
.webp)
July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 26, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Als Moonshot AI Kimi K2 als Open Source veröffentlichte, wurde die KI-Community aufmerksam. Als sie darauf Kimi K2 Thinking folgen ließen, ein Modell, das mit bemerkenswerter Kohärenz Hunderte von Tool-Aufrufen verarbeiten konnte, begannen Praktiker, ernsthaft aufmerksam zu werden. Jetzt, mit Kimi K2.6, ist Moonshot noch weiter gegangen: ein hochmodernes Open-Source-Modell, das an der Spitze der Benchmarks für Codierung und Agenten-Aufgaben mit langem Horizont steht und mit den besten Closed-Source-Angeboten der Welt konkurriert.
Dieser Beitrag beleuchtet ausführlich, was K2.6 so bemerkenswert macht, was die Benchmark-Zahlen tatsächlich für reale Arbeitslasten bedeuten und wie Sie es ohne ein sechswöchiges Bereitstellungsprojekt einsetzen können.
Kimi K2.6 ist das multimodale Modell der nächsten Generation von Moonshot AI, verfügbar auf Hugging Face und über die Kimi API. Wie seine Vorgänger basiert es auf einer Mixture-of-Experts (MoE)-Architektur mit einem Kontextfenster von 262.144 Tokens. Doch K2.6 ist mehr als eine inkrementelle Verbesserung – es stellt eine bedeutende Designverschiebung hin zu drei Aspekten dar, die die vorherige Generation inkonsistent handhabte: Codierung mit langem Horizont, codegesteuertes Design, und Agentenschwarm-Koordination.
Hier ist ein kurzes Beispiel dafür, was „langfristig“ in der Praxis bedeutet. In einer Benchmark-Demo hat K2.6 autonom ein Qwen3.5-0.8B-Modell lokal auf einem Mac bereitgestellt, die Inferenz in Zig (einer Nischen-Systemprogrammiersprache) implementiert und über 4.000+ Tool-Aufrufe und 12+ Stunden kontinuierlicher Ausführung, den Durchsatz von ~15 auf ~193 Tokens pro Sekunde verbessert (etwa 20 % schneller als LM Studio). Das ist kein Chatbot, der eine Frage beantwortet; das ist eine KI, die über einen längeren Zeitraum als leitender Performance-Ingenieur agiert.
In einer separaten Demonstration hat K2.6 in einer 13-stündigen Sitzung eine 8 Jahre alte Open-Source-Finanz-Matching-Engine überarbeitet und dabei über 1.000 gezielte Codeänderungen vorgenommen, um eine Verbesserung des mittleren Durchsatzes um 185 % und eine Steigerung des Spitzen-Durchsatzes um 133 % — ohne menschliche Anleitung nach der anfänglichen Aufgabenspezifikation.
