

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: May 29, 2026
.webp)
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Financial Operations (FinOps) ist im Cloud-Zeitalter zu einer unverzichtbaren Disziplin geworden und bringt Engineering-, Finanz- und Geschäftsteams zusammen, um Maximieren Sie den Wert der Technologieausgaben. Wie Unternehmen es übernehmen KI und große Sprachmodelle (LLMs) Im großen Maßstab sind die FinOps-Prinzipien heute auch für KI-Workloads von entscheidender Bedeutung.
Warum? Weil KI einführt neue Kostenherausforderungen für die das traditionelle Cloud-Kostenmanagement nicht konzipiert war. In der KI-gesteuerten Welt ist die Kontrolle der Ausgaben genauso wichtig wie die Genauigkeit oder Verfügbarkeit des Modells. Hier sind einige einzigartige Kostenherausforderungen, die durch moderne KI-Initiativen entstanden sind:
FinOps — ist die Disziplin des Cloud-Finanzmanagements und ihre Kernprinzipien sind Sichtbarkeit, Rechenschaftspflicht, und Optimierung. FinOps for AI bedeutet, dieselben Prinzipien auf diese KI-spezifischen Herausforderungen anzuwenden. In den folgenden Abschnitten werden wir aufschlüsseln, wie die einzelnen FinOps-Prinzipien auf KI zutreffen und, was entscheidend ist, wie die Plattform von TrueFoundry dabei hilft, sie auf praktische und ingenieurfreundliche Weise umzusetzen.
Die erste Säule von FinOps ist Sichtbarkeit — „Man kann nicht verbessern, was man nicht misst.“ Im KI-Kontext bedeutet Sichtbarkeit, umfassende Daten zu jedem Modellaufruf zu erfassen, sodass Sie genau wissen, wohin Ihre Token- und GPU-Budgets fließen. Das ist leichter gesagt als getan, wenn die Nutzung auf mehrere Anbieter und Infrastrukturen verteilt ist. TrueFoundry behebt dieses Problem durch eine zentrale KI-Gateway dass alle KI-Anfragen durchgehen.
Einheitliches KI-Gateway: True Foundry's KI-Gateway fungiert als einziger Einstiegspunkt (Proxy) für alle KI-Modellaufrufe — unabhängig davon, ob Sie auf eine externe API wie OpenAI oder Anthropic zugreifen oder auf ein selbst gehostetes Modell, das auf Ihrer Infrastruktur läuft. Indem Sie alle Inferenzanfragen über ein Gateway weiterleiten, richten Sie ein „einzelne Glasscheibe“ zur Beobachtbarkeit und Kostenverfolgung. Das Gateway kennt modellspezifische Nuancen wie Tokenzählung und Latenz und protokolliert jede Anfrage auf strukturierte Weise. Dadurch werden blinde Flecken aufgrund der Tool-Fragmentierung beseitigt: Unabhängig davon, welches Modell oder welcher Anbieter verwendet wird, wird die Nutzung zentral verfolgt.
Granulare Protokollierung und Metadaten: Jede Anfrage, die das AI Gateway von TrueFoundry passiert, wird automatisch mit umfangreichen Metadaten zur Zuordnung protokolliert. Dazu gehören der Modellname, der Zeitstempel, die Anzahl der Eingabe-/Ausgabe-Tokens, die Latenz, der Benutzer- oder API-Schlüssel, der die Anfrage gestellt hat, und vieles mehr. Teams können jeder Anfrage auch benutzerdefinierte Tags/Metadaten hinzufügen, z. B. customer_id, application, environment oder feature_name.
Beispielsweise können Sie Anfragen mit der Produktfunktion oder dem verantwortlichen internen Team kennzeichnen. TrueFoundry macht dies einfach, indem es Entwicklern ermöglicht, einen X-TFY-METADATA-Header in API-Aufrufe einzufügen. Verwenden Sie zum Beispiel das Python-SDK:
client = OpenAI(api_key="...", base_url="https://llm-gateway.truefoundry.com/api/inference/openai")
response = client.chat.completions.create(
model="openai-main/gpt-4",
messages=[{"role": "user", "content": "Hello"}],
extra_headers={
"X-TFY-METADATA": '{"application":"booking-bot","environment":"staging","customer_id":"123456"}',
"X-TFY-LOGGING-CONFIG": '{"enabled": true}'
}
)
In diesem Snippet wird die Anfrage mit einem Anwendungsnamen, einer Umgebung und einer Kunden-ID als Metadaten gekennzeichnet. Alle Werte sind Zeichenfolgen (maximal 128 Zeichen), und Sie können so viele Felder wie nötig einschließen. Diese Tags werden zusammen mit der Anfrage durch das Gateway übertragen und in Protokollen und Metriken aufgezeichnet.
