
.webp)
July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 26, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Das TrueFoundry AI Gateway ist eine vereinheitlichte Ausführungsschicht für die LLM-Infrastruktur. Es übernimmt die Authentifizierung, das Routing über verschiedene Anbieter hinweg, die Ratenbegrenzung, die Durchsetzung von Richtlinien, die MCP-Tool-Aufrufverwaltung und – entscheidend für diese Integration – OpenTelemetry-konformes Tracing. Jede Anfrage über das Gateway erzeugt einen Span, der standardmäßige gen_ai.* Attribute (Modellname, Token-Anzahl, Abschlussgrund) neben TrueFoundry-spezifischen Attributen wie tfy.input, tfy.outputund tfy.span_typeenthält. Diese Spans werden nach Abschluss der Anfrage asynchron an eine NATS-Nachrichtenwarteschlange gesendet, was bedeutet, dass der Exportpfad eine laufende Anfrage niemals blockiert. Ein dedizierter OTEL-Exporter-Dienst liest aus dieser Warteschlange und leitet die Spans an jeden konfigurierten OTLP-Endpunkt über HTTP oder gRPC weiter.
Pydantic Logfire ist eine Observability-Plattform, die vom Team hinter Pydantic entwickelt wurde – der Validierungsschicht, die in den SDKs von OpenAI und Anthropic sowie in den meisten heute in Produktion befindlichen KI-Frameworks integriert ist. Logfire nimmt standardmäßige OTLP-Daten auf und wendet darauf eine KI-native Darstellung an: Wenn es gen_ai.* Attribute in einem Span erkennt, wird das LLM Panel automatisch aktiviert und zeigt die vollständige Konversationshistorie, Tool-Aufrufargumente, Token-Anzahlen pro Anfrage und berechnete Kosten an – ohne jegliche SDK-Integration auf der sendenden Seite. Logfire-Abfragen sind in PostgreSQL-kompatiblem SQL geschrieben, sodass Produktionstraces sowohl für Menschen als auch für Coding Agents zugänglich sind. Es ist als verwalteter Cloud-Dienst mit regionalen Endpunkten in den USA und der EU verfügbar.
