





October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: May 19, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
In diesem Blog stellen wir Ihnen das Training von Modellen für maschinelles Lernen auf dem vor TrueFoundry-Plattform. Wir werden besprechen, wie wir Trainingsjobs auf TrueFoundry ausführen können. Wir werden auch sehen, wie Sie auf einfache Weise Hyperparameter-Tuning für Ihre Machine-Learning-Modelle durchführen und Ihre Jobs auf GPUs ausführen können.
Lassen Sie uns zunächst mit einer Problemstellung beginnen, sagen wir, wir möchten anhand verschiedener Merkmale wie Alter, BMI, Blutdruck usw. sehen, wie sich die Diabeteserkrankung bei einem Patienten entwickelt. In diesem Blog werden wir die Diabetes-Datensatz Modell für maschinelles Lernen in Scikit-Learn.
Apropos Training von Modellen für maschinelles Lernen: Es gibt mehrere Möglichkeiten, dies zu tun, z. B. durch Training örtlich an Ihrer Maschine, Schulung in Jupyter-Notizbücherusw. Für den Trainingsprozess sind jedoch möglicherweise mehr Ressourcen erforderlich, als auf einem lokalen Computer verfügbar sind.
Hier können Sie mit TrueFoundry's Jobs den Trainingscode für die Ausführung auf einem Remote-Computer bereitstellen und die Protokolle und Metriken verfolgen.
Hinweis: Obwohl wir diesen Diabetes-Datensatz verwenden, gelten die in diesem Blog genannten Anweisungen auch für andere Machine-Learning-/Deep-Learning-Modelle.
Jobs bieten die Möglichkeit, kurzlebige, parallele oder sequentielle Batch-Tasks innerhalb des Clusters auszuführen. Jobs sind so konzipiert, dass sie vollständig ausgeführt werden, und nicht als Dienste mit langer Laufzeit oder kontinuierlich ausgeführte Anwendungen. Sobald ein Job abgeschlossen ist, werden Rechen- und Speicherressourcen freigegeben, sodass uns keine zusätzlichen Kosten entstehen.
Wie bereits erwähnt, verwenden wir die Diabetes-Datensatz in Scikit-Learn. Der Datensatz enthält 442 Stichproben (Patienten) und 10 Merkmale, die alle numerisch sind. Die Merkmale stellen verschiedene Faktoren dar, die das Fortschreiten des Diabetes bei Patienten beeinflussen können. Die Zielvariable ist ebenfalls numerisch und stellt ein quantitatives Maß für das Fortschreiten der Erkrankung bei jedem Patienten ein Jahr nach Studienbeginn dar.
Bevor wir mit dem Training von Modellen für maschinelles Lernen fortfahren, gehen wir die Anweisungen zur Einrichtung durch:
Gehen Sie zum TrueFoundry Dashboard und erstellen Sie ein Konto. Sobald du dich anmeldest, wirst du aufgefordert, einen Workspace zu erstellen. Sie würden Ihre Jobs in diesem Workspace bereitstellen.

Nachdem Sie Ihren Workspace erstellt haben, erstellen Sie über das Dashboard ein ML-Repository.
Ein ML-Repository ist eine Sammlung von Läufen, Modellen und Artefakten, die ein Machine-Learning-Projekt darstellt. Sie können es sich wie ein Git-Repository vorstellen, außer dass es Artefakte, Modelle und Metadaten enthält. Alle Zugriffskontrollen können auf der Ebene von ml-repo konfiguriert werden.
Sobald das ML Repo erstellt ist, gehen Sie zu Workspaces, bearbeiten Sie Ihren Workspace und aktivieren Sie 'ML Repo Access'. Klicken Sie auf „ML Repo Access hinzufügen“, um Ihr ML Repo zu diesem Workspace hinzuzufügen. Dadurch kann der im Workspace ausgeführte Job das Schreiben und Lesen aus dem ML-Repo ermöglichen.
pip install servicefoundry
--Gastgeber: Geben Sie hier Ihre TrueFoundry Dashboard-URL ein
sfy login --host <YOUR-HOST-URL-HERE>
Sobald wir die obigen Einrichtungsanweisungen abgeschlossen haben, können wir mit dem Implementierungsabschnitt fortfahren.
Verzeichnisstruktur
In diesem Blog werden wir uns an die folgende Verzeichnisstruktur halten, wobei:
❯ Baum
.
√── deploy.py
√── requirements.txt
─ ── train.py
Lassen Sie uns nun den Trainingscode für das Diabetes-Modell durchgehen:
Trainingsschritte modellieren
aus sklearn.metrics importiere accuracy_score
importiere load_diabetes aus sklearn.datasets
aus sklearn.model_selection importiere train_test_split
aus sklearn.compose importiere TransformedTargetRegressor
von sklearn.preprocessing import QuantileTransformer
von sklearn.svm SVR importieren
X, y = load_diabetes (as_frame=Wahr, return_X_Y=Wahr)
X_Zug, X_Test, y_Zug, y_test = zug_test_split (X, y, Testgröße=0,2, zufälliger Zustand=42)
Regressor = SVR (Kernel=Kernel)
Modell = TransformedTargetRegressor (
regressor=Regressor,
transformer=QuantileTransformer (n_quantiles=n_quantile, output_distribution="normal“),
)
model.fit (X_Zug, y_Zug)
y_pred = model.predict (X_Test)
Genauigkeit = Genauigkeit_Ergebnis (y_test, y_pred)
print („Genauigkeit: {Genauigkeit: .2f}“)
Vollständiger Code für das Modelltraining
aus sklearn.metrics importiere accuracy_score
importiere load_diabetes aus sklearn.datasets
aus sklearn.model_selection importiere train_test_split
aus sklearn.compose importiere TransformedTargetRegressor
von sklearn.preprocessing import QuantileTransformer
von sklearn.svm SVR importieren
def train (Kernel: str, n_quantiles: int):
# lade den Datensatz und erstelle Zug- und Testsätze
X, y = load_diabetes (as_frame=Wahr, return_X_Y=Wahr)
X_Zug, X_Test, y_Zug, y_test = zug_test_split (X, y, Testgröße=0,2, zufälliger Zustand=42)
# initialisieren Sie das Modell
Regressor = SVR (Kernel=Kernel)
Modell = TransformedTargetRegressor (
regressor=Regressor,
transformer=QuantileTransformer (n_quantiles=n_quantile, output_distribution="normal“),
)
# Modell trainieren und testen
model.fit (X_Zug, y_Zug)
y_pred = model.predict (X_Test)
Genauigkeit = Genauigkeit_Ergebnis (y_test, y_pred)
print („Genauigkeit: {Genauigkeit: .2f}“
Regressor, Modell, X_Test, y_test zurückgeben
Nachdem wir nun den Code zum Trainieren eines Modells für maschinelles Lernen gesehen haben, können wir weitermachen und lernen, wie solche Modelle für die zukünftige Verwendung gespeichert (oder protokolliert) werden können.
