

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Die KI-Landschaft im Jahr 2025 entwickelt sich rasant, und Unternehmen verlassen sich zunehmend auf große Sprachmodelle, um Innovationen voranzutreiben, Abläufe zu rationalisieren und intelligentere Kundenerlebnisse zu bieten.
Angesichts der vielen Plattformen, die versprechen, die Implementierung, Orchestrierung und Governance von Modellen zu vereinfachen, kann die Auswahl der richtigen Lösung jedoch überwältigend sein. Zwei Namen, die in den Diskussionen über KI in Unternehmen an die Spitze rücken, sind Nexos AI und TrueFoundry. Beide zielen zwar darauf ab, Unternehmen dabei zu helfen, mehrere LLMs effizient zu verwalten, sie bedienen jedoch leicht unterschiedliche Zielgruppen und Anwendungsfälle.
Nexos AI konzentriert sich auf eine zentralisierte, Cloud-First-Orchestrierung für eine schnelle Integration, während TrueFoundry auf Steuerung, Skalierbarkeit und Flexibilität vor Ort auf Unternehmensebene Wert legt. Für Unternehmen, die ihre KI-Strategie zukunftssicher machen wollen, ist es entscheidend, ihre Unterschiede, Stärken und idealen Szenarien zu verstehen.
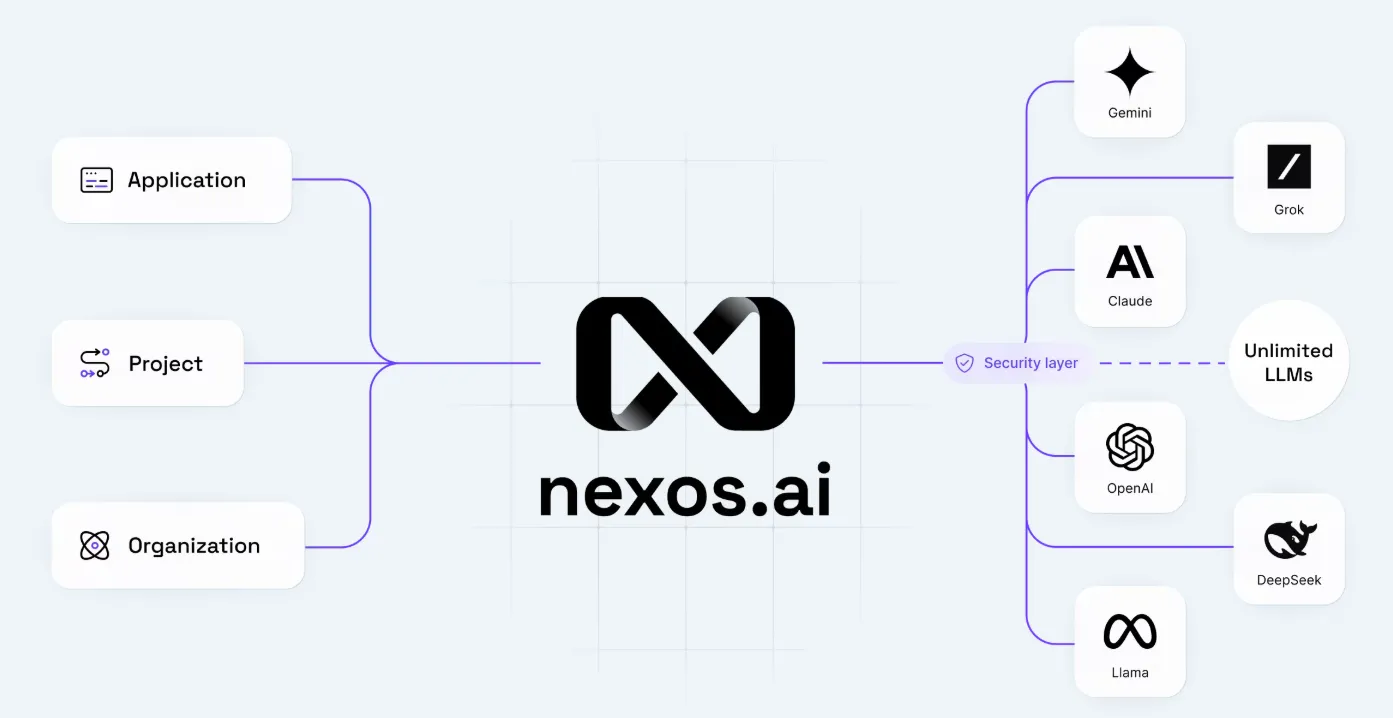
Die Verwaltung von Dutzenden von KI-Modellen kann schnell chaotisch werden. Jedes Modell verfügt über eine eigene API, eigene Macken und eine eigene Abrechnung. Nexos AI löst dieses Problem, indem es als zentrale Steuerzentrale für all Ihre KI-Modelle fungiert. Es verbindet Sie über eine einzige Plattform mit über 200 erstklassigen Modellen, sodass Sie nicht mit mehreren Integrationen jonglieren müssen.
