

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: May 29, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Große Sprachmodelle haben eine wichtige Schwelle überschritten. Was als isolierte Experimente und Pilotprojekte begann, hat sich heute zu Produktionsworkloads entwickelt, die in alle Unternehmenssysteme eingebettet sind. Kundensupport, interne Wissenssuche, Softwareentwicklung, Analytik und autonome Agenten verlassen sich zunehmend auf LLMs als Kernbausteine und nicht auf optionale Erweiterungen.
Dieser Wandel hat eine neue Klasse von Infrastrukturproblemen aufgedeckt. LLM-Workloads verhalten sich ganz anders als herkömmliche Anwendungsdienste. Die Kosten steigen eher mit Tokens als mit Anfragen, die Latenz variiert je nach Anbieter und Region erheblich, und die Fehlermodi — Timeouts, Halluzinationen oder Teilantworten — sind oft undurchsichtig. Da Unternehmen mehrere Modelle von verschiedenen Anbietern verwenden, verschärfen sich diese Probleme schnell.
Für die meisten Unternehmen wurden frühe LLM-Integrationen mit direkten API-Aufrufen und Logik auf Anwendungsebene erstellt. Dieser Ansatz ist in großem Maßstab nicht anwendbar. Teams sehen sich schnell mit unvorhersehbaren Inferenzkosten, eingeschränktem Einblick in die Nutzung, Anbieterbindung und wachsenden Bedenken hinsichtlich der Unternehmensführung konfrontiert. Die Optimierung von LLM-Workloads wird immer schwieriger, wenn jede Anwendung ihr eigenes Routing, ihre eigenen Wiederholungsversuche, Kostenkontrollen und Logging implementiert.
Da die Einführung von KI horizontal über Teams und vertikal über Umgebungen hinweg zunimmt, Die LLM-Workload-Optimierung verlagert sich von einem Anwendungsproblem zu einem Infrastrukturproblem. Unternehmen benötigen eine zentrale Ebene, die beobachten, steuern und optimieren kann, wie Modelle konsistent und maßstabsgetreu verwendet werden. Dieser Bedarf hat das Aufkommen von KI-Gateways als grundlegende Komponente der modernen KI-Infrastruktur vorangetrieben.
Die Optimierung von LLM-Workloads unterscheidet sich grundlegend von der Optimierung herkömmlicher Rechen- oder Microservices. Die Herausforderungen sind systemischer, nicht lokalisierter Natur.
Zuerst Die Kostendynamik ist nichtlinear. Eine kleine Änderung der Eingabeaufforderungsstruktur, der Wiederholungslogik oder der Kontextgröße kann den Token-Verbrauch und die Ausgaben erheblich erhöhen. Ohne zentrale Transparenz und ohne Struktur LLM-Lösung zur Kostenverfolgung, diese Änderungen bleiben oft unbemerkt, bis die Kosten steigen. Den Kontrollen auf Anwendungsebene fehlt der globale Kontext, der erforderlich ist, um Budgets durchzusetzen oder die Effizienz zwischen Teams und Anwendungsfällen zu vergleichen.
Zweitens, Leistungsvariabilität ist inhärent. Dies wird noch sichtbarer während LLM-Inferenz, wobei Latenz und Durchsatz je nach Modell, Anbieter und Region unterschiedlich sind und je nach Auslastung und Verfügbarkeit schwanken. Die feste Kodierung eines einzelnen Anbieters oder Modells in eine Anwendung führt zu Fragilität. Wenn es zu Ausfällen oder Ratenbeschränkungen kommt, sind die Teams gezwungen, reaktive Lösungen zu finden, anstatt sie proaktiv zu optimieren.
Drittens, Die Einführung mehrerer Modelle führt zu betrieblicher Komplexität. Unternehmen verwenden zunehmend eine Mischung aus Premium-Modellen für kritische Workflows und kostengünstigeren Modellen für umfangreiche oder unkritische Aufgaben. Um diesen Mix effizient zu verwalten, sind Routing-Entscheidungen erforderlich, die Kosten, Qualität und Latenz in Einklang bringen. Entscheidungen, die nicht im Anwendungscode enthalten sein sollten.
Endlich Führung und der Compliance-Druck nimmt weiter zu. Unternehmen müssen Zugriffskontrollen durchsetzen, die Nutzung überwachen, Auditprotokolle führen und sicherstellen, dass Daten in allen Regionen gespeichert werden. Diese Anforderungen betreffen alle KI-Workloads und können nicht effektiv auf Anwendungsbasis erfüllt werden.