Ein Model besteht aus einer Modelldatei und einigen Metadaten. Jedes Modell kann mehrere Versionen haben. Wir können Modellobjekte automatisch serialisieren, speichern und versionieren, indem wir Modellmetadaten speichern Methode und im Folgenden sind die Schritte dazu aufgeführt:
Schritte zur Modellprotokollierung
mlfoundry importieren
run = mlfoundry.get_client () .create_run (ml_repo=ml_repo, run_name="SVR-mit-QT“)
Ein Run steht für ein einzelnes Experiment, das im Kontext des maschinellen Lernens ein bestimmtes Modell (z. B. logistische Regression) mit einem festen Satz von Hyperparametern ist. Metriken und Parameter (Details unten) werden alle im Rahmen eines bestimmten Durchlaufs protokolliert.
run.log_params (regressor.get_params ())
run.log_metrics ({"Ergebnis“: model.score (x_Test, y_test)})
model_version = run.log_model (name="Diabetes-Regression“, model=model, framework="sklearn“)
print („model_version =“, model_version.version, „model_fqn =“, model_version.model_fqn)
Jedes protokollierte Modell generiert eine neue Version, die der angegebenen Version zugeordnet ist Name und mit dem aktuellen Lauf verknüpft. Mehrere Versionen des Modells können als separate Versionen unter derselben protokolliert werden Name.
Vollständiger Code zur Modellprotokollierung
mlfoundry importieren
def save_model_metadata (Regressor, Modell, X_Test, y_test, ml_repo):
# erstelle einen Lauf im ml_repo von truefoundry
run = mlfoundry.get_client () .create_run (ml_repo=ml_repo, run_name="SVR-mit-QT“)
# logge die Hyperparameter des Modells
run.log_params (regressor.get_params ())
# protokolliere die Metriken des Modells
run.log_metrics ({"Ergebnis“: model.score (x_Test, y_test)})
# das Modell protokollieren
model_version = run.log_model (name="Diabetes-Regression“, model=model, framework="sklearn“)
print („model_version =“, model_version.version, „model_fqn =“, model_version.model_fqn)
Nachdem wir den Prozess des Modelltrainings und der Protokollierung gesehen haben, können wir ihn zu einem einzigen zusammenfassen train.py Datei. Der endgültige Inhalt der train.py Datei sollte so aussehen:
train.py
# erforderliche Importanweisungen für beide Funktionen
def train (Kernel, n_Quantile):
...
def save_model_metadata (Regressor, Modell, X_Test, y_test, ml_repo):
...
Regressor, Modell, x_Test, y_test = train (kernel="linear“, n_quantiles=100)
save_model_metadata (Regressor, Modell, x_test, y_test, ml_repo="IHR ML-REPO-NAME“)
Damit ist unser Code für das Modelltraining und die Protokollierung abgeschlossen. Jetzt müssen wir den Modelltrainingscode als Aufgabe bereitstellen. Das deploy.py enthält den Code für die Bereitstellung des obigen Modelltrainingscodes, wie unten gezeigt:
deploy.py
von Servicefoundry importieren Build, Job, PythonBuild, LocalSource
# Definition der Stellenbeschreibungen
Beruf = Beruf (
name="diabetes-zug-job“,
image=BUILD (
build_spec=PythonBuild (command="python train.py „, requirements_path=“ requirements.txt „),
build_source=Lokalquelle (local_build=Falsch)
),
)
deployment = job.deploy (WORKSPACE_FQN="DEIN WORKSPACE-FQN HIER“)
Das requirements.txt sollte die folgenden Pakete enthalten:
requirements.txt
Pandas==1.3.5
scikit-learn==1.2.1
mlfoundry>=0.7.2, <0.8.0
In den obigen deploy.py Code, ein Job wird bereitgestellt, der die Genauigkeitsbewertung des trainierten Modells in den Protokollen anzeigt, wenn es aufgerufen wird. Außerdem wird das trainierte Modell für maschinelles Lernen protokolliert. Zu diesem Zweck wird ein Auftragsobjekt mit dem erstellt Service Foundry.job Klasse. Der Jobname wird beibehalten als Diabetes-Zug-Job hier.
HINWEIS: Stellen Sie sicher, dass Sie „IHR ML-REPO-NAME“ durch Ihren ML-Repo-Namen in ersetzen train.py und „DEIN WORKSPACE-FQN HIER“ mit deinem Workspace-FQN in deploy.py Datei.
In der train.py Datei, du musst die übergeben Name des ML-Repos du hast geschaffen, um Modellmetadaten speichern () Funktion. In der deploy.py Datei, die du bestehen musst LÜFTER des Workspace, den du erstellt hast, zu job.deploy () Funktion. Führen Sie nun den folgenden Befehl aus, um den Job bereitzustellen:
python deploy.py
Gehen Sie nach der Bereitstellung des Schulungsjobs zum Unterabschnitt „Jobs“ im Abschnitt „Bereitstellungen“. Er sollte ungefähr so aussehen:
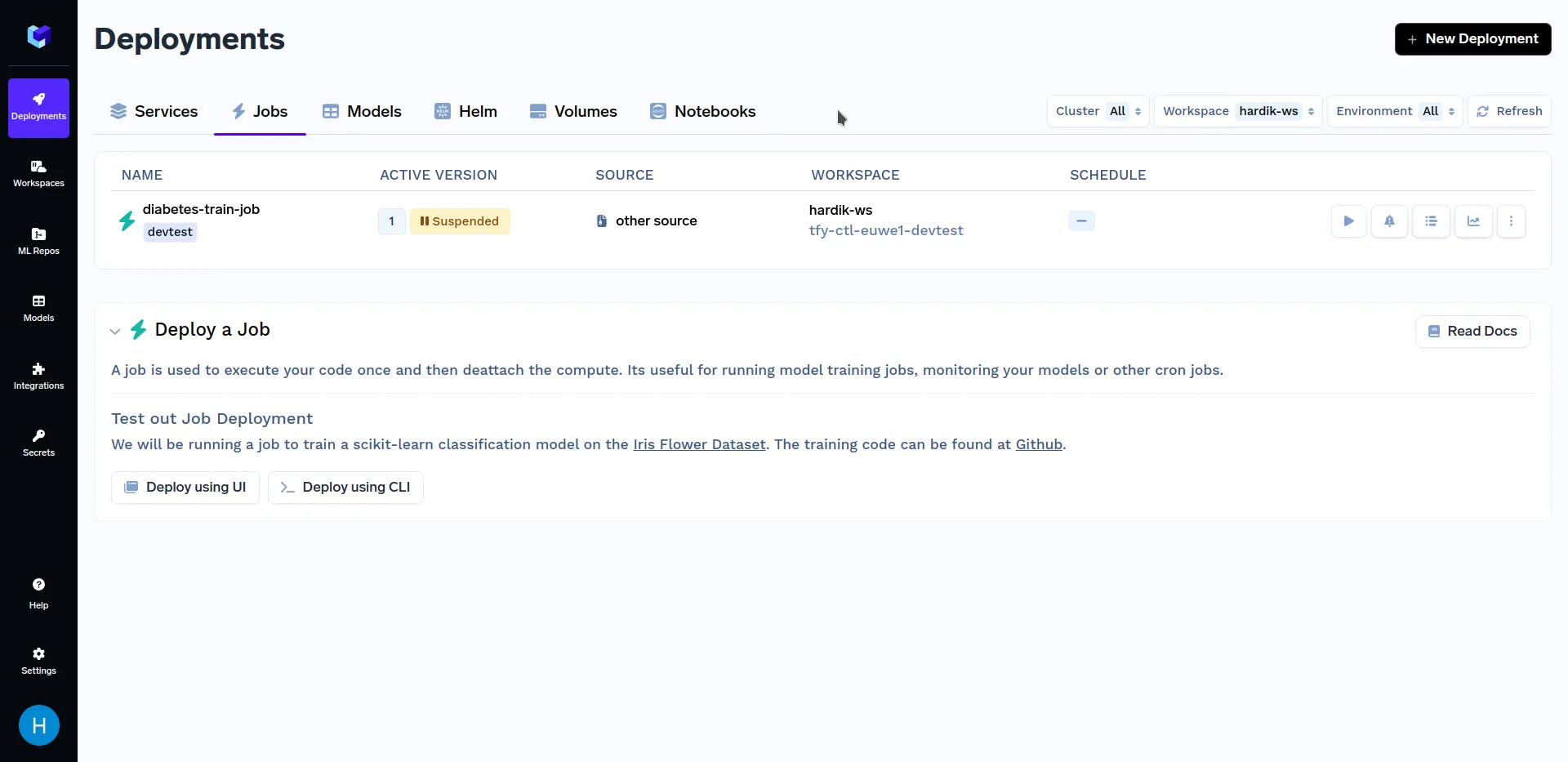
Jetzt, da wir mit der Bereitstellung unseres Jobs fertig sind, werden wir ihn auslösen wollen. Sie können dies mit einer unserer Python-SDK oder die TrueFoundry-Dashboard. Zunächst werden wir über die Auslösung von Jobs sprechen von TrueFoundry-Dashboard. Informationen zu anderen Methoden zum Auslösen von Aufträgen finden Sie in der Jobs aus dem Python-SDK auslösen Abschnitt.
