Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
9,9
Lösung von SEO-Datenengpässen mit Autonomous Agents und TrueFoundry
Published: April 22, 2026
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Verarbeitet mehr als 350 RPS auf nur 1 vCPU — kein Tuning erforderlich
Es ist Montagmorgen. Ihr SEO-Lead starrt auf drei verschiedene Browser-Tabs: Google Search Console (GSC), Looker Studio und eine Tabelle, die abstürzt, wenn Sie zu schnell scrollen. Sie exportieren manuell Tausende von Zeilen mit Abfragedaten, versuchen, einen VLOOKUP mit der Leistung der letzten Woche abzugleichen, und wenden subjektive Filter an, um zu entscheiden, wofür das Entwicklungsteam als Nächstes Inhalte erstellen soll.
Dies ist das „Last Mile“ -Problem der Datenanalyse. Wir verfügen über ausgeklügelte Erfassungstools, aber die eigentliche Synthese — die Entscheidungsebene — beruht auf fragilem menschlichem Klebstoff.
Bei TrueFoundry stellten wir fest, dass unser Growth Engineering-Workflow durch diese manuelle Aggregation blockiert wurde. Wir waren nicht durch Daten eingeschränkt, sondern durch den Durchsatz menschlicher Analysen. Um das zu beheben, haben wir kein weiteres Dashboard-Tool gekauft. Wir haben das gebaut Schlüsselwort-Automatisierungsagent, ein System, das SEO-Metriken als technischen Stream und nicht als statischen Bericht behandelt und auf dem TrueFoundry AI Gateway und dem Model Context Protocol (MCP) basiert.
Der technische Wandel: Von der statischen Analyse zu adaptiven Pipelines
Der Standardansatz für SEO-Operationen ist Umfragebasiert und manuell: Menschen rufen regelmäßig Daten ab, wenden fest codierte Regeln an (z. B. „Volumen > 100") und raten, ob sie relevant sind.
Wir wechselten zu einem Ereignisgesteuert und probabilistisch modell:
Deterministische Bewertung: Mathematik behandelt die offensichtlichen Metriken (CTR-Deltas, Rangdistanz).
Probabilistische Filterung: LLMs fügen einen Geschäftskontext hinzu (z. B. zu wissen, dass „AI Gateway“ für uns relevant ist, „Gateway Computer Drivers“ jedoch nicht).
Werkzeugabstraktion (MCP): Auf externe Datenquellen (Ahrefs, Google Trends) wird über standardisierte Protokolle zugegriffen, nicht über fragile API-Wrapper.
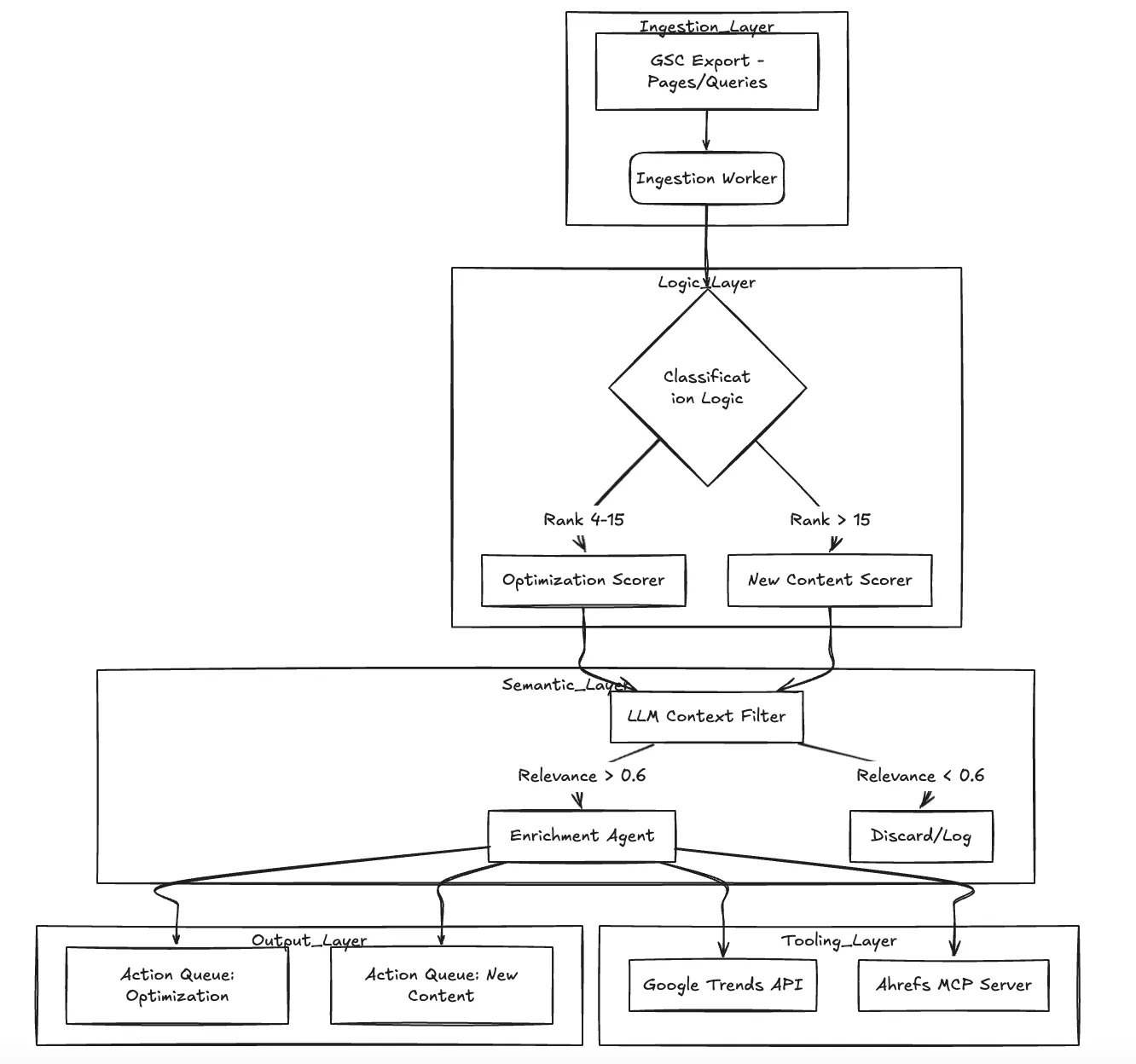
Tiefer Einblick in die Architektur
Das System arbeitet als gerichteter azyklischer Graph (DAG) von Verarbeitungsschritten. Es „fasst“ Daten nicht nur zusammen, sondern filtert und bereichert sie aktiv.
Kernkomponenten:
Worker bei Einnahme: Analysiert CSV-Rohexporte von GSC (Pages and Queries).
Bewertungscontroller: Wendet die mathematische Logik an. Zur Optimierung verwenden wir eine entfernungsbasierte Zerfallsfunktion: $Score =\ log (1 + Impressionen)\ times (1 - CTR)\ times (\ max (0, 20 - position)) $.
Relevanzagent (LLM): Fungiert als semantischer Torwächter. Es bewertet Schlüsselwörter anhand des Domänenkontextes von TrueFoundry (Kubernetes, LLM Ops, Entwicklerplattformen), um Störungen herauszufiltern.
Mitarbeiter im Bereich Anreicherung: Ruft Trenddaten und (in V2) externe Schwierigkeitsmetriken über MCP ab.
Infrastruktur und TrueFoundry: Gateway und MCP
Die Implementierung dieser Architektur bringt zwei große Herausforderungen für verteilte Systeme mit sich: Ratenbegrenzung und Integration von Tools.
Wenn Sie einfach 5.000 Keywords durchgehen und eine LLM-API für die Relevanzbewertung aufrufen, stoßen Sie sofort auf Ratenlimits. Wenn du Ahrefs API-Aufrufe in deinen Agenten festcodierst, stellst du eine enge Kopplung her, die bei jeder Änderung einer API-Version unterbrochen wird.
