

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: May 20, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Im Jahr 2026 können es sich Unternehmen nicht mehr leisten, ein LLM-Gateway in ein provisorisches KI-Gateway umzuwandeln. KI wird nur noch stärker in kundenorientierte Workflows eingebettet werden, sodass eine dedizierte Gateway-Ebene für zuverlässige KI-gestützte Anwendungen unverzichtbar wird. Die typische KI-Infrastruktur von Unternehmen besteht häufig aus mehreren Modellen, mehreren Teams und mehreren Clouds, was zu einer komplexen Einhaltung von Vorschriften und Kostenrechnungen führt.
Gartner definiert ein KI-Gateway als eine Technologie oder Plattform, die als Vermittler zwischen Anwendungen und verschiedenen Diensten oder Modellen für künstliche Intelligenz (KI) fungiert. Sein Zweck besteht darin, den Zugriff auf KI-Funktionen zu vereinfachen und zu verwalten und einen zentralen Punkt zu bieten, um die Sicherheit, Steuerung und Beobachtbarkeit von KI-Workloads zu gewährleisten. Lesen Sie den vollständigen Text Gartner Marktleitfaden für KI-Gateways 2025 um mehr zu erfahren.
Im letzten Jahr haben sich drei große Kategorien herauskristallisiert, um das Problem der Regierungsführung und Widerstandsfähigkeit von GenAI anzugehen:
Jede Kategorie ist für eine andere Phase der KI-Einführung optimiert. Probleme treten auf, wenn Tools, die für eine Phase optimiert wurden, auf eine andere Phase übertragen werden.
In diesem Blog fassen wir alle Wettbewerbsanalysen zu einer eindeutigen Landschaft zusammen und erklären, wo die einzelnen Plattformen hinpassen, wo sie versagen und was Unternehmen bei der Auswahl eines Anbieters berücksichtigen müssen, der ihren Anforderungen am besten entspricht.
1. Kong AI: Traditionelles API-Gateway, das für KI angepasst ist
Kong ist ein API-Gateway, das häufig in Kubernetes‑basierten Microservice-Architekturen verwendet wird. Kong AI baut auf dieser Grundlage auf und führt Plugins und Integrationen ein, mit denen der Datenverkehr an große Sprachmodelle weitergeleitet werden kann.
Was Kong AI gut macht
Wo Kong AI zusammenbricht
Mit zunehmender KI-Nutzung werden diese Lücken sichtbarer. Kostenzuweisung, Strategien zur Modellauswahl und KI-spezifische Governance müssen außerhalb des Gateways, oft innerhalb des Anwendungscodes, geregelt werden.
Fazit: Kong AI ist als API-Gateway effektiv, aber KI bleibt eher ein zweitrangiges Anliegen als eine native Abstraktion.
2. Portkey: LLM-Gateway auf Anwendungsebene
Portkey ist ein KI-Gateway, das speziell für LLM-Anwendungen entwickelt wurde. Anstatt KI-Anfragen als generische HTTP-Aufrufe zu behandeln, führt Portkey zeitnahes und modellbewusstes Routing und Beobachtbarkeit ein.
Was Portkey gut macht
Wo Portkey zu kurz kommt
Das Design von Portkey ist bewusst anwendungsorientiert, was zu Einschränkungen auf Unternehmensebene führt
Da KI zu einer gemeinsamen internen Funktion und nicht zu einer einzelnen Anwendungsfunktion wird, erfordern diese Einschränkungen häufig zusätzliche Infrastrukturebenen.
Am besten geeignet für: LLM-Anwendungen für ein einzelnes Team werden in die frühe Produktion überführt.
3. LitellM: Erstes Open-Source-Gateway für Entwickler
LiteLLM ist ein Open-Source-LLM-Gateway, das eine einheitliche, OpenAI-kompatible API für den Zugriff auf Dutzende von Modelanbietern bietet.
Was LitellM gut macht
Wo LitellM zu kurz kommt
Am besten geeignet für: LiteLLM ist ein effektiver Einstiegspunkt, erfordert jedoch eine erhebliche Erweiterung für regulierte Umgebungen oder Umgebungen mit mehreren Teams.
Lesen Sie auch: Portkey gegen LitelM
4. AWS Bedrock: APIs für serverlose Modelle
AWS Bedrock bietet verwalteten, serverlosen Zugriff auf Foundation-Modelle von Anbietern wie Anthropic und Amazon. Es abstrahiert die Infrastruktur vollständig und rechnet ausschließlich nach der Token-Nutzung ab.
