

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Da das Spektrum der Anwendungsfälle für maschinelles Lernen in den letzten Jahren stark zugenommen hat, ist auch die Notwendigkeit, die Abläufe rund um das Training, den Einsatz und die Überwachung dieser Modelle zu skalieren, sehr wichtig geworden. Viele dieser Probleme ähneln denen, die für allgemeine Software-Anwendungsfälle „gelöst“ wurden. Kubernetes ist eine solche Open-Source-Software, die das Cloud-native Ökosystem um sich herum konsolidiert hat, indem sie als zugrundeliegende Plattform dient.
Daher ist es unerlässlich zu untersuchen, ob es nützlich ist, Kubernetes für einen Anwendungsfall des maschinellen Lernens zu nutzen. Beginnen wir zunächst mit Kubernetes selbst und dem, was daran so interessant ist.

Quelle: Kubernetes
💡 Kubernetes ist eine Open-Source-Engine zur Container-Orchestrierung zur Automatisierung der Bereitstellung, Skalierung und Verwaltung von containerisierten Anwendungen.
Einfacher ausgedrückt bietet Kubernetes eine einfache und standardisierte Möglichkeit, Workloads auszuführen und zu betreiben, die dynamisch auf mehrere Maschinen skaliert werden müssen.
Lassen Sie uns einige der beliebtesten Funktionen durchgehen -
Dies sind nur einige der Funktionen, die standardmäßig verfügbar sind. Eine große Anzahl von Anwendungsfällen wird tatsächlich durch die Tools gelöst, die unter Verwendung von Kubernetes als zugrunde liegender Ebene erstellt wurden. In einer späteren Ausgabe werden wir uns mit bestimmten Tools befassen.