Zahlen sind wichtig, aber der Kontext ist wichtiger. So schneidet K2.6 bei den Benchmarks ab, die für agentische Produktionssysteme am wichtigsten sind:
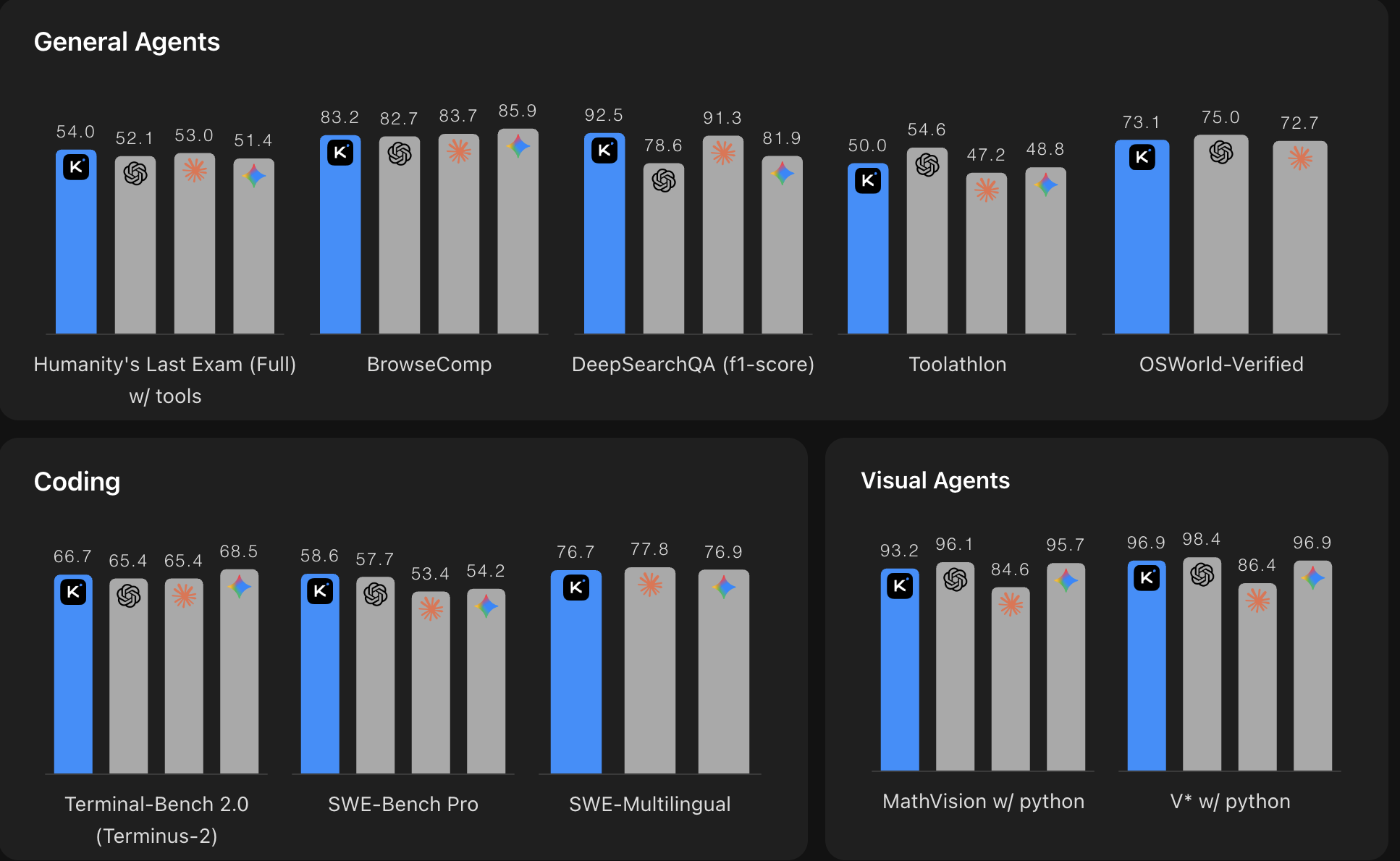
*Quelle: Moonshot AI Kimi K2.6 Benchmark-Vergleich. Höher ist besser. Die Grafik vergleicht Kimi K2.6 mit führenden Closed-Source-Modellen in den Bereichen allgemeine Agenten-, Coding- und Visual-Agent-Benchmarks.*
K2.6 ist mit den besten Closed-Source-Modellen konkurrenzfähig, darunter Claude Opus 4.6 und GPT-5.4, in praktisch jeder Hinsicht, die für agentisches Coding und Langzeitaufgaben relevant ist. Und das als Open-Weight-Modell zu 0,74 $ / 3,50 $ pro Million Input-/Output-Tokens. Das ist ein Bruchteil der Kosten vergleichbarer proprietärer Alternativen.
Der Sprung gegenüber Kimi K2.5 ist ebenfalls signifikant: eine Verbesserung von fast 80 % bei Toolathlon, ~8 Prozentpunkte bei BrowseComp und SWE-Bench Pro. Das sind keine marginalen Gewinne.
Unternehmenskunden, die frühzeitig Zugang hatten, berichten von ähnlich überzeugenden Ergebnissen: Der CTO von Augmentcode lobte die „chirurgische Präzision“ von K2.6 bei großen Codebasen; Vercel verzeichnete eine Verbesserung von über 50 % bei ihrem Next.js-Benchmark im Vergleich zu K2.5; und CodeBuddy maß eine 12%ige Verbesserung der Genauigkeit der Codegenerierung, wobei die Erfolgsrate der Tool-Aufrufe 96,6 % erreichte.
Die meisten LLMs eignen sich gut für die einmalige Codegenerierung. K2.6 ist für Aufgaben konzipiert, die Stunden dauern: Refactoring mehrerer Dateien, sprachübergreifende Optimierungen, Verbesserungen der Build-Pipeline und iterative Debugging-Schleifen, bei denen das Modell die Compiler-Ausgabe lesen, seine Hypothese anpassen und es erneut versuchen muss.
Das Modell zeigt eine starke Generalisierung über Python, Rust, Go und sogar seltene Sprachen wie Zig hinweg, was bemerkenswert ist, da es darauf hindeutet, dass das Modell Programmierkonzepte tief genug verinnerlicht hat, um sie zu übertragen, anstatt nur Muster aus Trainingsdaten auswendig zu lernen.
