Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
9,9
Resolver los cuellos de botella de datos de SEO con Autonomous Agents y TrueFoundry
Published: April 22, 2026
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Gestiona más de 350 RPS en solo 1 vCPU, sin necesidad de ajustes
Listo para la producción con soporte empresarial completo
Es lunes por la mañana. Tu líder de SEO está mirando tres pestañas diferentes del navegador: Google Search Console (GSC), Looker Studio y una hoja de cálculo que se bloquea si te desplazas demasiado rápido. Exportan manualmente miles de filas de datos de consultas, intentan comparar el rendimiento de la semana pasada con el mismo rendimiento que la semana pasada y aplican filtros subjetivos para decidir para qué debe crear el contenido el equipo de ingeniería a continuación.
Este es el problema de la «última milla» del análisis de datos. Disponemos de herramientas de recopilación sofisticadas, pero la síntesis propiamente dicha (la fase de toma de decisiones) se basa en el frágil pegamento humano.
En TrueFoundry, nos dimos cuenta de que nuestro flujo de trabajo de ingeniería de crecimiento estaba bloqueado por esta agregación manual. No nos limitaban los datos, sino el rendimiento del análisis humano. Para solucionar este problema, no compramos otra herramienta de panel de control. Construimos el Agente de automatización de palabras clave, un sistema que trata las métricas de SEO como un flujo de ingeniería en lugar de un informe estático, impulsado por la puerta de enlace de IA de TrueFoundry y el Model Context Protocol (MCP).
El cambio técnico: del análisis estático a las tuberías adaptativas
El enfoque estándar para las operaciones de SEO es Basado en encuestas y manual: los humanos obtienen datos periódicamente, aplican reglas codificadas (por ejemplo, «volumen > 100") y adivinan la relevancia.
Nos cambiamos a un Impulsado por eventos y probabilístico modelo:
