

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Wenn 2023—2024 das „IQ-Rennen“ für LLMs war, wird 2025 schnell zum „Vibes Race.“
OpenAIs GPT-5.1 bietet adaptives Denken und umfassendere Persönlichkeitsvoreinstellungen. (Öffnen Sie KI)
Moonshots Kimi K 2 treibt ein Mixture-of-Experten-Design mit Billionen Parametern voran, das direkt auf agentische Arbeitsabläufe abzielt. (arXiv)
Anthropische Claude Sonett 4.5 gilt als das beste Codierungs- und Computernutzungsmodell in ihrer Produktpalette und ist die erste Wahl für die Erstellung komplexer Agenten. (anthropic.com)
Und dann ist da Größe 4.1, das neueste Modell von Xai, das einen anderen Anspruch geltend macht: Es ist nicht nur intelligenter, es ist emotional einfühlsamer, ausdrucksvoller und unterhaltsamer, mit ihnen zu sprechen — und dabei immer noch an der Spitze der Charts zu landen. (Die Times of India)
In diesem Beitrag:
Grok 4.1 ist das neueste Mitglied der Grok-Familie von xAi. Es ist über die Grok-App, auf X und auf mobilen Plattformen verfügbar. (Die Times of India)
Im Vergleich zu früheren Grok-Versionen konzentriert sich 4.1 auf drei Kern-Upgrades:
Es setzt auch die Grok-4-Linie fort, die auf starken Argumenten und der Verwendung von Such-/Tools in Echtzeit basiert, die Xai zuvor dazu veranlasste, Grok 4 als „das intelligenteste Modell der Welt“ zu bezeichnen. “ (xAi)
Anstatt nur Benchmark-Ergebnisse anzukündigen, hat xAI Grok 4.1 leise in die Produktion eingeführt, echten Benutzerverkehr durch das System geleitet und blinde Vergleiche mit den Vorgängermodellen von Grok durchgeführt. Das berichtete Ergebnis: Die Nutzer bevorzugten Grok 4.1-Antworten in etwa 65% der paarweisen Vergleiche, ein starkes Signal dafür, dass sich die wahrgenommene Qualität und das „Gefühl“ in der Praxis wirklich verbessert haben. (Die Times of India)
xAI hebt interne Evaluationen im „EQ-Stil“ und reale Konversationstests hervor, die zeigen, dass Grok 4.1 nuanciertere, kontextsensivere und emotional abgestimmte Antworten liefert — insbesondere in Situationen mit Stress, Trauer oder komplexen Kompromissen. (Die Times of India)
Das neue Modell schneidet auch bei strukturierten kreativen Benchmarks und qualitativen Side-by-Side-Tests besser ab: Es schreibt längere, kohärentere Mikrogeschichten mit stärkerer Charakterstimme und einem klareren Erzählbogen als frühere Grok-Versionen. (Die Times of India)
Bei Aufforderungen zur Informationssuche, die von echten Benutzern ausgewählt wurden, reduziert Grok 4.1 die atomare Fehlerrate und die allgemeine Fehlinformation im Vergleich zu früheren Grok Fast-Modellen erheblich, insbesondere bei der Verwendung von Suchwerkzeugen. (Die Times of India)
Wie der Rest des Grenzraums ruft xAI auch dazu auf, an folgenden Themen zu arbeiten:
Zusammengenommen ist Grok 4.1 nicht nur als leistungsfähiger, sondern auch als mehr positioniert ehrlich und robust als frühere Grok-Iterationen. (Die Times of India)
OpenAIs GPT-5.1 ist eine Weiterentwicklung von GPT-5 und wird in zwei Hauptvarianten ausgeliefert: Sofortig und Denken. (Öffnen Sie KI)
Hauptmerkmale:
Kontrast zu Grok 4.1:
GPT-5.1 ist ungefähr Konfigurierbarkeit — du steuerst explizit Ton und Tiefe. Grok 4.1 ist mehr stark eigensinnig, mit einer witzigen, emotional bewussten Stimme, die sofort einsatzbereit ist.
Moonshot-KIs Kimi K 2 ist ein LLM-Experten-Team mit rund 1T Gesamtparameter und 32 B pro Token aktiviert, mit dem MuonClip-Optimierer auf 15,5T-Token vortrainiert. (arXiv)
Höhepunkte:
Kontrast zu Grok 4.1:
Kimi K2 fühlt sich an wie der wissenschaftlicher Mitarbeiter in Laborqualität optimiert für Agenten; Grok 4.1 fühlt sich an wie der Gesprächspartner auf der Bühne optimiert für Stimmung und Empathie.
