Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
9,9
AI Gateway: el panel de control central de la infraestructura de IA generativa actual
En nuestro reciente seminario web sobre AI Gateway, empezamos comprobando la situación actual de la audiencia en su viaje hacia la IA generativa (GenAI).
Curiosamente, más del 50% dijo que ya tiene GenAI en producción, y otro 15% lo está escalando en varios equipos, señales claras de una fuerte adopción empresarial y de una creciente madurez en la implementación de las aplicaciones de GenAI.
La evolución de la puerta de enlace LLM como plano de control central
Nos centramos en cómo Puerta de enlace de IA ha evolucionado en los últimos 6 a 9 meses, pasando de ser una capa de enrutamiento modelo básica a convertirse en un plano de control central crítico dentro de la moderna pila de IA generativa
Inicialmente, los LLM se utilizaban principalmente para generar respuestas de un solo turno a las solicitudes, vistas en gran medida como predictores avanzados de la siguiente palabra.
Estado actual de los agentes: Avanzando rápidamente hasta 2025, los agentes impulsados por LLM se han vuelto autónomos y orientados a objetivos, capaces de invocar múltiples herramientas y sistemas entre bastidores. Por ejemplo, un agente de restablecimiento de contraseñas puede autenticar a un usuario, llamar a las API para restablecer las contraseñas y enviar correos electrónicos de confirmación, todo ello sin intervención humana.
Complejidad organizacional: Las empresas suelen ejecutar docenas de agentes tan complejos que abarcan varios equipos y utilizan varios modelos de diferentes proveedores, marcos e infraestructuras (incluidos los hiperescaladores y las nubes híbridas).
Desafíos sin centralización: Esta descentralización provoca importantes problemas de gobernanza, incluidas inconsistencias en las API de los modelos, la capacidad de implementación, la auditabilidad, la administración de costos y las estrategias de conmutación por error.
La pasarela de LLM se ha vuelto indispensable como puerta de entrada central que consolida estos diversos recursos y necesidades operativas, lo que permite la gobernanza, la observabilidad, el control de costos y la confiabilidad a escala.
Desafíos que enfrentan las empresas que utilizan múltiples proveedores de LLM
Formatos de API inconsistentes: A pesar de las afirmaciones generales sobre la compatibilidad de la API OpenAI, los proveedores difieren en la sintaxis de los parámetros (por ejemplo, el máximo de tokens, los rangos de temperatura, las secuencias de parada), lo que complica la intercambiabilidad y la interoperabilidad.
Interrupciones frecuentes: Los proveedores de modelos son en sí mismos empresas emergentes, y los frecuentes tiempos de inactividad provocan errores en las aplicaciones; por lo tanto, las aplicaciones deben ser independientes del modelo y poder realizar una conmutación por error sin problemas.
Varianza de alta latencia: La latencia entre los proveedores fluctúa ampliamente, lo que hace que el rendimiento de las aplicaciones sea impredecible. La latencia afecta a la experiencia del usuario tan gravemente como el tiempo de inactividad total.
Límites de tarifas complejos: Los múltiples límites de tarifas por proveedor requieren limitaciones y controles de costos en todas las unidades de negocio y centros de costos. La aplicación centralizada es difícil pero esencial.
Demandas de infraestructura híbrida: Muchas empresas deben gestionar los límites de velocidad y las rotaciones de claves entre los proveedores de nube y la infraestructura de GPU local.
Consultas repetidas costosas: Las aplicaciones de IA generativa suelen recibir muchas consultas idénticas o semánticamente similares (por ejemplo, mensajes de saludo), lo que aumenta la coste de la IA generativa innecesariamente a menos que sea mitigado por almacenamiento en caché semántico.
Barandas y cumplimiento: Las empresas requieren un filtrado rápido de las entradas (por ejemplo, que no se filtre la PII) y la validación de los resultados (filtrando las blasfemias) en varios equipos y modelos, lo que requiere una aplicación centralizada.
