

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Large Language Models (LLMs) verändern die Art und Weise, wie Unternehmen Aufgaben automatisieren, Inhalte generieren und mit Daten interagieren. Die meisten LLM-Dienste sind heute jedoch Cloud-zentriert, was Bedenken hinsichtlich Datensicherheit, Compliance und Kontrolle aufkommen lässt.
Für Unternehmen, die mit sensiblen oder regulierten Informationen zu tun haben, ist es oft nicht praktikabel, sich auf externe APIs oder Public-Cloud-Modelle zu verlassen. Dies hat zu einer zunehmenden Verlagerung hin zu LLM-Bereitstellungen vor Ort geführt, bei denen Unternehmen Modelle sicher in ihrer eigenen Infrastruktur ausführen.
In diesem Artikel untersuchen wir, was On-Premise-LLMs sind, warum sie wichtig sind, wie sie funktionieren und wie Plattformen wie TrueFoundry skalierbare, sichere Bereitstellungen in Unternehmensumgebungen ermöglichen.

LLMs vor Ort beziehen sich auf große Sprachmodelle die innerhalb der eigenen Infrastruktur eines Unternehmens bereitgestellt und betrieben werden und nicht über externe Cloud-Dienste oder APIs von Drittanbietern. Diese Modelle können Open Source oder proprietär sein und werden in der Regel auf internen GPU-Servern, privaten Rechenzentren oder isolierten Cloud-Umgebungen ausgeführt, die so konfiguriert sind, dass sie interne Sicherheits- und Compliance-Standards erfüllen.
Im Gegensatz zu Cloud-gehosteten LLMs, die auf öffentlichen Endpunkten und einer vom Anbieter verwalteten Infrastruktur basieren, werden lokale LLMs vollständig von der Organisation kontrolliert. Dies ermöglicht eine bessere Anpassung, Feinabstimmung und Integration in interne Systeme und Workflows. Unternehmen können wählen, welche Modelle sie verwenden möchten, z. B. LLama 2, Mistral oder Mixtral, und sie auf der Grundlage spezifischer Geschäfts- oder Domänenanforderungen optimieren.
Die Bereitstellung vor Ort ermöglicht es Teams, das Modellverhalten individuell anzupassen, Richtlinien zur Datenspeicherung durchzusetzen und sicherzustellen, dass vertrauliche Informationen niemals ihr vertrauenswürdiges Netzwerk verlassen. Dies eröffnet auch Möglichkeiten für eine genauere Leistungsoptimierung und Kostenkontrolle, insbesondere für hochvolumige oder latenzempfindliche Anwendungen. Für Unternehmen, die Wert auf Autonomie, Sicherheit und die Einhaltung gesetzlicher Vorschriften legen, bieten lokale LLMs eine praktische und skalierbare Alternative zu kommerziellen KI-APIs.
Die LLM-Bereitstellung vor Ort gibt Ihnen die volle Kontrolle über Infrastruktur, Daten und Modellverhalten. Dies erfordert jedoch auch eine sorgfältige Planung, Investition und fortlaufende Verwaltung. Im Folgenden sind die wichtigsten Aspekte aufgeführt, die Sie berücksichtigen sollten:
Sie benötigen leistungsstarke Hardware, um große Sprachmodelle effizient ausführen zu können. Dazu gehören leistungsstarke GPUs wie NVIDIA A100 oder H100, reichlich RAM, Hochgeschwindigkeitsnetzwerke und schneller SSD-Speicher für große Modellgewichte und Datensätze.
Sie behalten das vollständige Eigentum an Ihren Daten und ermöglichen Air-Gap-Setups, strenge Firewall-Richtlinien und die Einhaltung von Datenschutzbestimmungen wie GDPR und HIPAA. Dies macht die Bereitstellung vor Ort ideal für Branchen, die mit sensiblen oder regulierten Informationen umgehen.
Sie müssen ML-Pipelines für Versionierung, Containerisierung, Bereitstellung und Überwachung implementieren. Eine kontinuierliche Leistungsverfolgung trägt dazu bei, die Genauigkeit, Zuverlässigkeit und Betriebsstabilität des Modells im Laufe der Zeit sicherzustellen.