Puntuación determinista: Las matemáticas manejan las métricas obvias (deltas del CTR, distancia de rango).
Filtrado probabilístico: Los LLM inyectan contexto empresarial (por ejemplo, saber que «AI Gateway» es relevante para nosotros, pero «Gateway Computer Drivers» no lo es).
Abstracción de herramientas (MCP): Se accede a las fuentes de datos externas (Ahrefs, Google Trends) mediante protocolos estandarizados, no mediante frágiles envoltorios de API.
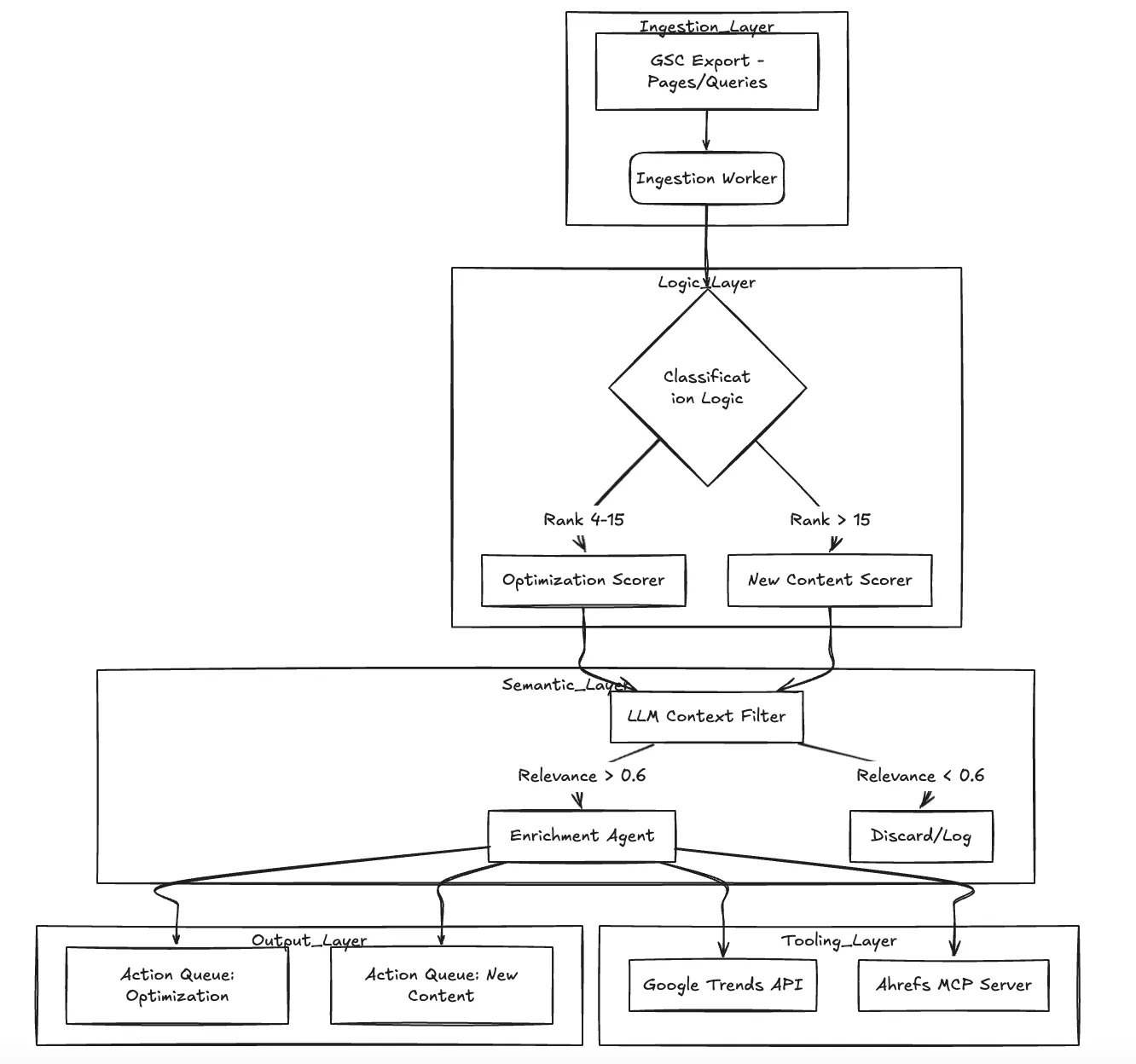
Análisis profundo de la arquitectura
El sistema funciona como un gráfico acíclico dirigido (DAG) de las etapas de procesamiento. No solo «resume» los datos, sino que los filtra y enriquece activamente.
Componentes principales:
Trabajador de ingestión: Analiza las exportaciones de CSV sin procesar de GSC (páginas y consultas).
Controlador de puntuación: Aplica la lógica matemática. Para la optimización, utilizamos una función de decaimiento basada en la distancia: $Score =\ log (1 + impressions)\ times (1 - CTR)\ times (\ max (0, 20 - position)) $.
Agente de relevancia (LLM): Actúa como guardián semántico. Evalúa las palabras clave comparándolas con el contexto de dominio de TrueFoundry (Kubernetes, LLM Ops, plataformas para desarrolladores) para filtrar el ruido.
Trabajador de enriquecimiento: Obtiene datos de tendencias y (en la versión 2) métricas de dificultad externas a través de MCP.
Infraestructura y TrueFoundry: Gateway y MCP
La implementación de esta arquitectura presenta dos desafíos principales para los sistemas distribuidos: Limitación de velocidad y Integración de herramientas.
Si simplemente recorres 5000 palabras clave y accedes a una API de LLM para obtener la puntuación de relevancia, alcanzarás los límites de tasa de inmediato. Si codificas las llamadas a la API de Ahrefs en tu agente, crearás un acoplamiento estrecho que se interrumpe cada vez que cambia una versión de la API.
