

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Große Sprachmodelle werden schnell zu einer Kernschicht von Unternehmenssoftware. Was als cloudbasiertes Experimentieren mit gehosteten APIs begann, entwickelt sich heute zu produktionstauglichen Systemen, die in interne Tools, kundenorientierte Anwendungen und automatisierte Workflows eingebettet sind.
Im Zuge dieses Wandels stoßen viele Unternehmen auf eine harte Realität: Nicht alle KI-Workloads können in der Public Cloud ausgeführt werden.
Sensible Unternehmensdaten, urheberrechtlich geschütztes geistiges Eigentum, regulierte Workloads, latenzkritische Anwendungen und Compliance-Verpflichtungen veranlassen Teams dazu, LLMs innerhalb von lokale oder private Infrastruktur. Einfache Self-Hosting-Modelle lösen das größere Betriebsproblem jedoch nicht. Da immer mehr Teams, Anwendungen und Modelle online gehen, benötigen Unternehmen eine einheitliche Methode, um den Zugriff zu kontrollieren, Richtlinien durchzusetzen, die Nutzung zu überwachen und die Kosten in ihrem gesamten LLM-Ökosystem zu verwalten.
Hier ist ein LLM Gateway-Infrastruktur vor Ort wird grundlegend.
Anstatt dass jede Anwendung direkt in einzelne Modelle integriert werden kann, führt ein LLM-Gateway eine zentrale Steuerungsebene ein, die regelt, wie auf Modelle zugegriffen und sie verwendet werden. In lokalen Umgebungen wird dieses Gateway zum Rückgrat, das es Unternehmen ermöglicht, die LLM-Einführung sicher, gesetzeskonform und effizient zu skalieren, ohne dabei an Transparenz oder Kontrolle einzubüßen.
Ein LLM-Gateway ist eine zentrale Zugriffs- und Steuerungsebene, die sich zwischen Anwendungen und Sprachmodellen befindet. Anstatt dass Anwendungen Modelle direkt aufrufen, laufen alle LLM-Anfragen über das Gateway, wodurch Sicherheits-, Routing-, Beobachtbarkeits- und Richtlinienkontrollen an einem Ort durchgesetzt werden.
In einem Einrichtung vor Ort, sowohl das Gateway als auch die Modelle laufen vollständig innerhalb der Infrastruktur des Unternehmens — beispielsweise in einem Rechenzentrum, einer Private Cloud (VPC) oder einer Air-Gap-Umgebung. Dadurch wird sichergestellt, dass Eingabeaufforderungen, Antworten, Einbettungen und Metadaten niemals die kontrollierten Grenzen verlassen.
Auf einer hohen Ebene bietet ein lokales LLM-Gateway:
Durch die Abstraktion des Modellzugriffs hinter einer standardisierten API entkoppelt das Gateway die Anwendungsentwicklung von der Modellinfrastruktur. Teams können Modelle wechseln, fein abgestimmte Versionen einführen oder neue Governance-Regeln durchsetzen, ohne den Anwendungscode zu ändern.
In lokalen Umgebungen, in denen die Infrastruktur begrenzt ist, die Compliance-Anforderungen streng sind und die betriebliche Komplexität hoch ist, macht diese zentralisierte Gateway-Ebene die groß angelegte Einführung von LLM möglich. Sie wandelt selbst gehostete Modelle aus isolierten Bereitstellungen in eine gesteuerte, produktionsbereite KI-Plattform um.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Der Betrieb von LLMs vor Ort ist selten nur eine Infrastrukturentscheidung. Es wird normalerweise angetrieben von nicht verhandelbare Unternehmensanforderungen rund um Datenkontrolle, Sicherheit und Verwaltung. Und LLM-Gateway ist es, was diese Bereitstellungen in großem Maßstab praktisch macht.
Unternehmen verarbeiten häufig sensible Eingaben wie interne Dokumente, Kundendaten, Quellcode oder vertrauliche Daten. In regulierten Umgebungen ist es inakzeptabel, dass selbst vorübergehende, unverzügliche Daten die kontrollierte Infrastruktur verlassen.
Ein lokales LLM-Gateway stellt sicher, dass:
Dies ist besonders wichtig für Unternehmen, die unter strengen Anforderungen an die Datenlokalisierung oder Souveränität arbeiten.