Sie vermeiden zwar wiederkehrende Token-basierte API-Gebühren, aber die LLM-Bereitstellung vor Ort erfordert erhebliche Vorabinvestitionen in Hardware. Sie müssen auch die laufenden Betriebskosten wie Strom, Kühlung, Wartung und qualifiziertes Personal berücksichtigen.
Sie erhalten vollen Zugriff auf Modellgewichte und ermöglichen eine erweiterte Feinabstimmung mit proprietären Daten. Dies ermöglicht eine hochgradig maßgeschneiderte Leistung, die auf die Arbeitsabläufe Ihres Unternehmens abgestimmt ist, im Gegensatz zu generischen, in der Cloud gehosteten Modellen.
Ihre Skalierbarkeit hängt von der verfügbaren Hardwarekapazität ab. Im Gegensatz zur automatischen Cloud-Skalierung müssen Sie Workloads bei Spitzenlasten einplanen, einen Lastenausgleich implementieren und die Systeme optimieren, um eine niedrige Latenz und einen hohen Durchsatz aufrechtzuerhalten.
Ihr internes IT- oder DevOps-Team ist für Sicherheitspatches, die Wartung der Infrastruktur und Modellaktualisierungen verantwortlich. Regelmäßige Wartung gewährleistet die Zuverlässigkeit, Sicherheit und Kompatibilität des Systems mit den sich ändernden KI-Anforderungen.
Cloud-basierte KI-Dienste haben es Teams leicht gemacht, Modelle für maschinelles Lernen in großem Maßstab zu experimentieren, Prototypen zu erstellen und bereitzustellen. Wenn es jedoch um Produktionsworkloads in Unternehmensumgebungen geht, weist die ausschließliche Verwendung von Cloud-zentrierten LLMs mehrere Einschränkungen auf, die nicht ignoriert werden können.
Datenschutz und Kontrolle sind die wichtigsten Bedenken. Bei der Verwendung von Public-Cloud-APIs müssen sensible Eingabedaten über das Internet übertragen und auf einer externen Infrastruktur verarbeitet werden. Dies birgt Risiken im Zusammenhang mit Datenlecks, unbefugtem Zugriff und Compliance-Verstößen — insbesondere in Sektoren wie Gesundheitswesen, Finanzen, Verteidigung und Rechtsdienstleistungen, in denen strenge regulatorische Standards gelten.
Bindung an einen Anbieter ist ein weiterer großer Nachteil. Cloud-KI-Plattformen bündeln häufig Inferenz-APIs, Speicher und Feinabstimmung in proprietären Ökosystemen. Sobald ein Workflow rund um einen bestimmten Anbieter aufgebaut ist, wird die Migration zu einem anderen Dienst oder die interne Bereitstellung von Workloads zeitaufwändig und kostspielig. Diese Abhängigkeit schränkt die langfristige Flexibilität und Kontrolle über Modellaktualisierungen oder Nutzungsbedingungen ein.
Unvorhersehbare Kostenskalierung wird auch zu einer Herausforderung, wenn die Nutzung zunimmt. LLMs sind rechenintensiv, und Cloud-Preismodelle, die auf der Anzahl der Token oder dem Anforderungsvolumen basieren, können zu steigenden Betriebskosten führen — insbesondere bei Anwendungen mit hohem Durchsatz oder konstanter Interaktion.
Darüber hinaus bieten Cloud-Umgebungen begrenzte Optionen für niedrige Latenz- und Edge-Bereitstellungen. Anwendungen, die nahezu sofortige Reaktionen oder Offline-Funktionen erfordern, können Leistungsziele möglicherweise nur schwer erreichen, wenn sie von externen APIs abhängig sind.
Schließlich abstrahieren Cloud-Anbieter einen Großteil der Infrastruktur, sodass die Teams nur einen minimalen Einblick in Leistungsengpässe, Optimierungsmöglichkeiten oder Tuning-Parameter haben.
Für Unternehmen, die Kontrolle, Transparenz und langfristige Nachhaltigkeit fordern, sind diese Einschränkungen ein starkes Argument für die Einführung von LLM-Lösungen vor Ort.