Nach dem oben genannten Ausbildungsberuf hat Bereitstellung abgeschlossen, Gehen Sie im Abschnitt „Bereitstellungen“ zum Unterabschnitt „Jobs“ und klicken Sie auf den „Diabetes-Zug-Job“, und klicken Sie auf „Job ausführen“, um den Job vor dem Auslösen zu konfigurieren. Es sollte ungefähr so aussehen:
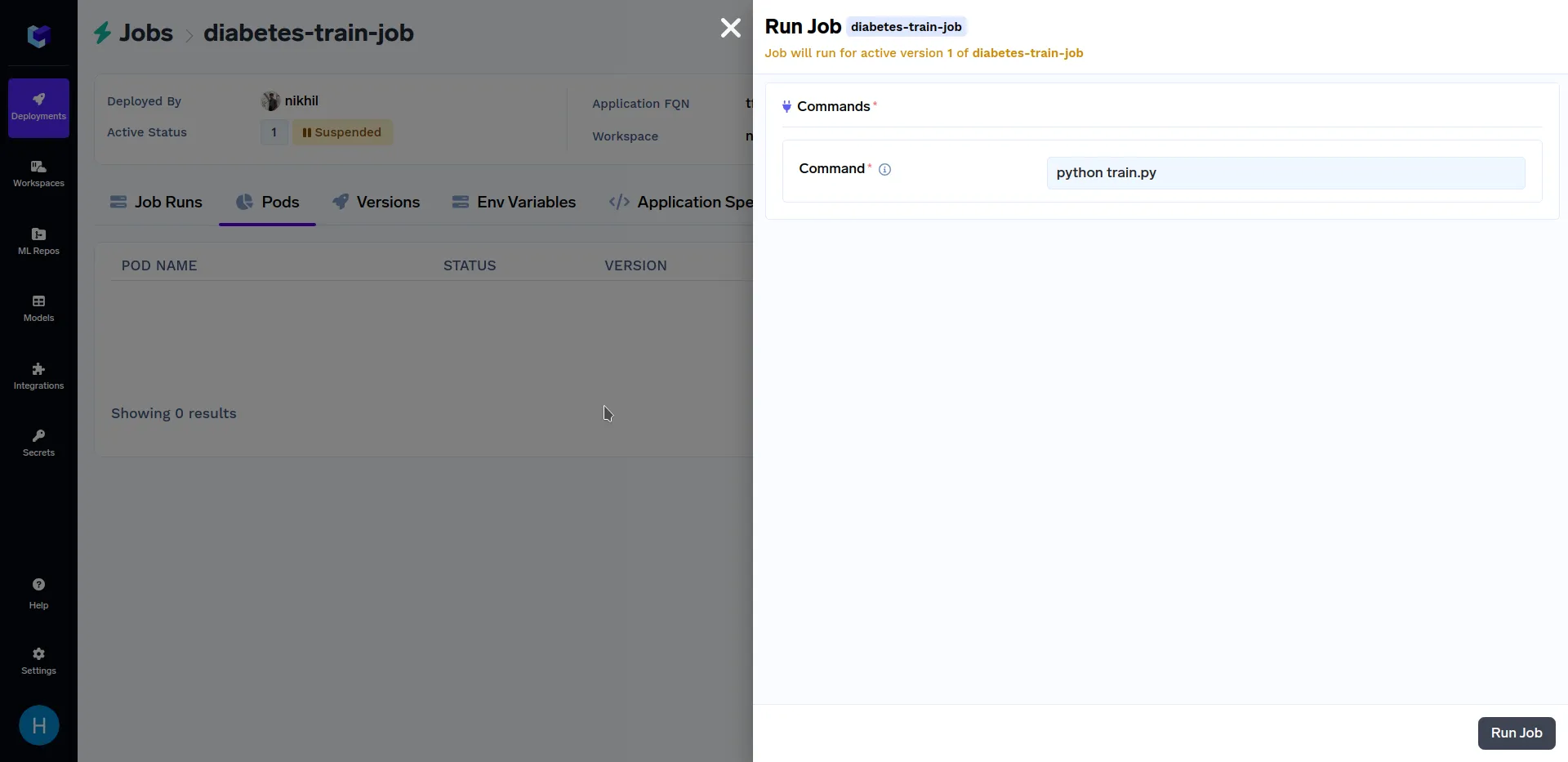
Wenn Sie sich auf dem obigen Bildschirm befinden, klicken Sie unten rechts auf „Job ausführen“, um diesen Job auszulösen. Nachdem der Trainingsjob ist fertig gelaufen, gehen Sie im Abschnitt „Bereitstellungen“ zum Unterabschnitt „Jobs“ und klicken Sie auf „Diabetes-Zug-Job“, es sollte ungefähr so aussehen:
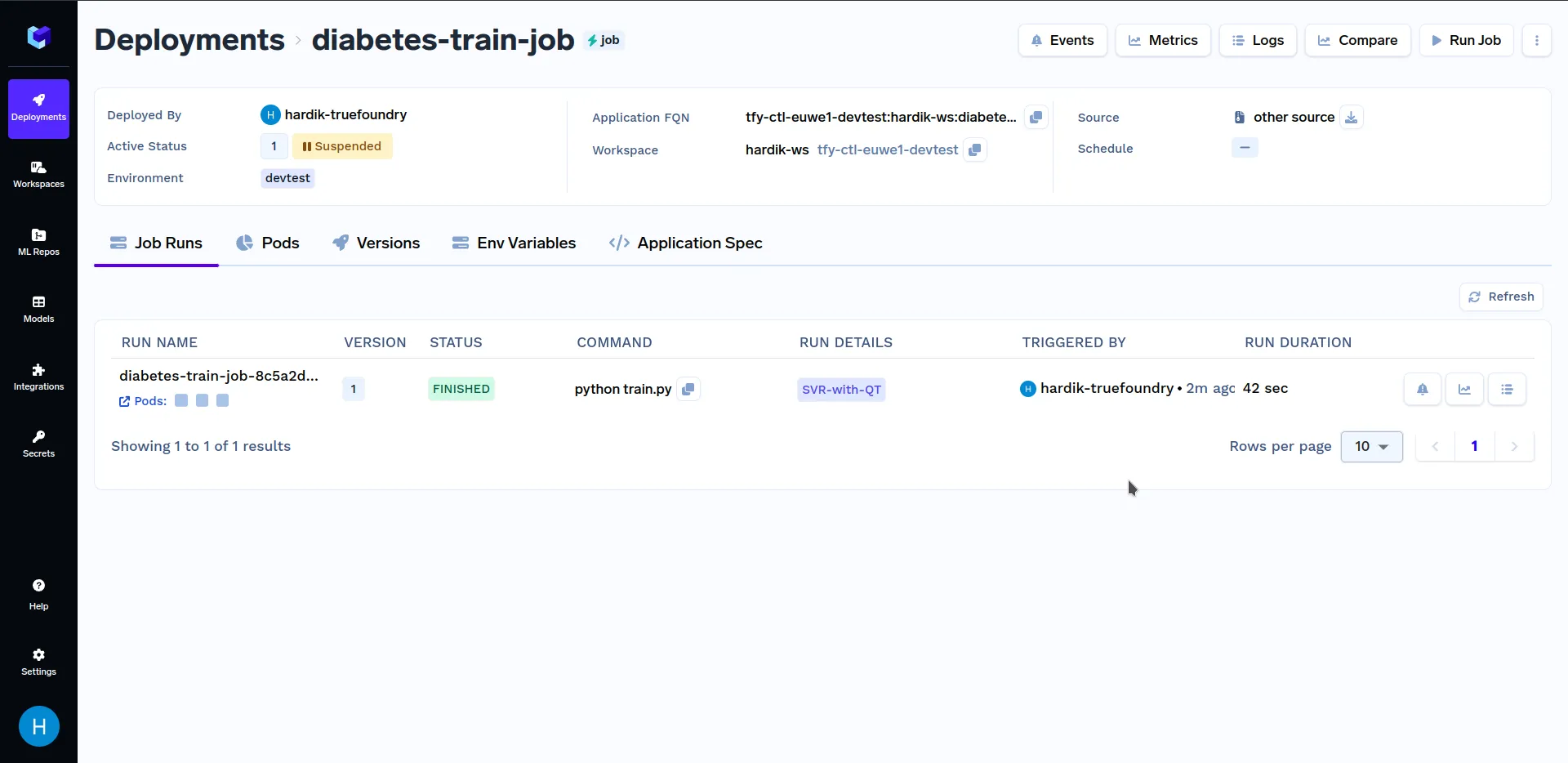
Klicken Sie unter „Ausführungsdetails“ auf „SVR-mit-QT“ um wichtige Metriken und Hyperparameter zu sehen, die im train.py Datei. Es sollte ungefähr so aussehen:
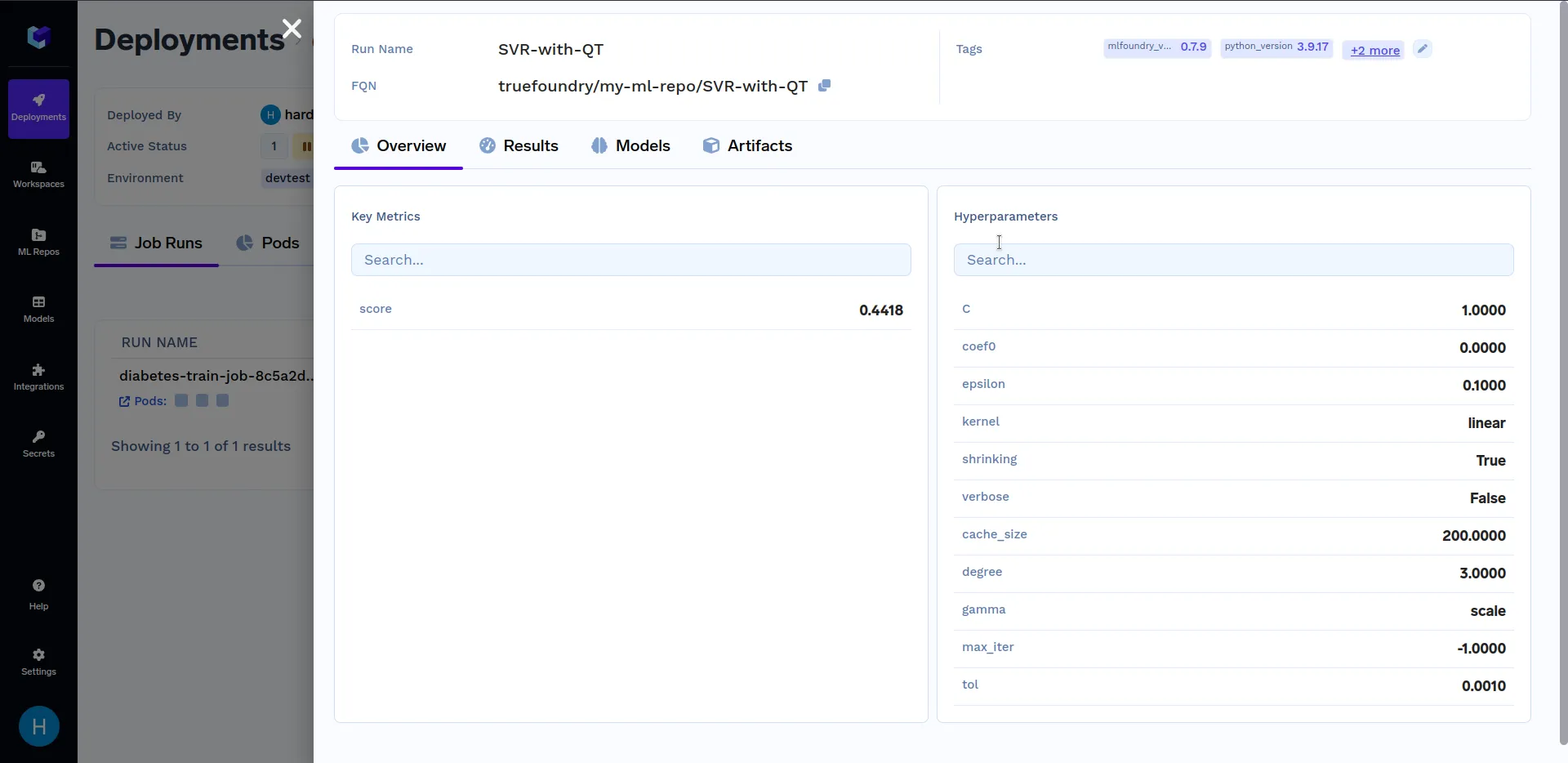
Stellen Sie sich vor, Sie haben umfangreiche Datenverarbeitungs- oder Stapelverarbeitungsaufgaben, bei denen die Ausführung eines einzelnen Jobs mit unterschiedlichen Konfigurationen unerlässlich ist, um nicht nur Ihren Arbeitsablauf zu optimieren, sondern auch die Konsistenz bei der Auftragsausführung sicherzustellen. In solchen Fällen wird sich ein parametrisierter Job als nützlich erweisen.
Ein parametrisierter Job ist eine Art von Job, mit dem Sie mehrere Instanzen (Pods) mit unterschiedlichen Parametern oder Eingaben erstellen können. Das primäre Ziel eines parametrisierten Jobs besteht darin, Flexibilität bei der Auftragsausführung zu bieten, indem sein Verhalten an verschiedene Szenarien angepasst wird.
Als Beispiel ein Job mit dem Befehl als python main.py --n_Quantile {{n_Quantile}} ist ein parametrisierter Job wie es dauert n_Quantile als Eingabe vor dem Laufen. Wir können den oben bereitgestellten Job mithilfe von Parametern vereinfachen.