K2.6 kann aus einer einzigen natürlichsprachlichen Anweisung ein vollständiges, produktionsreifes Frontend erstellen – nicht nur ein statisches Mockup, sondern eines mit interaktiven Elementen, Scroll-Animationen und datenbankgestützter Authentifizierung. Auf Moonshots internem Kimi Design Bench übertrifft K2.6 Google AI Studio bei visuellen Eingabeaufgaben, der Erstellung von Landingpages, der Full-Stack-Anwendungsentwicklung und der allgemeinen kreativen Programmierung.
Für Teams, die KI-gestützte Entwicklungsworkflows aufbauen, bedeutet dies im Wesentlichen ein einziges Modell, das den gesamten Stack abdeckt: Architektur, Logik, Benutzeroberfläche und Bereitstellungsgerüst.
K2.6 führt eine wesentliche architektonische Erweiterung des Agenten-Schwarm-Systems ein, das erstmals in K2.5 vorgestellt wurde. Der Schwarm skaliert nun auf 300 Sub-Agenten, die gleichzeitig 4.000 koordinierte Schritte ausführen, gegenüber 100 Agenten und 1.500 Schritten in K2.5. Das ist nicht nur eine Skalierungsverbesserung; es ist eine qualitative Veränderung dessen, welche Arten von Aufgaben machbar werden.
Eine Aufgabe, die zuvor einen Menschen zur Orchestrierung erforderte (zum Beispiel: „100 Halbleiterunternehmen recherchieren, fünf quantitative Anlagestrategien entwickeln und eine Präsentation im McKinsey-Stil erstellen“), kann nun als einzelne Anweisung an K2.6 erteilt und als vollständiges Ergebnis zurückgegeben werden.
Hier endet die Diskussion meistens: Ein Team liest die Benchmark-Zahlen, ist begeistert und verbringt dann die nächsten drei Wochen damit, herauszufinden, wie das Modell tatsächlich zuverlässig bereitgestellt werden kann.
K2.6 ist ein großes MoE-Modell. Sein 262K Kontextfenster bedeutet, dass der Speicherbedarf erheblich ist. Agentenbasierte Workloads erzeugen – per Definition – stark variable Traffic-Muster: stundenlang ruhig, dann plötzlich Hunderte paralleler Sub-Agenten, die alle gleichzeitig Anfragen stellen. Naive Bereitstellungsstrategien brechen unter dieser Last zusammen.
Dies ist das Infrastrukturproblem, das TrueFoundry AI Gateway lösen soll.
Anstatt Ihren eigenen GPU-Cluster bereitzustellen, einen benutzerdefinierten Load Balancer zu erstellen und Inferenzparameter manuell abzustimmen, ermöglicht TrueFoundry es Ihnen, Ihre Anwendung auf einen einzigen Endpunkt zu richten – und erledigt den Rest. Das Gateway leitet Anfragen intelligent über verschiedene Anbieter hinweg, verwaltet die Parallelität für Burst-Workloads (wie ein Schwarm, der 300 gleichzeitige Sub-Agenten abfeuert) und bietet Ihnen die Observability-Tools – Traces, Latenz-Histogramme, Token-Nutzung pro Team – die Sie sonst selbst entwickeln müssten.
Bei unseren internen Tests mit Kimi K2 Thinking bewältigte das Gateway von TrueFoundry über 350 RPS auf einer einzelnen vCPU mit einer Latenz von ca. 10 ms. Für agentenbasierte Workloads, bei denen eine einzelne, vom Benutzer initiierte Aufgabe sich in Dutzende oder Hunderte von API-Aufrufen verzweigen kann, ist dieser Spielraum entscheidend.
Es gibt auch eine praktische organisatorische Dimension. Unternehmensteams, die K2.6 einsetzen, haben typischerweise mehrere Teams – Data Science, Produktentwicklung, Plattform – die alle mit demselben Modell experimentieren möchten. Das Gateway bietet eine zentrale Steuerungsebene für Ratenbegrenzung, Kostenzuordnung und Zugriffsrichtlinien, ohne dass jedes Team ein eigenes API-Schlüsselmanagement benötigt.
Der schnellste Weg, K2.6 in einer verwalteten, produktionsbereiten Umgebung zu betreiben:
1. Über das TrueFoundry AI Gateway (API)
Wenn Sie bereits das OpenAI SDK oder einen OpenAI-kompatiblen Client verwenden, können Sie mit einer einzigen Änderung des Modell-Strings zu K2.6 wechseln:
from openai import OpenAI
client = OpenAI(
api_key="<your-truefoundry-api-key>",
base_url="https://llm-gateway.truefoundry.com/api/inference/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.6",
messages=[
{"role": "user", "content": "Refactor this codebase for better performance..."}
]
)Das Gateway übernimmt transparent die Anbieterauswahl, das Fallback-Routing und die Ratenbegrenzung.
