

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: May 28, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
KI-Systeme sind keine passiven Werkzeuge mehr. Sie werden zunehmend agentisch - Autonomer Betrieb über Workflows, APIs und sensible Unternehmensdaten hinweg. In herkömmlichen Systemen wurde der Speicherort der Daten dadurch definiert, wo die Daten gespeichert wurden. Sobald sich Datenbanken und Speicher in den zugelassenen Regionen befanden, galt die Einhaltung der Vorschriften als erledigt.
Agentic AI durchbricht dieses Modell. Jede Interaktion generiert neue Datenoberflächen — Eingabeaufforderungen, Agentenspeicher, Protokolle, Traces und transiente Inferenzdaten, die zur Laufzeit verarbeitet und beobachtet werden, oft regionsübergreifend, auch wenn nichts persistent ist.
Aus diesem Grund ist die Datenresidenz kein Compliance-Kontrollkästchen mehr. Es ist ein Kernanliegen der Infrastruktur wird jetzt auf Vorstandsebene erörtert. Die Frage, die Unternehmen beantworten müssen, ist einfach: Wohin bewegen sich KI-generierte Daten zur Laufzeit und wer kontrolliert diese Pfade?
In Wahre Gießerei, die Datenresidenz wird durchgesetzt bei KI-Gateway, wo Inferenz, Agenten und Tools zusammenlaufen. Der Wohnsitz wird behandelt als Systemeigenschaft, das bei normalem Betrieb, Ausfällen und Skalierung durchgesetzt wird. In diesem Blog wird erklärt, wie die Datenresidenz im TrueFoundry AI Gateway definiert, durchgesetzt und verifiziert wird.
Die Datenresidenz war einfacher, wenn Anwendungen vorhersehbare Datenpfade hatten. Anfragen gingen von Benutzern über Dienste bis hin zu Datenbanken weiter, in der Regel innerhalb einer einzigen Region, und die Compliance-Kontrollen waren weitgehend statisch.
KI-Systeme brechen dieses Modell zur Laufzeit.
In modernen KI-Architekturen Die Datenbewegung ist dynamisch und entscheidungsorientiert, nicht behoben. Eine einzelne Benutzeranfrage kann mehrere Ausführungspfade auslösen, die alle vom AI Gateway orchestriert werden. An dieser Stelle wird die Datenresidenz fragil.
Zur Laufzeit kann ein AI-Gateway:
Jede dieser Entscheidungen kann dazu führen implizite Datenbewegung, oft ohne dass die Anwendung davon Kenntnis hat.
Die häufigsten Fehler bei der Datenresidenz in KI-Systemen treten auf:
Entscheidend ist, dass diese Fehler auch dann auftreten, wenn:
Diese Ausfälle haben alle eines gemeinsam: Sie treten auf bei Laufzeit, gesteuert durch Routing, Wiederholungsversuche, Agentenausführung und Protokollierungsverhalten.
Das AI Gateway ist die einzige Ebene, die:
Aus diesem Grund kann die Datenresidenz in KI-Systemen nicht allein durch die Bereitstellungskonfiguration garantiert werden. Sie muss durchgesetzt werden am AI Gateway, wo die Ausführungspfade in Echtzeit festgelegt werden.
Auf Plattformen wie Wahre Gießerei, der Wohnsitz wird behandelt als harte Laufzeitbeschränkung, keine Best-Effort-Präferenz, die sicherstellt, dass kein Ausführungspfad, einschließlich Ausfallszenarien, regionale Grenzen verletzen kann.
Agentische KI-Systeme bieten nicht nur benutzen Daten, sie Generieren Sie kontinuierlich neue Datenoberflächen zur Laufzeit. Diese Oberflächen gab es in herkömmlichen Anwendungen nicht, und sie ändern grundlegend, was die Datenresidenz berücksichtigen muss.
In KI-Systemen Die Datenresidenz ist nicht mehr auf Daten im Ruhezustand beschränkt. Es erstreckt sich auf alle Daten, die während der Inferenz und Agentenausführung erzeugt, verarbeitet oder beobachtet werden, auch wenn diese Daten nur kurz existieren.