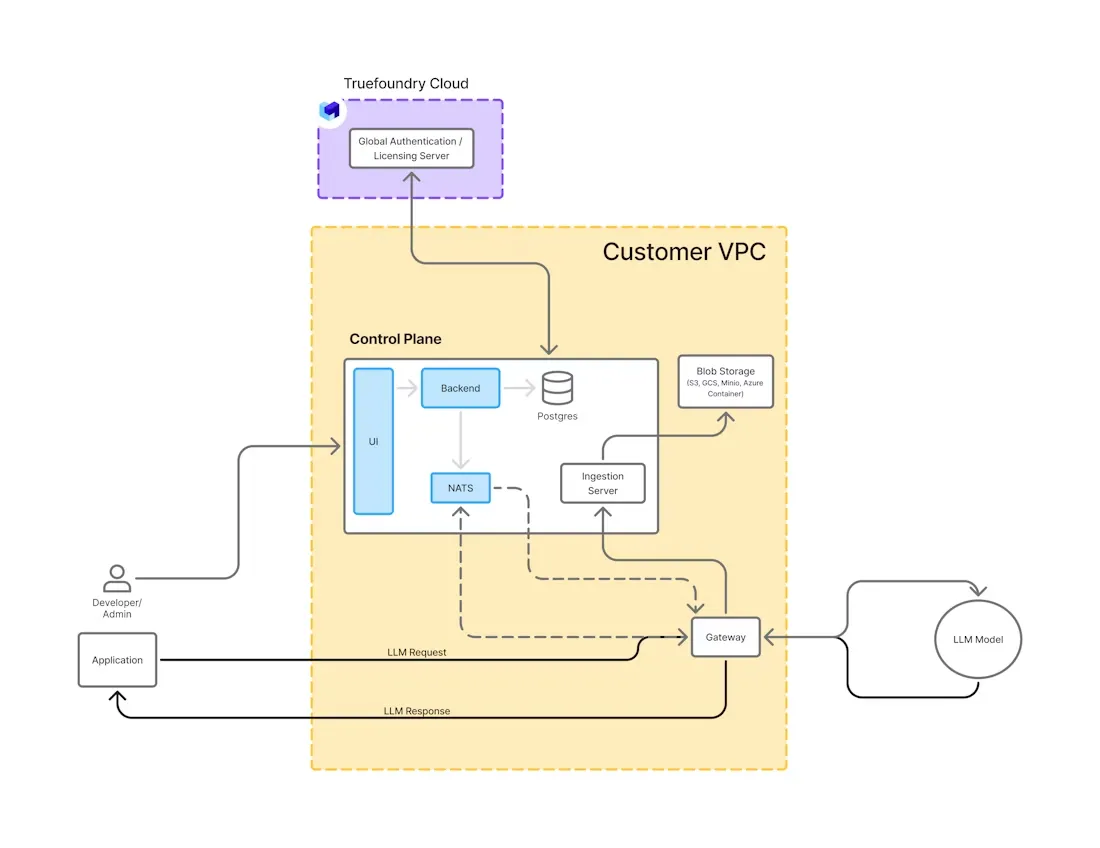
Die Bereitstellung von LLMs vor Ort erfordert eine sorgfältig strukturierte Architektur, die Leistung, Sicherheit und Wartbarkeit in Einklang bringt. Im Folgenden sind die wichtigsten Komponenten aufgeführt, die normalerweise in einer Produktionsumgebung zu finden sind.
Recheninfrastruktur: Hochleistungs-GPUs sind die Grundlage für lokale LLMs. Unternehmen verwenden häufig NVIDIA A100-, H100- oder L40-GPUs, je nach Modellgröße und Durchsatzanforderungen. Diese werden in lokalen Rechenzentren oder privaten Cloud-Clustern mit entsprechender Kühlung, Vernetzung und Speicher gehostet.
Inferenzmaschine: Inferenz-Frameworks wie vLLM, TGI oder DeepSpeed-Inference übernehmen die eigentliche Modellausführung. Sie optimieren die Speichernutzung, unterstützen Token-Streaming und ermöglichen die Stapelverarbeitung mehrerer Anfragen, um den Durchsatz zu maximieren.