2. Für agentische Workloads
Die Tool-Calling-Schnittstelle von K2.6 folgt dem Standard-OpenAI-Funktionsaufruf-Schema. Für langfristige Aufgaben sollten Sie:
- `max_tokens` großzügig einstellen (das Modell kann ein großes Generierungsbudget produktiv nutzen)
- Streaming aktivieren, um inkrementelle Ausgaben von langen Tool-Ketten zu erhalten
- Das Tracing-Dashboard von TrueFoundry verwenden, um zu visualisieren, welche Tool-Aufrufe Zeit in Anspruch nehmen und wo Kontext verbraucht wird
3. Für die Orchestrierung von Agenten-Schwärmen
Wenn Sie Multi-Agenten-Systeme entwickeln, bietet das Gateway von TrueFoundry Metadaten auf Anfrageebene – Sie können die Anfragen jedes Sub-Agenten mit einer übergeordneten Aufgaben-ID versehen und anschließend den vollständigen Ausführungs-Trace rekonstruieren. Dies ist von unschätzbarem Wert für das Debugging von Schwarmverhalten und um zu verstehen, wo Parallelität hilft (oder schadet).
Entwicklungsteams, die agentische Codierungstools entwickeln: K2.6 ist das erste Open-Source-Modell, das ernsthaft mit GPT-5.4 und Claude Opus auf SWE-Bench Pro konkurriert. Wenn Sie auf ein Open-Weight-Modell gewartet haben, das produktionsreife Codebasis-Aufgaben bewältigen kann, ist dies das Richtige.
ML-Plattformteams, die den Modellzugriff verwalten: Ein Unternehmen, das K2.6 neben anderen Frontier-Modellen evaluiert, profitiert davon, alles über ein einziges Gateway laufen zu lassen. Der Modellkatalog-Ansatz von TrueFoundry ermöglicht es Ihnen, K2.6 gegen Claude oder GPT-5.4 auf Ihren tatsächlichen Workloads A/B-Tests zu unterziehen, mit gleichzeitiger Kosten- und Latenzverfolgung.
Teams mit Anforderungen an die Datenresidenz: Die offenen Gewichte von K2.6 bedeuten, dass es auf einer von Ihnen kontrollierten Infrastruktur bereitgestellt werden kann. Die Bereitstellungsplattform von TrueFoundry übernimmt die Orchestrierung, sodass Sie eine unternehmensweite Modell-Governance erhalten, ohne dass ein proprietärer Anbieter in Ihrem Inferenzpfad sitzt.
Jeder, der es leid ist, Preise für Closed-Source-Modelle zu zahlen: Bei 0,74 $ / 3,50 $ pro Million Tokens und einer Benchmark-Leistung, die proprietäre Alternativen bei den meisten agentischen Aufgaben erreicht oder übertrifft, ist das Kosten-Leistungs-Argument für K2.6 schwer zu ignorieren.
Kimi K2.6 ist ein echtes Spitzenmodell. Nicht nur „gut für Open Source“ – sondern wirklich konkurrenzfähig mit den besten Modellen der Welt bei den Benchmarks, die für echte Ingenieurarbeit relevant sind. Seine langfristige Zuverlässigkeit, die Agenten-Schwarm-Architektur und die wettbewerbsfähige Preisgestaltung machen es zum überzeugendsten Open-Weight-Modell, das heute für agentenbasierte Produktionssysteme verfügbar ist.
Die praktische Frage ist nicht, ob sich der Einsatz von K2.6 lohnt. Das tut es. Die Frage ist, wie schnell und zuverlässig Sie es in die Produktion bringen können. Das TrueFoundry AI Gateway beantwortet diese Frage – so verbringt Ihr Team seine Zeit damit, mit dem Modell zu entwickeln, anstatt die Infrastruktur darum herum aufzubauen.
Jetzt ausprobieren: Greifen Sie auf Kimi K2.6 über das [TrueFoundry AI Gateway](https://www.truefoundry.com/ai-gateway) zu oder [buchen Sie eine Demo](https://www.truefoundry.com/book-demo), um zu sehen, wie es in den Workflow Ihres Teams passt.
*Alle Benchmark-Zahlen stammen aus dem offiziellen technischen Blog von Kimi K2.6 und verifizierten Drittanbieter-Evaluierungen auf OpenRouter. Die Leistungsdaten der Infrastruktur stammen aus internen Tests von TrueFoundry.*
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