Direkte Integrationen von Anwendung zu Modell führen zu fragmentierten Sicherheitsgrenzen. Am Ende verwaltet jeder Dienst seine eigenen Anmeldeinformationen, Berechtigungen und Zugriffslogik, was die Durchsetzung einheitlicher Sicherheitsstandards erschwert.
Ein LLM-Gateway zentralisiert:
Indem Unternehmen den gesamten Datenverkehr über eine einzige Steuerungsebene leiten, reduzieren sie ihre Angriffsfläche erheblich und gewinnen Vertrauen in die Art und Weise, wie auf Modelle zugegriffen wird.
Regulatorische Rahmenbedingungen verlangen von Unternehmen zunehmend die Beantwortung von Fragen wie:
Ein lokales LLM-Gateway bietet standardmäßig integrierte Audit-Trails. Jede Anfrage kann protokolliert, gemessen und nachverfolgt werden, ohne dass einzelne Anwendungsteams die Compliance-Logik korrekt implementieren müssen.
Dies ist wichtig für Umgebungen, die den GDPR-, ITAR-, HIPAA- oder internen Verwaltungsstandards unterliegen.
Lokale GPU-Ressourcen sind begrenzt und teuer. Ohne zentrale Kontrollen können Teams leicht zu viel Inferenzkapazität beanspruchen oder ineffiziente Workloads bereitstellen.
Ein LLM Gateway ermöglicht:
Dies ermöglicht es Unternehmen, LLM-Inferenz als verwaltete Ressource und nicht als unkontrollierte Ausgabe zu behandeln.
Ein vor Ort LLM Gateway ist kein einzelner Dienst. Es ist ein mehrschichtiger Infrastrukturstapel wurde entwickelt, um zu steuern, wie auf Modelle in Unternehmensumgebungen zugegriffen, diese verwaltet und betrieben werden.
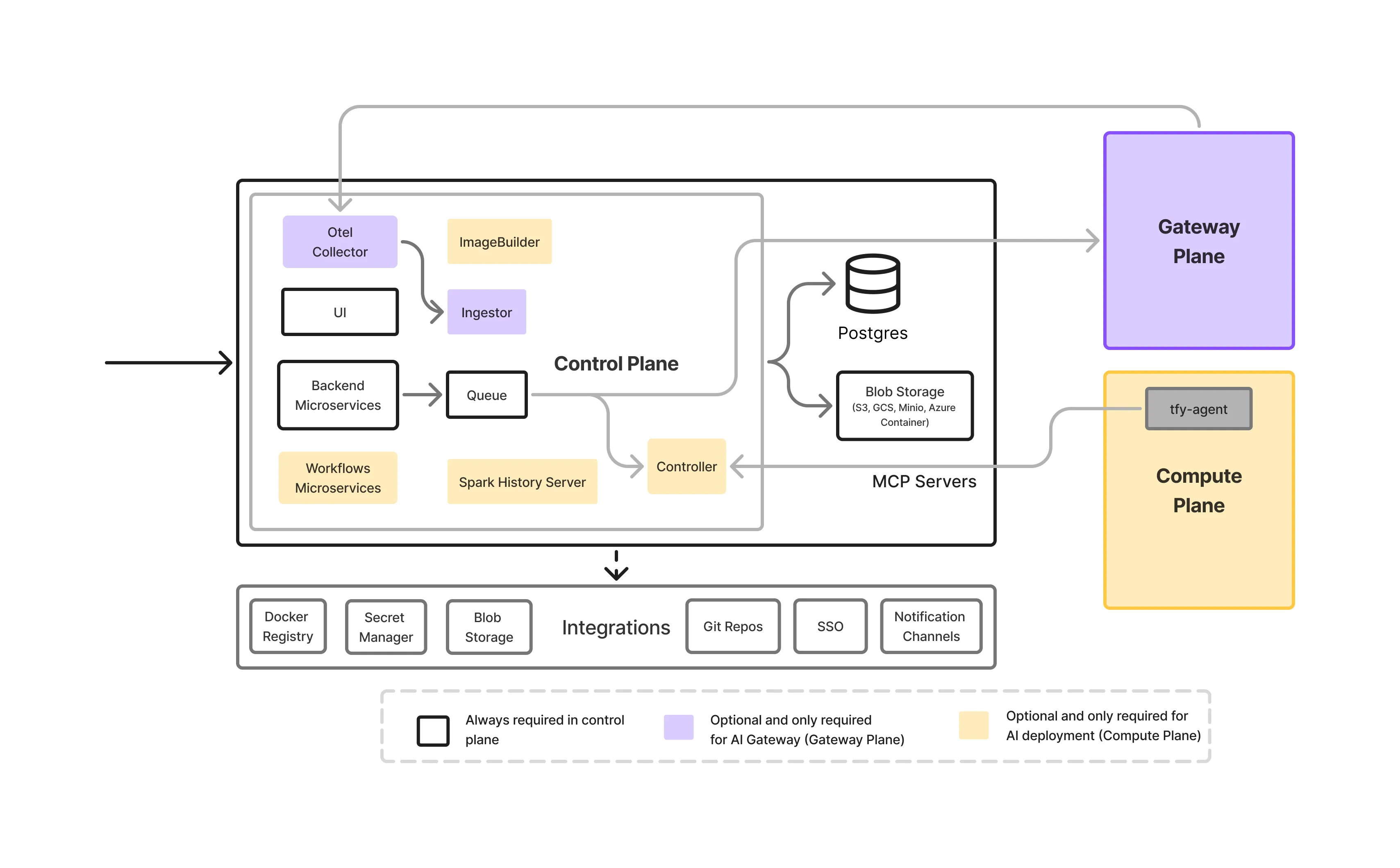
Dies ist die Eingangstür für den gesamten LLM-Verkehr.
