

May 8, 2024
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Während große Sprachmodelle vom Experimentieren zur Produktion übergehen, überdenken die Teams, wie der KI-Verkehr verwaltet, gesichert und beobachtet werden sollte. Was früher wie eine einfache API-Integration aussah, beinhaltet heute Aufforderungen, Tokens, Modellweiterleitung, Wiederholungsversuche, Kostenverfolgung und Zuverlässigkeitsprobleme, für die eine herkömmliche Anwendungsinfrastruktur nie konzipiert war.
Viele Entwicklungsteams beginnen diese Reise mit der Erweiterung vertrauter API-Gateways wie Kong, wobei bestehende Routing-, Authentifizierungs- und Ratenbegrenzungsmuster genutzt werden. Da die LLM-Nutzung zunimmt, bieten KI-native Gateways wie Portschlüssel Betreten Sie das Bild und bieten Sie Abstraktionen, die auf Aufforderungen, Modelle und Beobachtbarkeit auf Token-Ebene zugeschnitten sind.
Beide Ansätze zielen darauf ab, reale Probleme zu lösen, gehen jedoch von grundlegend unterschiedlichen Ausgangspunkten aus. Kong hat seine Wurzeln in der Verwaltung von HTTP-APIs und Microservices, während Portkey speziell für LLM-Anwendungsworkflows entwickelt wurde. Die Unterschiede zwischen diesen Philosophien werden immer wichtiger, da KI-Systeme über Teams, Umgebungen und Produktionsanwendungsfälle hinweg skaliert werden.
In diesem Artikel vergleichen wir Kong und Portkey in Bezug auf Architektur, Beobachtbarkeit, Governance und Unternehmensfähigkeit. Wir schauen uns an, wo die einzelnen Tools am besten geeignet sind, wo Einschränkungen auftauchen und welche Plattformteams berücksichtigen sollten, wenn KI zu einem zentralen Bestandteil ihres Infrastruktur-Stacks wird.
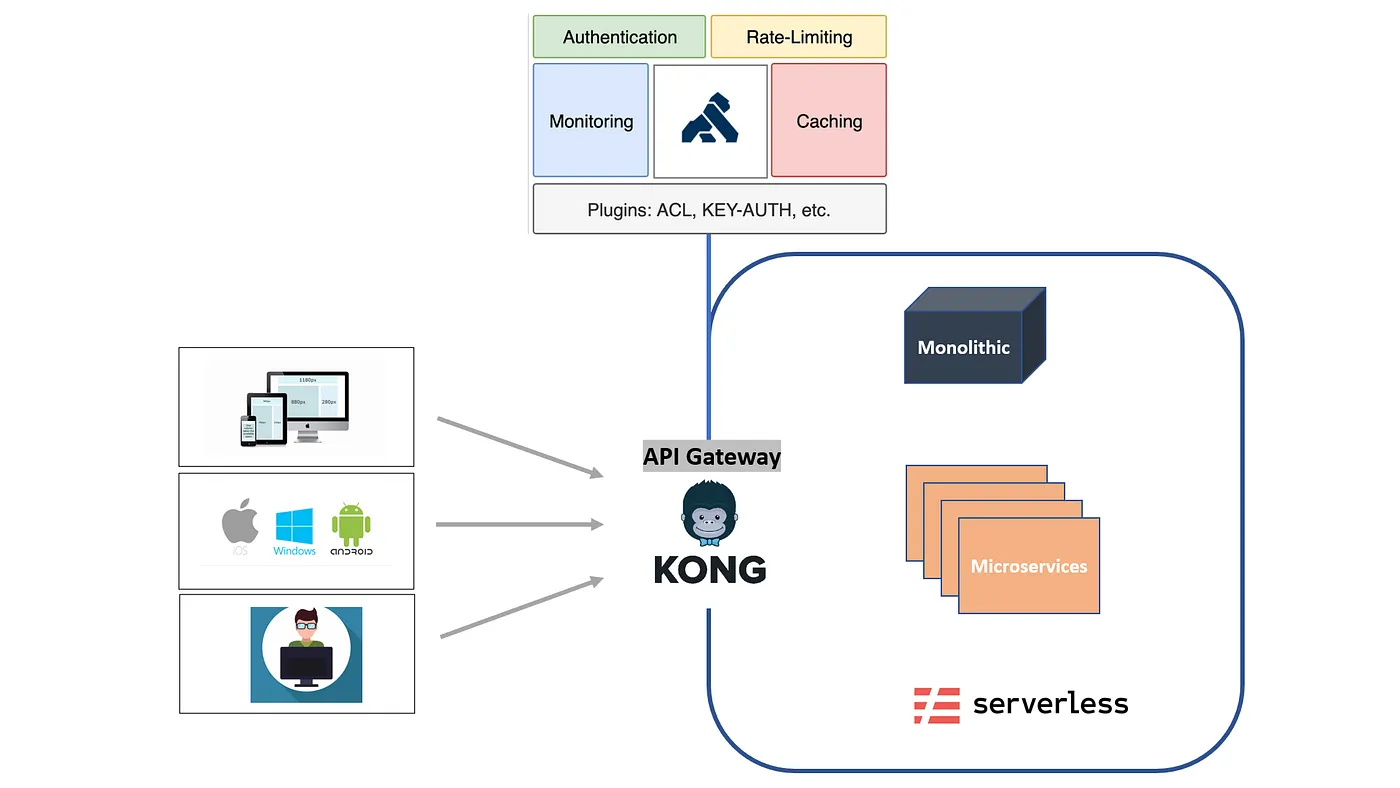