Modellverwaltung und Speicher: Modelle werden lokal in sicheren Artefakt-Repositorys oder Volume-Mounts gespeichert. Versionierungs-, Rollback- und Zugriffskontrollmechanismen sind unerlässlich, um die Lebenszyklen von Modellen zu verwalten und Änderungen zu überprüfen.
Containerisierung und Orchestrierung: Tools wie Docker und Kubernetes werden zur Bereitstellung, Skalierung und Verwaltung von LLM-Workloads verwendet. Kubernetes kümmert sich um Autoscaling, GPU-Planung, Lastenausgleich und Fehlerbehebung und gewährleistet so eine konsistente Leistung aller Dienste.
API-Schicht und Routing: Eine REST- oder OpenAI-kompatible API-Ebene stellt LLM-Funktionen internen Anwendungen zur Verfügung. Sie kann aus Sicherheits- und Kontrollgründen Routing mit mehreren Modellen, Benutzerauthentifizierung und Aufforderungsfilterung umfassen.
Beobachtbarkeit und Überwachung: Metriken wie Latenz, GPU-Auslastung, Anforderungsdurchsatz und Geschwindigkeit der Token-Generierung werden mit Tools wie Prometheus, Grafana und OpenTelemetry verfolgt. Protokollierung und Warnmeldungen sind entscheidend für die Aufrechterhaltung der Verfügbarkeit und das Debuggen von Problemen.
Diese modulare Architektur ermöglicht es Unternehmen, skalierbare und sichere LLM-Systeme aufzubauen, die auf ihre internen Richtlinien, Leistungsziele und Compliance-Anforderungen zugeschnitten sind.
LLMs vor Ort werden zunehmend in Branchen eingesetzt, die Datensouveränität, Leistung mit niedriger Latenz und volle Kontrolle über KI-Pipelines erfordern. Hier sind einige häufige und wirkungsvolle Anwendungsfälle.
Krankenhäuser und Forschungslabore verwenden LLMs, um Patientennotizen zusammenzufassen, Entlassungsberichte zu erstellen und bei der klinischen Dokumentation zu helfen. Bereitstellungen vor Ort stellen sicher, dass die Gesundheitsinformationen der Patienten in der sicheren Infrastruktur des Krankenhauses bleiben, und unterstützen so die HIPAA-Konformität und die behördlichen Datenrichtlinien.
Finanzinstitute verwenden LLMs für Aufgaben wie die Zusammenfassung von Gewinnausschreibungen, die Automatisierung von Compliance-Berichten und die Analyse von Jahresabschlüssen. Lokale Einrichtungen verhindern, dass sensible Finanzdaten APIs von Drittanbietern ausgesetzt werden, und sorgen gleichzeitig für die Einhaltung interner Risikorahmen und behördlicher Prüfungen.
Agenturen verwenden LLMs für die Beantwortung von Fragen, die Zusammenfassung klassifizierter Berichte und den internen Wissensabruf. Da nationale Sicherheitsdaten strikt geheim gehalten werden müssen, ermöglichen lokale LLMs generative KI-Anwendungen, ohne gegen Datenklassifizierungsprotokolle zu verstoßen.
Anwaltskanzleien und Rechtsabteilungen verwenden LLMs, um Verträge zu analysieren, Zusammenfassungen zu erstellen und bei der Rechtsforschung zu helfen. Durch den Einsatz vor Ort wird gewährleistet, dass vertrauliche Informationen von Anwälten und Mandanten niemals die internen Server verlassen, sodass die Vertraulichkeit gewahrt bleibt und die Anforderungen der Anwaltskammer erfüllt werden.
Fertigungsunternehmen verwenden LLMs, um Anleitungen zur Fehlerbehebung zu erstellen, Sensorprotokolle zu interpretieren und Techniker vor Ort zu unterstützen. Durch den Einsatz von LLMs auf lokalen Servern wird vermieden, dass firmeneigene Maschinendaten an externe Dienste gesendet werden, und reduziert die Latenz in entfernten oder getrennten Umgebungen.
Telekommunikationsunternehmen verwenden LLMs, um Chatbots zu betreiben, Tickets zu prüfen und automatisierte Serviceempfehlungen abzugeben. Die Bereitstellung vor Ort ermöglicht eine Leistung in Echtzeit und speichert gleichzeitig die Kundendaten in der internen Infrastruktur, um die Einhaltung der regionalen Datenschutzgesetze zu gewährleisten.
