April 22, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Aktualisiert: April 7, 2026




Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
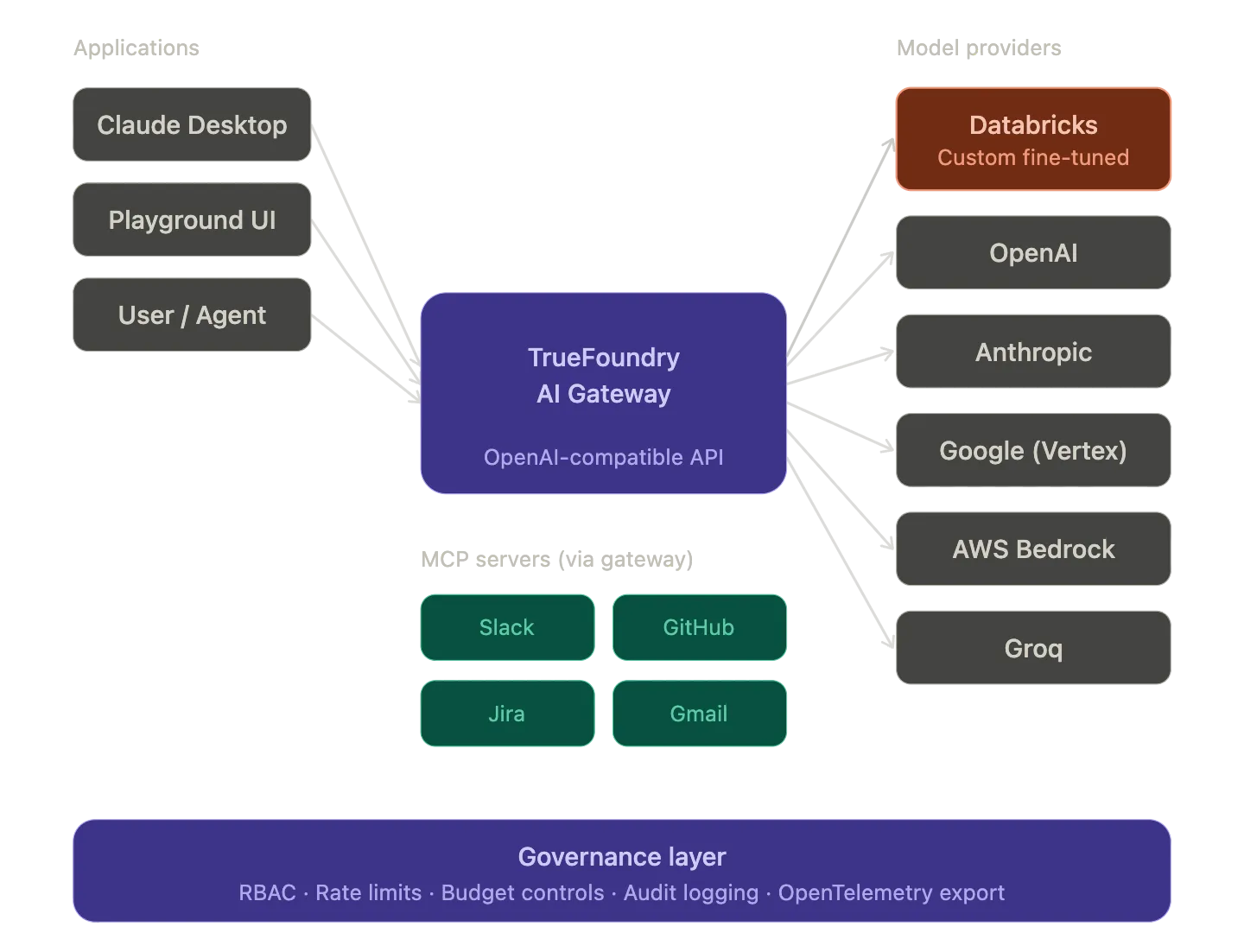
TrueFoundry AI Gateway registriert Databricks Model Serving als erstklassigen Anbieter und leitet den Inferenzverkehr über denselben OpenAI-kompatiblen Endpunkt an ihn weiter, der jeden anderen Anbieter in Ihrem Stack verarbeitet. Die Integration geht über das Model-Routing hinaus. Das MCP Gateway von TrueFoundry befindet sich vor den von Databricks verwalteten MCP-Servern, um die Authentifizierung und Zugriffskontrolle auf Toolebene sowie die Auditprotokollierung für Agenten-Workflows, die Unity Catalog abfragen, durchzusetzen.