Die Integration erfolgt an einem einzigen Punkt: TrueFoundrys OTEL Config, die einen OTLP-HTTP-Endpunkt und einen Autorisierungs-Header akzeptiert. Navigieren Sie zu AI Gateway → Controls → Settings → OTEL Config und klicken Sie auf die Schaltfläche „Bearbeiten“, um das Konfigurationspanel zu öffnen.

Der OTEL-Konfigurationsbereich von TrueFoundry – der Traces-Endpunkt ist auf die EU-Ingestions-URL von Logfire eingestellt, wobei der Authorization-Header gesetzt ist.
Stellen Sie den Endpunkt auf Logfires regionale Ingestions-URL ein, wählen Sie HTTP mit Proto-Kodierung und fügen Sie den Logfire-Schreib-Token als den Authorization -Header-Wert hinzu. Derselbe Schreib-Token deckt sowohl die Traces- als auch die Metrik-Exporter ab.
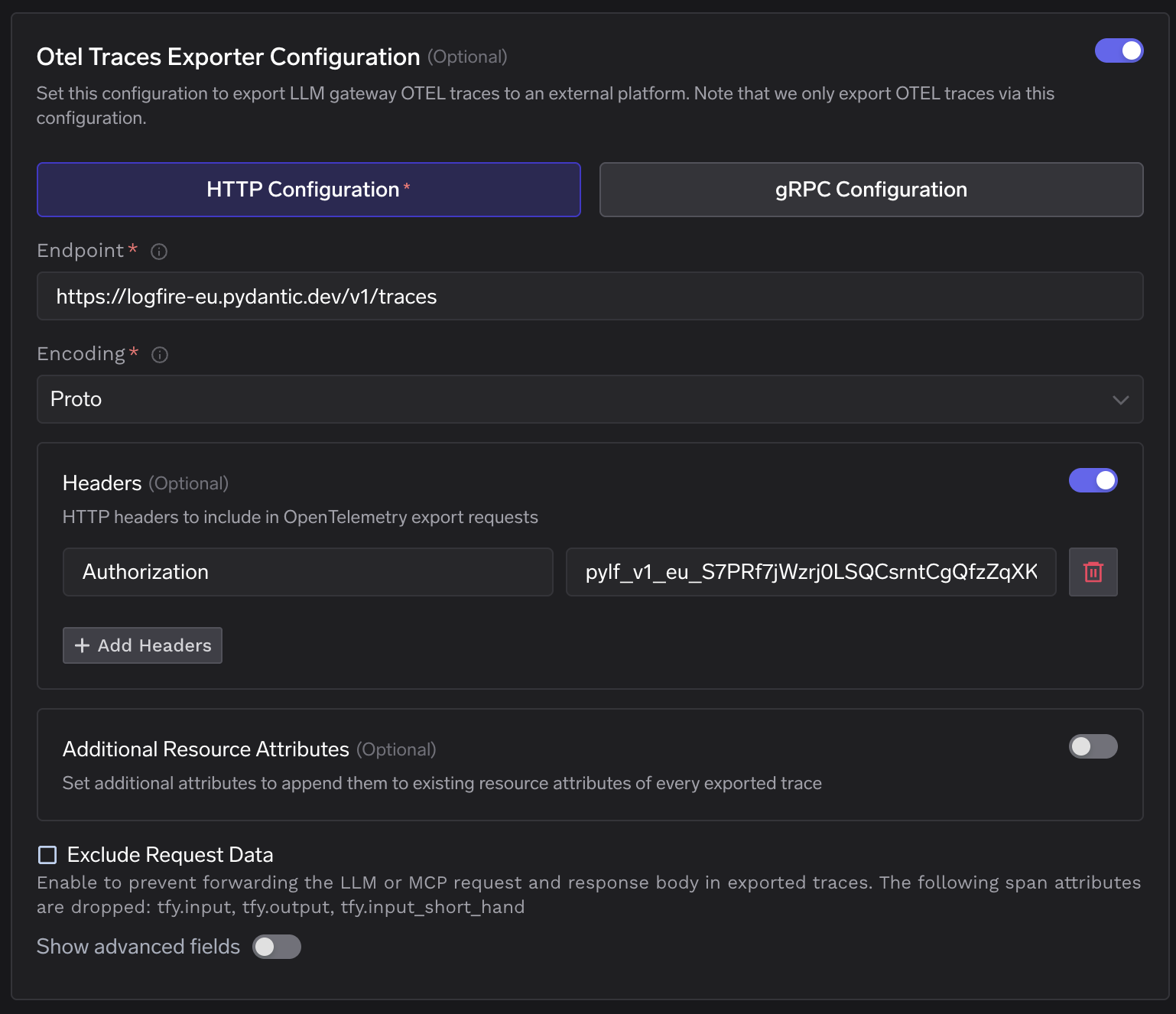
Das ausgefüllte Formular des Traces-Exporters – Endpunkt eingestellt auf https://logfire-eu.pydantic.dev/v1/traces, Kodierung Proto und der Logfire-Schreib-Token im Authorization-Header.
Es sind keine Codeänderungen in den Anwendungen erforderlich, die Anfragen über das Gateway senden. Die Tracing-Pipeline arbeitet vollständig auf der Infrastrukturebene. Eine Anfrage von einem beliebigen Team, die ein beliebiges Modell über einen beliebigen Anbieter nutzt, erzeugt einen Span, der mit dem vollständigen Kontext dessen, was am Gateway geschah, zu Logfire fließt.
Wenn eine Anfrage am Gateway ankommt, ist die Abfolge:
Nach der Konfiguration erscheinen Spans vom tfy-llm-gateway in Logfires Live-Ansicht in Echtzeit. Der tfy.span_type Attribut unterscheidet ChatCompletion, AgentResponse, und MCPGateway Spans – so können Teams nach Operationstyp filtern oder sie in SQL abfragen.

Logfires Live-Ansicht zeigt tfy-llm-gateway-Spans – AgentResponse-, ChatCompletion- und MCPGateway-Operationen erscheinen mit vollständigem Timing, Status und verschachtelten Kind-Spans.
Über einzelne Traces hinaus liefert der Metrik-Exporter aggregierte Nutzungsdaten über Anbieter, Modelle und Teams hinweg. Die Nutzungsübersicht von Logfire gruppiert diese nach Scope und Span-Namen und gibt Plattformverantwortlichen einen Überblick darüber, wohin der Traffic fließt und in welchem Umfang.
