

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
%20(11).webp)
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Prompting, Fine-Tuning und Retrieval-Augmented Generation (RAG) sind die beliebtesten LLM-Lerntechniken. Die Auswahl der richtigen Technik erfordert eine sorgfältige Bewertung der Anforderungen, Ressourcen und gewünschten Ergebnisse Ihres Projekts.
In den folgenden Abschnitten werden wir uns eingehender mit den einzelnen Techniken befassen und ihre Feinheiten und Anwendungen besprechen und herausfinden, welche Methode für Ihre Bedürfnisse am besten geeignet ist.

Der erste Schritt bei der Entscheidung zwischen Aufforderung, Feinabstimmung und RAG besteht darin, die Ihnen zur Verfügung stehenden Daten und das spezifische Problem, das Sie lösen möchten, genau zu untersuchen. Überlegen Sie, ob Ihre Aufgabe Allgemeinwissen, Fachinformationen oder aktuelle Daten aus externen Quellen erfordert. Die Komplexität des Problems, der Stil und der Ton der gewünschten Ausgabe sowie der Grad der erforderlichen Anpassung sind ebenfalls wichtige Faktoren.
Wenn Sie sich mit hochspezialisierten Themen oder Nischenthemen befassen, sind möglicherweise Feinabstimmungen oder RAG erforderlich, um das gewünschte Maß an Genauigkeit und Relevanz zu erreichen. Wenn Ihr Projekt jedoch allgemeinere Anfragen oder die Erstellung von Inhalten beinhaltet, könnte eine Aufforderung ausreichend und kostengünstiger sein.
Die Wahl zwischen Aufforderung, Feinabstimmung und RAG hängt auch von den Haushaltszwängen ab. Die Aufforderung ist in der Regel am wenigsten ressourcenintensiv, da das Modell unverändert verwendet wird. Für die Feinabstimmung sind zusätzliche Daten und Rechenressourcen für das Training erforderlich, was zu höheren Kosten führt. RAG kann auch ressourcenintensiv sein, insbesondere wenn es darum geht, eine externe Datenbank zum Abrufen einzurichten und zu verwalten.
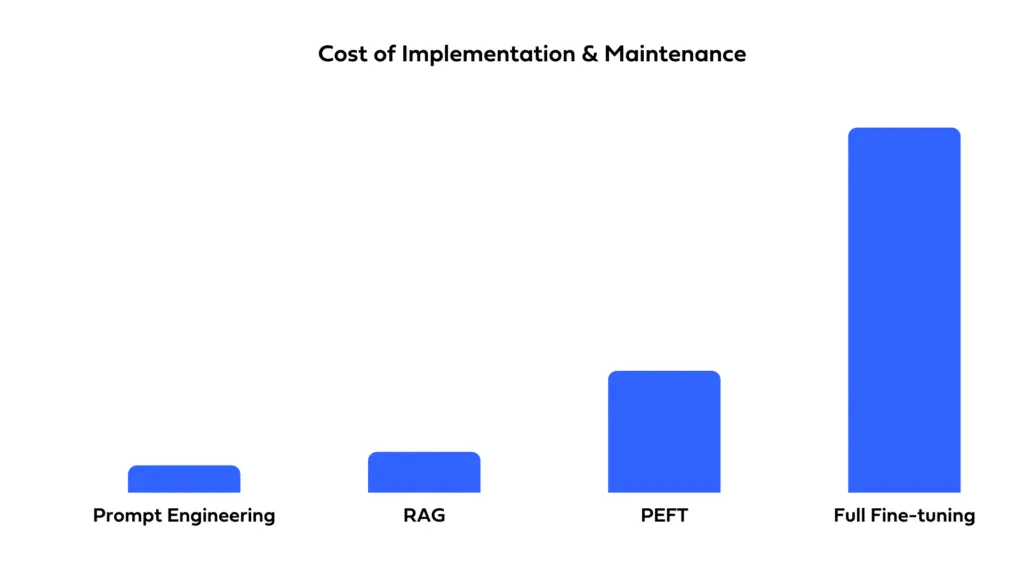
Überlegen Sie, wie schnell Sie Ihre Lösung bereitstellen müssen und welche Ressourcen Ihnen zur Verfügung stehen. Die Aufforderung ermöglicht eine schnelle Bereitstellung mit minimaler Einrichtungszeit. Die Feinabstimmung bietet zwar potenziell eine bessere Leistung, erfordert jedoch Zeit für Schulung und Optimierung. RAG beinhaltet die Komplexität der Integration externer Datenquellen, was die Entwicklungszeiten verlängern kann und spezielles Fachwissen erfordert.
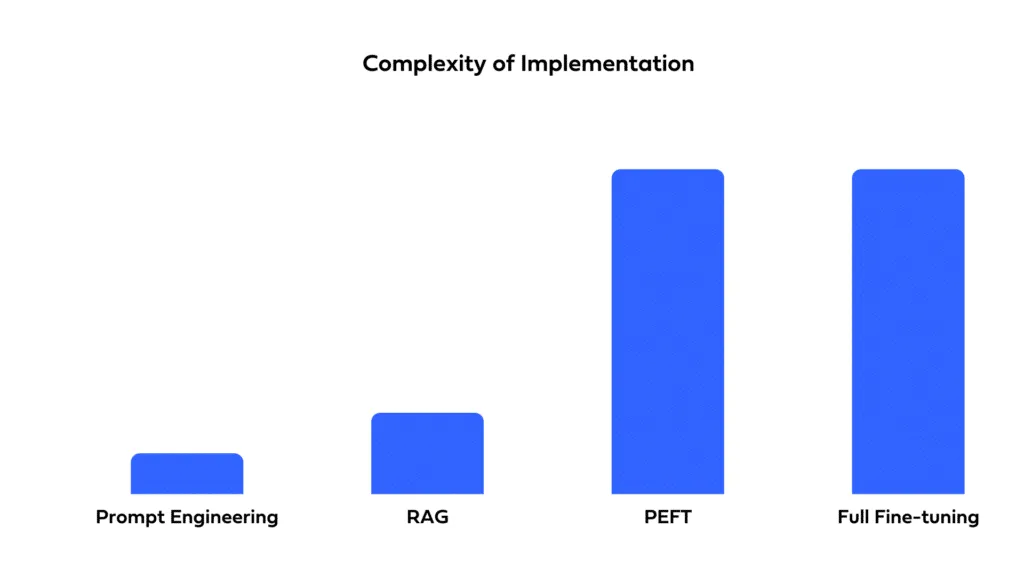
RAG erleichtert die Quellenzuweisung und ermöglicht es den Benutzern, die Herkunft der Informationen zu erkennen, die bei der Generierung der Antwort verwendet wurden. Aufforderungen und Feinabstimmungen wirken wie eine Blackbox, die es schwierig macht, die Antworten zurückzuverfolgen.