Was AWS Bedrock gut macht
Versteckte Kompromisse bei AWS Bedrock
Diese Kompromisse überraschen Teams oft, wenn die Arbeitslast vom Experimentieren zum dauerhaften Einsatz in der Produktion übergeht.
Fazit: Bedrock optimiert für Geschwindigkeit und Einfachheit, nicht für langfristige Kosteneffizienz oder Kontrolle.
5. AWS SageMaker: Verwaltete ML-Infrastruktur
SageMaker bietet eine umfassende Suite für das Training, die Optimierung und den Einsatz von Modellen für maschinelles Lernen. Im Gegensatz zu Bedrock werden die Infrastrukturoptionen direkt den Benutzern zur Verfügung gestellt.
Was AWS Sagemaker gut macht
Nachteile von AWS Sagemaker
Fazit: SageMaker bietet Kontrolle, allerdings auf Kosten einer einfachen Bedienung.
6. Databricks: Die Lakehouse ML-Plattform
Databricks betrachtet KI aus einer datenorientierten Perspektive und integriert ML- und GenAI-Funktionen in seine Lakehouse-Architektur.
Was Databricks gut macht
Wo Databricks zu kurz kommt
Fazit: Databricks zeichnet sich durch Data Engineering aus, nicht durch KI-Serving.
Der rote Faden: Gateways ohne Governance
Quer Kong gegen LitelLM, Portkey und sogar Bedrock, das gleiche Problem taucht auf: Sie verwalten Anfragen, keine KI-Systeme.
Bei Gateways und Managed Services tritt immer wieder ein Problem auf: Die meisten Tools konzentrieren sich auf Anfragen, nicht auf Systeme.
Sie beantworten Fragen wie:
Sie haben Probleme mit:
Dies sind Bedenken auf Infrastrukturebene.
TrueFoundry belegt eine andere Ebene im Stapel. Anstatt sich ausschließlich auf API-Routing oder verwaltete Dienste zu konzentrieren, behandelt es KI-Workloads — Modelle, Agenten, Dienste und Jobs — als erstklassige Infrastrukturobjekte. Dadurch verlagert sich die Verantwortung vom Anwendungscode auf die Plattform selbst.
Das TrueFoundry AI Gateway basiert auf den folgenden Kernprinzipien:
Das bedeutet, dass das AI Gateway eine Komponente eines größeren Systems ist, sodass Unternehmen ihre KI-Anwendungsfälle nahtlos skalieren können.
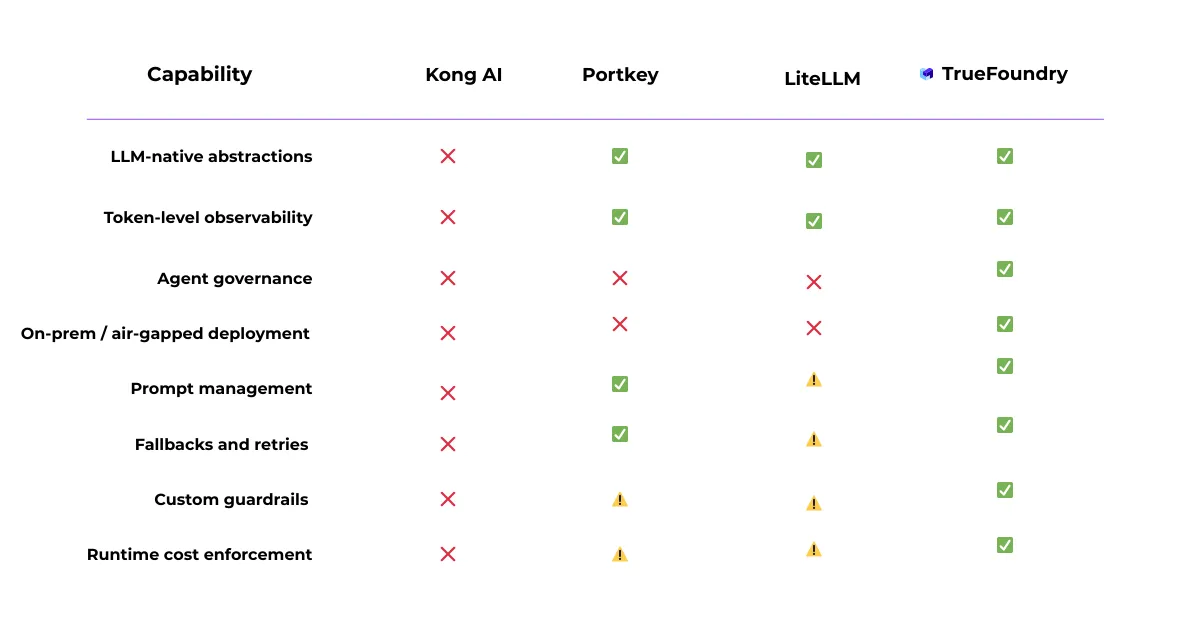
Das TrueFoundry AI Gateway wird entscheidend, wenn die KI-Nutzung über isolierte Anwendungen hinausgeht und zu einer gemeinsamen, produktionskritischen Funktion wird. In dieser Phase geht es bei den Herausforderungen oft weniger um einzelne Modellanforderungen als vielmehr um die betriebliche Konsistenz zwischen Teams und Umgebungen.