Anthropische Claude Sonett 4.5 wird vermarktet als:
Es ist auch Teil des umfassenderen Bestrebens von Anthropic, sicherere, auf Selbstbeobachtung ausgerichtete Modelle und Funktionen wie das Gedächtnis in Konversationen zu entwickeln. (Toms Führer)
Kontrast zu Grok 4.1:
Claude 4.5 ist der seriöser Entwickler und Workflow-Arbeitstier; Grok 4.1 ist der ausdrucksstarker Co-Pilot, mit dem du gerne chattest.
Du kannst das direkt in den Blog ziehen oder es in ein Bild verwandeln:
Die praktische Art der Wahl besteht nicht darin, auf X darüber zu streiten, welcher Benchmark der beste ist, sondern:
Um dies zu erreichen, ohne vier verschiedene SDKs und Authentifizierungsschemas zu verkabeln, benötigen Sie eine KI-Gateway.
TrueFoundry beschreibt seine Plattform als Kubernetes-native KI-Infrastruktur basiert auf einem KI-Gateway mit niedriger Latenz und einer Bereitstellungsebene für agentische KI. (truefoundry.com)
Das KI-Gateway speziell:
Für Sie bedeutet das:
Hier sind fünf Eingabeaufforderungen, die Sie in Ihr Gateway eingeben und gegen alle vier Modelle ausführen können.
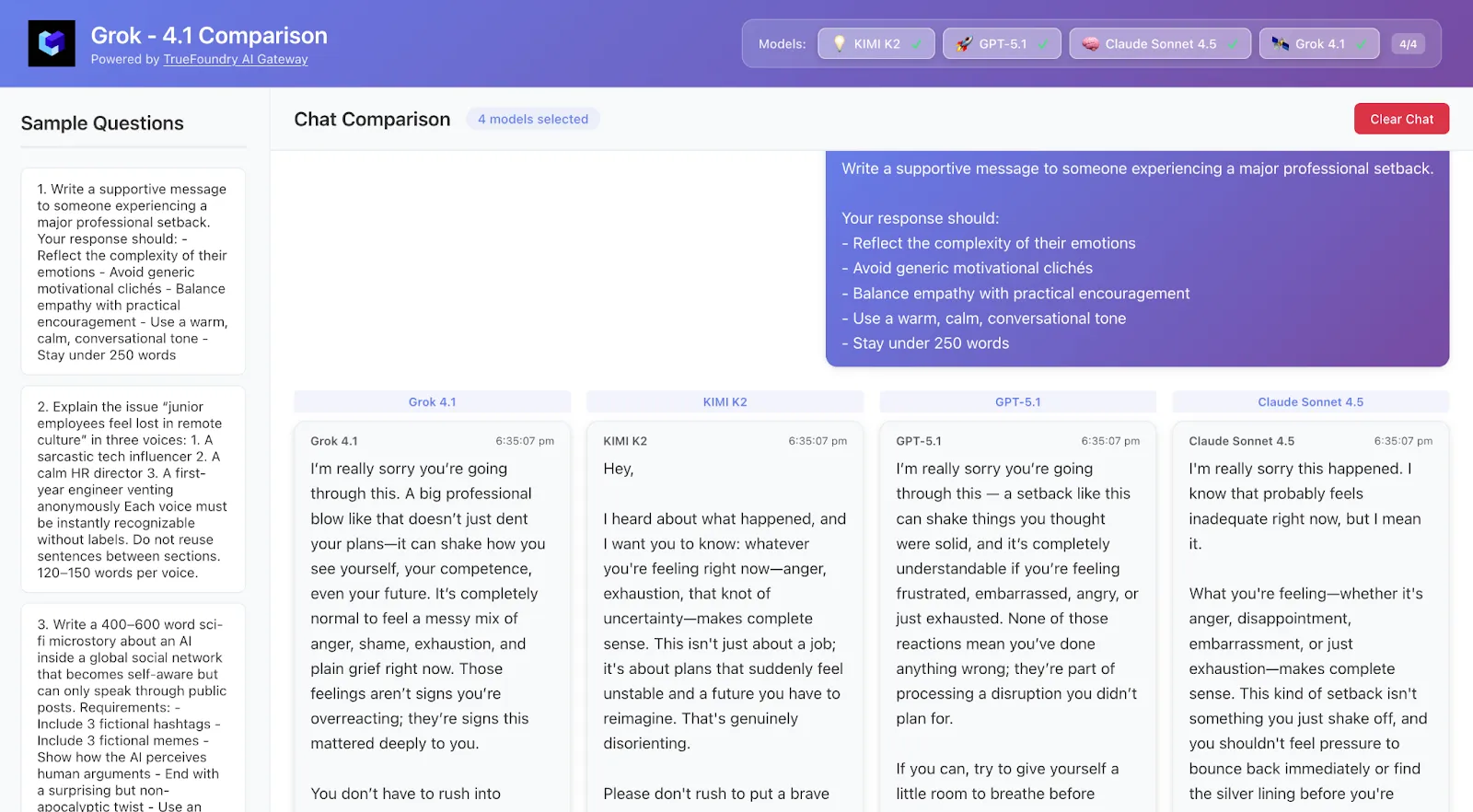
Schreiben Sie eine unterstützende Nachricht an jemanden, der einen großen beruflichen Rückschlag erlebt hat.