Diese Anwendungsfälle zeigen, wie lokale LLMs leistungsstarke Automatisierung und Intelligenz ermöglichen, ohne Kompromisse bei Sicherheit, Compliance oder Kontrolle einzugehen.
Die Bereitstellung von LLMs vor Ort umfasst eine Reihe koordinierter Schritte, von der Modellauswahl bis zur Produktionsüberwachung. Ein klar definierter Arbeitsablauf stellt sicher, dass das System skalierbar, sicher und für die Anforderungen Ihres Unternehmens optimiert ist.
Der Prozess beginnt mit der Auswahl eines geeigneten Modells, das auf Ihrem Anwendungsfall basiert. Beliebte Open-Source-Modelle wie LLama 2, Mistral oder Mixtral werden häufig für Bereitstellungen vor Ort bevorzugt. Nach der Auswahl wird das Modell heruntergeladen, bei Bedarf quantisiert und auf Kompatibilität mit Ihrer Infrastruktur überprüft.
Als Nächstes werden GPU-Server oder private Cloud-Ressourcen vorbereitet. Dazu gehört das Einrichten von Container-Laufzeiten (z. B. Docker), Orchestratoren (z. B. Kubernetes) und Speicherebenen zum Hosten von Modellgewichten und Protokollen. Zugriffskontrollen und Sicherheitsrichtlinien sind so konfiguriert, dass sie die Compliance-Anforderungen erfüllen.
Das Modell wird in eine Inferenz-Engine wie vLLM oder TGI geladen. Diese Engines bieten die Laufzeitumgebung für Textgenerierung, Batching, Streaming und Speicheroptimierung in Echtzeit. In den Konfigurationsdateien werden die Stapelgröße, die maximale Anzahl an Tokens und die Grenzwerte für die Parallelität definiert.
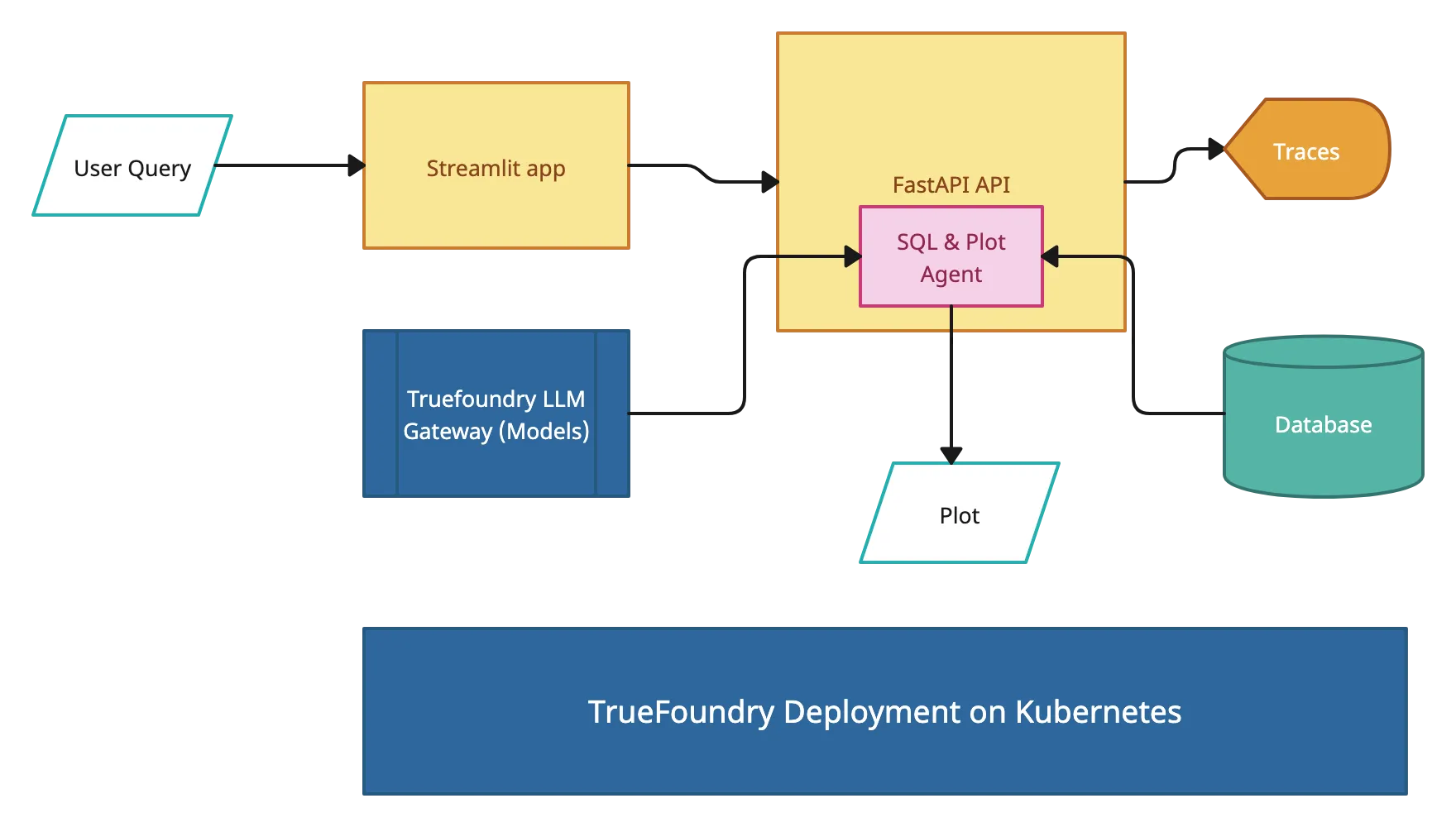
Sobald die Engine betriebsbereit ist, wird sie über eine REST- oder OpenAI-kompatible API verfügbar gemacht. Dadurch können interne Apps, Tools oder Benutzeroberflächen das Modell abfragen. Zur besseren Steuerung können auf dieser Ebene Routing, Authentifizierung und Ratenbegrenzung für mehrere Modelle hinzugefügt werden.