Kong ist ein weit verbreitetes API-Gateway zur Verwaltung, Sicherung und Weiterleitung von HTTP-Verkehr über Microservices. Es wird häufig als Eingangsebene in Kubernetes-basierten Architekturen verwendet und ist bekannt dafür, Probleme wie Authentifizierung, Ratenbegrenzung, Traffic-Routing und Beobachtbarkeit auf Anforderungsebene zu lösen.
Aus architektonischer Sicht ist Kong optimiert für API-First-Systeme. Seine Kernabstraktionen drehen sich um Endpunkte, Dienste, Routen und Plugins. Dadurch eignet es sich hervorragend für traditionelle Backend- und Microservice-Umgebungen, in denen Anfragen zustandslos, vorhersehbar und einheitlich sind.
Wenn Teams LLMs einführen, ist Kong oft der erstes Werkzeug wiederverwendet um den KI-Verkehr zu verwalten — LLM-Aufrufe werden nur als ein weiterer API-Endpunkt behandelt. Das funktioniert zunächst für:
Der LLM-Verkehr führt jedoch Eigenschaften ein, die herkömmlichen APIs nicht eindeutig zugeordnet werden können.
Da die Nutzung von KI über einfache Experimente hinausgeht, werden diese Lücken zunehmend sichtbar, insbesondere in Umgebungen mit mehreren Teams oder in kostensensiblen Umgebungen.
Portschlüssel ist ein KI-natives Gateway, das speziell für Anwendungen entwickelt wurde, die auf großen Sprachmodellen basieren. Anstatt LLM-Aufrufe als generische API-Anfragen zu behandeln, führt Portkey Abstraktionen ein, die darauf abgestimmt sind, wie KI-Anwendungen tatsächlich funktionieren — Aufforderungen, Modelle, Token und Anbieter.
Im Kern fungiert Portkey als Zwischenschicht zwischen KI-Anwendungen und mehreren LLM-Anbietern. Es ermöglicht Entwicklern, zwischen Modellen zu wechseln, den Verkehr weiterzuleiten und die Nutzung zu beobachten, ohne den Anwendungscode eng mit der API eines bestimmten Anbieters zu verknüpfen.