Um die Befehlszeilenargumente zu analysieren, verwenden wir den argparse Modul. Der folgende Code zeigt den aktualisierten Code für train.py und deploy.py Dateien, in denen die Standardwerte von Kernel und n_Quantile sind linearen und 100 jeweils:
train.py
importiere os, argparse
def train (Kernel, n_Quantile):
...
def log_model (Regressor, Modell, X_Test, y_test, ml_repo):
...
Parser = argParse.ArgumentParser ()
parser.add_argument („--kernel“, default="linear“, typ=str)
parser.add_argument („--n_quantiles“, Standard=100, Typ=int)
Argumente = parser.parse_args ()
Regressor, Modell, x_Test, y_test = train (kernel=args.kernel, n_quantiles=args.n_quantiles)
log_model (Regressor, Modell, X_Test, y_test, ml_repo=os.environ.get („ML_REPO_NAME“))
deploy.py
argparse importieren
von Servicefoundry importieren Build, Job, PythonBuild, Param, LocalSource
Parser = argParse.ArgumentParser ()
parser.add_argument („--workspace_fqn“, typ=str, required=Wahr)
parser.add_argument („--ml_repo“, typ=str, required=Wahr)
Argumente = parser.parse_args ()
cmd = „python train.py --kernel {{kernel}} --n_Quantile {{n_Quantile}}“
# Definition der Stellenbeschreibungen
# Nur der Befehl ändert sich im Attribut 'image'
Beruf = Beruf (
...
image=build (build_spec=PythonBuild (Befehl=cmd,...), ... ),
Parameter = [
Param (name="n_quantiles“, Standard='100'),
Param (name="kernel“, default='linear', description="svm-Kernel“),
],
env= {„ML_REPO_NAME“: args.ml_repo}
)
Einsatz = job.deploy (workspace_fqn=args.workspace_fqn)
HINWEIS: Stellen Sie sicher, dass Sie im folgenden Befehl „IHR ML-REPO-NAME“ durch Ihren ML-Repo-Namen und „YOUR WORKSPACE FQN HERE“ durch Ihren Workspace-FQN ersetzen.