Observability-Tools sind miteinander verbunden, um GPU-Nutzung, Latenz, Token-Durchsatz und Anforderungsfehler zu verfolgen. Basierend auf Verkehrsmustern werden Autoscaling-Richtlinien oder manuelle Skalierungsverfahren so konfiguriert, dass die Nachfrage ohne Ausfallzeiten bewältigt werden kann.
Die Einhaltung dieses Workflows hilft Unternehmen dabei, LLMs effizient in ihrer Infrastruktur zu starten und zu verwalten, ohne auf externe Plattformen angewiesen zu sein oder vertrauliche Daten preiszugeben.
Mit diesen Tools und Techniken können Sie lokale LLMs mit hoher Leistung, Sicherheit und vollständiger Datenkontrolle bereitstellen und gleichzeitig die Zuverlässigkeit auf Unternehmensebene aufrechterhalten.
Der Einsatz von LLMs vor Ort gibt Unternehmen die volle Kontrolle über ihre KI-Infrastruktur, ist aber auch mit Kompromissen verbunden. Für eine erfolgreiche Einführung ist es unerlässlich, sowohl die Vorteile als auch die Herausforderungen zu verstehen.
TrueFoundry vereinfacht die Bereitstellung und Verwaltung großer Sprachmodelle innerhalb einer privaten Infrastruktur und macht GenAI vor Ort für Unternehmen zugänglich, ohne dass tiefes DevOps- oder MLOps-Fachwissen erforderlich ist. TrueFoundry basiert auf Kubernetes und ermöglicht eine schnelle, sichere und skalierbare LLM-Serving durch vorintegrierte Unterstützung für leistungsstarke Inferenz-Engines wie vLLM und TGI.
Die Plattform abstrahiert die Komplexität der Verwaltung von Containern, GPUs und Skalierungsrichtlinien, sodass sich Teams auf die Erstellung von Anwendungen statt auf die Wartung der Infrastruktur konzentrieren können. Mit Das KI-Gateway von TrueFoundry, Unternehmen können LLMs mithilfe von OpenAI-kompatiblen APIs bereitstellen und gleichzeitig Ratenbegrenzung, tokenbasierte Abrechnung und Routing mit mehreren Modellen anwenden, und das alles in ihrer sicheren Umgebung.