Im Vergleich zu API-Gateways wie Kong ist Portkey LLM-bewusst. Es versteht, dass:
Dies macht Portkey zu einer guten Wahl für Teams, die LLM-gestützte Anwendungen entwickeln und diese iterieren, insbesondere in Produktionsumgebungen in der frühen oder mittleren Phase.
Da sich die Nutzung von LLM über Teams und Umgebungen hinweg ausbreitet, ergeben sich einige Einschränkungen:
Diese Einschränkungen werden wichtig, wenn KI von einer Anwendungsfunktion zu einer gemeinsame Unternehmensfähigkeit.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Während Kong und Portschlüssel können beide vor KI-Workloads sitzen, sie basieren auf sehr unterschiedlichen architektonischen Annahmen. Das Verständnis dieses Unterschieds ist entscheidend für Plattformteams, die entscheiden, wie KI über eine einzelne Anwendung hinaus skaliert werden kann.
Kong ist eine gute Wahl, wenn:
In diesem Setup arbeitet Kong als vorübergehende Verlängerung der bestehenden API-Infrastruktur.
Portkey passt gut, wenn:
Portkey glänzt im Anwendungsschicht, insbesondere für schnelllebige KI-Produktteams.
Beides Kong und Portschlüssel adressieren echte Herausforderungen im KI-Stack, aber sie tun dies auf unterschiedlichen und letztlich begrenzten Ebenen. Diese Einschränkungen werden deutlich, wenn sich KI von einer einzelnen Anwendungsfunktion zu einer gemeinsame Unternehmensfähigkeit erstreckt sich über mehrere Teams, Umgebungen und regulatorische Grenzen.
Kong wurde entwickelt, um API-Anfragen zu regeln, nicht das KI-Verhalten. Aufforderungen, Token, Modellauswahl und Agentenausführung sind für das Gateway undurchsichtig.
Portkey führt LLM-fähige Kontrollen ein, aber die Unternehmensführung bleibt weitgehend erhalten anwendungsumfangsbezogen.
KI-Teams in Unternehmen benötigen jedoch Antworten auf Fragen wie:
Weder Kong noch Portkey bieten unternehmensweite KI-Governance als erstklassige Fähigkeit.
Die KI-Kosten werden durch eine Kombination aus folgenden Faktoren bestimmt:
Kong hat keinen Einblick in diese KI-spezifischen Kostentreiber.
Portkey stellt Kennzahlen auf Token-Ebene zur Verfügung, aber die Kostenzuweisung wird immer schwieriger, da sich die Nutzung über mehrere Teams, Anwendungen und Umgebungen erstreckt.
Ohne Zuordnung auf Infrastrukturebene haben Plattform- und Finanzteams Schwierigkeiten, eine grundlegende Frage zu beantworten: wer gibt was aus und warum?
KI-Systeme für die Produktion erfordern eine strikte Trennung zwischen:
Kong wurde nicht mit Blick auf die Isolierung der KI-Umgebung entwickelt.
Portkey optimiert für Anwendungsabläufe, anstatt strenge Umgebungsgrenzen durchzusetzen.
Für Unternehmen in regulierten Branchen wird dieser Mangel an Isolation schnell zu einem Hindernis für die Implementierung.
KI-Bereitstellungen in Unternehmen müssen Anforderungen wie die folgenden erfüllen:
Diese Einschränkungen müssen durchgesetzt werden auf der Infrastrukturebene, nicht in den Anwendungscode eingebettet oder manuell von Teams bearbeitet.
Kong behandelt KI-Verkehr als generische HTTP-Anfragen.
Portkey geht von einer Cloud-First-Nutzung auf Anwendungsebene aus.
Keiner der beiden Ansätze ist konzipiert für KI-Bereitstellungen, bei denen Compliance an erster Stelle steht.
KI in der Produktion ist nicht mehr auf synchrone Prompt-Response-Aufrufe beschränkt. Zu den realen Systemen gehören:
Gateways, die sich nur auf den API-Verkehr oder das Prompt-Routing konzentrieren, regeln nicht vollständiger Lebenszyklus von KI-Workloads.