Die wichtigsten dieser neuen Datenverbindlichkeiten sind oft die am wenigsten sichtbaren.
Inferenzanfragen tragen Eingabeaufforderungen und Antworten über das AI Gateway, das häufig proprietäre Logik, Kundendaten oder sensiblen internen Kontext enthält. Im Gegensatz zu herkömmlichen APIs liegen diese Daten in freier Form vor und sind nicht desinfiziert, weshalb sie ein besonders hohes Risiko darstellen.
Einführung von Agentic Workflows persistenter Kontext und Erinnerung interaktionsübergreifend. Wenn dieser Status außerhalb zugelassener Regionen verarbeitet oder wiedergegeben wird, liegt ein Verstoß gegen den Wohnsitz vor, selbst wenn einzelne Inferenzanrufe den Anforderungen entsprechen.
KI-Systeme generieren auch Logs, Traces, Einbettungen und Ausführungsmetadaten das kann vertrauliche Informationen verschlüsseln. Wenn Observability-Pipelines diese Daten regionsübergreifend exportieren, kommt es im Hintergrund zu Verstößen.
Entscheidend ist, dass Daten nicht gespeichert werden müssen, um nicht konform zu sein. Transiente Inferenzdaten, das nur für Millisekunden im Speicher verarbeitet wird, fällt immer noch unter die Wohnsitzerfordernisse, wenn es eine Zuständigkeitsgrenze überschreitet.
Herkömmliche Residenzkontrollen wurden für statische Systeme entwickelt, nicht für dynamisches Routing, Wiederholungen, Failover und agentengesteuerte Ausführung. In KI-Systemen muss die Residenzpflicht durchgesetzt werden zur Laufzeit, wo diese Datenpfade erstellt werden.
Auf Plattformen wie Wahre Gießerei, diese Durchsetzung erfolgt am KI-Gateway, wo Eingabeaufforderungen, Agentenkontext, Wiederholungsversuche und Telemetrie zusammenlaufen, sodass der Wohnsitz zu einer Systemeigenschaft und nicht zu einer Annahme wird.
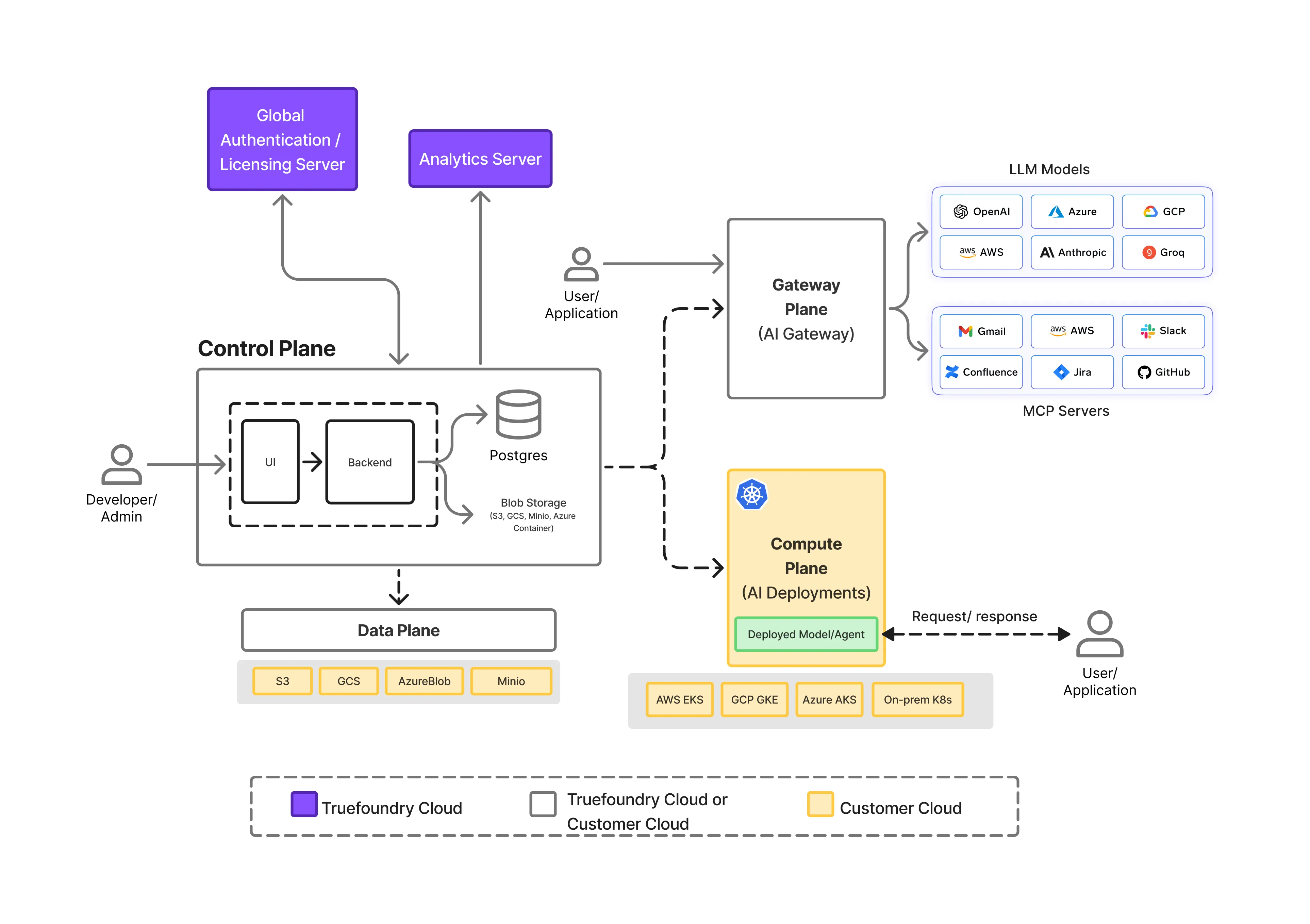
Die Durchsetzung der Datenresidenz in KI-Systemen erfordert mehr als eine regionale Bereitstellung. Es erfordert klare Trennung der Zuständigkeiten über den gesamten KI-Stack hinweg, sodass Ausführungs-, Steuerungs- und Datenpfade unabhängig voneinander gesteuert werden können.