Die wichtigsten Funktionen:
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

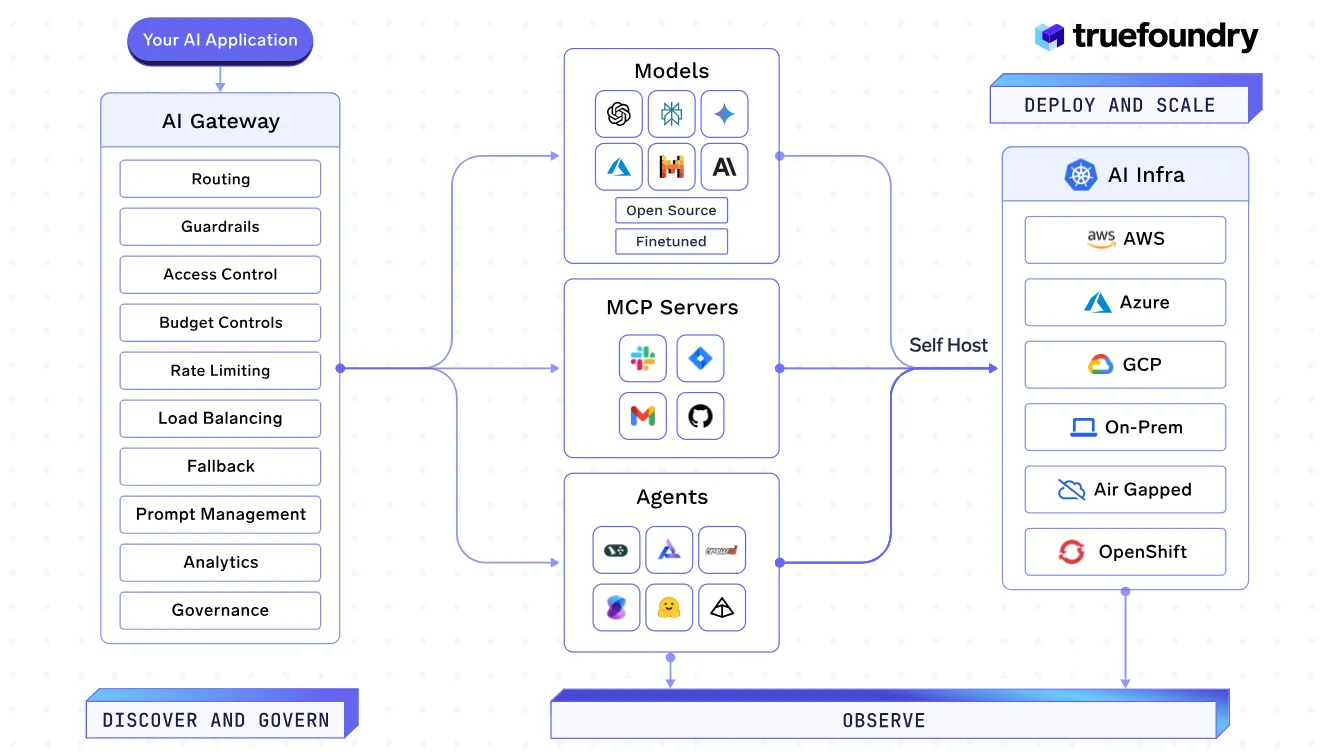
TrueFoundry ist ein KI-Gateway für Unternehmen, das ein LLM Gateway, MCP Gateway und Agent Gateway umfasst und es Unternehmen ermöglicht, agentische KI-Anwendungen anbieterübergreifend von einer einzigen Steuerungsebene aus zu verbinden, zu beobachten und zu steuern.