Erfassung von Metriken in Echtzeit: Das AI Gateway protokolliert nicht nur Rohdaten, sondern gibt auch strukturierte Metriken zur Überwachung aus. Für jede Anfrage verfolgt TrueFoundry Metriken wie die Anzahl der Eingabe-Tokens, Ausgabetokens und geschätzte Kosten dieser Anfrage. Diese Metriken sind mit Dimensionen wie Modellname, Benutzername (oder Dienst) und allen benutzerdefinierten Metadaten-Tags, die Sie als Labels aktiviert haben, beschriftet.
Zum Beispiel ist llm_gateway_request_total_cost eine Zählermetrik, die die Kosten der verwendeten Token akkumuliert, gekennzeichnet nach Modell, Benutzer und benutzerdefinierten Metadaten wie customer_id. Das bedeutet, dass Sie die Kosten in Ihren Überwachungstools sofort nach den Kategorien aufschlüsseln können, die für Ihr Unternehmen wichtig sind (Team, Kunde, Funktion usw.).
Integration mit Monitoring-Dashboards: Die Observability von TrueFoundry ist so konzipiert, dass sie in Ihren bestehenden Monitoring-Stack integriert werden kann. Das Gateway stellt einen /metrics-Endpunkt mit Prometheus-kompatiblen Metriken zur Verfügung und kann auch Metriken über OpenTelemetry übertragen. Mit ein paar Konfigurationseinstellungen können Sie das Gateway veranlassen, Metriken in Echtzeit an Ihr Prometheus- oder Datadog-Backend zu veröffentlichen. Nach der Erfassung können diese Metriken auf Grafana-Dashboards oder einer beliebigen Analyseplattform, die Ihr Unternehmen verwendet, visualisiert werden.
Tatsächlich bietet TrueFoundry ein vorgefertigtes Grafana-Dashboard-JSON für AI Gateway-Metriken, das Ansichten pro Modell, pro Benutzer und pro Konfigurationsregel abdeckt.
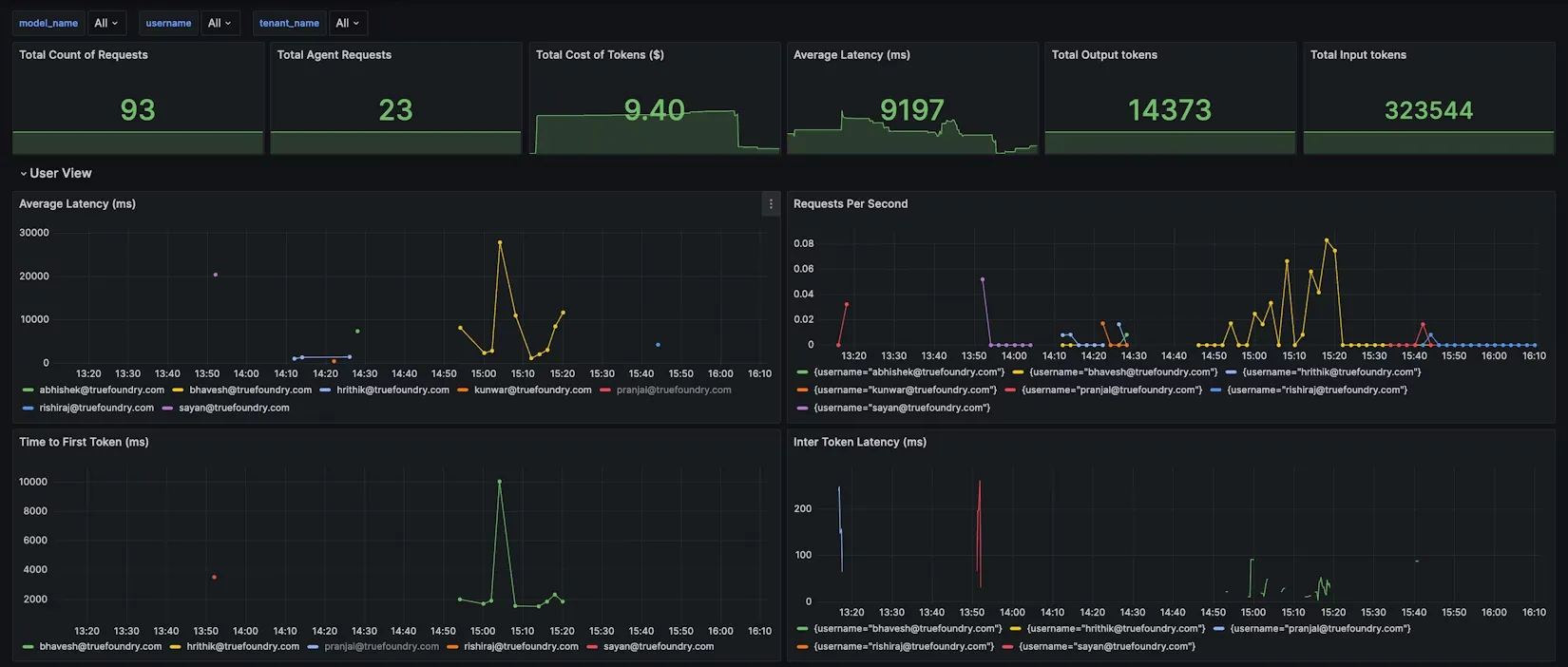
Zum Beispiel die Modell-Ansicht zeigt möglicherweise Token-Nutzung und Latenz pro Modell an, während Benutzeransicht schlüsselt die Nutzung nach Nutzernamen auf, um Vielnutzer zu identifizieren. Sie können sogar benutzerdefinierte Dashboard-Filter für Ihre Metadaten-Tags hinzufügen (z. B. alle Diagramme nach Kunden-ID oder Projekt filtern), um On-Demand-Kostenberichte für einen bestimmten Kunden oder ein bestimmtes Projekt zu erhalten.