Hemos utilizado el Plataforma TrueFoundry para resolver ambos:
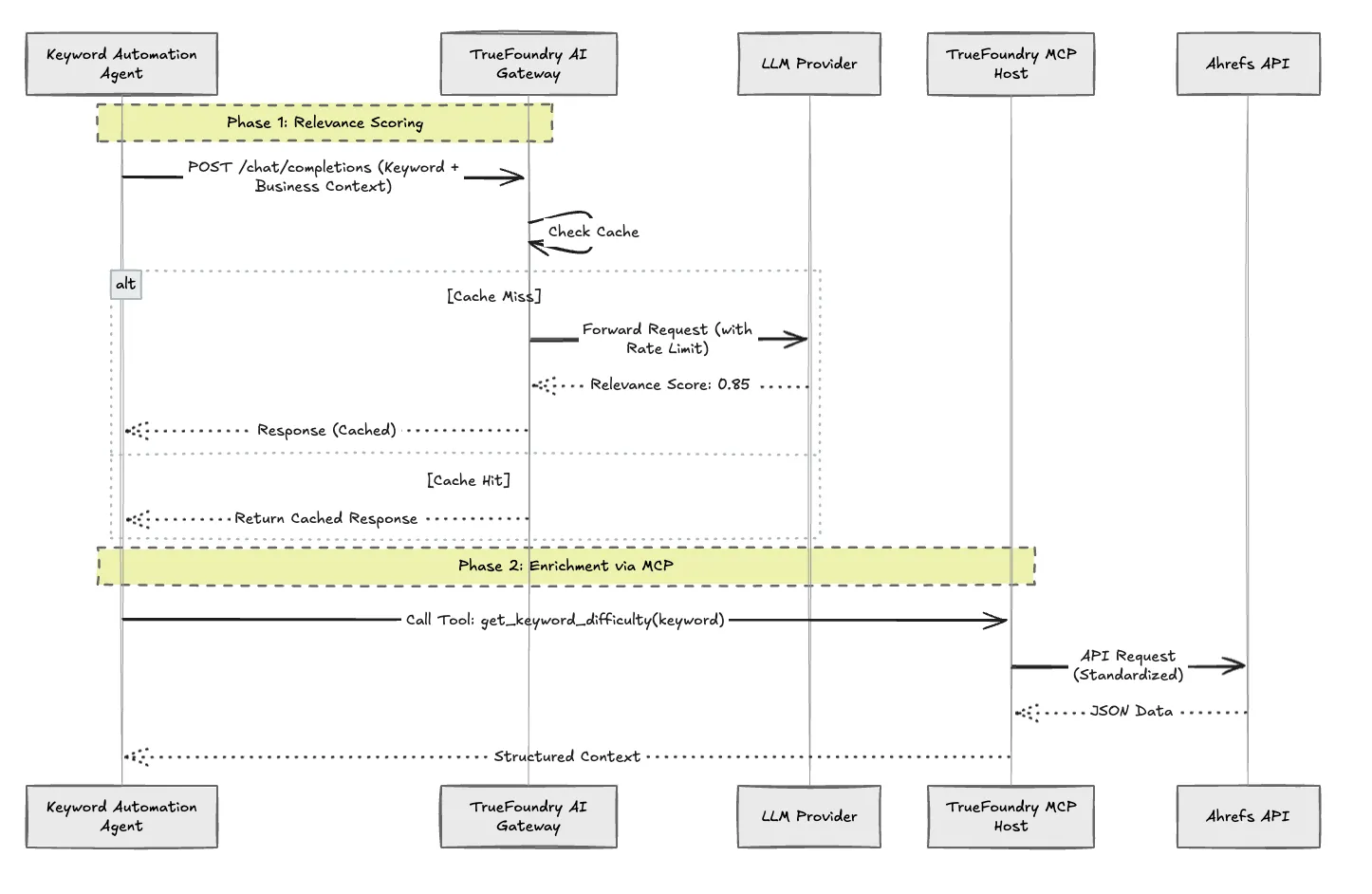
Puerta de enlace de IA de TrueFoundry: Dirigimos todas las convocatorias de LLM (para la puntuación de relevancia y la generación de resúmenes) a través del Gateway. Esto proporciona:
Limitación de velocidad centralizada: Establecemos un presupuesto de solicitudes por minuto a nivel de puerta de enlace para proteger a nuestros proveedores intermedios.