Requisitos de gobierno y auditoría: Las solicitudes pueden abarcar varios proveedores y fuentes de datos dentro de una sola acción de interfaz de usuario, por lo que las empresas exigen una observabilidad, un registro de auditorías, una explicabilidad y una trazabilidad centralizados para satisfacer las necesidades de cumplimiento.
Estos desafíos justifican el papel de la puerta de enlace LLM como el plano de control central en los ecosistemas de IA generativa empresarial.
Funciones y beneficios principales de una puerta de enlace de inteligencia artificial
Una puerta de enlace de IA desempeña un papel clave a la hora de abordar estos desafíos al ofrecer una gama de capacidades técnicas diseñadas para optimizar el acceso, la gobernanza y la confiabilidad de los modelos.
Funcionalidades clave de Gateway:
Capa de API unificada: Proporciona una interfaz API única y coherente que abstrae los detalles y mecanismos de autenticación específicos del proveedor. Esto garantiza:
Sin dependencia de un proveedor.
Cambio de proveedor sin problemas sin cambios de código.
Uso simplificado del SDK para desarrolladores.
Administración centralizada de claves: administra diversos métodos de autenticación (funciones de AWS IAM, claves de API de OpenAI, identidades de GCP) a través de un sistema unificado. Los beneficios incluyen:
Emisión de claves de API a nivel de usuario para la trazabilidad.
Cuentas de servicio o claves virtuales para aplicaciones.
Fácil rotación y gestión de claves.
Evita el intercambio general de claves de API y permite controles de permisos más precisos.
Reintentos y devoluciones: Gestiona las interrupciones de los proveedores sin problemas con políticas de conmutación por error automatizadas. El respaldo configurable de un modelo a otro garantiza un servicio ininterrumpido sin afectar al código de la aplicación.
Limitación de tarifas y controles de costos: Permite la aplicación precisa de las políticas de uso de la API por usuario, aplicación o unidad de negocio. Entre los ejemplos se incluyen:
Límites de llamadas diarias para desarrolladores.
Niveles de usuarios premium con cuotas diferenciadas.
Protección contra agentes incontrolados que invocan bucles infinitos, lo que evita picos de facturación inesperados.
Equilibrio de carga: automatiza el enrutamiento de las solicitudes al modelo más rápido o confiable en tiempo real, realizando comprobaciones de estado y balanceo de carga basadas en la latencia.
Canary lanza nuevos modelos: Facilita la implementación gradual y controlada de las nuevas versiones del modelo, lo que permite realizar pruebas y comparar el rendimiento antes de la migración completa.
Diferentes tipos de equilibrio de carga
Barandas centrales : Implementa filtros de aviso y respuesta en toda la empresa, como:
Eliminación de PII antes de enviar datos de forma externa.
Detección y eliminación de contenido blasfemo o dañino en las respuestas.
Capacidad para bloquear o mutar las indicaciones de forma centralizada.
Integración transparente para que los desarrolladores de aplicaciones no tengan que gestionar estas reglas de forma individual.
Almacenamiento en caché semántico: Mantiene una caché de pares de respuesta y respuesta semánticamente similares para reducir las llamadas a modelos y disminuir la latencia y los costos de las consultas repetitivas.
Ventajas clave
Una gobernanza central sólida para las empresas.
Capacidad inmediata de intercambiar modelos y proveedores sin tiempo de inactividad.
Acceso auditable y observable a todas las interacciones del modelo con métricas granulares.
Reducción del esfuerzo de ingeniería para gestionar la complejidad de varios modelos.
Experiencia de usuario mejorada con optimizaciones de conmutación por error y latencia.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Visión futura: integración con servidores MCP con AI Gateway
En el futuro, la pasarela LLM se extenderá más allá de los modelos para administrar herramientas y agentes completos a través de los protocolos MCP y A2A -
¿Qué es un servidor MCP?
Un servidor MCP expone las API de los productos (por ejemplo, los canales, los mensajes y los usuarios de Slack) de una forma que los agentes de LLM pueden descubrir y consumir.