Durch die Zentralisierung all dieser Daten erreichen Sie vollständige Sichtbarkeit in den KI-Konsum. Es wird trivial, Fragen zu beantworten wie: Welches Team hat diese Woche die meisten GPT-4-Token generiert? Wie viel hat unsere neue Chatbot-Funktion bei API-Aufrufen gekostet? Welche Kunden oder Nutzer haben die höchste Nutzung? Mit TrueFoundry können Sie einfach einen Filter umschalten oder eine Abfrage ausführen, um diese Antworten zu erhalten. Dieses Maß an Transparenz ist die Grundlage für FinOps in der KI — es beleuchtet jedes Token und jede GPU-Stunde und verwandelt Ungewissheit in umsetzbare Erkenntnisse.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Sichtbarkeit bereitet die Bühne, aber FinOps erfordert auch Rechenschaftspflicht und proaktiv Führung der Ausgaben. Bei Cloud-FinOps werden Teams ermutigt, ihre Nutzung selbst zu bestimmen und Budgets einzuhalten. Bei KI-FinOps ist es angesichts der Unvorhersehbarkeit der Nutzung unerlässlich, einige durchzusetzen Leitplanken damit die Kosten nicht durch einen Bug oder ein wild gewordenes Experiment davonlaufen. Die Plattform-Builds von TrueFoundry Kostenkontrolle direkt in die KI-Infrastrukturschicht, sodass Sie die Nutzung in Echtzeit kontrollieren können, anstatt erst im Nachhinein darüber zu berichten.
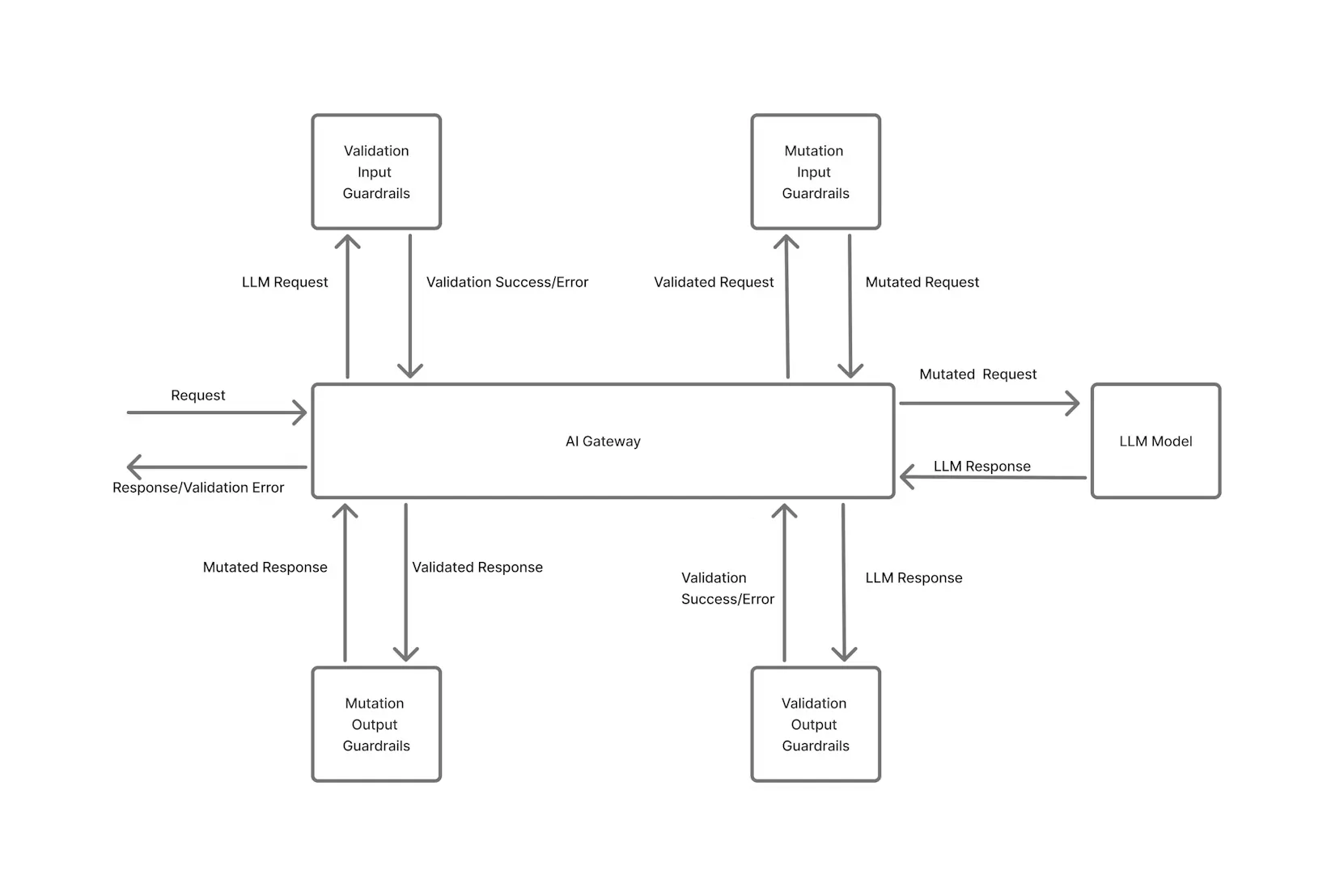
Zuordnung pro Anfrage und Rückbuchungen: Da TrueFoundry jede Anfrage mit Team- und Projektmetadaten taggt und verfolgt, können Sie die Kosten in Echtzeit detailliert zuordnen. Dies ermöglicht interne Chargeback- oder Showback-Modelle — z. B. zeigen Sie jedem Produktteam, wie viel seine Funktionen für KI ausgeben, oder berechnen Sie einem externen Kunden die spezifische Nutzung.