TrueFoundry bietet eine einheitliche Oberfläche für den Zugriff auf über 250 große Sprachmodelle (LLMs), darunter OpenAI, Claude und Gemini. Es bietet intelligentes Modellrouting, automatisches Failover und geografische Verkehrsverteilung und gewährleistet so eine hohe Verfügbarkeit und optimale Leistung. Die Plattform unterstützt multimodale Eingaben, einschließlich Text, Bild und Audio, für alle kompatiblen Modelle und lässt sich nahtlos in Model Control Planes (MCPs) integrieren, um die Arbeitsabläufe der Agenten zu verbessern.
Die wichtigsten Funktionen:
Bei der Wahl zwischen Nexos AI und TrueFoundry geht es nicht nur um Funktionen auf dem Papier, sondern auch darum, zu verstehen, wie sich jede Plattform in realen, technischen Szenarien verhält. Von der Flexibilität bei der Bereitstellung bis hin zur Modellbereitstellung, Beobachtbarkeit und Kostenmanagement — die Unterschiede können sich erheblich auf Ihre KI-Workflows auswirken.
In der folgenden Tabelle werden acht wichtige technische Aspekte hervorgehoben, sodass Sie auf einen Blick erkennen können, wo sich die einzelnen Plattformen auszeichnen und welche am besten zu Ihren Unternehmensanforderungen passt.
Nexos AI eignet sich hervorragend, wenn Unternehmen eine zentralisierte, Cloud-First-Plattform benötigen, um mehrere große Sprachmodelle zu verwalten, ohne mit separaten APIs oder Provider-SDKs zu jonglieren. Es vereinfacht die Orchestrierung, reduziert den Betriebsaufwand und ermöglicht es Teams, sich auf die Entwicklung KI-gestützter Anwendungen zu konzentrieren, anstatt sich auf die Verwaltung der Infrastruktur zu konzentrieren.
Unternehmen sollten Nexos AI in den folgenden Szenarien in Betracht ziehen:
TrueFoundry eignet sich hervorragend, wenn Unternehmen Kontrolle, Skalierbarkeit und Sicherheit auf Unternehmensebene für die Verwaltung umfangreicher Sprachmodelle und generativer KI-Workloads benötigen. Es wurde für Teams entwickelt, die KI-Modelle in großem Maßstab bereitstellen, überwachen und optimieren möchten, sei es in der Cloud, vor Ort oder in Hybridumgebungen.
Unternehmen sollten TrueFoundry in den folgenden Szenarien in Betracht ziehen:
Die Wahl zwischen Nexos AI und TrueFoundry hängt letztlich von den Prioritäten, dem Umfang und den technischen Anforderungen Ihres Unternehmens ab. Beide Plattformen bieten eine leistungsstarke KI-Orchestrierung, erfüllen jedoch leicht unterschiedliche Anforderungen.
Wählen Sie Nexos AI, wenn Sie sich auf schnelles Experimentieren, Cloud-native Workflows und zentralisierten Zugriff auf mehrere Modelle konzentrieren. Das vereinheitlichte Gateway vereinfacht die Verbindung zu über 200 LLMs. Intelligentes Caching, automatisiertes Routing und Beobachtbarkeit machen es ideal für Teams, die Flexibilität, Geschwindigkeit und Kosteneffizienz benötigen. Nexos AI funktioniert am besten, wenn Ihr Team KI-Workflows optimieren möchte, ohne eine komplexe Infrastruktur verwalten oder sich mit lokalen Bereitstellungen auseinandersetzen zu müssen.
Entscheiden Sie sich für TrueFoundry, wenn Ihr Unternehmen Skalierbarkeit, Compliance und robuste Modellbereitstellungsfunktionen auf Unternehmensebene benötigt. TrueFoundry zeichnet sich durch automatische Skalierung, fein abgestimmte Modellbereitstellung und GPU-Optimierung bei der Verwaltung hochvolumiger Produktionsworkloads aus. Die native Kubernetes-Plattform, die erweiterte Beobachtbarkeit und die starken Sicherheitsfunktionen machen es zur bevorzugten Wahl für regulierte Umgebungen oder Unternehmen mit komplexer KI-Infrastruktur.