In diesem Beitrag werden vier Integrationspunkte behandelt: die Registrierungs- und Routing-Ebene des AI Gateway-Anbieters für Databricks Model Serving-Endpunkte. Die MCP Gateway-Governance-Ebene für von Databricks verwaltete MCP-Server. Die Virtual Model-Routing-Ebene, die ein Failover mehrerer Anbieter zwischen von Databricks gehosteten Modellen und kommerziellen APIs ermöglicht. Und die Workflow-Orchestrierungsschicht, die Databricks-Jobs als native Aufgaben innerhalb von TrueFoundry-Pipelines auslöst. Jeder Abschnitt enthält eine funktionierende Konfiguration und genügend architektonische Details, um zu beurteilen, ob diese Integration zu Ihrem Stack passt.
TrueFoundry AI Gateway verwendet eine geteilte Architektur. Eine Steuerungsebene verwaltet die Konfiguration, einschließlich Modelle und Benutzer sowie Routing-Regeln und Ratenbegrenzungen. Eine Gateway-Ebene verarbeitet die tatsächlichen Inferenzanforderungen. Die Steuerungsebene speichert ihren Status in PostgreSQL und ClickHouse und synchronisiert die gesamte Konfiguration mit den Gateway-Pods über NATS Nachrichtenwarteschlange. Updates werden in Echtzeit ohne Neustarts weitergegeben.
Das Gateway-Flugzeug ist gebaut auf dem Hono-Rahmen und führt alle Authentifizierungs- und Autorisierungs- und Ratenbegrenzungsprüfungen im Speicher durch. Ein einzelner Gateway-Pod auf 1 vCPU und 1 GB RAM verarbeitet mehr als 250 Anfragen pro Sekunde mit einer zusätzlichen Latenz von ca. 3 ms. Der Pod skaliert vor der CPU-Sättigung auf über 350 RPS. Die horizontale Skalierung über zusätzliche Pods erhöht den Durchsatz auf Zehntausende von Anfragen pro Sekunde.
Wenn eine Anfrage das Gateway erreicht, folgt die Verarbeitung einer strengen Reihenfolge ohne externe Aufrufe im Hotpath:
Der einzige externe Aufruf in diesem Pfad ist der eigentliche LLM-Provider-Aufruf. Protokolle und Metriken werden nach Abschluss der Antwort asynchron in NATS geschrieben. Das Gateway schlägt bei einer Anfrage niemals fehl, auch wenn die NATS-Warteschlange vorübergehend nicht erreichbar ist.
Sie registrieren Databricks Model Serving als Anbieter im AI Gateway, indem Sie die Authentifizierungsdaten und Ihre Workspace-URL angeben. TrueFoundry unterstützt zwei Authentifizierungsmethoden.
Service Principal-Authentifizierung ist der empfohlene Ansatz für die Produktion. Sie geben die Client-ID und das OAuth-Geheimnis an, die in Ihren Databricks-Workspace-Einstellungen unter Service Principals generiert wurden. Dabei wird der OAuth 2.0-Client-Anmeldeinformationsfluss verwendet.
Persönliche Zugriffstoken-Authentifizierung arbeitet für Entwicklung und Tests. Sie stellen direkt ein Databricks-PAT bereit.
In beiden Fällen geben Sie auch die Basis-URL des Workspace an (z. B. <workspace_id>https://.cloud.databricks.com).
Sobald der Anbieter registriert ist, fügen Sie einzelne Modelle hinzu. Die Modell-ID in TrueFoundry muss genau mit dem Namen des Serving-Endpunkts in Ihrem Databricks-Workspace übereinstimmen. Jedes von Databricks bereitgestellte Modell kann über das Gateway weitergeleitet werden. Dazu gehören Foundation-Modelle, die über Databricks verfügbar sind, und benutzerdefinierte, fein abgestimmte Modelle von Mosaic AI und Modellen von Drittanbietern, auf die über Databricks Model Serving zugegriffen werden kann.