Almacenamiento en caché: Si ya calificamos la palabra clave «LLM Observability» la semana pasada, el Gateway emite el veredicto almacenado en caché, lo que reduce la latencia y el costo a cero.
Modelo de enrutamiento: Podemos cambiar el modelo subyacente (por ejemplo, de GPT-4 a un modelo más barato y rápido como Gemini Flash) para la tarea de clasificación sin cambiar una línea del código de la aplicación.
Protocolo de contexto modelo (MCP): En lugar de escribir funciones personalizadas para Ahrefs, implementamos un Servidor Ahrefs MCP en TrueFoundry. El agente simplemente consulta el servidor MCP para ver las métricas del explorador del sitio o la dificultad de las palabras clave. El servidor MCP se encarga de la autenticación y los detalles de la API. Esto estandariza la forma en que nuestros agentes se comunican con las herramientas externas.
Fragmento de código
Comparación: Standard Scripting frente a TrueFoundry Accelerator
La siguiente tabla destaca por qué pasamos de los scripts locales de Python a una arquitectura gestionada.
Dimension
Standard Python Script Approach
TrueFoundry Accelerator Approach
Resilience
Fragile. If the GSC API times out or the script hits an LLM rate limit, the entire process crashes. Requires manual restarts.
High. TrueFoundry Gateway handles retries and exponential backoff. Process isolation ensures one failed batch doesn't kill the pipeline.
Security
Low. API keys for OpenAI and Ahrefs are often stored in local .env files or hardcoded.
Enterprise. Keys are managed in TrueFoundry Secrets. Agents access tools via authenticated MCP endpoints, never touching raw credentials.
Scalability
Vertical. Limited by the local machine's memory when processing large CSVs combined with trend data.
Horizontal. Workers run as microservices on Kubernetes. We can parallelize the scoring of 10,000 keywords across multiple pods.
Maintenance
High. Every time Ahrefs changes an API endpoint, the main application code must be refactored.
Low. Tool logic is isolated in the MCP Server. The core agent logic remains untouched during external API updates.
Manejo de casos extremos y confiabilidad
En un entorno de producción, los datos rara vez están limpios. Hemos implementado barreras de protección específicas para garantizar la confiabilidad:
La puerta de la «alucinación»: Los LLM pueden ser demasiado confiados. Hemos implementado una puerta lógica en la que si la relevancia es falsa y la confianza es inferior a 0,6, la palabra clave se descarta como ruido. Sin embargo, si la relevancia es verdadera pero la confianza es inferior a 0,5, se marca para que sea revisada por humanos en lugar de procesarla automáticamente.
Divergencia de tendencia: Un modo de error común en el SEO es la optimización para una palabra clave moribunda. Nuestro experto en enriquecimiento comprueba las tendencias de Google. Si Impression_Trend se mantiene estable pero Market_Trend sube, significa que se ha perdido una oportunidad. Si Impression_Trend sube pero Market_Trend es cero, indica una posible anomalía botológica o un repunte estacional, lo que evita desperdiciar esfuerzo.
Conclusión
Al trasladar el flujo de trabajo de SEO de hojas de cálculo manuales a un flujo de trabajo de agencia en TrueFoundry, redujimos el tiempo de obtención de información de días a minutos. Y lo que es más importante, desvinculamos la lógica de la infraestructura. El portal de IA de TrueFoundry gestiona el «costo de la cognición» (llamadas de LLM), mientras que el MCP gestiona la «complejidad de la integración» (herramientas externas).
Esta arquitectura demuestra que las herramientas internas no tienen por qué ser scripts pirateados. Pueden ser sistemas resilientes y escalables que impulsen el valor empresarial real.
Implemente este acelerador de la biblioteca TrueFoundry hoy mismo para estandarizar sus propios flujos de trabajo de enriquecimiento de datos.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga





























.png)

.webp)
.webp)
.webp)



.webp)
.webp)