Zusammengenommen machen diese Faktoren deutlich, dass die LLM-Workload-Optimierung nicht stückweise gelöst werden kann. Sie erfordert eine zentrale Steuerungsebene, die Einblick in den gesamten KI-Verkehr hat und die Befugnis hat, Richtlinien konsistent durchzusetzen.
KI-Gateways begegnen dieser Herausforderung, indem sie als Steuerungsebene für LLM-Workloads. Ein KI-Gateway, das zwischen Anwendungen und Modellanbietern positioniert ist, zentralisiert, wie LLM-Anfragen weitergeleitet, beobachtet, gesteuert und optimiert werden.
Im Gegensatz zu herkömmlichen API-Gateways wurden KI-Gateways speziell für die Eigenschaften von LLM-Workloads entwickelt. Sie verstehen modellspezifisches Verhalten, tokenbasierte Preisgestaltung, Latenzkompromisse und die Notwendigkeit einer feinkörnigen Beobachtbarkeit. Auf diese Weise können Optimierungsstrategien einmal auf der Infrastrukturebene implementiert und einheitlich auf alle Anwendungen angewendet werden.
Auf hohem Niveau ermöglichen KI-Gateways die LLM-Workload-Optimierung durch:
Dieser architektonische Ansatz entkoppelt die Anwendungslogik von der Modellverwaltung. Entwickler konzentrieren sich auf die Entwicklung KI-gestützter Funktionen, während die Plattformteams die Kontrolle über Leistung, Kosten und Risiken behalten.
Da Unternehmen ihren Einsatz von LLMs ausweiten, wird diese Trennung von entscheidender Bedeutung. Ohne sie sind die Optimierungsbemühungen fragmentiert, reaktiv und schwer aufrechtzuerhalten. Damit erhalten Unternehmen eine konsistente, messbare und wiederholbare Möglichkeit, LLM-Workloads effizient auszuführen, unabhängig davon, wie viele Modelle, Teams oder Anwendungen beteiligt sind.
In dem Maße, in dem Unternehmen LLMs einsetzen, werden Optimierungsstrategien systematischer und infrastrukturorientierter. Bis 2026 werden sich mehrere Muster als Standardpraxis in Unternehmen herauskristallisieren, die LLM-Workloads in großem Umfang ausführen.
Anstatt die Modellauswahl als feste Wahl zu betrachten, übernehmen Unternehmen kostenbewusste Orchestrierung. In diesem Modell balancieren KI-Gateways Kosten, Qualität und Latenz auf der Grundlage des Kontextes jeder Anfrage dynamisch aus.
Zum Beispiel:
Dieser Ansatz ermöglicht es Unternehmen, ihre Ausgaben zu optimieren, ohne die Benutzererfahrung zu beeinträchtigen. Im Laufe der Zeit entsteht auch eine Feedback-Schleife, in der echte Nutzungsdaten als Grundlage für bessere Orchestrierungsentscheidungen dienen.
Regulatorische Anforderungen und geopolitische Realitäten verändern die Art und Weise, wie KI-Systeme eingesetzt werden. Unternehmen sind zunehmend tätig geopartitionierte KI-Stacks, wo LLM-Workloads nach Regionen isoliert sind, um die Anforderungen an Datenresidenz, Datenhoheit und Compliance zu erfüllen.
In der Praxis bedeutet das:
KI-Gateways spielen eine zentrale Rolle bei der Durchsetzung dieser Einschränkungen und bieten dennoch ein einheitliches Betriebsmodell für alle Regionen.
Da die Nutzung von LLM immer weiter steigt, gehen Unternehmen davon ab, wiederholt große Kontexte an Modelle zu senden. Stattdessen übernehmen sie werkzeuggestützte KI-Systeme, wo Modelle Informationen bei Bedarf über kontrollierte Schnittstellen abrufen.
Diese Schicht:
KI-Gateways vermitteln zunehmend nicht nur Modellaufrufe, sondern auch die Tool- und API-Ausführung und stellen so sicher, dass KI-Systeme auf kontrollierte und überprüfbare Weise mit Unternehmensdaten interagieren.