Der Anwendungscode trifft unabhängig vom zugrunde liegenden Anbieter auf eine URL. Das Gateway übersetzt zwischen dem OpenAI-kompatiblen Format und dem, was der Downstream-Anbieter erwartet.
aus openai importiere OpenAI
Klient = OpenAI (
base_url=“ https://your-truefoundry-gateway.com/api/llm „,
api_key="dein-truefoundry-API-Schlüssel“
)
# Diese Anfrage wird über das Gateway an Databricks Model Serving weitergeleitet.
# Der Anwendungscode weiß oder kümmert sich nicht darum, welcher Anbieter ihn anbietet.
Antwort = client.chat.completions.create (
model="databricks-main/custom-finetuned-llama“,
messages= [{"role“: „user“, „content“: „Analysieren Sie die Abwanderungstrends im dritten Quartal"}]
)
Das Modell Feld verwendet das Format <provider-account-name>/<model-id> wobei die Modell-ID mit dem von Ihnen konfigurierten Namen des Databricks-Serverendpunkts übereinstimmt.
EIN Virtuelles Modell ist eine logische Modell-ID, die mehreren physischen Anbietern mit Routing-Regeln zugeordnet ist. Ihre Anwendung ruft einen einzelnen Modellnamen auf, und das Gateway kümmert sich automatisch um die Zielauswahl und den Failover.
# Dies trifft auf ein virtuelles Modell. Das Gateway löst das Problem bestmöglich
# physischer Anbieter basierend auf Ihrer Routing-Konfiguration.
Antwort = client.chat.completions.create (
model="Produktionsassistent“,
messages= [{"role“: „user“, „content“: „Fasse diesen Vertrag zusammen"}]
)
TrueFoundry unterstützt drei Routing-Strategien für virtuelle Modelle.
Gewichtsbasiertes Routing verteilt den Traffic anhand zugewiesener Prozentsätze auf die Ziele. Sie können 80% für Ihr von Databricks gehostetes, fein abgestimmtes Modell und 20% für Claude für Vergleichstests konfigurieren. Das gewichtsbasierte Routing unterstützt auch das feste Routing, bei dem Sitzungen mithilfe von Anforderungsheadern oder Metadaten einem Ziel zugeordnet werden, um eine konsistente Konversation mit mehreren Runden zu gewährleisten.
Prioritätsbasiertes Routing sendet den gesamten Datenverkehr an das gesunde Ziel mit der höchsten Priorität (Priorität 0 ist am höchsten). Wenn dieses Ziel ausfällt oder nicht verfügbar ist, fällt das Gateway auf die nächste Priorität zurück. Dies unterstützt eine optionale SLA-Grenzwert das die durchschnittliche Zeit pro Ausgabe-Token über ein fortlaufendes Zeitfenster von 3 Minuten überwacht und Ziele als fehlerhaft markiert, wenn sie einen konfigurierten Schwellenwert überschreiten.
Latenzbasiertes Routing leitet automatisch an das Ziel mit der niedrigsten aktuellen Latenz weiter. Das Gateway verwendet Zeit pro Ausgabetoken (Latenz zwischen den Token) als Metrik. Sie berücksichtigt Anfragen der letzten 20 Minuten mit maximal 100 Samples. Wenn weniger als 3 Anfragen für ein Ziel existieren, wird es als das schnellste Ziel betrachtet, das mehr Daten sammelt. Ziele gelten als gleich schnell, wenn ihre Latenz nicht mehr als das 1,2-fache der Latenz am schnellsten beträgt, um ein schnelles Umschalten zu vermeiden.
Das Gateway überwacht kontinuierlich jedes Ziel und markiert Ziele als fehlerhaft, wenn Fehler einen Schwellenwert überschreiten. Zu den protokollierten Fehlerantworten gehören die Statuscodes 5xx und 429 sowie 401 und 403. Der Standardschwellenwert für Fehler liegt bei 2 oder mehr Ausfällen innerhalb eines fortlaufenden Bewertungsfensters von 2 Minuten. Wenn ein Ziel als fehlerhaft markiert wird, wird es an das Ende der Routing-Liste verschoben und fehlerfreie Ziele werden immer zuerst ausprobiert. Die Wiederherstellung erfolgt automatisch, sobald das Evaluierungsfenster abgelaufen ist.
Jedes Ziel unterstützt auch die Konfiguration von Wiederholungsversuchen pro Ziel. Die Standardeinstellung sind 2 Wiederholungsversuche mit einer Verzögerung von 100 ms zwischen den Wiederholungen. Der Wiederholungsversuch wird bei den Statuscodes 429 und 500 sowie 502 und 503 ausgelöst. Der Fallback zu einem anderen Ziel wird bei 401 und 403 sowie 404 und 429 und 500 und 502 und 503 ausgelöst.