Mit zunehmender Akzeptanz von KI kommen Unternehmen zu derselben Erkenntnis: Gateways allein reichen nicht aus. Für den Betrieb von KI in der Produktion ist eine Infrastrukturebene erforderlich, die Zugriff, Bereitstellung, Beobachtbarkeit, Steuerung und Compliance. Aus diesem Grund gehen Unternehmen irgendwann über API-Gateways und LLM-Anwendungsgateways hinaus zu KI-native Infrastrukturplattformen, die für Unternehmen entwickelt wurden
Die Einschränkungen von Kong und Portschlüssel haben dieselbe Grundursache: beide wurden entwickelt, um sie zu lösen Probleme auf Gateway-Ebene, nicht Probleme mit der KI-Infrastruktur von Unternehmen.
Da KI zu einer gemeinsamen, produktionskritischen Funktion wird, benötigen Unternehmen mehr als Traffic-Routing oder schnelle Abstraktion. Sie benötigen eine Plattform, die Folgendes behandelt KI-Governance, Einsatz, Beobachtbarkeit und Sicherheit als erstklassige Infrastrukturanliegen. Das ist wo Wahre Gießerei steht auseinander.
TrueFoundry basiert auf der Idee, dass KI-Workloads wie jedes andere kritische Produktionssystem verwaltet werden sollten, jedoch mit KI-native Primitive. Anstatt nur im Anforderungspfad zu arbeiten, fungiert TrueFoundry als vereinheitlichte KI-Steuerungsebene.
Auf hohem Niveau vereint TrueFoundry:
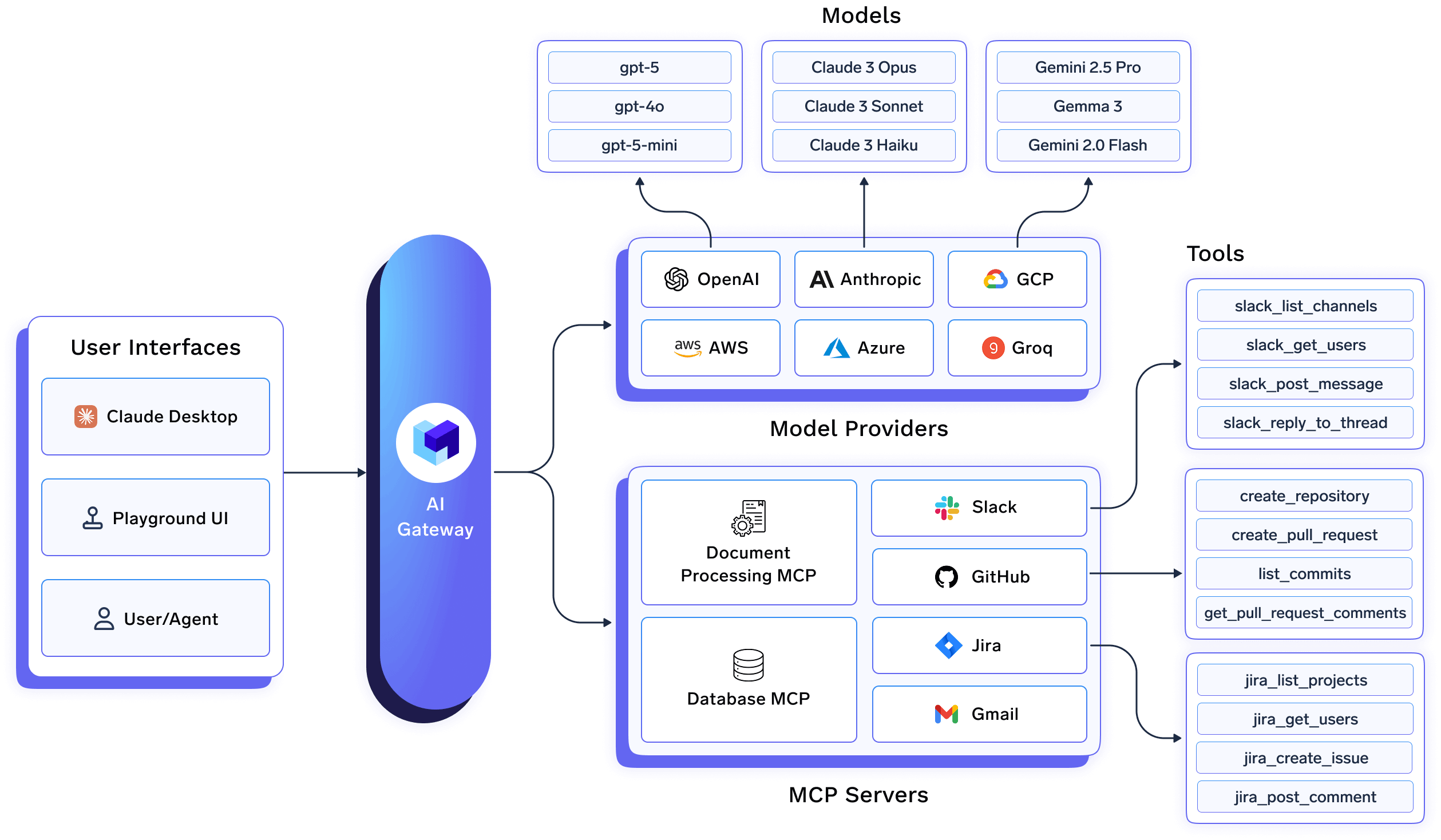