Ejemplo: un servidor MCP de Slack expone las API para leer canales, mensajes y enviar mensajes, todo ello comprensible para un agente de LLM.
Interacción del agente con los servidores MCP:
Los agentes consultan el servidor MCP para identificar las herramientas disponibles.
En función de una solicitud en lenguaje natural, el agente planifica y llama de forma autónoma a la secuencia correcta de herramientas (p. ej., recuperar mensajes, resumir o crear tareas de Jira).
Integración de Gateway con MCP:
La puerta de enlace actuará como un punto de acceso unificado para los modelos LLM y los servidores MCP dentro de una organización.
Los usuarios podrán emitir comandos en lenguaje natural (por ejemplo, «Crear tareas en Jira a partir de mis mensajes de Slack») en las herramientas integradas sin necesidad de programar.
La autenticación se administrará sin problemas y se federará a través de los proveedores de identidad existentes, como Okta o Azure AD.
Esta integración permite a los usuarios no técnicos automatizar fácilmente los procesos empresariales.
Punto de acceso unificado para los modelos LLM y los servidores MCP dentro de una organización
Analizar y clasificar las alertas mediante la combinación de los datos de la API de Datadog y GitHub.
Programación de flujos de trabajo recurrentes utilizando múltiples herramientas de software empresarial.
Auditoría y control centralizados de todas las actividades de los agentes y las invocaciones de herramientas.
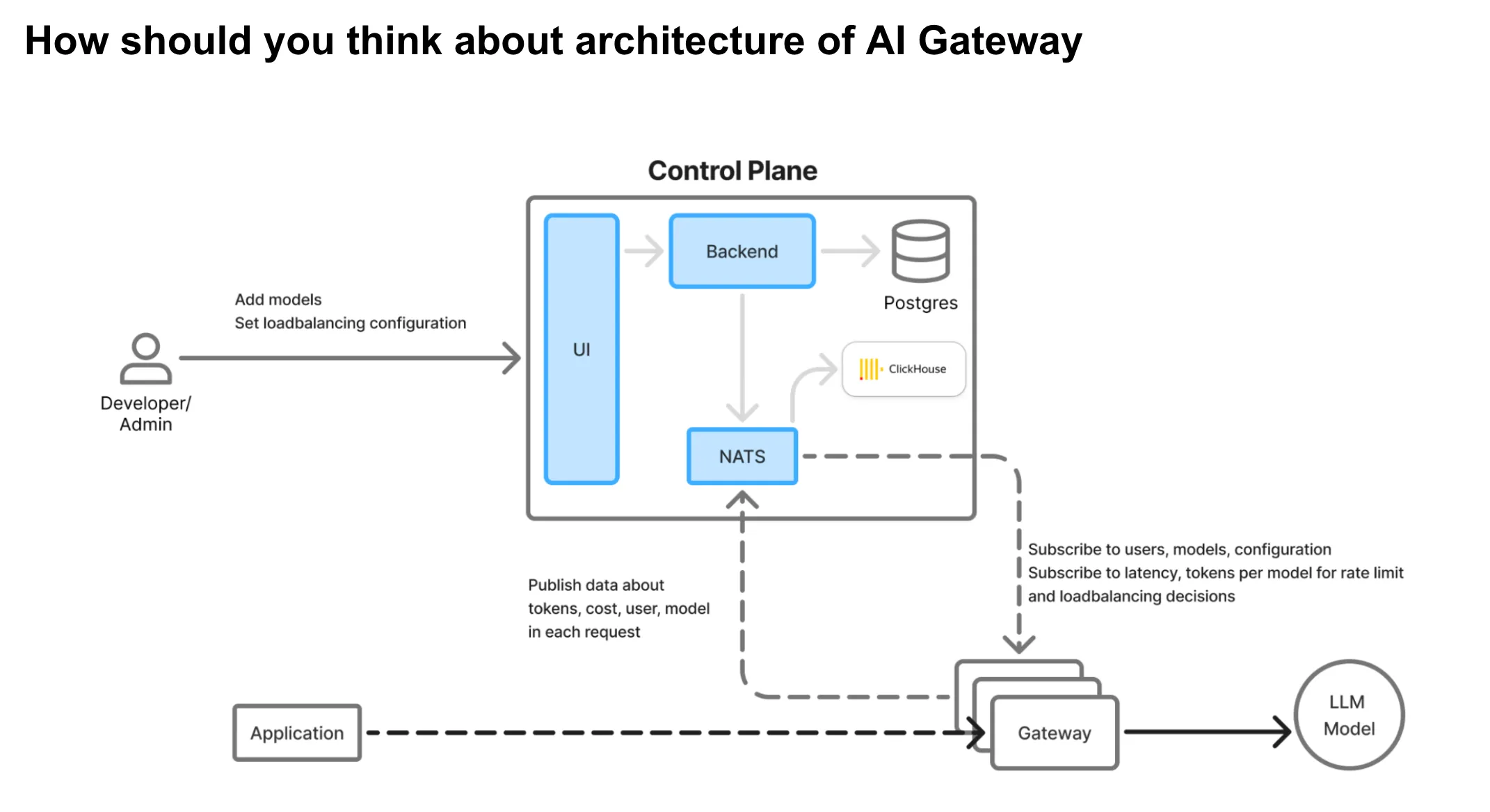
Arquitectura AI Gateway
La puerta de enlace de IA funciona como la capa de proxy crítica entre las aplicaciones y los proveedores de modelos de lenguaje (LLM). Porque la puerta de enlace se encuentra en la ruta crítica del tráfico de producción, debe diseñarse teniendo en cuenta los siguientes principios básicos:
Prioridades arquitectónicas clave:
Alta disponibilidad: La puerta de enlace no debe convertirse en un único punto de falla. Incluso en caso de problemas de dependencia (como interrupciones en las bases de datos o en las colas), debe seguir gestionando el tráfico correctamente.