Jede Anfrage über das Gateway wird mit vollständiger Zuordnung verfolgt: welcher Benutzer und welches Modell und welcher Anbieter und welche Anforderungslatenz sowie Token-Anzahl und geschätzte Kosten. Das Gateway ist OpenTelemetry-konform und exportiert Traces asynchron über NATS an einen konfigurierbaren OTEL-Endpunkt (gRPC oder HTTP). Sie können diese an jeden Observability-Stack weiterleiten, den Sie ausführen. Auf diese Weise erhalten Sie ein einziges Dashboard für alle Anbieter, anstatt anbieterspezifische Kennzahlen zusammenzustellen.
Databricks führte Mitte 2025 die Unterstützung für verwaltete MCP-Server ein. Diese Server ermöglichen es Agenten, über das Model Context Protocol sicher auf Unity-Catalog-Ressourcen zuzugreifen. Databricks bietet verwaltete Server für Genie (strukturierter Datenzugriff über natürliche Sprache) und Vektor-Suche (unstrukturierte Daten aus Vektorindizes) und UC-Funktionen (benutzerdefinierte Funktionen, die im Unity-Katalog registriert sind). Die Unity-Katalogberechtigungen werden automatisch durchgesetzt, sodass Agenten nur auf Tools und Daten zugreifen können, für die ihre Identität autorisiert ist.
Die Governance-Herausforderung besteht darin, was zwischen dem Agenten und diesen MCP-Servern passiert. Ohne eine Kontrollebene konfiguriert jeder Entwickler seine eigenen Verbindungen, verwaltet seine eigenen Anmeldeinformationen und erstellt seine eigenen Tool-Richtlinien. Es gibt keinen zentralen Audit-Trail, aus dem hervorgeht, welcher Agent welches Tool aufgerufen hat. Es gibt keine Möglichkeit, teamübergreifend den Zugriff mit den geringsten Rechten durchzusetzen. Es gibt keine zentrale Stelle, an der der Zugriff entzogen werden kann, wenn jemand das Unternehmen verlässt.
TrueFoundry MCP Gateway befindet sich zwischen Ihren Agenten (Claude Code and Cursor und benutzerdefinierte Agenten-Frameworks) und Ihren MCP-Servern (einschließlich der von Databricks verwalteten MCP-Server). Es fungiert als Reverse-Proxy mit Authentifizierung und Autorisierung sowie Auditprotokollierung.
Ablauf der Authentifizierung. Agenten authentifizieren sich einmal beim MCP Gateway mithilfe eines TrueFoundry-API-Schlüssels oder eines externen IdP-Tokens (Okta und Azure AD und Auth0 werden unterstützt). Das Gateway verarbeitet die ausgehende Authentifizierung für jeden Downstream-MCP-Server. Für Databricks bedeutet dies, dass das Gateway die Service Principal OAuth-Anmeldeinformationen (PAT) speichert und einzelne Agenten niemals die unformatierten Databricks-Anmeldeinformationen bearbeiten.
Zugriffskontrolle auf Toolebene. Mit dem Gateway können Sie einzelne Tools pro Team wahlweise aktivieren oder deaktivieren. Sie können auch Tools von mehreren MCP-Servern zu einem zusammenfassen Virtueller MCP-Server das zeigt nur eine kuratierte Teilmenge. Beispielsweise könnte Ihr Data-Science-Team von Databricks Zugriff auf Genie und Vector Search sowie einen Websuchserver erhalten, während Ihr Entwicklungsteam ein anderes Toolset erhält.
Leitplanken. Das Gateway trägt Leitplanken an vier Haken. MCP Vorwerkzeug Leitplanken werden ausgeführt, bevor das Tool aufgerufen wird. Sie können SQL-Abfragen validieren, nach sensiblen Daten suchen und Berechtigungsrichtlinien durchsetzen. Wenn eine der vorinstallierten Leitplanken ausfällt, wird das Tool nie ausgeführt. MCP Posttool Leitplanken überprüfen die Werkzeugausgaben und schreiben sie optional neu, bevor die Ergebnisse an das Modell zurückgegeben werden. Sie können diese so konfigurieren, dass sie nach personenbezogenen Daten und Geheimnissen in den Ergebnissen suchen. Workflows zur Benutzergenehmigung können für Vorgänge mit hohem Risiko konfiguriert werden. Drei Strategien zur Durchsetzung stehen zur Verfügung: Durchsetzen (Sperrung bei Verstoß oder Leitplankenfehler) und Erzwingen, aber bei Fehler ignorieren (bei Verstoß blockieren, aber bei Leitplanken-Wartungsfehler zulassen) und Prüfung (nur protokollieren und niemals blockieren).