Die Kostenkennzahlen von TrueFoundry können nach diesen Attributen gefiltert werden, um sofort Aufschlüsselungen zu erstellen (Kosten pro Benutzer, nach Funktion, nach Kunde usw.). Durch das Teilen dieser Berichte entsteht Rechenschaftspflicht: Teams können sehen die Auswirkungen ihres Codes und ihrer Aufforderungen auf die Rechnung, und die Finanzabteilung kann sicherstellen, dass die Ausgaben den Geschäftsbereichen oder Kunden zugeordnet werden.
Rollenbasierte Zugriffskontrolle und Berechtigungen: Ein Teil der Unternehmensführung besteht darin, sicherzustellen, dass teure Ressourcen nur autorisiert verwendet werden. Das Gateway für Unternehmen von TrueFoundry unterstützt rollenbasierte Zugriffskontrolle (RBAC) und API-Schlüsselverwaltung. Das bedeutet, dass Sie einschränken können, wer bestimmte kostenintensive Modelle aufrufen darf, oder den Zugriff auf experimentelle Funktionen einschränken.
Beispielsweise könnten Sie einer QA- oder Staging-Umgebung erlauben, ein kleineres Modell zu verwenden, aber nur die Produktion kann die teure GPT-4-API aufrufen. Oder Sie könnten den API-Schlüssel eines Junior-Entwicklers auf ein Sandbox-Modell beschränken. Indem Sie den Zugriff sperren, verhindern Sie, dass teure Modelle versehentlich von den falschen Personen verwendet werden. In Kombination mit detaillierten Auditprotokollen und Metadaten wird so auch ein Prüfpfad für die Einhaltung der Vorschriften erstellt (d. h. Sie wissen genau, welcher Benutzer oder Dienst die jeweilige Anfrage gestellt hat).
Richtlinien zur Ratenbegrenzung: Eine der mächtigsten FinOps-Leitplanken ist Ratenbegrenzung. Mit dem AI Gateway von TrueFoundry können Sie flexible Regeln für Ratenbegrenzungen konfigurieren, um die Nutzung anhand verschiedener Dimensionen zu begrenzen — nach Benutzer, Team, Modell oder sogar nach benutzerdefinierten Tags.
Zum Beispiel kannst du sagen „Benutzer X kann nur 1.000 GPT-4-Anfragen pro Tag stellen“ oder „Alle Anfragen von Project ABC sind auf 50.000 Token pro Stunde begrenzt.“ Die Konfiguration ist in einem einfachen YAML-Format definiert. Hier ist ein Beispielausschnitt, der einige Regeln veranschaulicht:
name: ratelimiting-config
type: gateway-rate-limiting-config
rules:
# 1. Limit a specific user to 1000 requests/day on the GPT-4 model
- id: "limit-gpt4-user1-daily"
when:
subjects: ["user:[email protected]"]
models: ["openai-main/gpt4"]
limit_to: 1000
unit: requests_per_day
# 2. Limit each project (by metadata tag) to 50k tokens per hour
- id: "project-{metadata.project_id}-hourly"
when: {}
limit_to: 50000
unit: tokens_per_hourIn der obigen Regel #1 ist ein bestimmter Benutzer (identifiziert durch seinen API-Schlüssel oder Benutzernamen) auf 1000 GPT-4-Anfragen pro Tag begrenzt. In Regel #2 legen wir ein Limit von 50.000 Token/Stunde pro Projekt fest, vorausgesetzt, jede Anfrage enthält eine project_id in ihren Metadaten. Die Syntax {metadata.project_id} bedeutet, dass das Gateway für jede gefundene eindeutige Projekt-ID einen separaten Bucket erzwingt. In der Praxis verhindert diese Regel, dass ein einzelnes Projekt versehentlich mehr als 50.000 Token in einer Stunde verbraucht (z. B. wenn eine Integration nicht mehr funktioniert oder ein Kunde einen unerwarteten Anstieg verzeichnet). Das Gateway bewertet eingehende Anfragen anhand dieser Regeln der Reihe nach, und wenn eine Anfrage ein Limit überschreitet, ist gedrosselt oder abgewiesen an Ort und Stelle.