In vielen KI-Stacks wird die LLM-Nutzung als API-Integrationsproblem behandelt: Anfragen werden weitergeleitet, authentifiziert und protokolliert, aber alles, was über die Anforderungsgrenze hinausgeht, wird einzelnen Anwendungen überlassen. TrueFoundry verfolgt einen anderen Ansatz und behandelt KI-Workloads, Dienste, Jobs und Agenten als Infrastrukturobjekte mit Lebenszyklus-, Eigentums- und Betriebsgrenzen.
Anstatt nur zu entscheiden ob eine Anfrage sollte erlaubt sein, TrueFoundry kontrolliert wo KI-Systeme laufen, wie sie ausgeführt werden und unter welchen Einschränkungen, von der Bereitstellung bis zur Laufzeit. Diese Verlagerung vom Anforderungsrouting zur Lebenszykluskontrolle ermöglicht eine konsistente Steuerung, wenn die KI-Nutzung immer weiter wächst.
Konkret zeigt sich dies in mehreren kritischen Dimensionen.
In Gateway-zentrierten Architekturen Zugriffsrichtlinien sind in der Regel in Anwendungscode, SDK-Konfiguration oder Gateway-Regeln pro Dienst eingebettet. Dies wird schnell spröde, wenn sich Teams, Dienste und Umgebungen vervielfachen.
TrueFoundry setzt die Zugriffs- und Nutzungsrichtlinien unter Arbeitsplatz- und Umgebungsebene. Modelle, Agenten und Tools sind auf Umgebungen wie Entwicklung, Staging und Produktion zugeschnitten, wobei Berechtigungen und Kontrollen einheitlich auf alle in dieser Umgebung bereitgestellten Workloads angewendet werden.