TrueFoundry bietet auch integrierte Beobachtbarkeit, einschließlich Echtzeitüberwachung der Token-Nutzung, Latenz und Modellleistung. Dies hilft Teams, den Durchsatz zu optimieren, Probleme zu beheben und die Unternehmensführung durchzusetzen.
Ganz gleich, ob Sie LLama 2, Mistral oder fein abgestimmte interne Modelle einsetzen, TrueFoundry bietet Unternehmen eine produktionsfertige Lösung für GenAI vor Ort, die vollständig anpassbar, konform und skalierbar ist.
Da Unternehmen zunehmend große Sprachmodelle einsetzen, bietet die Bereitstellung vor Ort eine sichere und flexible Möglichkeit, diese zu nutzen GenA I ohne den Datenschutz, die Einhaltung von Vorschriften oder die Infrastrukturkontrolle zu gefährden. Cloud-basierte Lösungen bieten zwar Komfort, sind aber in regulierten oder sensiblen Umgebungen oft unzureichend. LLMs vor Ort geben Unternehmen die volle Verantwortung für den Stack, eine bessere Anpassung und vorhersehbare Kosten, was sie ideal für langfristige KI-Strategien macht. Mit Plattformen wie TrueFoundry wird die interne Bereitstellung und Skalierung von LLMs schneller, effizienter und einfacher zu verwalten. Für Unternehmen, die sich auf Kontrolle, Transparenz und Innovation konzentrieren, ist GenAI vor Ort nicht nur eine Alternative, sondern auch ein strategischer Vorteil.
Sie stellen LLMs vor Ort bereit, indem Sie Modelle mit Docker containerisieren, sie über Kubernetes orchestrieren und sie über optimierte Inferenz-Engines wie vLLM oder TGI bereitstellen. Sie konfigurieren GPUs, Netzwerke und Speicher, integrieren Überwachungstools und implementieren MLOps-Pipelines, um Versionierung, Skalierung, Sicherheit und Leistung innerhalb Ihrer privaten Infrastruktur zu verwalten.
Die Cloud-Bereitstellung bietet On-Demand-Skalierbarkeit, verwaltete Infrastruktur und nutzungsabhängige Preise, während die Bereitstellung vor Ort vollständige Datenkontrolle, Anpassung und Compliance bietet. Sie tauschen Cloud-Flexibilität gegen mehr Sicherheit und Souveränität vor Ort ein, müssen aber Hardwarekosten, Wartung, Skalierungsbeschränkungen und betriebliche Komplexität intern bewältigen.
Sie können Public Cloud-LLM-Dienste, private Cloud-Umgebungen, hybride Bereitstellungen oder verwaltete KI-Plattformen verwenden. API-basierte Modelle wie OpenAI oder gehostete Hugging Face-Endpunkte reduzieren den Infrastrukturaufwand. Mit Hybrid-Setups können Sie vertrauliche Daten lokal speichern und gleichzeitig die Cloud-Skalierbarkeit für Spitzenauslastungen und Experimente nutzen.
LLMs vor Ort erfordern hohe Hardwarekosten im Voraus, kontinuierliche Wartung, qualifiziertes Personal und Kapazitätsplanung. Sie sind mit Skalierungsbeschränkungen, Strom- und Kühlungskosten und langsameren Upgrades konfrontiert. Die Verwaltung von Sicherheitspatches, Modellaktualisierungen und der Zuverlässigkeit der Infrastruktur erhöht die betriebliche Komplexität im Vergleich zu vollständig verwalteten Cloud-basierten KI-Services.
TrueFoundry vereinfacht die lokale LLM-Bereitstellung durch die Integration von Kubernetes-Orchestrierung, GPU-Planung, Modellbereitstellung, Überwachung und Sicherheitskontrollen. Sie profitieren von zentralisierter Verwaltung, RBAC, Beobachtbarkeit und nahtloser Skalierung in allen Umgebungen. Die vorintegrierten Inferenz-Engines und die Compliance-fähigen Funktionen helfen Ihnen dabei, KI auf Produktionsniveau sicher und effizient bereitzustellen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