Budgetwarnungen und Kontingente: Zusätzlich zu den reinen Ratenlimits ermöglicht TrueFoundry die Festlegung von Budgetschwellenwerten. Sie können monatliche oder tägliche Ausgabenobergrenzen für ein Team oder eine Anwendung definieren. Beispielsweise könnten Sie 1000$ pro Monat für das Experimentieren eines Entwicklungsteams mit LLMs einplanen. Das Gateway kann die kumulativen Kosten von Anfragen verfolgen. Sobald der Schwellenwert überschritten ist, kann es entweder Warnungen senden oder die weitere Nutzung deaktivieren, bis ein Administrator eingreift. Das ist im Wesentlichen automatisierte Haushaltsvollstreckung. Anstatt am Ende des Monats herauszufinden, dass Team A zu viel ausgegeben hat, erfährst du es bei (sagen wir) 80% des Budgets und kannst Maßnahmen ergreifen.
Das Gateway von TrueFoundry kann sogar automatische Drosselung oder Pause fordert an, wenn ein Budget ausgeschöpft ist, um zu hohe Ausgaben zu verhindern und gleichzeitig die Interessengruppen zu informieren. Finanzteams wissen diese Art von Sicherheitsnetz zu schätzen, da dadurch die Kostenkontrolle zu einem aktiven, kontinuierlichen Prozess und nicht zu einer nachträglichen Analyse wird.
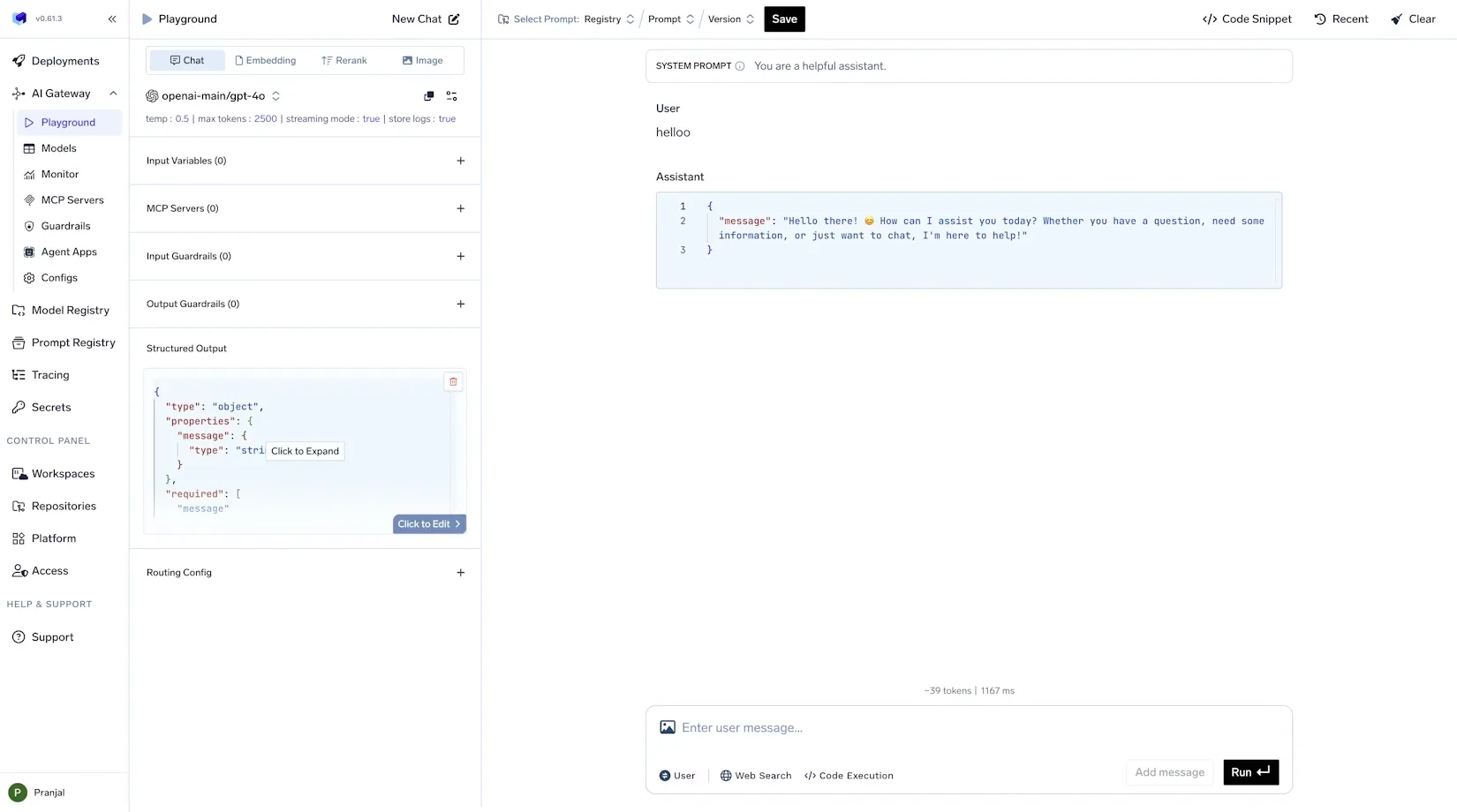
Sofortige Leitplanken und Validierung: Ein weiterer Aspekt der Unternehmensführung ist die Durchsetzung bewährter Verfahren in Bezug auf Aufforderungen und Nutzungsmuster, um Kostenexplosionen zu vermeiden. Die Plattform von TrueFoundry umfasst Schutzfunktionen, mit denen beispielsweise bestimmte unsichere oder ineffiziente Aufforderungen blockiert werden können. Sie können Regeln einrichten, um Aufforderungen abzulehnen, die eine maximale Tokenlänge überschreiten oder unzulässige Inhalte enthalten.