Letztlich hängt die richtige Wahl davon ab, ob Sie Wert auf Benutzerfreundlichkeit und Cloud-First-Flexibilität legen oder volle Kontrolle, Sicherheit und skalierbare Bereitstellung auf Produktionsniveau schätzen. Verstehen Sie den Arbeitsablauf, die Infrastrukturanforderungen und die KI Ihres Teams
Sowohl Nexos AI als auch TrueFoundry bieten leistungsstarke Lösungen für die Verwaltung und Bereitstellung großer Sprachmodelle, die jedoch auf unterschiedliche Anforderungen zugeschnitten sind. Nexos AI eignet sich hervorragend für Teams, die Cloud-native Einfachheit, Orchestrierung mehrerer Modelle und schnelles Experimentieren suchen. TrueFoundry zeichnet sich durch Skalierbarkeit, Sicherheit und komplexe Produktionsbereitstellungen auf Unternehmensebene aus.
Ihre Wahl sollte mit der Infrastruktur, dem Arbeitsablauf und der KI-Strategie Ihres Unternehmens übereinstimmen. Wenn Sie die Stärken der einzelnen Plattformen kennen, können Sie diejenige auswählen, die Effizienz, Leistung und Kontrolle maximiert und so sicherstellt, dass Ihre KI-Initiativen reibungslos ablaufen und echte geschäftliche Auswirkungen haben.
TrueFoundry bietet einen vollständigen LLMOPS-Stack, während Nexos sich hauptsächlich auf das Gateway-Management konzentriert. Mit TrueFoundry können Sie Modelle in Ihrer eigenen sicheren VPC trainieren, optimieren und bereitstellen. Dieser umfassende Ansatz bietet Unternehmen im Vergleich zu spezialisierten Proxys eine bessere Kontrolle über ihre Daten und Infrastruktur.
Nein, nexos.ai fehlen die integrierten Schulungs- und Feinabstimmungspipelines, die für einen vollständigen LLMOPS-Stack unerlässlich sind. TrueFoundry bietet leistungsstarke Inferenzserver wie vLLM und sGLang für Self-Hosting-Modelle. Nexos aggregiert in erster Linie externe APIs, während TrueFoundry das Infrastrukturmanagement automatisiert, von der GPU-Planung bis hin zur speziellen Modellversionskontrolle.
Beide unterstützen Hunderte von Anbietern, TrueFoundry bietet jedoch eine überragende Flexibilität für private Bereitstellungen. Mit TrueFoundry können Sie über 1.000 Modelle skalieren, einschließlich selbst gehosteter Open-Source-Optionen wie Llama und Mistral. Dadurch wird sichergestellt, dass Sie fein abgestimmte Modelle auf einer privaten Infrastruktur bereitstellen können, ohne auf die Verfügbarkeit externer APIs angewiesen zu sein.
TrueFoundry unterstützt VPC-, lokale und Air-Gap-Umgebungen, während es sich bei nexos.ai ausschließlich um ein SaaS-Angebot handelt. Die Architektur von TrueFoundry sorgt dafür, dass sensible Daten innerhalb Ihrer Netzwerkgrenzen bleiben, um die strikte SOC 2- oder HIPAA-Konformität zu erfüllen. Nexos konzentriert sich auf eine schnelle Cloud-Integration, was die Einrichtung vereinfacht, aber Ihre Kontrolle über den Speicherort der Daten einschränkt.
Ja, aber das MCP Gateway von TrueFoundry wurde für die Abstraktion und Sicherheit von Tools auf Unternehmensebene entwickelt. Während Nexos das grundlegende API-Routing übernimmt, verwendet TrueFoundry virtuelle MCP-Server, um den Toolzugriff für KI-Agenten sicher zu verwalten. Dazu gehören native Unterstützung für RBAC, Beobachtbarkeit in Echtzeit und kostenoptimiertes Routing für alle Modelle.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