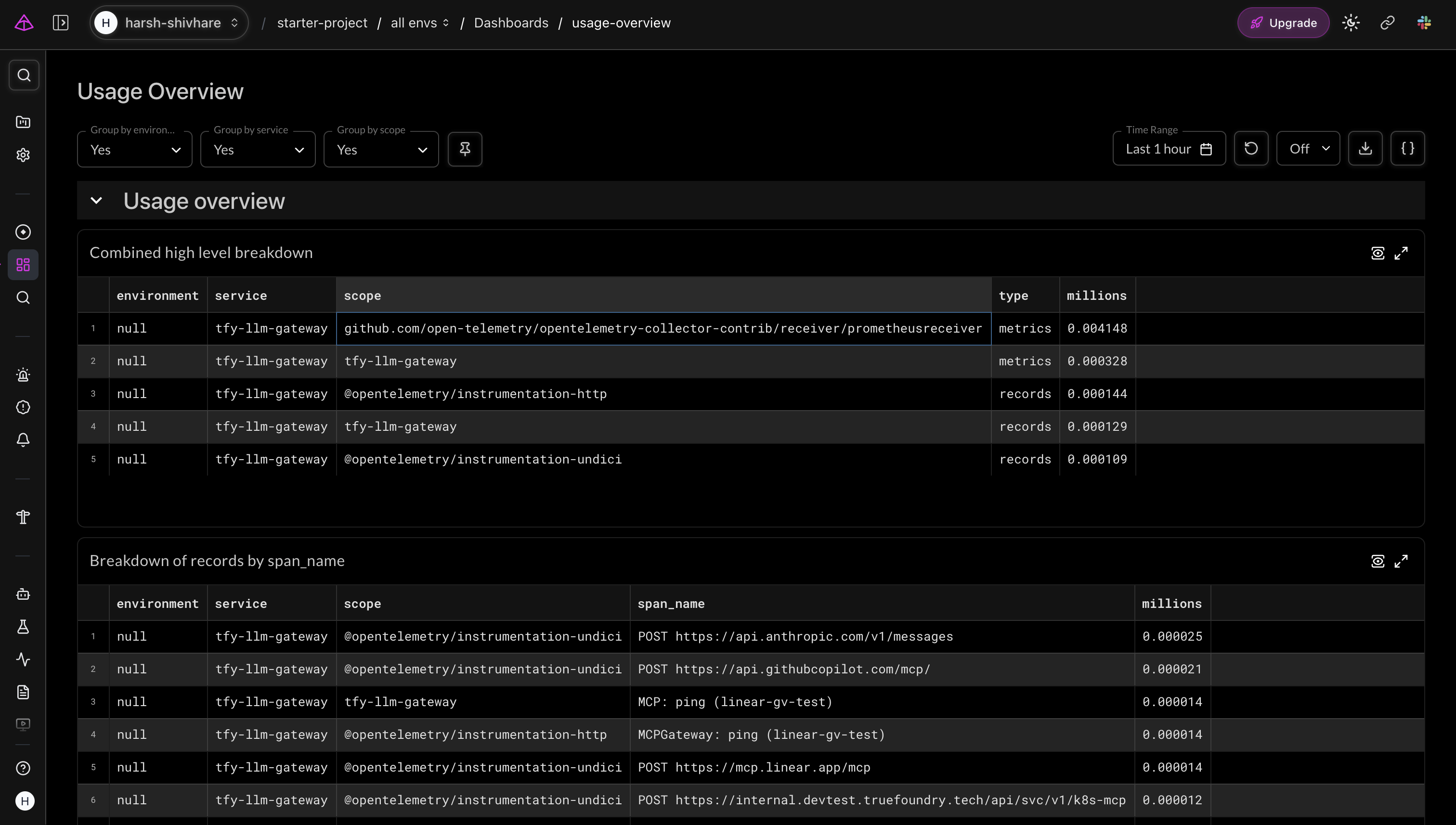
Logfires Nutzungsübersicht – Metriken vom tfy-llm-gateway, aufgeschlüsselt nach Instrumentation Scope, zeigt den ChatCompletion- und MCPGateway-Traffic über verschiedene Anbieter hinweg.
Beginnen Sie mit der Erstellung eines Schreib-Tokens in Logfire. Navigieren Sie zu Ihrem Projekt, öffnen Sie Projekteinstellungen → Schreib-Tokens, und klicken Sie auf Neuer Schreib-Token. Kopieren Sie den Token sofort – Logfire zeigt den vollständigen Wert danach nicht mehr an.

Die Logfire Schreib-Tokens-Seite – Erstellen Sie einen dedizierten Token für TrueFoundry und speichern Sie ihn sicher, bevor Sie den Dialog schließen.
Gehen Sie dann zu KI-Gateway → Steuerung → Einstellungen → OTEL-Konfiguration in TrueFoundry und konfigurieren Sie sowohl die Traces- als auch die Metrik-Exporter mit dem regionalen Endpunkt von Logfire und dem Schreib-Token. Die vollständige Endpunkt-Referenz und Konfigurationsanleitung finden Sie in der TrueFoundry-Dokumentation. Logfire bietet einen dauerhaft kostenlosen Tarif sowie eine selbst gehostete Enterprise-Option für Teams mit Anforderungen an die Datenresidenz.
Die wichtigste Erkenntnis aus dieser Integration ist architektonischer Natur: TrueFoundry und Logfire mussten sich nie direkt abstimmen. Das Gateway sendet standardmäßige OpenTelemetry-Spans mit gen_ai.*-Attributen; Logfire liest denselben Standard und aktiviert automatisch seine LLM-spezifischen Ansichten. OpenTelemetry ist der Vertrag zwischen ihnen – das Gateway steuert die Ausführung und generiert Telemetriedaten, Logfire zeichnet das Verhalten auf und visualisiert es, und der Standard verbindet sie, ohne dass eines der Systeme von den Interna des anderen abhängt.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