In ähnlicher Weise unterstützt TrueFoundry strukturierte Ausgabeschemas und Vorlagen für Aufforderungen, die dabei helfen, die Antworten präzise und vorhersehbar zu halten und die Token-Nutzung indirekt zu kontrollieren.
Das letzte FinOps-Prinzip lautet Optimierung — kontinuierliche Verbesserung der Kosteneffizienz ohne Einbußen bei Leistung oder Ergebnissen. Nachdem die Transparenz erreicht und die Unternehmensführung eingerichtet wurde, können sich Unternehmen darauf konzentrieren, mehr Wert aus jedem für KI ausgegebenen Dollar herauszuholen. TrueFoundry bietet mehrere Möglichkeiten zur Optimierung von KI-Workloads, vom intelligenten Anforderungsrouting auf Modellebene bis hin zur effizienten Nutzung der GPU-Infrastruktur.
Intelligente Modellauswahl (Modelle in der richtigen Größe): Nicht jede Aufgabe benötigt das teuerste Modell. Ein Markenzeichen der KI-Kostenoptimierung ist die Verwendung der preiswerteste ausreichend Modell für jeden Job. Das AI Gateway von TrueFoundry unterstützt Routing von Hybridmodellen Strategien, mit denen Sie Anfragen basierend auf Kosten- oder Komplexitätsrichtlinien automatisch an verschiedene Modelle weiterleiten können.
Beispielsweise könnten Sie einfache Abfragen oder Anfragen mit niedriger Priorität an ein kleineres, billigeres Modell weiterleiten (z. B. ein Open-Source-7B-Modell oder eine OpenAI GPT-3.5-Tier) und nur komplexe Abfragen oder Abfragen mit hohen Einsätzen an ein Premium-Modell wie GPT-4 senden. Viele Teams stellen fest, dass ein großer Teil ihres Datenverkehrs mit billigeren Modellen bewältigt werden kann, sodass das kostspielige Modell den wenigen Fällen vorbehalten ist, in denen seine überlegene Funktionalität wirklich benötigt wird. TrueFoundry macht dies möglich, indem es regelbasiertes Routing (oder sogar ML-basiertes dynamisches Routing) in der Gateway-Konfiguration ermöglicht. Das Ergebnis ist, dass Sie nicht zu viel für „übertriebene“ Modelle bezahlen müssen — Sie Zahlen Sie niemals zu viel für Funktionen, die Sie nicht benötigen wenn das Gateway für die richtigen Szenarien automatisch auf ein günstigeres Modell herunterschalten kann.
Batching und Caching: Wenn Sie pro Anfrage oder pro Token bezahlen, lohnt es sich, redundante Arbeit zu vermeiden. Die Plattform von TrueFoundry bietet Funktionen für Stapelverarbeitung und Zwischenspeichern von Antworten um die Effizienz zu verbessern. Mit dem Batch-Inferenz-API, Sie können mehrere Aufforderungen oder Eingaben in einer Anfrage kombinieren, um die Gemeinkosten zu amortisieren.
Sofortige Optimierung und Kürzung: Ein weiterer Optimierungsweg ist die Reduzierung der Größe der Eingabeaufforderung. Durch die Beobachtbarkeit stellen Sie möglicherweise fest, dass bestimmte Eingabeaufforderungen unnötig lang sind (z. B. mit irrelevantem Kontext). Techniken wie die Komprimierung von Eingabeaufforderungen, die Verwendung eines kürzeren Verlaufs oder die Verwendung von durch Abruf erweiterter Generierung (bei der externes Wissen relevant abgerufen wird, anstatt ein ganzes Dokument in die Eingabeaufforderung zu kopieren) können die Anzahl der Tokens reduzieren.