TrueFoundry basiert auf einem geteilte Ebene Architektur das macht das möglich.
Auf hoher Ebene besteht die Plattform aus drei verschiedenen Ebenen:
Diese Trennung ist grundlegend dafür, wie die Datenresidenz zur Laufzeit zuverlässig durchgesetzt wird.
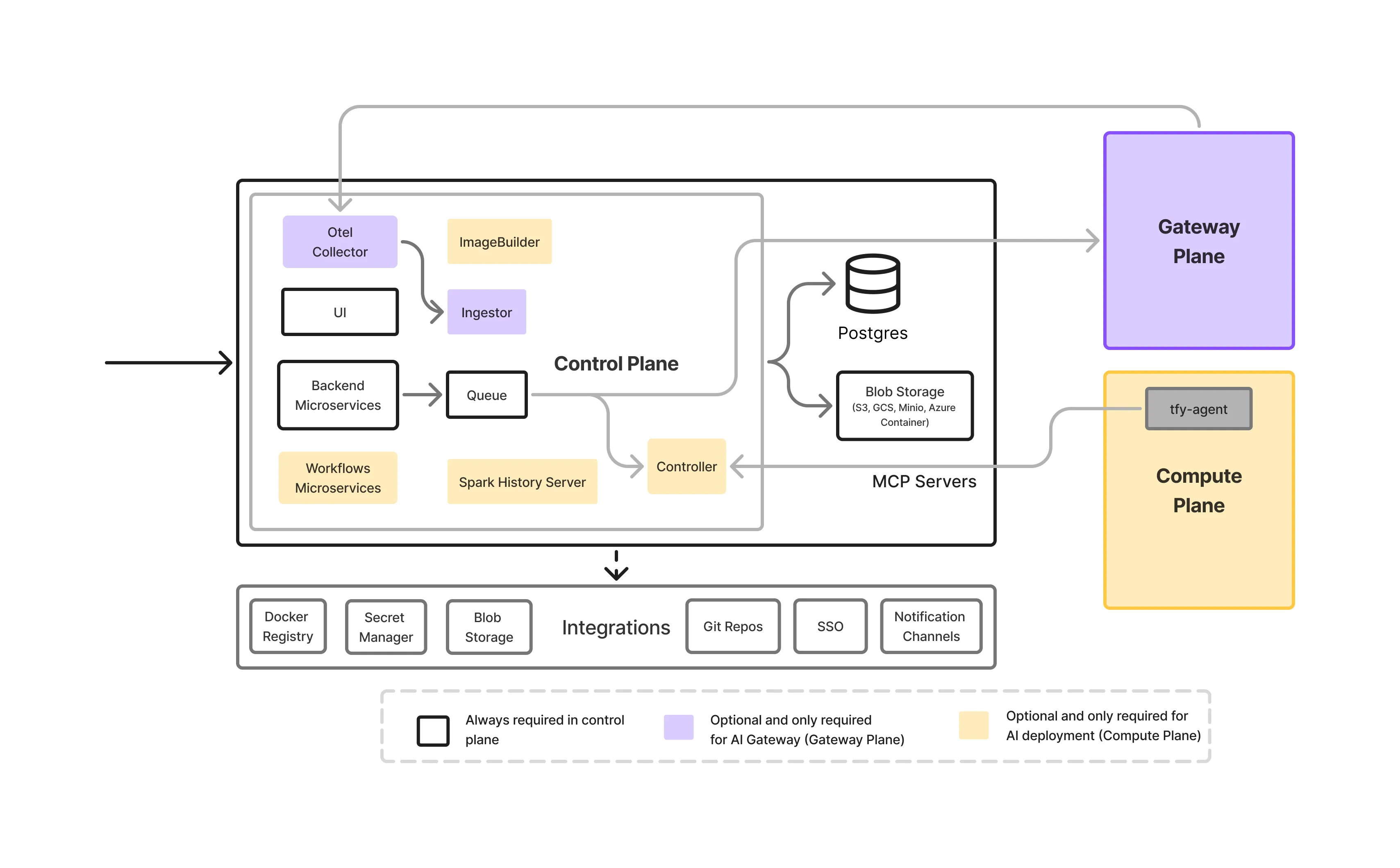
Das Steuerungsebene ist die Orchestrierungsebene der TrueFoundry-Plattform. Sie ist verantwortlich für:
Entscheidend ist die Kontrollebene verarbeitet keinen Inferenzverkehr und führt keine Workloads aus. Es definiert was sollte passieren, nicht wo Daten zur Laufzeit fließen.
Für Unternehmen mit strengen Compliance-Anforderungen unterstützt TrueFoundry beides:
Auf diese Weise können Unternehmen das richtige Gleichgewicht zwischen betrieblicher Einfachheit und Souveränitätsanforderungen wählen, ohne die nachgelagerte Funktionsweise der Wohnsitzdurchsetzung zu ändern.