Es kümmert sich um Authentifizierung, Autorisierung, Anforderungsvalidierung und Routing-Entscheidungen. Durch die zentrale Durchsetzung von Richtlinien müssen Anwendungsteams auf der Kontrollebene keine Sicherheits- oder Verwaltungslogik in ihren Code einbetten.
Diese Ebene ist verantwortlich für Modell servieren, das Hosten der eigentlichen LLMs, die vor Ort laufen, und sie für GPU-beschleunigte Inferenzen mit niedriger Latenz verfügbar macht, einschließlich:
Das Gateway abstrahiert diese Modelle hinter einer einheitlichen API, sodass Teams Modelle ändern oder aktualisieren können, ohne die Anwendungen zu beeinträchtigen.
Sichtbarkeit ist in lokalen Umgebungen, in denen die Ressourcen begrenzt sind, von entscheidender Bedeutung.
Das Gateway bietet:
Auf diese Weise können Teams verstehen, wie Modelle verwendet werden, und Leistungs- oder Kostenprobleme frühzeitig erkennen.
Führungsregeln werden einmal definiert und überall durchgesetzt.
Dazu gehören:
Eine zentrale Governance verhindert, dass Richtlinien zwischen Teams und Anwendungen unterschiedlich sind.
Das Gateway und die Modelldienste werden in der Regel auf einer Kubernetes-basierten Infrastruktur mit GPU-Unterstützung ausgeführt. Diese Ebene bietet:
Es stellt sicher, dass das Gateway als Teil des umfassenderen On-Prem-KI-Stacks zuverlässig funktioniert.
In einer On-Premise-Konfiguration fungiert das LLM Gateway als zentrale Steuerebene zwischen Anwendungen und selbst gehosteten Modellen. Alle Anfragen durchlaufen diese Ebene, wodurch eine konsistente Sicherheit, Steuerung und Beobachtbarkeit gewährleistet wird.