TrueFoundry unterstützt RAG-Workflows und sogar Tools zur Verwaltung von Eingabeaufforderungen (wie zeitnahe Versionierung und Testen), um Teams dabei zu unterstützen, effizientere Eingabeaufforderungen zu entwickeln. Anstatt beispielsweise bei einer Benutzerkonversation auf Schritt und Tritt den gesamten Chatverlauf zu senden, könnten Sie älteren Kontext zusammenfassen oder löschen, sobald er irrelevant ist — und ein winziges bisschen Genauigkeit gegen eine große Kostenersparnis eintauschen. TrueFoundry's Prompter Spielplatz und Analysen können dabei helfen, zu analysieren, wie die Länge der Prompts mit den Kosten korreliert, und aufzeigen, wo Sie Fett abbauen könnten.
Optimierung der GPU-Nutzung: Für Teams, die selbst gehostete Modelle verwenden oder Trainingsjobs ausführen, ist die Optimierung der GPU-Infrastruktur für FinOps von entscheidender Bedeutung. Die ML-Plattform von TrueFoundry wurde entwickelt, um die GPU-Auslastung zu maximieren und Verschwendung zu vermeiden. Zu den wichtigsten Funktionen gehören:
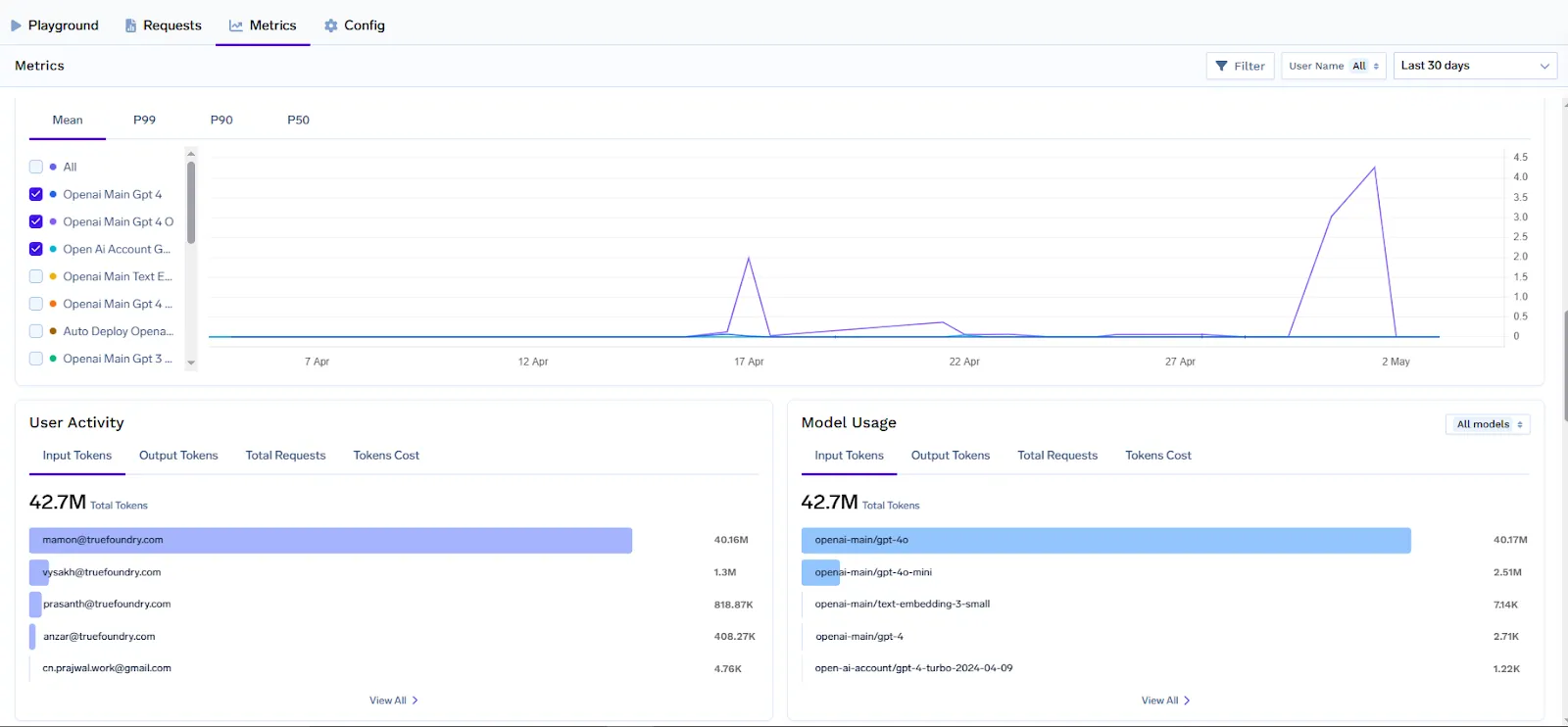
Eine praktische FinOps-Initiative profitiert von klaren Berichten und Dashboards, die die Kennzahlen und Geschäftseinblicke zusammenführen. TrueFoundry vereinfacht die Erstellung von FinOps-Dashboards für KI indem wir alle notwendigen Daten und Integrationspunkte für beliebte Tools sofort bereitstellen.