Der Aufstieg autonomer und halbautonomer Agenten bringt neue Optimierungsherausforderungen mit sich. Agenten führen häufig mehrere Modellaufrufe durch, rufen Tools auf und führen Workflows mit langer Laufzeit aus.
Führende Unternehmen weiten Optimierungsstrategien auf die Agentenebene aus, indem sie:
KI-Gateways werden weiterentwickelt, um diesen Wandel zu unterstützen. Sie dienen als Vermittlungsebene sowohl für die Modellinferenz als auch für die Agentenausführung.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Die Wahl eines KI-Gateways ist keine Tooling-Entscheidung — es ist eine Verpflichtung zur Infrastruktur. In den meisten Unternehmen befindet sich diese Ebene im kritischen Pfad jeder LLM-gestützten Anwendung, sodass die Entwurfsentscheidungen später nur schwer rückgängig zu machen sind. Daher sollte sich die Bewertung weniger auf Funktionen auf oberflächlicher Ebene als vielmehr auf die architektonische Eignung, die betriebliche Reife und die langfristige Flexibilität konzentrieren.
Im Folgenden finden Sie einen praktischen Rahmen, den technische Führungskräfte verwenden können, um KI-Gateways speziell unter dem Gesichtspunkt der LLM-Workload-Optimierung zu bewerten.
Ein führendes KI-Gateway sollte eine echte Nutzung mehrerer Modelle ermöglichen, ohne dass Anwendungen gezwungen werden, sich zu ändern, wenn sich Modelle oder Anbieter ändern.
Wichtige Fragen, die Sie stellen sollten:
Wenn die Modellauswahl in die Anwendungslogik eindringt, erfolgt die Optimierung langsam und spröde.
LLM-Optimierung ist ohne Kostentransparenz nicht möglich. Gateways sollten Einblicke und Durchsetzungsmöglichkeiten auf der Ebene bieten, auf der Entscheidungen getroffen werden.
Suchen Sie nach:
Ein Gateway, das nur die Gesamtnutzung meldet, reicht für eine echte Optimierung nicht aus.
Da sich das Gateway im Hot-Pfad befindet, sind die Leistungsmerkmale von Bedeutung.
Evaluieren Sie:
Selbst eine kleine Leistungseinbuße kann sich in großem Maßstab verschärfen.
Die Optimierung hängt von Rückkopplungsschleifen ab. Das Gateway sollte als Aufzeichnungssystem für LLM-Aktivitäten dienen.
Prüfen Sie, ob das Gateway Folgendes bietet:
Wenn sich die Beobachtbarkeit als gesichert anfühlt, erfolgt die Optimierung eher reaktiv als systematisch.
Die Optimierung muss mit der Risikokontrolle des Unternehmens koexistieren.
Zu den wichtigsten Überlegungen gehören:
Ein Gateway, das Kompromisse zwischen Optimierung und Compliance erfordert, wird in regulierten Umgebungen nicht skalieren.
Prüfen Sie abschließend, wie sich das Gateway in Ihre bestehende Infrastruktur und Ihr Betriebsmodell einfügt.
Erwägen Sie:
Je enger das Gateway in Ihren Plattform-Stack integriert ist, desto einfacher wird es sein, es langfristig zu betreiben.
True Foundry's Die Architektur basiert auf einer klaren Prämisse: LLM-Workload-Optimierung ist ein Infrastrukturproblem, keine Anwendungsverantwortung. Aus diesem Grund ist das KI-Gateway als erstklassige Steuerungsebene konzipiert, die im Mittelpunkt des KI-Stacks des Unternehmens steht.
In einer TrueFoundry-Bereitstellung interagieren Anwendungen und Agenten niemals direkt mit Modellanbietern. Stattdessen fließt der gesamte LLM-Verkehr durch den KI-Gateway, das als zentrale, stabile Schnittstelle für Inferenz, Routing, Observability und Governance fungiert.