Nachdem wir verstanden haben, was Kubernetes ist und welche Hauptfunktionen es in einem Softwareentwicklungsszenario bietet, wollen wir uns mit den spezifischen Problemen befassen, die es in einem Datenwissenschaftler-Workflow lösen kann.
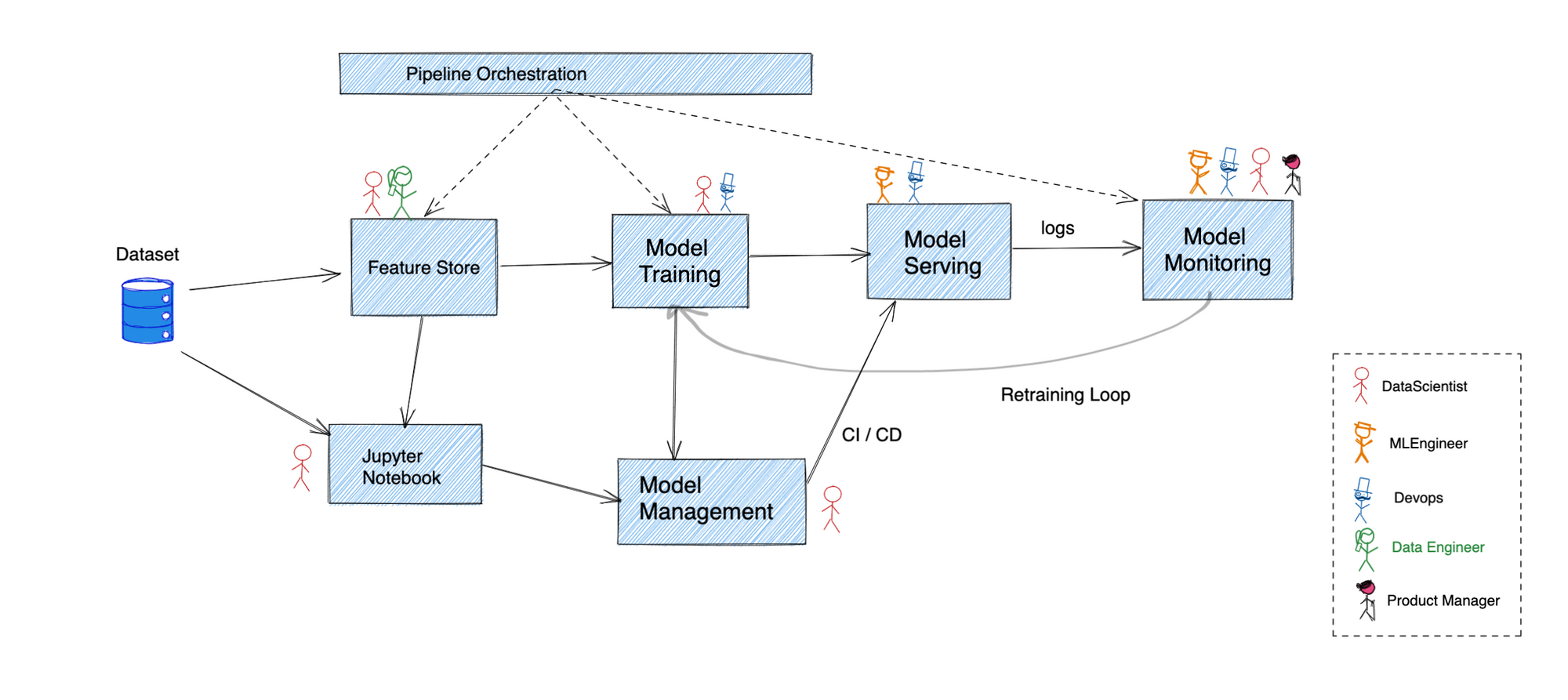
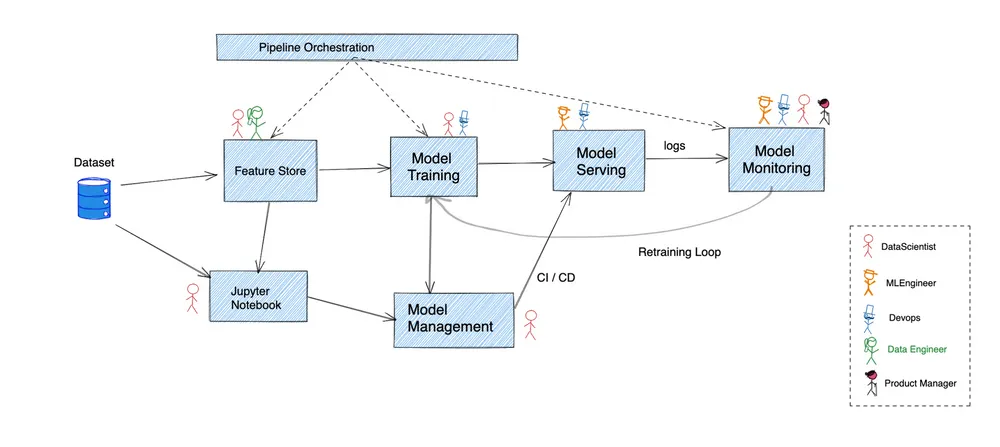
Die obige Abbildung gibt einen groben Überblick darüber, wie eine typische Data-Science-Pipeline abläuft. Viele Unternehmen haben sich für eine Vielzahl maßgeschneiderter Lösungen mit sich überschneidenden Funktionen entschieden, um alles miteinander zu verbinden.
Wir werden jeden dieser Schritte durchgehen, um herauszufinden, wo Kubernetes die richtige Wahl ist —
Bevor Rohdaten nutzbar gemacht werden können, müssen sie zunächst in bereinigte Eingaben für die Modelltrainingspipeline umgewandelt werden. An dieser Stelle kommen Feature-Speicher ins Spiel, indem sie die Feature-Daten transformieren, speichern und bereitstellen.
Kubernetes unterstützt die Bereitstellung von statusbehafteten Workloads und lässt sich sehr gut in Cloud-Anbieter integrieren, um eine nahtlose Persistenz zu gewährleisten.
Die meiste Modellentwicklung beginnt damit, dass ein ML-Ingenieur Code in ein Jupyter-Notebook schreibt, und für viele ist das fast alles, was benötigt wird. Es bietet eine REPL-Schnittstelle zum Ausführen von Python-Code. Dies beginnt damit, dass es auf persönlichen Laptops gehostet wird, aber es ist besser, einen zentralisierten Pool von gehostete Jupyter-Notebooks die von mehreren Personen genutzt werden kann.