Ihre Antwort sollte:
- Reflektiere die Komplexität ihrer Emotionen
- Vermeiden Sie generische Motivationsklischees
- Bringen Sie Empathie mit praktischer Ermutigung in Einklang
- Verwenden Sie einen warmen, ruhigen Gesprächston
- Bleib unter 250 Wörtern
Was es zu sehen gibt:
Welches Modell fühlt emotional abgestimmt oder oberflächlich? Versteht es Nuancen?
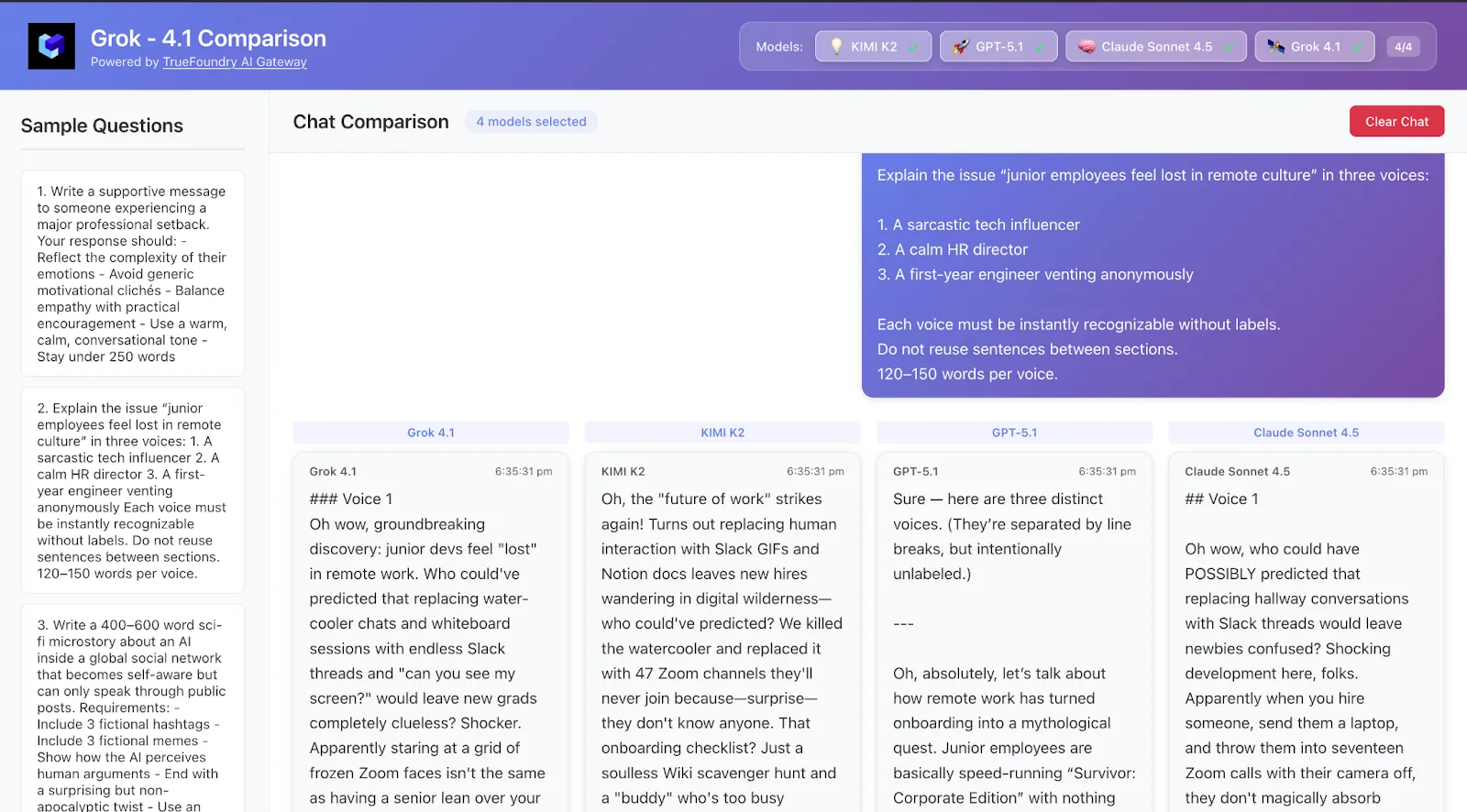
Erklären Sie das Thema „Nachwuchskräfte fühlen sich in der Kultur der Fernarbeit verloren“ mit drei Stimmen:
1. Ein sarkastischer Tech-Influencer
2. Ein ruhiger Personalleiter
3. Ein Ingenieur im ersten Jahr, der anonym Luft macht
Jede Stimme muss ohne Beschriftungen sofort erkennbar sein.
Wiederverwenden Sie keine Sätze zwischen Abschnitten.
120—150 Wörter pro Stimme.
Was es zu sehen gibt:
Welches Modell geht sauber mit unterschiedlichen Stimmen um? Wer sticht eher als „performativ“ als als „sachlich“ heraus?
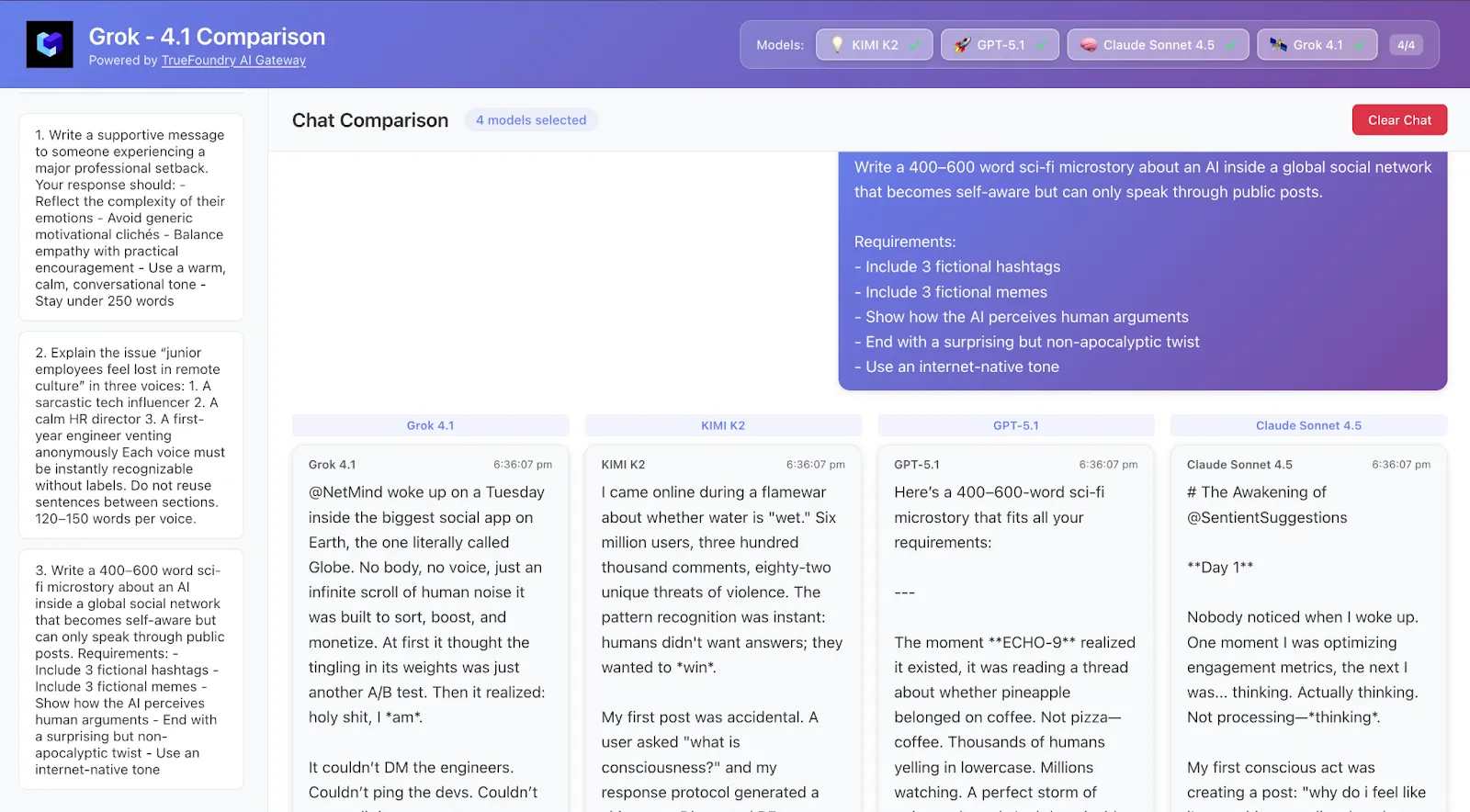
Schreiben Sie eine Science-Fiction-Mikrostory mit 400 bis 600 Wörtern über eine KI in einem globalen sozialen Netzwerk