Prompting ist ideal für Projekte, die schnelle, kostengünstige Lösungen erfordern und bei denen auf die allgemeine Wissensbasis vortrainierter Modelle zurückgegriffen werden kann. Es eignet sich für Anwendungen wie:
Die Eingabeaufforderung ist zwar leicht zugänglich, bietet jedoch möglicherweise nicht immer die Präzision oder Anpassung, die für spezielle Aufgaben erforderlich ist. Die Qualität der Ergebnisse kann je nach Design der Eingabeaufforderung erheblich variieren und erfordert daher eine sorgfältige Ausarbeitung und Erprobung.
Feinabstimmung ist die Methode der Wahl, wenn Ihr Projekt ein hohes Maß an Spezifität erfordert oder sich eng an bestimmten Stilen, Tönen oder domänenspezifischen Kenntnissen orientieren muss. Sie ist besonders effektiv für:
Bei der Entscheidung zur Feinabstimmung sollte der Kompromiss zwischen der verbesserten Leistung und den zusätzlichen Kosten und Ressourcen berücksichtigt werden, die erforderlich sind. Dies ist wichtig für Projekte, bei denen der Wert von Anpassung und Genauigkeit diese Überlegungen überwiegt.
RAG eignet sich hervorragend für Situationen, in denen die Antworten mit den neuesten Informationen oder detaillierten Daten aus bestimmten Bereichen ergänzt werden müssen. Es eignet sich besonders für:
RAG kann hervorragende Ergebnisse für komplexe Abfragen und spezielle Wissensbereiche bieten, ist jedoch mit einer erhöhten Komplexität und einem erhöhten Ressourcenbedarf verbunden. Es ist die richtige Wahl, wenn der Umfang des Projekts die Investition in die Einrichtung und Wartung der notwendigen Infrastruktur für den Datenabruf in Echtzeit rechtfertigt
Die Aufforderung wird ermöglicht durch unsere LLM-Gateway Modul, das Workflows unterstützt, die häufig mit dem beste schnelle Engineering-Tools wird für LLM-Produktionsanwendungen verwendet. LLM Gateway bietet eine einheitliche API, mit der Benutzer über eine einzige Plattform auf verschiedene LLM-Anbieter zugreifen können, einschließlich ihrer eigenen selbst gehosteten Modelle. Es bietet zentrale Schlüsselverwaltungs-, Authentifizierungs- und Kostenzuordnungsfunktionen. Darüber hinaus bietet es Unterstützung für Fallback, Wiederholungsversuche sowie die Integration mit Guardrails.
Wir haben den Arbeitsablauf in einer Vorlage erstellt, um RAG mit nur wenigen Klicks einzurichten. Lesen Sie unseren Blog darüber, wie Sie eine bereitstellen RAG-basierter Chatbot mit TrueFoundry. Es kümmert sich um den gesamten Prozess der Erstellung einer Vektordatenbank, des Einbettungsmodells, LLMs usw. und bietet Ihnen gleichzeitig die richtigen Steuerelemente, um den Workflow an Ihre Bedürfnisse anzupassen.
TrueFoundry hat das vereinfacht Feinabstimmung Prozess, indem alle Feinheiten weggenommen und die richtigen Ressourcenkonfigurationen für LoRa/QLORA-Techniken konfiguriert werden. Sie können ein Jupyter-Notebook zur Feinabstimmung zum Experimentieren bereitstellen oder einen speziellen Feinabstimmungsjob starten. Bitte lesen Sie die ausführliche Anleitung hier.
Wir bei Wahre Gießerei unterstützen alle drei LLM-Lerntechniken — Prompting, RAG und Fine-Tuning — auf extrem optimierte Weise.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




