

June 24, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 24, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
There's a moment in most enterprise AI programs when a workload appears that can't send its data to a third-party API — a regulated dataset, a sovereignty requirement, a cost curve that's gotten frightening at scale. The answer is an open-weight model you run yourself. The reason teams dread it isn't the model; it's that self-hosting usually means a second, different stack — a non-OpenAI API, a serving layer, GPU operations — bolted onto a platform built around commercial APIs. This post is how a gateway collapses that, making a self-hosted Llama or Mistral a drop-in alongside the commercial models you already call.
Ravi, an ML platform engineer, got the request he'd been expecting: a new workload would process records that, by policy, could not leave the company's cloud. No commercial API was an option. An open-weight model running in their own VPC was the obvious answer — and Ravi's heart sank a little, because the application that needed it was written against the OpenAI API, the team had no serving stack, and he could already picture the parallel universe of a second SDK, a second set of dashboards, and a GPU autoscaling problem nobody had solved. The model was the easy decision. The stack around it was the dread.
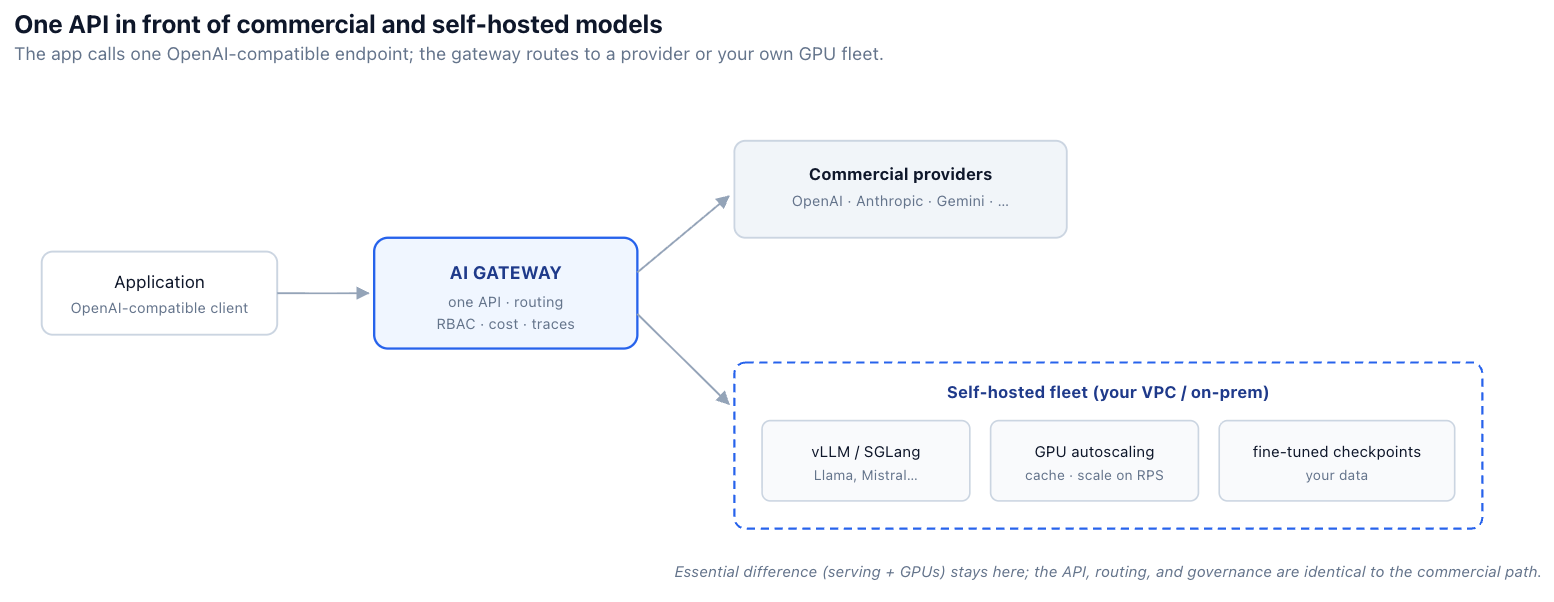
What changed Ravi's week was realizing the self-hosted model didn't have to be a different stack at all. If it sat behind the same gateway as the commercial models, speaking the same OpenAI-compatible API, then to the application it was just another model name — and to the platform it was one more endpoint governed by the same rules. The sovereignty requirement got met without forking the architecture. This post is how that works, and where the genuine engineering still lives.
Self-hosting an open-weight model is rarely about quality — frontier APIs are excellent and improving. It's about four other things. Sovereignty: some data legally or contractually cannot leave your environment, which a model running in your VPC or on-prem satisfies by construction. Cost at scale: past a certain steady volume, amortized GPUs can undercut per-token pricing, especially for high-throughput, predictable workloads. Control: you choose the model version, can fine-tune on proprietary data, and aren't subject to a provider deprecating or changing a model under you. Availability: your inference path is no longer directly tied to a model API provider's uptime — though it now depends on your own infrastructure and deployment supply chain.
The honest counterweight is that you now own inference operations: GPU capacity, the serving stack, scaling, and reliability — work that a commercial API hides entirely. Self-hosting is worth it when one of those four drivers is real and the operational cost is contained. Most enterprises end up hybrid: commercial APIs for general traffic, self-hosted models for the sovereign or high-volume slices. The goal isn't to replace one with the other; it's to run both without running two of everything.
Customization deserves to be pulled out of that list, because it's often the driver that tips a team toward open weights specifically. A commercial API gives you a model someone else trained for everyone; an open-weight model you can adapt to your domain, your formats, your tone, and your edge cases by fine-tuning on data you can't or won't send anywhere. For narrow, repetitive tasks a smaller fine-tuned open model can match or beat a much larger general one at a fraction of the serving cost — which folds the customization driver back into the cost one. The catch is that fine-tuning is its own pipeline: data preparation, training runs, evaluation, versioning, and then serving the result like any other model. TrueFoundry supports both no-code and full-code fine-tuning alongside its serving stack, so a tuned model lands behind the same gateway endpoint as everything else rather than becoming a separate artifact you have to operationalize by hand. The point isn't that fine-tuning is always worth it — it frequently isn't, and a good base model with strong prompting often wins — but when it is, owning the weights is what makes it possible at all.
One caveat belongs in this decision, not after it: open-weight does not mean obligation-free. Before you self-host or fine-tune, verify the model's license, acceptable-use policy, redistribution terms, attribution requirements, and any restrictions on regulated or commercial use — some popular open-weight models carry usage thresholds or field-of-use limits that matter at enterprise scale. Treat the license review as part of the deployment checklist, not a footnote discovered after the model is already in production.
Ravi's dread was well founded, because the naive way to self-host produces exactly that second stack. The open-weight model exposes its own API shape, so the application needs a code path for it. It needs a serving engine, which is its own operational surface. It needs GPU autoscaling, which behaves nothing like scaling a stateless web service. And it needs its own observability, because the commercial-API dashboards don't see it. Multiply that by a few models and you have a parallel platform whose only job is to be different from the one you already run.
The insight that defuses this is that almost none of that difference needs to reach the application or the platform's control surface. The serving engine and GPU scaling are real and unavoidable — they're the genuine work of self-hosting. But the API shape, the routing, the governance, and the observability can be made identical to the commercial path by putting the same gateway in front. The rest of this post separates the difference that's essential (serving, GPUs) from the difference that's accidental (everything the gateway can absorb).
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.



.webp)
.webp)





.webp)
.webp)
.webp)
.webp)
.webp)

.webp)