Prüfpfad. Jeder Toolaufruf wird anhand des aufrufenden Benutzers und des MCP-Servers sowie der spezifischen Tool- und Anforderungsnutzlast und Antwort-Nutzlast und Latenz verfolgt. Dies wird zusammen mit Ihren LLM-Anforderungs-Traces über OpenTelemetry exportiert, sodass Sie ein einheitliches Protokoll über alles erhalten, was Ihre Agenten tun.
Wenn Ihre Entwickler Claude Code verwenden, konfigurieren Sie das MCP Gateway als Remote-MCP-Server. Für die Unternehmensführung sind zwei separate Konfigurationsdateien erforderlich, die über MDM auf Unternehmensgeräten bereitgestellt werden.
Das managed-settings.json Datei steuert, zu welchen MCP-Servern Claude Code eine Verbindung herstellen darf:
{
„Erlaubte MCP-Server“: [
{„serverUrl“: "https://mcp-gateway.your-company.com/ *“}
],
„Strikt bekannte Marktplätze“: []
}
Einstellung Streng bekannte Marktplätze zu einem leeren Array blockiert alle vom Marktplatz stammenden MCP-Installationen. Kombiniert mit Zulässige MCP-Server Dadurch wird eine gesperrte Konfiguration erstellt, in der Agenten nur über Ihr gesteuertes Gateway auf Tools zugreifen können.
Das managed-mcp.json Datei definiert die tatsächlichen MCP-Serververbindungen. Stellen Sie dies über MDM auf den Pfad auf Systemebene bereit (/Library/Anwendungsunterstützung/ClaudeCode/Managed-MCP.json auf macOS oder /etc/claude-code/managed-mcp.json unter Linux):
{
„databricks-unity-katalog“: {
„Typ“: „http“,
„url“: "https://mcp-gateway.your-company.com/mcp/v1/databricks-uc/mcp“
},
„databricks-SQL“: {
„Typ“: „http“,
„url“: "https://mcp-gateway.your-company.com/mcp/v1/databricks-sql/mcp“
}
}
Wann managed-mcp.json wird über MDM bereitgestellt und übernimmt die ausschließliche Kontrolle. Entwickler können keine MCP-Server hinzufügen oder verwenden, die über das hinausgehen, was in dieser Datei definiert ist. Entscheidungen zur Zugriffskontrolle werden am Gateway getroffen, sodass Sie die bereitgestellte MDM-Datei nur aktualisieren müssen, wenn Sie ganze Serverintegrationen hinzufügen oder entfernen.
Eine umfassende Anleitung zum Schutz von Claude Code in Unternehmensumgebungen, einschließlich MDM-Bereitstellungsskripten und Sandbox-Durchsetzung, sowie das vollständige Schema für verwaltete Einstellungen finden Sie im Unternehmenssicherheit für Claude Dokumentation.
Dieser Integrationspunkt richtet sich speziell an Teams, die mithilfe von Mosaic AI Training Modelle auf Databricks optimieren und diese zusammen mit kommerziellen API-Modellen über einen einzigen Endpunkt bereitstellen möchten.
Das Setup ist wie folgt. Sie optimieren das Modell und stellen es mithilfe von Databricks Model Serving bereit, sodass es als Serving-Endpunkt verfügbar ist. Sie registrieren Databricks wie oben beschrieben als Anbieter im AI Gateway. Sie erstellen ein virtuelles Modell mit prioritätsbasiertem Routing, das zuerst Ihr von Databricks gehostetes Modell ausprobiert und auf eine kommerzielle API zurückgreift:
routing_config:
Typ: Prioritätsbasiertes Routing
load_balance_targets:
- Ziel: databricks-main/custom-finetuned-llama-3
Priorität: 0
- Ziel: anthropic-main/claude-Sonnet-4-5
Priorität: 1
Der gesamte Datenverkehr wird standardmäßig an Ihr von Databricks gehostetes benutzerdefiniertes Modell weitergeleitet. Wenn Databricks einen Serverfehler oder eine Zeitüberschreitung zurückgibt oder ein Ratenlimit erreicht, versucht das Gateway automatisch erneut, Claude Sonnet zu verwenden. Die Fallback-Statuscodes, die dieses Verhalten auslösen, sind 401 und 403 und 404 und 429 und 500 und 502 und 503. Der Anwendungscode weiß nie, dass der Failover stattgefunden hat. Es wird eine erfolgreiche Antwort von der ID des virtuellen Modells angezeigt.