Führen Sie nun den folgenden Befehl aus, um den parametrisierten Job bereitzustellen:
python deploy.py --workspace_fqn „DEIN WORKSPACE-FAN HIER“ --ml_repo „DEIN ML-REPO-NAME“
Alternativ, du kannst es direkt aus unserem Github-Repository ausführen.
Git-Klon https://github.com/truefoundry/truefoundry-examples.git
CD-Ausbildung-Job-Beispiel
python deploy.py --workspace_fqn „DEIN WORKSPACE-FAN HIER“ --ml_repo „DEIN ML-REPO-NAME“
Version 2 des Jobs wird nach Abschluss der Bereitstellung erstellt. Nach Ablauf des Trainingsauftrags Bereitstellung abgeschlossen, der nächste Schritt besteht darin, diesen Job auszulösen.
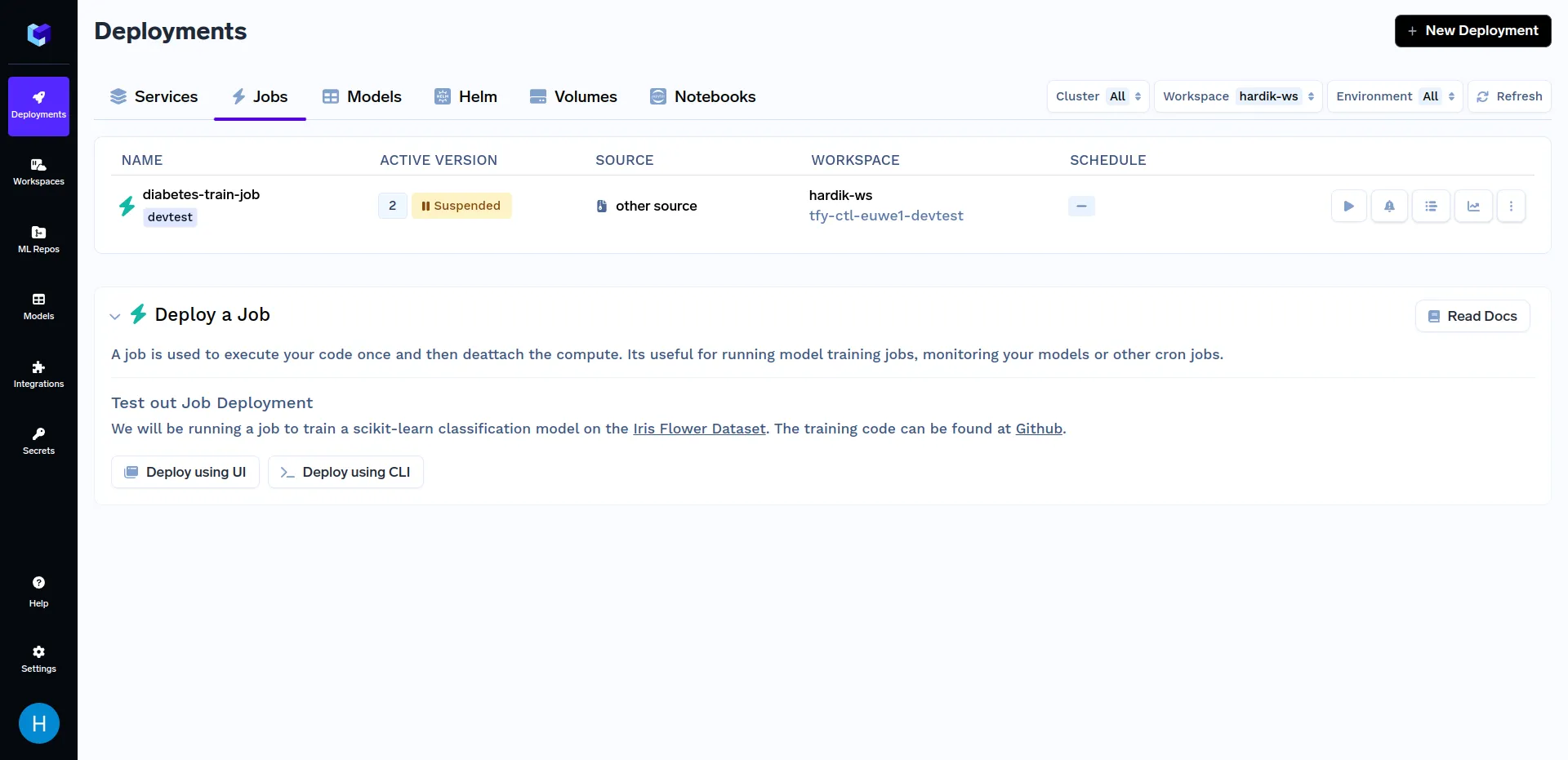
Klicken Sie auf das „Diabetes-Zug-Job“, und klicken Sie auf „Job ausführen“, um den Job vor dem Auslösen zu konfigurieren. Sie können jetzt das ändern n_Quantile und Kernel Parameter. Es sollte ungefähr so aussehen:
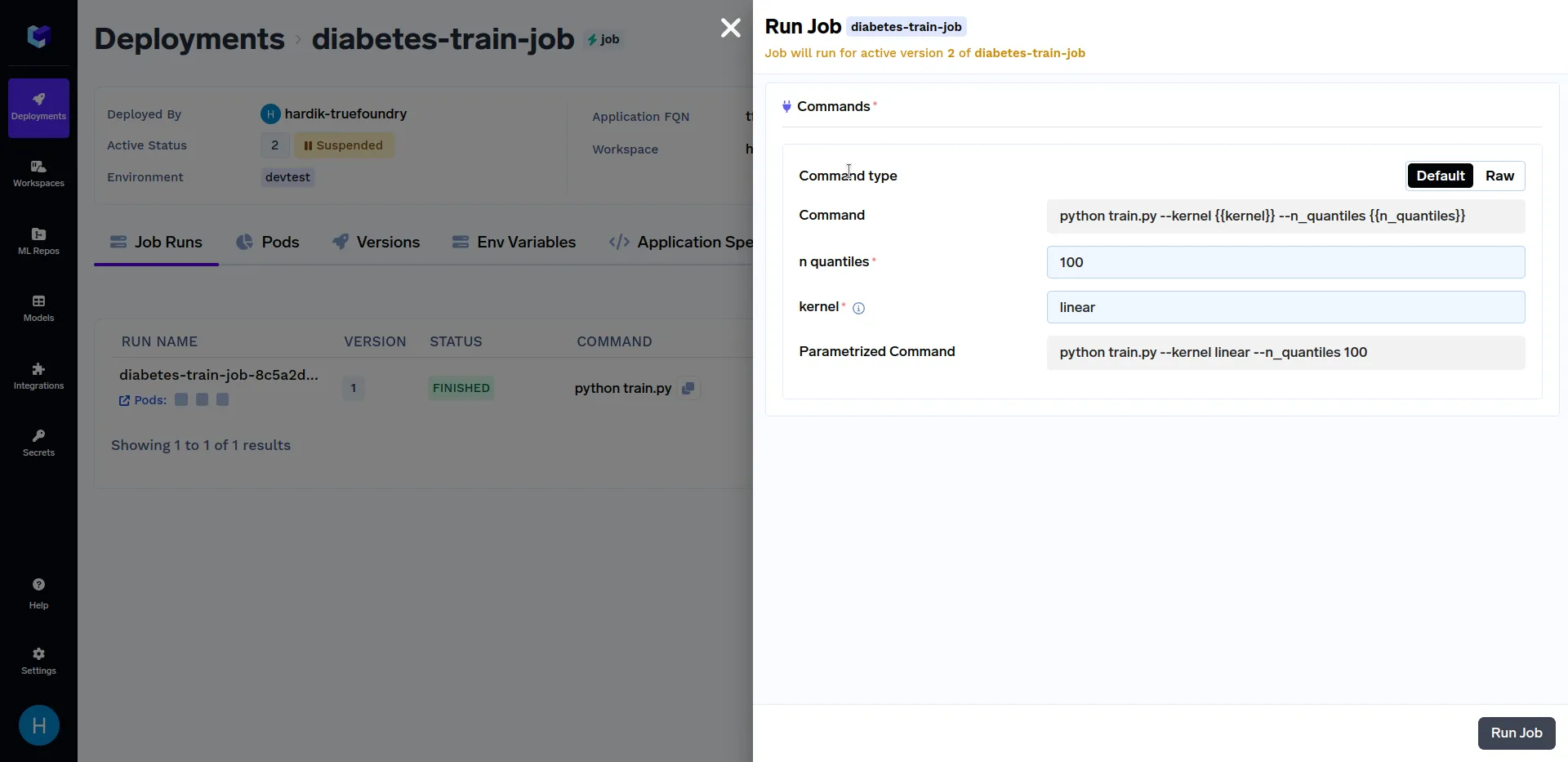
Versuchen Sie, Jobläufe mit unterschiedlichen Werten von auszulösen Kernel Parameter wie linearen, sigmoid, Poly und rbf. In ähnlicher Weise können Sie verschiedene Werte von verwenden n_Quantile Parameter wie 50, 80, 100 usw. Verschiedene Jobausführungen sollten in etwa so aussehen:
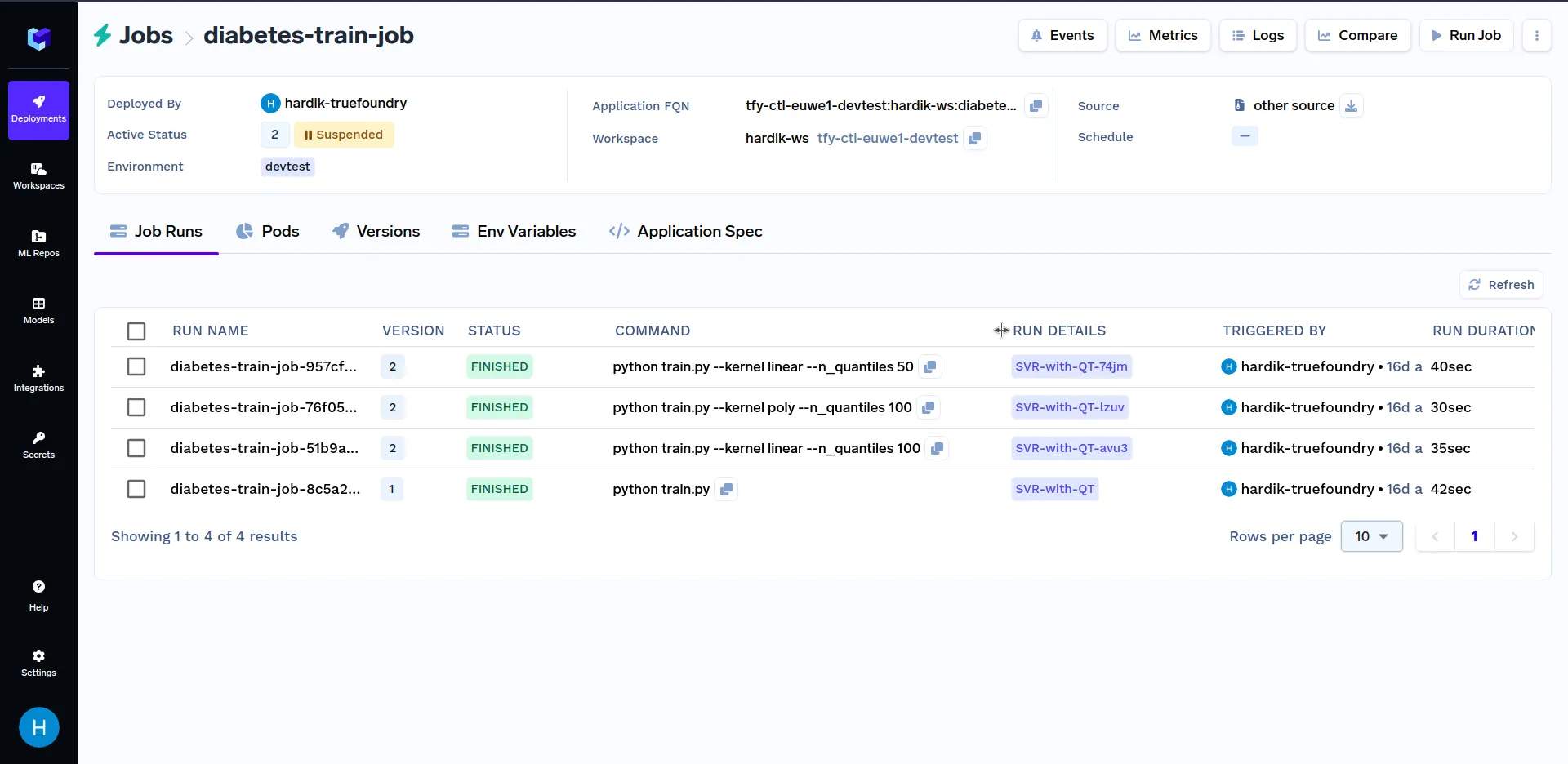
Sie können die Metriken verschiedener Jobausführungen im Dashboard vergleichen, indem Sie oben rechts im Dashboard auf die Schaltfläche „Vergleichen“ klicken, wie unten dargestellt:
Weitere Informationen zu Parameterized Job Deployment finden Sie hier:
Bisher haben wir nur auslösende Jobläufe von der gesehen TrueFoundry-Dashboard. Jetzt ist es möglich, dass auslösend ein Job ist nicht immer per UI wünschenswert, also gehen wir jetzt darauf ein, wie man einen Job programmatisch auslöst über Python-SDK.