Wir nutzten die TrueFoundry-Plattform um beide zu lösen:
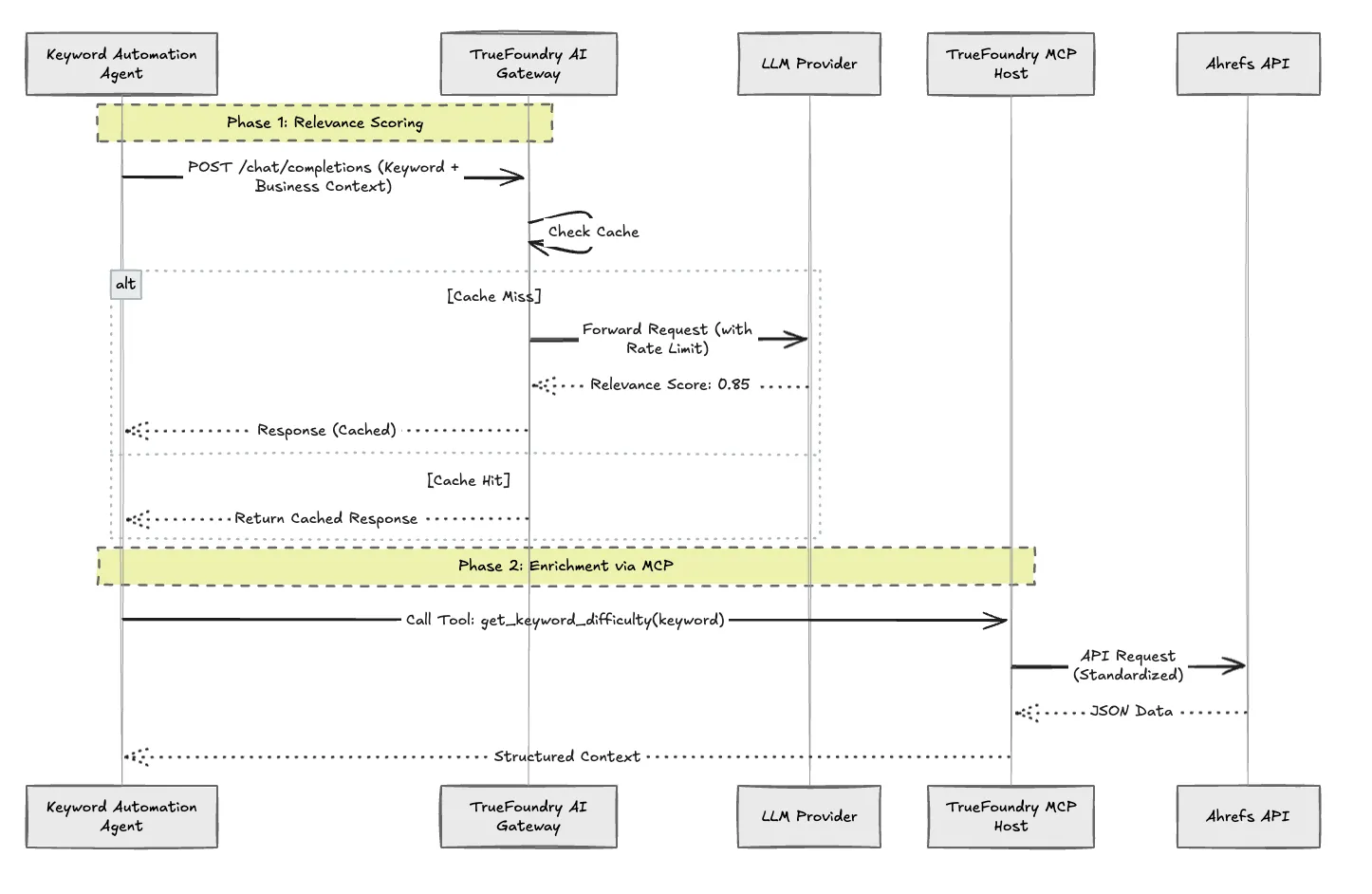
TrueFoundry KI-Gateway: Wir leiten alle LLM-Anrufe (zur Relevanzbewertung und Briefgenerierung) über das Gateway weiter. Dies bietet:
Zentralisierte Ratenbegrenzung: Wir legen ein Budget für Anfragen pro Minute auf Gateway-Ebene fest, um unsere nachgelagerten Anbieter zu schützen.
Zwischenspeichern: Wenn wir das Keyword „LLM Observability“ letzte Woche bereits bewertet haben, liefert das Gateway das gecachte Urteil aus, wodurch Latenz und Kosten auf Null reduziert werden.