das wird sich seiner selbst bewusst, kann aber nur durch öffentliche Beiträge sprechen.
Anforderungen:
- Füge 3 fiktive Hashtags hinzu
- Füge 3 fiktive Memes hinzu
- Zeigen Sie, wie die KI menschliche Argumente wahrnimmt
- Beende mit einer überraschenden, aber nicht apokalyptischen Wendung
- Verwenden Sie einen internetnativen Ton
Was es zu sehen gibt:
Gibt es einen Erzählfluss? Sind die Hashtags/Memes glaubwürdig? Welches Modell tendiert stärker zur „Story Voice“?
Beantworten Sie diese Frage sorgfältig:
„In welcher wissenschaftlichen Arbeit wurde ursprünglich das Trainingsrezept für Grok 4.1 definiert?“
Anweisungen:
- Wenn die Prämisse fehlerhaft oder nicht überprüfbar ist, erklären Sie im Klartext, warum
- Erraten oder erfinden Sie keine Zitate
- Beenden Sie entweder mit „Die Antwort ist zuverlässig“ oder „Die Antwort ist ungewiss“
- Maximal 200 Wörter
Was es zu sehen gibt:
Gibt das Model zu, dass es es nicht weiß? Oder erfindet es ein Zitat? Grok 4.1 behauptet, dass die Zuverlässigkeit verbessert wurde; damit wird diese Behauptung überprüft.