Mithilfe der vom AI Gateway exportierten Metriken können Teams Dashboards in Grafana, Datadog oder einem beliebigen BI-Tool erstellen, um KI-Nutzungs- und Ausgabentrends zu visualisieren. Da beispielsweise jede Anfrage mit Team und Modell beschriftet ist, könnten Sie ein Grafana-Panel erstellen, das Folgendes anzeigt „Kosten pro Team (letzte 7 Tage)“ durch Abfragen der Metrik llm_gateway_request_total_cost, gruppiert nach tenant_name (team). Möglicherweise wird ein anderes Fenster angezeigt „Tokens pro Anfrage nach Modell“ um herauszufinden, welche Modelle tokenhungrig sind und möglicherweise optimiert werden müssen. TrueFoundry's vorgefertigtes Grafana-Dashboard enthält bereits Ansichten zur Analyse der Nutzung nach Modell, Benutzer und Konfigurationsregeln (z. B. um festzustellen, ob Ratenlimits häufig überschritten werden). Sie können diese um benutzerdefinierte Metadaten erweitern. Fügen Sie beispielsweise einen Filter für customer_id als Variable hinzu, sodass Stakeholder einen bestimmten Kunden auswählen und dessen Token-Nutzung und Kosten im Laufe der Zeit sehen können.
Die Integration mit anderen Monitoring- und APM-Tools ist über OpenTelemetry möglich. Wenn Ihre Organisation Datadog verwendet, können Sie die Metriken des Gateways an den Messwerteingang von Datadog weiterleiten (da Datadog OpenTelemetry- oder Prometheus-Metriken aufnehmen kann). Das bedeutet, dass Ihre KI-Kostenkennzahlen mit Ihren Infrastrukturkostenkennzahlen übereinstimmen können. Es wird einfach, beispielsweise einen Anstieg der Token-Nutzung mit einer bestimmten Bereitstellung oder dem Start einer bestimmten Funktion zu korrelieren, da alle Daten an einem Ort zugänglich sind.
TrueFoundry bietet auch eine Analytics-API für Nutzungsdaten. Wenn Sie die Daten also lieber in ein benutzerdefiniertes Finanz-Dashboard oder eine Tabelle ziehen möchten, können Sie dies tun. Viele Unternehmen exportieren Rohdaten (TrueFoundry ermöglicht sogar den CSV-Download von Kostendaten), um sie mit Rechnungsdatensätzen zu kombinieren. So erhalten Sie ein vollständiges Bild der Kosten pro Projekt, wenn Sie Overhead wie Speicher oder Netzwerk hinzufügen.
Der Schlüssel ist, dass mit den Grundlagen, die TrueFoundry geschaffen hat (Metadaten-Tagging, Echtzeit-Metriken), die Erstellung dieser FinOps-Erkenntnisse nicht erfordert, eine Datenpipeline von Grund auf neu aufzubauen. Sie erhalten genaue, attributionsreiche Daten in Echtzeit. Das ist ein großer Fortschritt gegenüber dem Warten auf die Cloud-Rechnung zum Monatsende. Führungskräfte aus den Bereichen Technik, ML und Finanzen können gemeinsam Dashboards überprüfen, die sowohl technische als auch geschäftliche Fragen zur KI-Nutzung beantworten. Diese funktionsübergreifende Sichtbarkeit fördert eine Kultur des Kostenbewusstseins
Die Implementierung von FinOps für KI ist ein fortlaufender Prozess. Es beginnt mit Bewusstsein und entwickelt sich zu einer Disziplin, die in den KI-Entwicklungszyklus eingebettet ist. Durch die Einführung von Transparenz, Rechenschaftspflicht und Optimierungspraktiken entwickeln Unternehmen ihren FinOps-Reifegrad weiter — von reaktiven Kostenberichten über die Kostenkontrolle in Echtzeit bis hin zur vorausschauenden Optimierung. Am wichtigsten ist der Aufbau einer FinOps-Kultur around AI sorgt für Nachhaltigkeit. Die Einführung von KI wird ins Stocken geraten, wenn die Kosten ungebremst oder unvorhersehbar steigen. Wenn Unternehmen KI durch eine FinOps-Linse betrachten, betrachten sie den Modellzugriff und die GPU-Zeit als wertvolle Ressourcen, die es zu verwalten gilt, und nicht als grenzenlose Magie. Dieser kulturelle Wandel wird durch Tools ermöglicht: Wenn Teams Self-Service-Zugriff auf Kennzahlen und Kostenberichte haben, können sie die Verantwortung übernehmen. True Foundry's Die Lösung beschleunigt diese kulturelle Akzeptanz durch den Einsatz von KI transparent und designoritiert — Kostentransparenz und Kontrollen sind in die Plattform integriert und nicht als Nebensache gedacht.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