Baja latencia: Dado que se encuentra en línea con cada solicitud de inferencia, la puerta de enlace debe agregar gastos generales mínimos para garantizar una experiencia de usuario ágil.
Alto rendimiento y escalabilidad: El sistema debe escalar linealmente con la carga y ser capaz de gestionar miles de solicitudes simultáneas con un uso eficiente de los recursos.
No hay dependencias externas en la ruta activa: Todas las operaciones vinculadas a la red o a un disco deben descargarse a sistemas asincrónicos para evitar cuellos de botella en el rendimiento.
Toma de decisiones en memoria: Controles críticos como límite de velocidad, equilibrio de carga, autenticación, y autorización todo debe realizarse en memoria para obtener la máxima velocidad y confiabilidad.
Separación del plano de control y el plano proxy: Los cambios de configuración y la administración del sistema deben desvincularse del enrutamiento del tráfico en vivo, lo que permite las implementaciones globales con aislamiento de fallas regionales.
El AI Gateway de TrueFoundry incorpora todos los principios de diseño anteriores, diseñados específicamente para ofrecer una baja latencia, una alta confiabilidad y una escalabilidad perfecta.
Arquitectura de puerta de enlace de IA de TrueFoundry
Basado en Hono Framework: La puerta de enlace aprovecha Hono, un marco minimalista y ultrarrápido optimizado para entornos periféricos. Esto garantiza una sobrecarga de tiempo de ejecución mínima y una gestión de solicitudes extremadamente rápida.
Sin llamadas externas en la ruta de solicitud: Una vez que una solicitud llega a la puerta de enlace, no desencadena ninguna llamada externa (a menos que esté habilitado el almacenamiento en caché semántico). Toda la lógica operativa se gestiona internamente, lo que reduce el riesgo y aumenta la fiabilidad.
Aplicación en memoria: Todas las decisiones de autenticación, autorización, limitación de velocidad y equilibrio de carga se toman mediante configuraciones en memoria, lo que garantiza tiempos de respuesta inferiores a un milisegundo.