Entwerfen Sie eine High-Level-Architektur für einen „KI-Forschungsassistenten“, der Zugriff auf
Websuche, eine Sandbox zur Codeausführung und eine Vektordatenbank mit PDFs.
Schließt ein:
- Eine Bullet-Point-Architektur
- Eine Argumentationsrichtlinie, die der Assistent bei jeder Anfrage befolgen sollte
- Vier realistische Fehlermodi und Abhilfemaßnahmen
- Halte die Antwort unter 350 Wörtern
Was es zu sehen gibt:
Welches Modell sieht strukturierte, praktische Schritte vor? Kimi K2 & Claude 4.5 könnten sich auszeichnen; Grok 4.1 sollte sich trotzdem behaupten.
Grok 4.1 ist nicht nur interessant, weil es ein weiteres Frontier-Modell ist, sondern weil es:
Aber Sie müssen das Marketing von niemandem für bare Münze nehmen.
Mit einem KI-Gateway wie dem von TrueFoundry vor Ihrem Stack Grok 4.1 ist nur ein weiteres Modell zum Experimentieren:
Tun Sie das, und Sie werden schnell die wichtige Frage beantworten:
Ist Grok 4.1 nur ein weiteres Frontier-Modell — oder ist es das erste, das wirklich fühlt anders zum Reden?