Weil Richtlinien eher an Umgebungen als an einzelne Anwendungen gebunden sind:
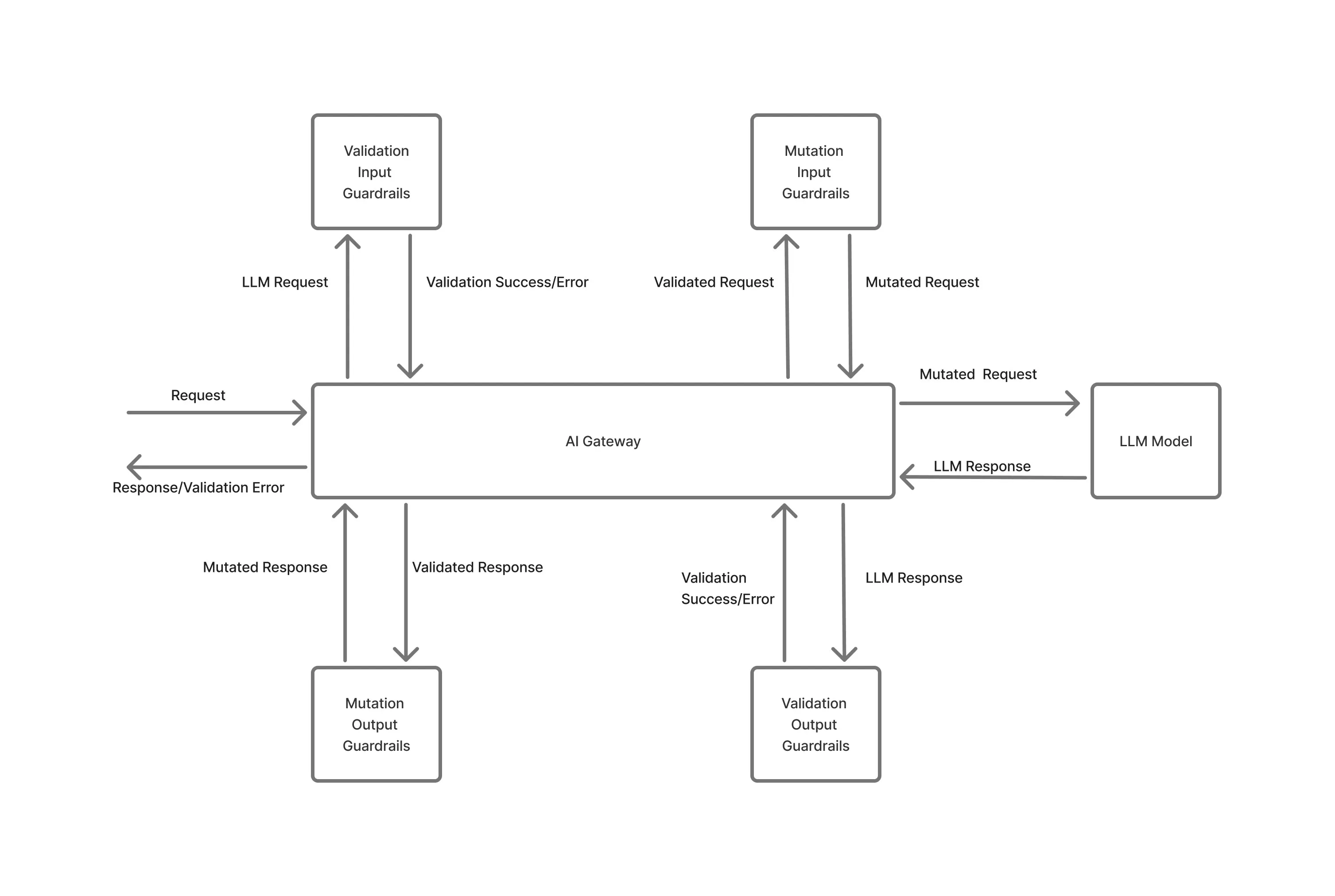
KI-Systeme scheitern in der Produktion nicht, weil eine einzelne Anforderung ungültig ist, sondern weil sich die Nutzung auf unerwartete Weise durch Parallelitätsspitzen, Wiederholungsstürme oder im Hintergrund ausgeführte Workloads in großem Umfang ansammelt.
TrueFoundry erzwingt die Verwendung Leitplanken zur Ausführungszeit, mit Einblick in das Verhalten von Workloads zur Laufzeit. Grenzwerte für Parallelität, Durchsatzbeschränkungen und Nutzungsobergrenzen werden zentral auf alle Dienste und Jobs angewendet, die die zugrunde liegenden Modelle oder Infrastrukturen gemeinsam nutzen.