Registro asincrónico: Los registros y las métricas de solicitudes se envían a una cola de mensajes de forma asincrónica, lo que garantiza que la observabilidad de los datos no bloquee ni ralentice la ruta de la solicitud.
Comportamiento a prueba de fallos: Incluso si la cola de registro externa está inactiva, la puerta de enlace no rechazará ninguna solicitud. Esto garantiza el tiempo de actividad y la resiliencia en caso de fallos parciales del sistema.
Escalable horizontalmente: La puerta de enlace está vinculada a la CPU y no tiene estado, lo que facilita la escalabilidad horizontal. Funciona de manera eficiente en condiciones de alta simultaneidad y bajo uso de memoria.
La puerta de entrada a la IA de True Foundry
Soporte para múltiples proveedores: añada y administre fácilmente modelos de AWS, GCP, OpenAI, Anthropic, DeepInfra y opciones personalizadas/autohospedadas.
Unified Playground: pruebe y ejecute las indicaciones en cualquier modelo a través de una interfaz. Las claves de API y los nombres de los modelos se pueden configurar sin necesidad de cambiar el código.
Gestión rápida con guardarraíles: muestra la redacción en tiempo real de datos confidenciales durante el envío rápido, integrado con el servidor de guarraíles centralizado.
Métricas detalladas y observabilidad:
Seguimiento en vivo de quién llama a qué modelo.
Estadísticas de latencia detalladas que incluyen el «tiempo hasta el primer token» y la «latencia entre tokens» (fundamentales para la supervisión del rendimiento de LLM).
Las estadísticas de activación de la limitación de velocidad, el respaldo y la barrera de protección.
Registros de auditoría de todos los pares de solicitud-respuesta, exportables para garantizar su cumplimiento.
Ajustes de administración configurables: defina los límites de velocidad por desarrollador o equipo, establezca políticas alternativas, enrutamiento basado en la latencia y administre las barreras de protección de forma centralizada.
Hoja de ruta de integración de servidores MCP: vista previa de la próxima funcionalidad compatible con todos los servidores MCP internos para herramientas como Gmail, Slack, Confluence, Jira, GitHub y API personalizadas.
Preguntas y respuestas en vivo: Cómo abordar la escalabilidad, la integración y las consultas técnicas
La sesión concluye con una sesión de preguntas y respuestas del público que abarca:
Escalabilidad de puerta de enlace: Diseñado para ser escalable horizontalmente; los puntos de referencia de rendimiento muestran que una CPU puede gestionar 350 solicitudes por segundo (RPS), lo que requiere despliegues escalables para obtener velocidades más altas.
Latencia y estabilidad: Gateway proporciona mecanismos de devolución de llamada y reintento para una mayor confiabilidad y cambia automáticamente de modelo cuando los proveedores se enfrentan a interrupciones.
Límites de tamaño de entrada del modelo: los modelos no pueden manejar entradas extremadamente grandes (por ejemplo, 500 MB); se recomienda utilizar sistemas de generación aumentada por recuperación (RAG).
Integraciones de marcos: compatible con los principales marcos de creación de agentes, como LangChain y LangGraph, utiliza API estándar compatibles con OpenAI sin necesidad de SDK especiales.
Compatibilidad con lenguajes de programación: Gateway se ha creado con marcos ligeros y de alto rendimiento (Hono, similares a los que se utilizan en los trabajadores de Cloudflare) y es independiente del lenguaje para los clientes de API (Python, JavaScript, Go, etc.).
Adaptación rápida a las API del nuevo modelo: actualizaciones continuas para respaldar los parámetros específicos del proveedor y las entradas multimodales con una documentación rigurosa.
Herramientas de control y auditoría: capacidad de exportar datos detallados de latencia, uso y costos para auditorías alineadas con las necesidades de gobierno.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga




































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