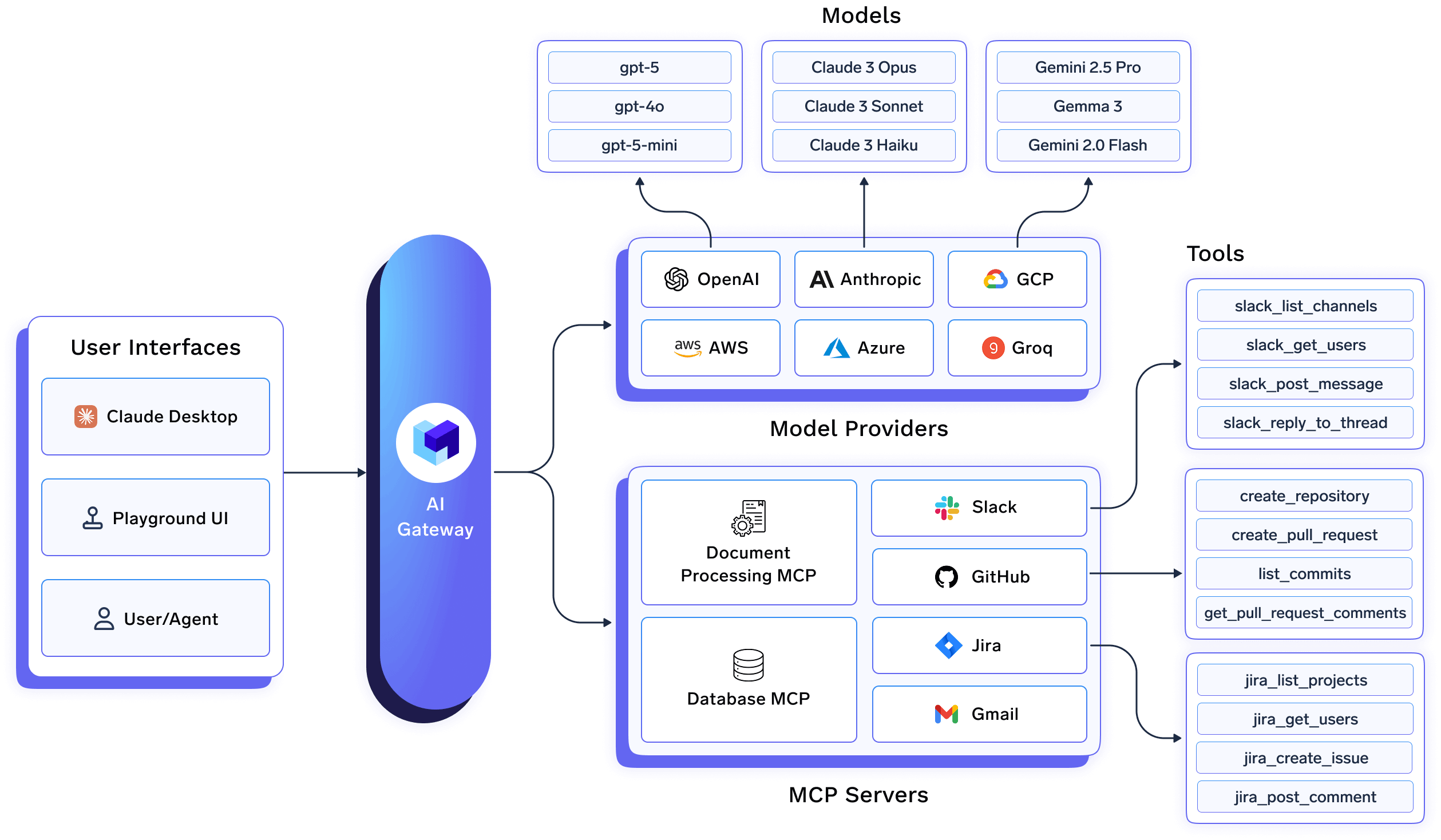
Auf architektonischer Ebene bedeutet das:
Dieses Design entfernt modellspezifische Bedenken aus dem Anwendungscode und ermöglicht die unabhängige Entwicklung von Optimierungsstrategien.
Das AI Gateway von TrueFoundry ermöglicht einen echten Betrieb mit mehreren Modellen, indem es anbieterspezifische APIs hinter einem einzigen Vertrag abstrahiert. Routing-Entscheidungen, z. B. welches Modell verwendet werden soll, wann ein Fallback erforderlich ist oder wie Kosten und Latenz in Einklang gebracht werden sollen, werden zentral am Gateway getroffen.
In der Praxis ermöglicht dies Plattformteams:
Da das Routing am Gateway abgewickelt wird, können Änderungen der Preise, der Leistung oder der Anbieterverfügbarkeit sofort berücksichtigt werden, ohne dass Änderungen auf Anwendungsebene erforderlich sind.