Dieses Muster ist bei der Modellbewertung nützlich. Sie können beide Anbieter parallel betreiben, indem Sie gewichtsbasiertes Routing mit einer 50/50-Aufteilung verwenden und die Antworten protokollieren und die Qualität vergleichen, bevor Sie sich für das fein abgestimmte Modell für den gesamten Verkehr entscheiden. Die Traces des Gateways pro Anfrage enthalten den aufgelösten Provider, der jede Antwort gesendet hat (zurückgegeben in x-tfy-gelöstes Modell Response-Header), sodass Sie in Ihrem Observability-Stack nach Anbietern filtern und analysieren können.
TrueFoundry-Workflows basieren auf Flyte und bieten eine Möglichkeit, mehrstufige Pipelines als gerichtete azyklische Diagramme von Aufgaben zu orchestrieren. Jede Aufgabe wird in einem eigenen Container mit definierten Ressourcen und Abhängigkeiten ausgeführt. Die Databricks-Integration fügt einen nativen Aufgabentyp hinzu, der bestehende Databricks-Jobs innerhalb dieser Workflows auslöst, sodass die Spark-basierte Datenverarbeitung und das Modelltraining zusammen mit den nativen TrueFoundry-Aufgaben wie der Modellbereitstellung und -bewertung zusammengestellt werden können.
Eine Databricks-Aufgabe verwendet den Standard @task Dekorateur mit einem DataBricksJobTaskConfig das gibt den Databricks-Workspace und den Job an, der ausgelöst werden soll. Unter der Haube ruft die Aufgabe die Databricks Jobs API auf run_now () Endpunkt mit einem Idempotenz-Token, das von der Flyte-Ausführungs-ID abgeleitet wurde. Dadurch wird sichergestellt, dass dieselbe logische Workflow-Ausführung niemals doppelte Databricks-Jobs sendet, selbst wenn der Task-Pod es erneut versucht.
von truefoundry.workflow import (
DataBricksJobTaskConfig,
Aufgabe Python Build,
Aufgabe,
Arbeitsablauf,
)
@task (
task_config=DataBricksJobTaskConfig (
image=taskPythonBuild (
pip_packages = ["truefoundry [Arbeitsablauf]"],
),
<your-workspace>workspace_host="https://.cloud.databricks.com“,
service_account="flyte-databricks-sa“,
job_id="123",
Timeout_Sekunden=2000,
)
)
def run_databricks_training ():
print („Databricks-Schulungsauftrag abgeschlossen“)
@task
def deploy_model ():
# Stellen Sie das trainierte Modell als API-Endpunkt bereit
Pass
@workflow ()
def train_and_deploy ():
run_databricks_training ()
deploy_model ()
Der Aufgabenprozess selbst wird in einem Lightweight Container ausgeführt, der durch den Bild Feld. Die eigentliche Jobausführung erfolgt vollständig in Databricks. Standardmäßig fragt die Aufgabe ab, bis der Databricks-Lauf beendet ist oder bis Timeout_Sekunden vergeht. Wenn der Timeout erreicht ist, wird der Databricks-Lauf abgebrochen und ein Laufzeitfehler wird angehoben. Wenn du setzt überspringen_warten_auf_fertigstellen zu Wahr Die Aufgabe kehrt sofort nach dem Auslösen des Jobs zurück, ohne darauf zu warten, dass er abgeschlossen ist.
Das DataBricksJobTaskConfig akzeptiert die folgenden Felder.
Die Aufgabe unterstützt zwei Authentifizierungsmethoden. Persönliches Zugriffstoken Authentifizierung funktioniert, wenn DATABRICKS_PERSONAL_ACCESS_TOKEN wird in der Umgebung der Aufgabe festgelegt. Sie injizieren das PAT über den env Feld in der Aufgabenkonfiguration mit einer geheimen Referenz, sodass das Token niemals hartcodiert wird.