Sie können Ihren Job programmgesteuert auslösen, indem Sie den Triggerjob Funktion wie unten gezeigt:
von servicefoundry Import Job, trigger_job
# Eine Jobbereitstellung konfigurieren
Beruf = Beruf (...)
# Einen Job bereitstellen
job_deployment = job.deploy (WORKSPACE_FQN="DEIN WORKSPACE-FQN“)
# Einen Job auslösen/ausführen
Triggerjob (
application_fqn=job_deployment.application_fqn,
params= {"n_quantile“ :"80"}
)
Es ist auch möglich, die application_fan einfach vom Dashboard aus, indem du auf Deployments --> Jobs --> Suche in deinem Workspace nach deinem Jobnamen (hier Diabetes-Zug-Job).
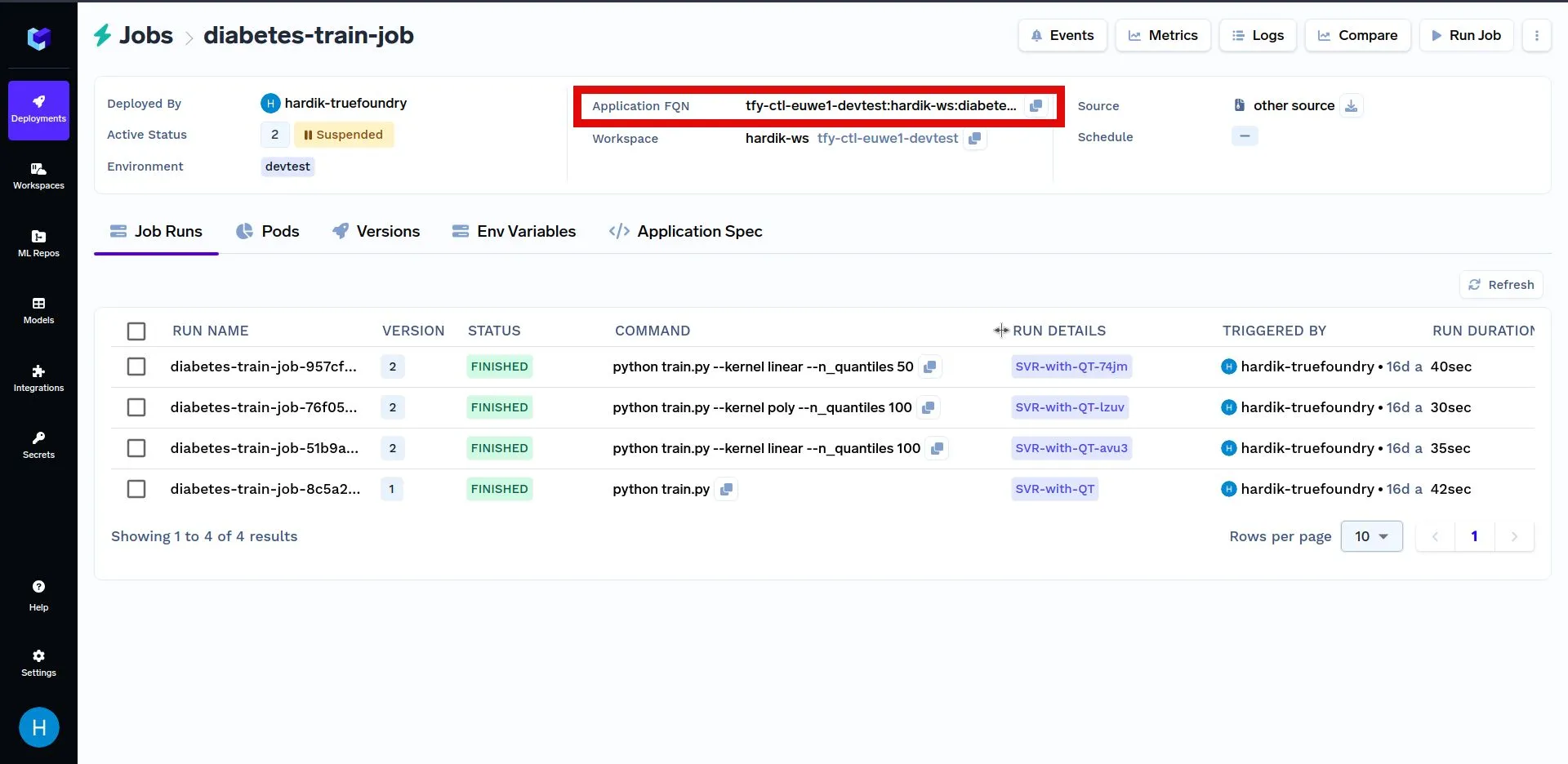
Unten finden Sie ein weiteres Beispiel für das programmatische Auslösen eines Jobs. Ersetzen Sie zunächst YOUR_APPLICATION_FAN mit dem Anwendung FQN des oben eingesetzter Job in dem unten gezeigten Code. Das Anwendung FQN für eine Bewerbung ist unten hervorgehoben:
Im unten gezeigten Code wählen wir nach dem Zufallsprinzip einen Wert für Modellparameter aus und lösen eine Auftragsausführung mit diesen Parametern aus. Danach durchsuchen wir die Job-Runs, um den Lauf mit dem Maximum zu finden Punktzahl. Der Job, der mit der höchsten Punktzahl ausgeführt wurde, weist auf eine optimalere Auswahl der Modellparameter hin.
zufällig importieren
mlfoundry als mlf importieren
von servicefoundry import trigger_job
# Finden Sie den ausgeschriebenen Job und ersetzen Sie ihn durch den Bewerbungsfan Ihres Jobs
application_fqn = „IHRE_APPLICATION_FQN“
# Parameter zufällig generieren
n_quantiles = random.randint (50, 100)
kernel_values = ['linear', 'sigmoid', 'poly', 'rbf']
kernel = kernel_values [random.randrange (0, len (kernel_values))]
# Einen Job auslösen/ausführen
getrigger_job = trigger_job (
application_fqn=application_fqn,
Parameter = {
„n_Quantile“: str (n_Quantile),
„kernel“: Kernel
}
)
print (f'hat Jobausführung mit n_quantiles= {n_quantiles} und kernel= {kernel} ausgelöst und als' benannt, triggered_job.jobRunname)
client = mlf.get_client ()
ml_repo_name = „IHR ML-REPO-NAME HIER“
runs = client.search_runs (ml_repo=ml_repo_name)
max_score = 0
für Run-in-Runs:
Metriken = run.get_metrics ()
print (F'Alle Metriken für den Lauf mit dem Namen {run.run_name}“ :', Metriken)
wenn „Ergebnis“ in Metriken:
max_score = max (max_score, metriken ['score'] [0] .value)
print („Maximaler Wert des Modells: „, max_score)
HINWEIS: Stellen Sie sicher, dass Sie im folgenden Befehl „YOUR ML REPO NAME HERE“ durch Ihren ML Repo-Namen und „YOUR WORKSPACE FQN HERE“ durch Ihren Workspace-FQN ersetzen.