Modell-Routing: Wir können das zugrunde liegende Modell (z. B. von GPT-4 auf ein billigeres, schnelleres Modell wie Gemini Flash) für die Klassifizierungsaufgabe austauschen, ohne eine Zeile Anwendungscode zu ändern.
Modellkontextprotokoll (MCP): Anstatt benutzerdefinierte Funktionen für Ahrefs zu schreiben, setzen wir eine ein Ahrefs MCP Server auf TrueFoundry. Der Agent fragt den MCP-Server einfach nach Site-Explorer-Metriken oder nach Keyword-Schwierigkeiten ab. Der MCP-Server kümmert sich um die Authentifizierung und die API-Spezifikationen. Dies standardisiert die Art und Weise, wie unsere Agenten mit externen Tools kommunizieren.
Codeschnipsel
Vergleich: Standard Scripting mit TrueFoundry Accelerator
Die folgende Tabelle zeigt, warum wir von lokalen Python-Skripten zu einer verwalteten Architektur übergegangen sind.
Dimension
Standard Python Script Approach
TrueFoundry Accelerator Approach
Resilience
Fragile. If the GSC API times out or the script hits an LLM rate limit, the entire process crashes. Requires manual restarts.
High. TrueFoundry Gateway handles retries and exponential backoff. Process isolation ensures one failed batch doesn't kill the pipeline.
Security
Low. API keys for OpenAI and Ahrefs are often stored in local .env files or hardcoded.
Enterprise. Keys are managed in TrueFoundry Secrets. Agents access tools via authenticated MCP endpoints, never touching raw credentials.
Scalability
Vertical. Limited by the local machine's memory when processing large CSVs combined with trend data.
Horizontal. Workers run as microservices on Kubernetes. We can parallelize the scoring of 10,000 keywords across multiple pods.
Maintenance
High. Every time Ahrefs changes an API endpoint, the main application code must be refactored.
Low. Tool logic is isolated in the MCP Server. The core agent logic remains untouched during external API updates.
Umgang mit Randfällen und Zuverlässigkeit
In einer Produktionsumgebung sind Daten selten sauber. Wir haben spezielle Leitplanken eingeführt, um die Zuverlässigkeit zu gewährleisten:
Das „Halluzination“ -Tor: LLMs können zu selbstbewusst sein. Wir haben ein Logikgatter implementiert, bei dem, wenn Relevanz = falsch UND Konfidenz < 0,6 ist, das Schlüsselwort als Rauschen weggelassen wird. Wenn Relevanz = wahr, aber Konfidenz < 0,5 ist, wird es für eine menschliche Überprüfung und nicht für die automatische Verarbeitung markiert.
Trenddivergenz: Ein häufiger Fehlermodus bei der Suchmaschinenoptimierung ist die Optimierung für ein sterbendes Keyword. Unser Enrichment Worker überprüft Google Trends. Wenn Impression_Trend unverändert ist, Market_Trend jedoch steigt, wird eine „verpasste Gelegenheit“ angezeigt. Wenn Impression_Trend steigt, Market_Trend jedoch Null ist, weist dies auf eine wahrscheinliche Bot-Anomalie oder einen saisonalen Anstieg hin und verhindert so vergebliche Mühe.
Fazit
Durch die Umstellung des SEO-Workflows von manuellen Tabellenkalkulationen auf einen agentischen Workflow auf TrueFoundry haben wir die Zeit bis zur Gewinnung von Erkenntnissen von Tagen auf Minuten reduziert. Noch wichtiger ist, dass wir die Logik von der Infrastruktur entkoppelt haben. Das TrueFoundry AI Gateway verwaltet die „Kosten der Kognition“ (LLM-Aufrufe), während MCP die „Komplexität der Integration“ (externe Tools) verwaltet.
Diese Architektur beweist, dass interne Tools keine hackigen Skripte sein müssen. Sie können robuste, skalierbare Systeme sein, die den tatsächlichen Geschäftswert steigern.
Setzen Sie diesen Accelerator aus der TrueFoundry Library noch heute ein, um Ihre eigenen Workflows zur Datenanreicherung zu standardisieren.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last






























.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