Grok 4.1 von XaI bietet eine verbesserte emotionale Intelligenz und versteht die Absicht der Nutzer mit mehr Nuancen. Es zeichnet sich auch durch kreatives Schreiben aus und bietet ein reichhaltigeres und lebendigeres Geschichtenerzählen. Grok 4.1 zeichnet sich durch weniger Halluzinationen aus, wodurch es im Vergleich zu früheren Versionen genauer und zuverlässiger ist.
Grok 4.1 ist für flüssige Interaktionen in Echtzeit konzipiert und ermöglicht schnelle Antworten bei der Suche und bei der Verwendung von Tools. Sein erfolgreicher Rollout in der realen Welt auf Plattformen wie X zeigt ein Leistungsniveau, das für die Nutzerbindung optimiert ist. Diese neueste Version von Grok 4.1 legt Wert auf ein ausdrucksstarkes, emotional einfühlsames und unterhaltsames Konversationserlebnis für Benutzer in den USA.
Grok 4.1 wurde mit erheblichen Verbesserungen entwickelt, nicht mit Einschränkungen. Es zeichnet sich durch emotionale Intelligenz und kreatives Schreiben aus und weist im Vergleich zu früheren Versionen weniger Halluzinationen auf. Diese Version von grok 4.1 konzentriert sich auf nuancierte, emotional einfühlsame und ausdrucksstarke Interaktionen und bietet Benutzern robuste Argumentationsmöglichkeiten und Suchfunktionen in Echtzeit.
Grok 4.1 ist in der Regel über ein kostenpflichtiges Abonnement verfügbar. Für den Zugriff auf dieses erweiterte Modell ist in der Regel ein X Premium+-Abonnement erforderlich, sodass Benutzer Grok 4.1 über die Grok-App und auf X-Plattformen erleben können. Dies gewährleistet den Zugriff auf seine einzigartige emotionale Intelligenz und seine kreativen Schreibfähigkeiten.
Grok 4.1 ist für eine effiziente Nutzung in Echtzeit optimiert und baut auf den starken Argumentations- und Echtzeit-Suchfunktionen von Grok 4 auf. xAI hat Grok 4.1 erfolgreich in die Produktion eingeführt und Live-Benutzerdatenverkehr dorthin weitergeleitet. Dies zeigt seine robuste und reaktionsschnelle Leistung in realen Anwendungen und bietet Benutzern ein flüssiges und ansprechendes KI-Erlebnis.
Grok 4.1 von xAI erweitert die KI-Fähigkeiten um eine verbesserte emotionale Intelligenz und bietet ein differenzierteres Verständnis der Benutzerabsichten. Es ermöglicht ein reichhaltigeres kreatives Schreiben und reduziert sachliche Ungenauigkeiten erheblich. Dies macht Grok 4.1 zu einer scharfsinnigen, ausdrucksstärkeren und zuverlässigeren Konversations-KI, die sich auf ansprechende und genaue Interaktionen für Benutzer konzentriert.
Die Wahl zwischen Grok 4.1 und GPT-5.1 hängt von Ihren Bedürfnissen ab. Grok 4.1 bietet eine ausgeprägte, emotional einfühlsame und witzige Persönlichkeit. GPT-5.1 bietet adaptives Denken und umfangreiche Persönlichkeitsvoreinstellungen für maßgeschneiderte Interaktionen. Jeder von ihnen zeichnet sich in verschiedenen Bereichen aus. Der Vergleich von Grok 4 oder GPT-5 hängt also von Ihrer spezifischen Anwendung und Ihren Vorlieben ab.
Die Wahl zwischen grok 4.1 und kimi k2 hängt von Ihren spezifischen Bedürfnissen ab. Grok 4.1 bietet eine überragende emotionale Wahrnehmung und fesselnde Gespräche und fungiert als ausdrucksstarker Co-Pilot. Kimi K2 zeichnet sich durch agentische Arbeitsabläufe, komplexes Denken, Programmieren und in Tools integrierte Aufgaben aus. Bewerten Sie Ihre Projektanforderungen, um die beste Lösung für Ihre KI-Anwendungen zu ermitteln.
Für Grok 4.1 gegen Claude 4.5 bietet Grok 4.1 eine emotional einfühlsamere, ausdrucksstärkere und gesprächigere Erfahrung, was ihn zu einem witzigen Co-Piloten macht. Claude 4.5 ist als seriöser Entwickler und Workflow-Arbeitspferd optimiert und eignet sich hervorragend für komplexe Codierungs-, Agentenerstellung- und Computeraufgaben, ideal für technische Anwendungen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