Das deklarative Modell von Kubernetes und die Unterstützung persistenter Speichersysteme machen es trivial, einen Pool von Notebooks zu hosten und die Zugriffskontrolle über einzelne Notebooks zu ermöglichen, um eine effektive Zusammenarbeit zu erzwingen.
Jeder auf ein Notebook geschriebene Algorithmus muss mit Trainingsdaten gefüttert werden, um ein Modellartefakt als Ausgabe zu erhalten. In kleineren Anwendungsfällen kann dies im Notebook selbst geschehen, für größere Datensätze ist jedoch eine wesentlich leistungsfähigere Pipeline erforderlich. Normalerweise wird hier auch die Validierung anhand des Testdatensatzes durchgeführt, bevor das Artefakt für die Durchführung von Schlussfolgerungen in der Produktion verwendet wird.
Es gibt mehrere Lösungen für die Orchestrierung einer DAG-Pipeline auf Kubernetes. Airflow bietet native Unterstützung für Kubernetes, während Kubeflow vollständig auf Kubernetes basiert. Alle wichtigen Überwachungslösungen bieten eine erstklassige Integration mit Kubernetes, die für den Betrieb von Pipelines in Produktionsqualität unerlässlich ist.
In dieser Phase werden der Datensatz und das Modell gespeichert und versioniert. Dadurch wird sichergestellt, dass jedes Modellartefakt so lange wie nötig reproduzierbar bleibt. Es kann eine Parallele dazu gezogen werden, wie die Codeverwaltung mit Git durchgeführt wird.
Obwohl der zugrunde liegende Datenspeicher für solche Managementsysteme auf Kubernetes selbst gehostet werden kann, ist es in vielen Fällen besser, eine verwaltete Lösung eines Cloud-Anbieters zu verwenden. In solchen Fällen integrieren die meisten Cloud-Anbieter ihre eigenen IAM-Systeme nahtlos in die von Kubernetes, sodass der Zugriff auf Daten von außerhalb des Clusters sicher ist, ohne die Zugangsdaten speichern zu müssen.
Schließlich wird das Modellartefakt so vorbereitet, dass ein Produktionssystem daraus Rückschlüsse ziehen kann. Dies beinhaltet in der Regel, ein Modell in ein API-Framework einzubinden und anderen Diensten zu erlauben, das Modell aufzurufen, um Rückschlüsse zu ziehen. Hier kommen ähnliche Bedenken wie bei der Softwareentwicklung wie Authn/Authz, Skalierbarkeit, Zuverlässigkeit usw. ins Spiel.
Hier glänzt Kubernetes. Die meisten Funktionen, über die wir im vorherigen Abschnitt gesprochen haben, werden zu diesem Zeitpunkt von entscheidender Bedeutung.
Wie bei jedem Produktionssystem ist die kontinuierliche Überwachung des aktuell eingesetzten Modells unerlässlich, um sicherzustellen, dass sich Ihr System erwartungsgemäß verhält. Die Metriken, auf die Sie achten sollten, können alles umfassen, von der tatsächlichen Genauigkeit der Vorhersagen bis hin zur Latenz und dem Durchsatz, den das System unterstützen kann.
Viele Monitoring-Lösungen lassen sich eng mit Kubernetes integrieren. Ein Ziel zu finden, um tatsächlich Metriken zu scrapen, darauf aufbauend Berechnungen durchzuführen und sie für die spätere Verwendung zu speichern — all das kann ohne externe Abhängigkeit durchgeführt werden.
Die gesamte Landschaft rund um Kubernetes ist explosionsartig explodiert und es gibt bereits eine Menge Tools. Es gibt jedoch einige Fallstricke, die jede Organisation berücksichtigen sollte, bevor sie sie flächendeckend einsetzt. Wir werden uns in der nächsten Ausgabe mit diesen befassen und darauf, wie sie gemildert werden können.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.









.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