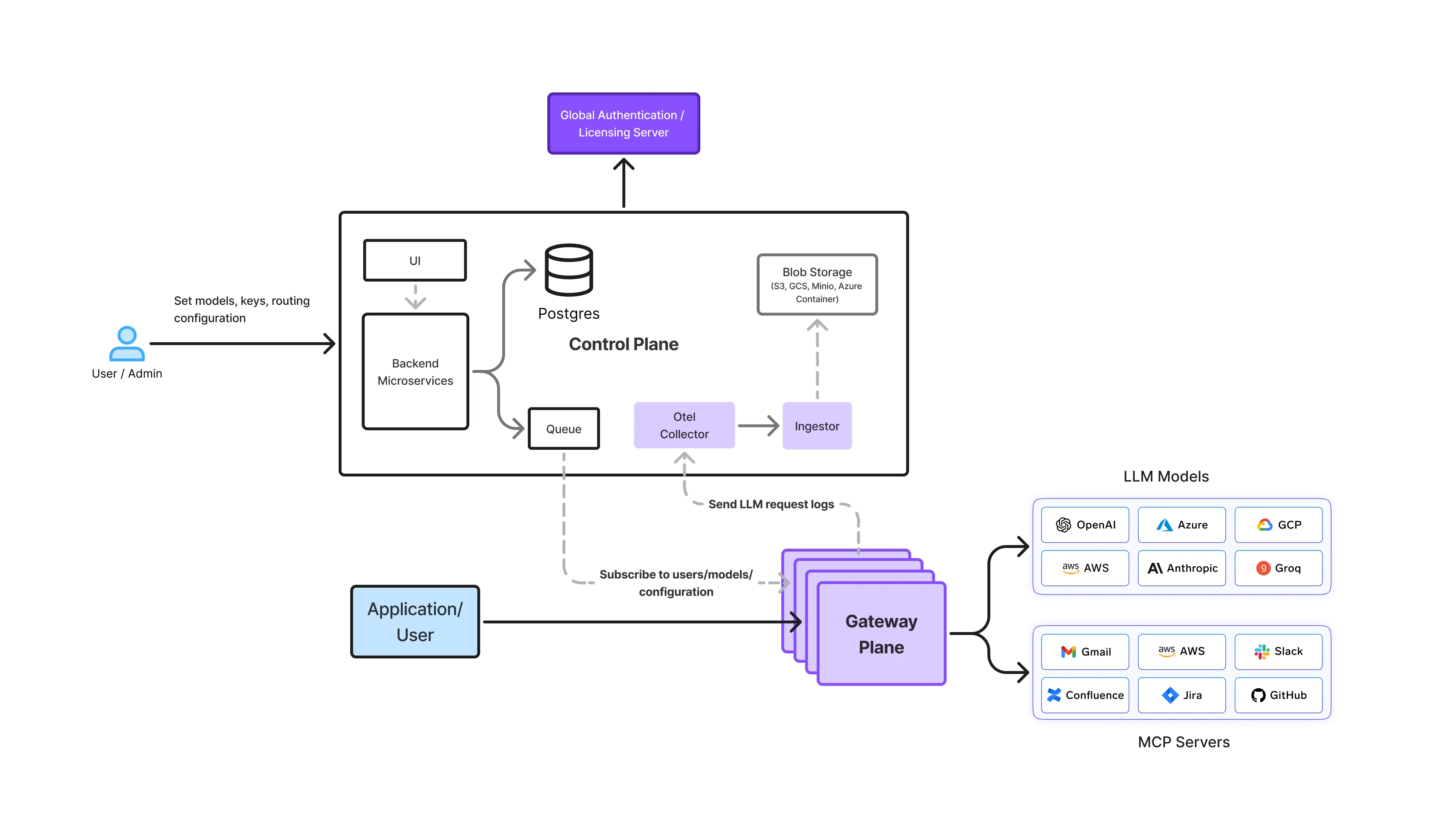
Unternehmen setzen lokale LLM-Gateways je nach Sicherheits-, Compliance- und Konnektivitätsanforderungen auf unterschiedliche Weise ein. Die Gateway-Architektur bleibt unverändert, das Bereitstellungsmodell ändert sich.
In stark regulierten Umgebungen arbeitet die Infrastruktur mit kein externer Netzwerkzugriff.
In diesen Setups bietet das LLM Gateway die vollständige Kontrolle und erfüllt gleichzeitig strenge Isolationsanforderungen.
Viele Unternehmen setzen LLM Gateways in ihren eigenen Cloud-Konten oder privaten Netzwerken ein.
Dieses Modell ist für regulierte SaaS- und Finanzdienstleistungsunternehmen üblich.
Einige Unternehmen teilen die Arbeitslasten je nach Sensitivität auf.
Das Gateway gewährleistet konsistente Richtlinien, auch wenn mehrere Ausführungsumgebungen beteiligt sind.
LLM-Gateways vor Ort bieten zwar Kontrolle und Compliance, bringen aber auch betriebliche Herausforderungen mit sich, für die Unternehmen planen müssen.
