diferenciador radica en la forma en que la plataforma gobierna los sistemas de IA a escala. Es esencial comprender dónde encaja cada plataforma y dónde comienzan a fallar sus suposiciones de diseño. La elección correcta depende menos de las características individuales y más de la forma en que la organización espera que su uso de la IA evolucione con el tiempo.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