Ein Kernprinzip der TrueFoundry-Architektur besteht darin, dass das AI Gateway als Aufzeichnungssystem für alle LLM-Aktivitäten. Jede Anfrage, die das Gateway passiert, wird mit detaillierten Metadaten erfasst, einschließlich Modellauswahl, Token-Nutzung, Latenz und Anforderungskontext.
Im Gegensatz zu vielen Plattformen, die diese Daten in herstellerverwalteten Systemen zentralisieren, stellt das Design von TrueFoundry Folgendes sicher:
Dieser Ansatz vermeidet das „Blackbox“ -Problem und ermöglicht es Unternehmen, langfristige Optimierungs-Feedback-Schleifen mit ihren eigenen Daten aufzubauen.
True Foundry's KI-Gateway bettet Kosten- und Governance-Kontrollen direkt in den Anforderungspfad ein. Anstatt sich auf nachgelagerte Abrechnungsberichte oder externe Tools zu verlassen, erfolgen Optimierung und Durchsetzung in Echtzeit.
Zu den wichtigsten architektonischen Funktionen gehören:
Da diese Steuerungen zentralisiert sind, erbt sie jede LLM-betriebene Anwendung automatisch. Dadurch ist es möglich, die KI-Nutzung teamübergreifend zu skalieren, ohne die Governance-Logik zu duplizieren.
Das AI Gateway von TrueFoundry ist so konzipiert, dass es dort eingesetzt werden kann, wo Unternehmensdaten bereits gespeichert sind. Es kann in privaten VPCs, lokalen Umgebungen oder kontrollierten Cloud-Regionen ausgeführt werden, sodass Unternehmen strenge Anforderungen an den Datenspeicherort und behördliche Auflagen erfüllen können.
Architektonisch unterstützt dies:
Dieses Design passt zu Unternehmen, die in verschiedenen Ländern tätig sind und in denen der Datenaustausch streng kontrolliert werden muss.
Die Gateway-orientierte Architektur von TrueFoundry ist auch auf die Umstellung hin zu agentenbasierten KI-Systemen ausgerichtet. Da Agenten zunehmend mehrstufige Workflows orchestrieren und Tools oder APIs aufrufen, wird das Gateway zum natürlichen Durchsetzungspunkt.
Innerhalb dieses Modells kann das AI Gateway:
Dadurch wird das Gateway nicht nur als Inferenzschicht, sondern auch als umfassendere Ausführungssteuerungsebene für intelligente Systeme positioniert.
Das entscheidende Merkmal des Ansatzes von TrueFoundry ist, dass Optimierung, Governance und Observability werden einmal auf der Infrastrukturebene implementiert und überall wiederverwendet. Dies reduziert die betriebliche Komplexität, verbessert die Konsistenz und ermöglicht es Unternehmen, LLM-Workloads zu skalieren, ohne die Kontrolle zu verlieren.
Die umfassendere Erkenntnis ist, dass das AI Gateway von TrueFoundry nicht als Add-On positioniert ist, sondern als Kerninfrastruktur der KI. TrueFoundry behandelt das Gateway als langlebige Architekturebene und folgt damit der Denkweise von Unternehmen über kritische Systeme wie API-Gateways, Datenplattformen und Rechenorchestrierung.
Da die Akzeptanz von LLM zunimmt, ist die Optimierung nicht mehr eine Frage der schnellen Abstimmung oder Modellauswahl — es ist eine Entscheidung über die Infrastruktur. Kostenschwankungen, Leistungsschwankungen und Governance-Anforderungen erfordern eine zentrale Steuerungsebene, die modell-, team- und anwendungsübergreifend funktionieren kann.
KI-Gateways haben sich als diese Ebene herauskristallisiert. Durch die Konsolidierung von Routing, Beobachtbarkeit, Kostenkontrolle und Durchsetzung von Richtlinien machen sie die LLM-Optimierung zu einer systematischen Fähigkeit und nicht zu einer kontinuierlichen betrieblichen Belastung.
Plattformen wie Wahre Gießerei spiegeln Sie diesen Wandel wider, indem Sie das AI Gateway als Kernstück der KI-Infrastruktur von Unternehmen betrachten. Für technische Führungskräfte ist die Botschaft klar: Eine nachhaltige LLM-Skalierung hängt weniger von der Wahl des richtigen Modells ab, sondern mehr davon, die richtige Grundlage für ihren Betrieb zu schaffen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