OAuth-Token-Verbund ist die Alternative, wenn kein PAT gesetzt ist. Das erfordert DATABRICKS_SERVICE_PRINCIPAL_CLIENT_ID in der Umgebung und einem Kubernetes service_account auf dem Task-Pod. Das Kubernetes-Dienstkonto-Token wird über den Workspace-OIDC-Endpunkt gegen ein Databricks-Zugriffstoken ausgetauscht. Für den Databricks-Workspace muss der OIDC-Verbund konfiguriert sein, damit dieser Pfad funktioniert.
Der OAuth-Token-Verbund vermeidet das vollständige Speichern langlebiger Databricks-Anmeldeinformationen. Das Kubernetes-Dienstkonto-Token ist kurzlebig und auf den Task-Pod beschränkt. Der OIDC-Austausch findet zur Laufzeit statt, sodass keine Geheimnisse rotiert oder verwaltet werden müssen.
Der typische Anwendungsfall ist eine Pipeline, in der die Datenaufbereitung und das Modelltraining in Databricks ablaufen (weil dort Ihre Delta Lake-Daten gespeichert sind und wo Ihre Spark-Cluster bereitgestellt werden) und nachgelagerte Schritte wie die Modellregistrierung sowie die Bereitstellung und Bewertung in TrueFoundry ausgeführt werden. Die Databricks-Aufgabe verbindet die beiden Umgebungen innerhalb einer einzigen Workflow-Definition. Sie erhalten die Abhängigkeitsauflösung von Flyte und versuchen es erneut mit Semantik und Caching über die gesamte Pipeline, anstatt separate Orchestrierungssysteme zusammenzufügen.
Die Integration zwischen Databricks und TrueFoundry erfolgt auf drei Ebenen. Die AI Gateway-Ebene registriert Databricks Model Serving als Anbieter und leitet den Inferenzverkehr über denselben einheitlichen Endpunkt weiter, der alle anderen Anbieter abwickelt. Virtuelle Modelle ermöglichen das Routing mehrerer Anbieter mit automatischem Failover zwischen von Databricks gehosteten Modellen und kommerziellen APIs. Die MCP Gateway-Ebene befindet sich vor den von Databricks verwalteten MCP-Servern und zentralisiert die Authentifizierung und die Zugriffskontrolle auf Toolebene sowie die Auditprotokollierung für Agenten-Workflows. Die Workflow-Ebene löst Databricks-Jobs als native Aufgaben innerhalb von Flyte-basierten Pipelines aus, sodass Spark-Workloads mit TrueFoundry-Bereitstellungs- und Evaluierungsschritten in einer einzigen DAG zusammengefasst werden.
Es sind keine Beiwagen erforderlich. Im Anwendungscode sind keine SDK-Änderungen erforderlich. Die Adapterschicht des Gateways übersetzt transparent zwischen dem OpenAI-kompatiblen Format und dem Databricks Model Serving-Format. Die einzige Konfiguration, die erforderlich ist, ist die Anbieterregistrierung mit Authentifizierungsdaten und Modellendpunktzuordnung.
Das Design, das diese Integration sauber macht, ist die Architektur der Gateway-Ebene ohne externe Anrufe. Alle Authentifizierungs-, Autorisierungs- und Routing-Entscheidungen werden anhand des In-Memory-Status getroffen, der über NATS synchronisiert wird. Der einzige Netzwerk-Hop, der einer Anfrage hinzugefügt wird, ist der Gateway-Pod selbst, wodurch die Latenz um ca. 3 ms erhöht wird. Alles andere, einschließlich der Frequenzbegrenzung und Budgetdurchsetzung sowie der Erfassung des Zustands und der Telemetrieerfassung, erfolgt asynchron, ohne den Anforderungspfad zu berühren.
Die vollständige AI Gateway-Dokumentation finden Sie in der TrueFoundry-Dokumente. Informationen zur Einrichtung des Databricks-Anbieters finden Sie unter Databricks-Modelle. Informationen zur MCP Gateway-Konfiguration finden Sie unter MCP Gateway im Überblick. Informationen zur Workflow-Integration finden Sie unter Eine Databricks-Aufgabe erstellen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.







Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2025 Alle Rechte vorbehalten.





.png)


.webp)


.webp)