Die Verwaltung von GPU-gestützten Inferenz-Workloads vor Ort erfordert eine sorgfältige Kapazitätsplanung. Ohne Automatisierung können die Skalierung von Modellen oder die Bewältigung von Datenverkehrsspitzen betrieblich aufwändig werden.
Lokale Umgebungen haben begrenzte Rechenleistung. Ein schlechtes Routing oder fehlende Anforderungskontrollen können zu Latenzproblemen oder zu wenig ausgelasteten GPUs führen. Ein zentralisiertes Verkehrsmanagement ist unerlässlich, um Leistung und Effizienz in Einklang zu bringen.
Da mehrere Teams LLMs einführen, können die Governance-Regeln leicht abweichen, wenn sie auf Anwendungsebene durchgesetzt werden. Ohne ein zentrales Gateway ist es schwierig, konsistente Zugriffskontrollen und Nutzungsrichtlinien in allen Umgebungen aufrechtzuerhalten.
Unternehmen müssen klare Aufzeichnungen über die LLM-Nutzung führen, ohne den Speicherplatz zu überlasten oder die Leistung zu beeinträchtigen. Das richtige Gleichgewicht zwischen Beobachtbarkeit und Overhead zu finden, ist eine häufige Herausforderung.
Unternehmen, die mit LLM-Bereitstellungen vor Ort erfolgreich sind, behandeln das Gateway als Kerninfrastruktur, nicht nur ein API-Proxy.
Alle Anwendungen und Agenten sollten ausschließlich über das Gateway auf Modelle zugreifen. Dadurch werden Schattenintegrationen vermieden und eine einheitliche Sicherheit und Governance gewährleistet.
Anwendungen sollten niemals von bestimmten Modellendpunkten abhängen. Die Abstraktion der Modelle hinter dem Gateway ermöglicht es Teams, Modelle ohne Codeänderungen auszutauschen, zu aktualisieren oder zu optimieren.
Zugriffskontrollen, Ratenbeschränkungen und Nutzungsregeln sollten auf der Gateway-Ebene verankert sein und nicht in der Anwendungslogik. Dadurch wird verhindert, dass Richtlinien zwischen Teams und Umgebungen unterschiedlich sind.
Entwicklung, Inszenierung und Produktion sollten auf Infrastruktur- und Politikebene isoliert werden. Dies reduziert das Risiko und macht das Experimentieren sicherer.
Erfassen Sie ausreichend Telemetriedaten für Überprüfbarkeit und Optimierung und maskieren oder beschränken Sie sensible Eingabeaufforderungsdaten bei Bedarf. Die Beobachtbarkeit sollte die Kontrolle ermöglichen und keine neuen Risiken mit sich bringen.
Die Einhaltung dieser Praktiken stellt sicher, dass die lokalen LLM-Gateways erhalten bleiben sicher, skalierbar und verwaltbar wenn die Adoption zunimmt.
Da Unternehmen das Experimentieren hinter sich lassen und umfangreiche Sprachmodelle in Kernsysteme einbetten, Kontrolle wird genauso wichtig wie Fähigkeit. Lokale Bereitstellungen erfüllen die Anforderungen an Datenspeicherung, Sicherheit und Compliance, aber ohne eine zentrale Zugriffsebene werden sie schnell fragmentiert und schwer zu verwalten.
Ein LLM Gateway-Infrastruktur vor Ort liefert die fehlende Steuerungsebene. Es standardisiert, wie Anwendungen mit Modellen interagieren, setzt konsistente Richtlinien durch und bietet die Transparenz, die für einen verantwortungsvollen und skalierbaren Betrieb von LLMs erforderlich ist.
Auswahl der bestes LLM-Gateway Für lokale Bereitstellungen ist ein ausgewogenes Verhältnis zwischen Governance, Leistung und einfacher Bedienung erforderlich, anstatt sich ausschließlich auf das Routing von Anfragen zu konzentrieren.
Anstatt selbst gehostete Modelle als isolierte Dienste zu behandeln, verwandeln Unternehmen, die einen Gateway-First-Ansatz verfolgen, LLMs in eine verwaltete Unternehmensinfrastruktur — sicher, beobachtbar und bereit für langfristiges Wachstum.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