Weitere Informationen zum Auslösen von Jobs finden Sie hier:
Sie können die Metriken verschiedener Auftragsausführungen programmgesteuert vergleichen, indem Sie mlfoundry.search_runs Funktion wie im folgenden Code beschrieben:
mlfoundry als mlf importieren
client = mlf.get_client ()
ml_repo_name = „DEIN-ML-REPO-NAME“
# Gibt alle Läufe zurück
runs = client.search_runs (ml_repo=ml_repo_name)
# Suche nach der Teilmenge der Läufe mit einer protokollierten Genauigkeitsmetrik > 0,7
filter_string = „metrics.score > 0.7"
runs = client.search_runs (ml_repo=ml_repo_name, filter_string=filter_string)
Sie können mehr über die lesen search_runs Funktion hier:
Stellen Sie sich vor, Sie haben es mit großen Modellen zu tun, die Millionen oder Milliarden von Parametern haben. Das Training solcher Modelle mit herkömmlichen CPUs wäre sehr zeitaufwändig und aufgrund von Speicherbeschränkungen möglicherweise sogar nicht durchführbar.
Beispielsweise dauert das Training eines CNN-Modells, das auf dem CIFAR-10-Datensatz basiert, in einer CPU-Umgebung mit 10 Epochen 36 Minuten und 31 Sekunden, aber dasselbe Modell, wenn es auf einer GPU-Umgebung (NVIDIA K80) trainiert wurde, dauerte es nur 4 Minuten und 6 Sekunden. Das ist eine Verbesserung um den Faktor 9 (siehe hier)
GPUs spielen eine wichtige Rolle beim groß angelegten Modelltraining. Sie bieten die erforderliche Speicherbandbreite und parallele Verarbeitungsfunktionen, um große Modellgrößen und komplexe Architekturen effizient zu handhaben. Jetzt werden wir uns ansehen, wie eine GPU in einem Job verwendet wird.
Die Verwendung einer GPU im obigen Beispiel erfordert geringfügige Änderungen in der Konfiguration eines Jobs in deploy.py Datei. Der folgende Code zeigt das aktualisierte Beruf Konfiguration für GPU-Auslastung und benutzerdefinierte CPU- und Speicherressourcenzuweisung:
deploy.py
von Servicefoundry Import Job, NodeSelector, GPUType, Resources
Beruf = Beruf (
Resources=Ressourcen (
# GPU konfigurieren
gpu_count=1,
node=Knotenselektor (GPU_TYPE=GPUType.t4)
# (Optional) CPU- und Speicherressourcen konfigurieren
cpu_request=0,2,
CPU-Limit = 0,5,
speicheranforderung=128,
Speicherlimit = 512,
),
...
)
Hinweis: Der Rest des Codes bleibt unverändert
Bisher haben wir verschiedene Job-Deployment-Optionen gesehen, wie zum Beispiel Bild, Parameter, und env. Es gibt mehrere Möglichkeiten, Ihren Job mit erweiterten Optionen anzupassen. Einige davon sind wie folgt:
Nachdem wir Jobs besprochen haben, die manuell entweder über das TrueFoundry Dashboard oder das Python SDK ausgelöst werden können. Aber was ist, wenn wir möchten, dass ein Job nach einem Zeitplan ausgeführt wird (wie ein Cron-Job)?
Ein Cron-Job führt den definierten Job nach einem sich wiederholenden Zeitplan aus. Dies kann nützlich sein, um ein Modell regelmäßig neu zu trainieren, Berichte zu erstellen und vieles mehr. Wir können solche Jobs implementieren, indem wir sie ändern auslösen geben Sie wie folgt ein:
von servicefoundry Import Job, Schedule
Beruf = Beruf (
trigger=Zeitplan (
schedule="0 8 1 * *“,
concurrency_policy="Forbid“ # Werte: ["Verbieten“, "Zulassen“, „Ersetzen"]
),
concurrency_limit=3,
...
)
Bei Cron-Jobs ist es möglich, dass die vorherige Ausführung des Jobs nicht abgeschlossen wurde, obwohl es aufgrund der geplanten Zeit bereits an der Zeit ist, den Job erneut auszuführen. In solchen Fällen können wir Folgendes definieren Parallelitätsrichtlinie wie folgt:
Verbieten: Das ist die Standardeinstellung. Erlaube keine gleichzeitigen Läufe.Erlauben: Erlaubt die gleichzeitige Ausführung von Aufträgen. Optional kann die maximale Anzahl von Jobs, die gleichzeitig ausgeführt werden sollen, durch Folgendes geändert werden Concurrency_limit auf Ihren gewünschten Wert. Ersetzen: Ersetzt den aktuellen Job durch den neuen.Parallelität gilt nicht für manuell ausgelöste Jobs. In diesem Fall wird immer eine neue Auftragsausführung erstellt.
Der Jobstatus kann von 3 Typen sein: FERTIG, BEENDET, und GESCHEITERT. Ein Job kann so konfiguriert werden, dass er es bei einem Fehler mehrmals wiederholt.
Ein Job ist markiert als GESCHEITERT wenn es auch nach der konfigurierten Anzahl von Wiederholungen nicht erfolgreich abgeschlossen wird. Wiederholungen kann für einen Job wie diesen konfiguriert werden:
von servicefoundry import Job
Beruf = Beruf (
Wiederholungen = 6, # Standard = 1
...
)
In einigen Anwendungsfällen müssen Sie möglicherweise angeben, wie lange ein Job maximal weiter ausgeführt werden soll.
Verwenden Auszeit, können Sie (in Sekunden) die maximale Zeit für die Ausführung eines Jobs angeben, unabhängig davon, ob er fehlgeschlagen ist oder nicht. Dies hat Vorrang vor dem versucht es erneut Limit. In der Standardeinstellung ist dies festgelegt auf 1000 Sekunden.
Wenn Sie beispielsweise denversucht es erneut zu 6 und ein Auszeit von 480 Sekunden, der Job wird nach 480 Sekunden beendet, unabhängig davon, wie oft er versucht hat, ihn auszuführen.
von servicefoundry import Job
Beruf = Beruf (
Zeitlimit = 480,
...
)
Abgesehen von den in diesem Blog besprochenen Jobbereitstellungsoptionen gibt es noch einige, die wir in diesem Blog nicht besprechen werden, wie zum Beispiel:
... und noch ein paar mehr. Sie können sich auf unsere beziehen Dokumentation unten angegeben, um die Antworten auf die obigen Fragen zu erfahren:)
Unser öffentliches Repositorium echte Foundry-Beispiele enthält den Job-Quellcode dieses Blogs und enthält auch mehrere Beispiele, darunter LLM-Feinabstimmung, Erste Schritte mit Notebooks, Beispiele von Anfang bis Ende um die von der TrueFoundry Platform angebotenen Funktionen einer breiteren Öffentlichkeit zugänglich zu machen.
Zusammenfassend bietet TrueFoundry's Job ein leistungsstarkes Framework für die Verwaltung und Ausführung von Trainingsaufgaben auf skalierbare, fehlertolerante und ressourceneffiziente Weise.
Sie ermöglichen es Ihnen, die Ausführung von Machine-Learning-Workloads zu verteilen und zu steuern, deren Fortschritt zu überwachen und sicherzustellen, dass Ihre Trainingsmodelle effektiv und zuverlässig trainiert werden. Dadurch eignen sie sich ideal für die Ausführung einmaliger oder On-Demand-Aufgaben.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