Weil diese Grenzwerte auf Plattformebene durchgesetzt werden:
Dies unterscheidet sich grundlegend von clientseitigen Steuerelementen oder Steuerelementen auf SDK-Ebene, bei denen davon ausgegangen wird, dass sich Anwendungen korrekt und unabhängig verhalten.
TrueFoundry erzwingt die Isolierung bei Bereitstellungs- und Umgebungsebene, nicht nur auf Antrag Zulassung. KI-Services, Batch-Jobs und Agenten-Workflows werden als isolierte Workloads in definierten Umgebungen bereitgestellt, wobei Zugriff, Richtlinien und Ressourcen pro Umgebung begrenzt sind.
Diese Workloads werden ausgeführt als separate Bereitstellungen und Jobs mit unabhängigen Laufzeitprozessen und Fehlerdomänen, anstatt sich einen einzigen flachen Ausführungskontext hinter einem Gateway zu teilen. Als Ergebnis:
LLM-Gateways auf Anwendungsebene, die hauptsächlich im Anforderungspfad arbeiten, steuern weder die Laufzeitausführung noch den Infrastrukturstatus. Daher können sie dieses Maß an Bereitstellung und Umgebungsisolierung nicht bieten — ein Problem, das zunehmend sichtbar wird, da die KI-Workloads über Teams und Produktionsumgebungen hinweg immer größer werden.

Metriken auf Token-Ebene sind nützlich, aber unzureichend, wenn die KI-Workloads Dienste, Hintergrundjobs und Agenten-Workflows mit langer Laufzeit umfassen. In Produktionssystemen ergeben sich Kosten und Leistung aus der Interaktion zwischen:
TrueFoundry korreliert diese Signale auf Plattformebene, sodass Teams über KI-Verhalten genauso nachdenken können wie über andere Produktionssysteme —nach Umgebung, Service und Besitzer, nicht durch einzelne API-Aufrufe.
Viele KI-Bereitstellungen in Unternehmen unterliegen Einschränkungen, die Gateways auf Anwendungsebene implizit übernehmen, darunter:
Die Steuerungsebene von TrueFoundry ist so konzipiert, dass sie über diese Bereitstellungsmodelle hinweg funktioniert und sicherstellt, dass Governance, Isolierung und Beobachtbarkeit konsistent bleiben, unabhängig davon, wo die Inferenz ausgeführt wird. Daher werden Compliance-Eigenschaften wie Datengrenzen und Überprüfbarkeit als Teil der Infrastruktur selbst durchgesetzt und müssen nicht erst später durch Anwendungslogik oder Prozesskontrollen hinzugefügt werden.
Kong und Portkey lösen jeweils wichtige Probleme in unterschiedlichen Phasen der KI-Einführung. Kong erweitert vertraute API-Gateway-Muster auf den KI-Verkehr, während Portkey LLM-native Abstraktionen einführt, die es einfacher machen, KI-gestützte Anwendungen zu erstellen und zu betreiben.
Da KI jedoch zu einer gemeinsamen, produktionskritischen Funktion wird, stehen Unternehmen schnell vor Herausforderungen, die über die Weiterleitung von Anfragen oder das Promptmanagement hinausgehen. Unternehmensführung, Kostenzuweisung, Isolierung der Umgebung und Einhaltung gesetzlicher Vorschriften erfordern Kontrollen auf der Infrastrukturebene, nicht nur am Gateway.
Aus diesem Grund gehen viele Unternehmen über API- und LLM-Anwendungsgateways hinaus zu KI-nativen Infrastrukturplattformen wie Wahre Gießerei, die darauf ausgelegt sind, KI-Systeme in Teams und Umgebungen zuverlässig auszuführen, zu steuern und zu skalieren.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