So unterscheidet sich das AI Gateway von TrueFoundry von anderen Lösungen:
Viele KI-Tools konzentrieren sich auf Probleme auf Anforderungsebene wie Routing, Wiederholungsversuche und grundlegende Beobachtbarkeit. In frühen Phasen ist dies in der Regel ausreichend.
Mit zunehmender Nutzung verhalten sich Modelle und Agenten jedoch zunehmend wie langlebige Dienste. Teams benötigen klarere Zuständigkeiten, ein klareres Lebenszyklusmanagement und klarere betriebliche Grenzen. TrueFoundry wurde entwickelt, um KI-Workloads — Modelle, Services und Jobs — als Infrastrukturkomponenten mit definierten Bereitstellungs- und Laufzeitmerkmalen zu verwalten.
In vielen Stacks werden Zugriffskontrollen und Nutzungsrichtlinien auf Anwendungs- oder SDK-Ebene konfiguriert. Im Laufe der Zeit kann dies zu Inkonsistenzen führen, da die Anzahl der Dienste zunimmt.
TrueFoundry wendet Kontrollen auf Umgebungsebene an und trennt standardmäßig Entwicklung, Staging und Produktion. Auf dieser Ebene definierte Richtlinien gelten einheitlich für alle in einer Umgebung bereitgestellten Workloads, wodurch die Abhängigkeit von der Konfiguration pro Anwendung reduziert wird.
Die KI-Kosten steigen häufig eher aufgrund von Parallelität, Wiederholungsversuchen oder Hintergrundworkloads als aufgrund einzelner Anfragen. TrueFoundry begegnet diesem Problem, indem es Beschränkungen für Parallelität, Durchsatz und Ressourcenverbrauch während der Ausführung durchsetzt.
Auf diese Weise können Unternehmen gemeinsam genutzte Infrastrukturen besser vorhersagbar verwalten, wenn die Nutzung steigt.
Metriken auf Token-Ebene sind zwar nützlich, erklären aber das Systemverhalten in der Produktion nicht vollständig. TrueFoundry korreliert Signale auf Anforderungsebene mit Infrastrukturkennzahlen wie der CPU-/GPU-Auslastung und dem Verhalten bei der automatischen Skalierung und hilft Teams so, Leistungs- und Kostentreiber im Kontext zu verstehen.
Einige Unternehmen unterliegen Einschränkungen, die private Netzwerke, lokale Bereitstellungen oder eine strikte Datenresidenz erfordern. TrueFoundry wurde für den Betrieb in diesen Umgebungen entwickelt, sodass KI-Workloads mithilfe derselben Infrastrukturstandards gesteuert werden können, die an anderer Stelle im Unternehmen gelten.
Fazit
Die aktuelle KI-Plattformlandschaft spiegelt die Geschwindigkeit wider, mit der sich die generative KI weiterentwickelt hat. Viele Tools befassen sich mit echten Problemen — Routing, Modellzugriff, Beobachtbarkeit oder Training —, aber sie tun dies von unterschiedlichen Ausgangspunkten aus. Daher deckt natürlich keine einzelne Kategorie die gesamten betrieblichen Anforderungen ab, die entstehen, wenn KI produktionskritisch wird.
TrueFoundry bietet den größten Nutzen, wenn KI-Workloads mit derselben Disziplin wie andere Produktionssysteme betrieben werden müssen — umgebungsübergreifend, unter gemeinsamen Richtlinien und mit vorhersehbarem Ressourcenverhalten.
Unternehmen, die Anbieter vergleichen, beginnen häufig mit der Suche nach bestes LLM-Gateway, aber das eigentliche Unterscheidungsmerkmal liegt darin, wie gut die Plattform KI-Systeme in großem Maßstab steuert. Es ist wichtig zu verstehen, wo die einzelnen Plattformen hinpassen und wo ihre Entwurfsannahmen zu versagen beginnen. Die richtige Wahl hängt weniger von einzelnen Funktionen ab, sondern mehr davon, wie sich die KI-Nutzung eines Unternehmens im Laufe der Zeit entwickeln wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