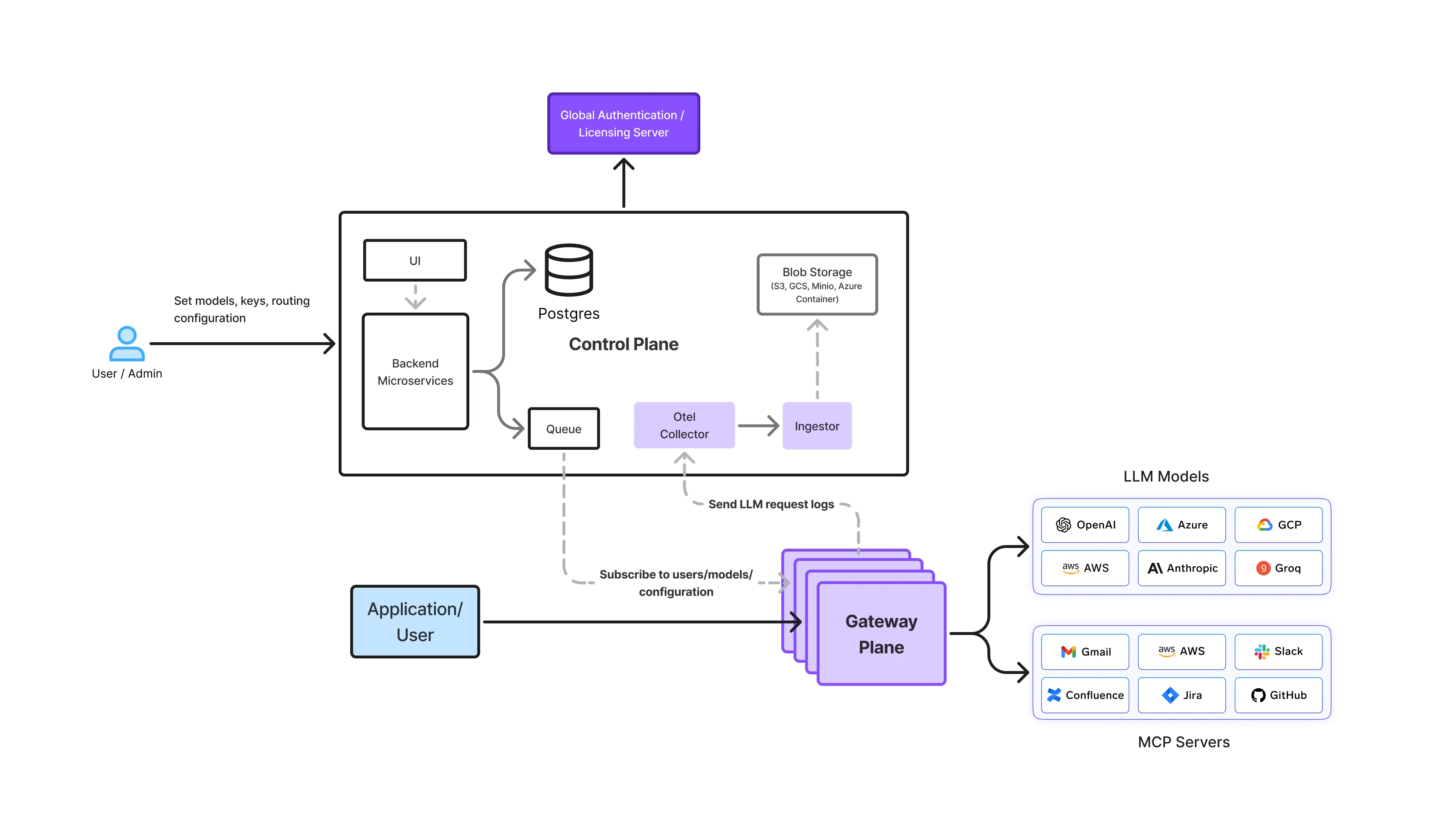
Das Gateway-Flugzeug ist der Ort, an dem die Datenresidenz aktiv durchgesetzt wird.
TrueFoundry AI Gateways befinden sich zwischen Anwendungen und allen Modellanbietern und agieren als:
Jede Inferenzanforderung, jeder Wiederholungsversuch, jedes Failover, jeder Agentenaufruf und jedes Observability-Ereignis durchläuft das Gateway. Dadurch erhält es einen vollständigen Überblick über:
Aus diesem Grund ist die Gateway-Ebene die einzige Ebene, die in der Lage ist, die Datenresidenz als harte Einschränkung durchzusetzen.
Wenn eine Anfrage innerhalb der konfigurierten Wohnsitzgrenzen nicht erfüllt werden kann, wird das Gateway schlägt fehl, die Anfrage wird geschlossen anstatt es stillschweigend an eine nicht konforme Region weiterzuleiten.
Dies ist der entscheidende Unterschied zwischen Durchsetzung der Laufzeit und Best-Effort-Konfiguration.
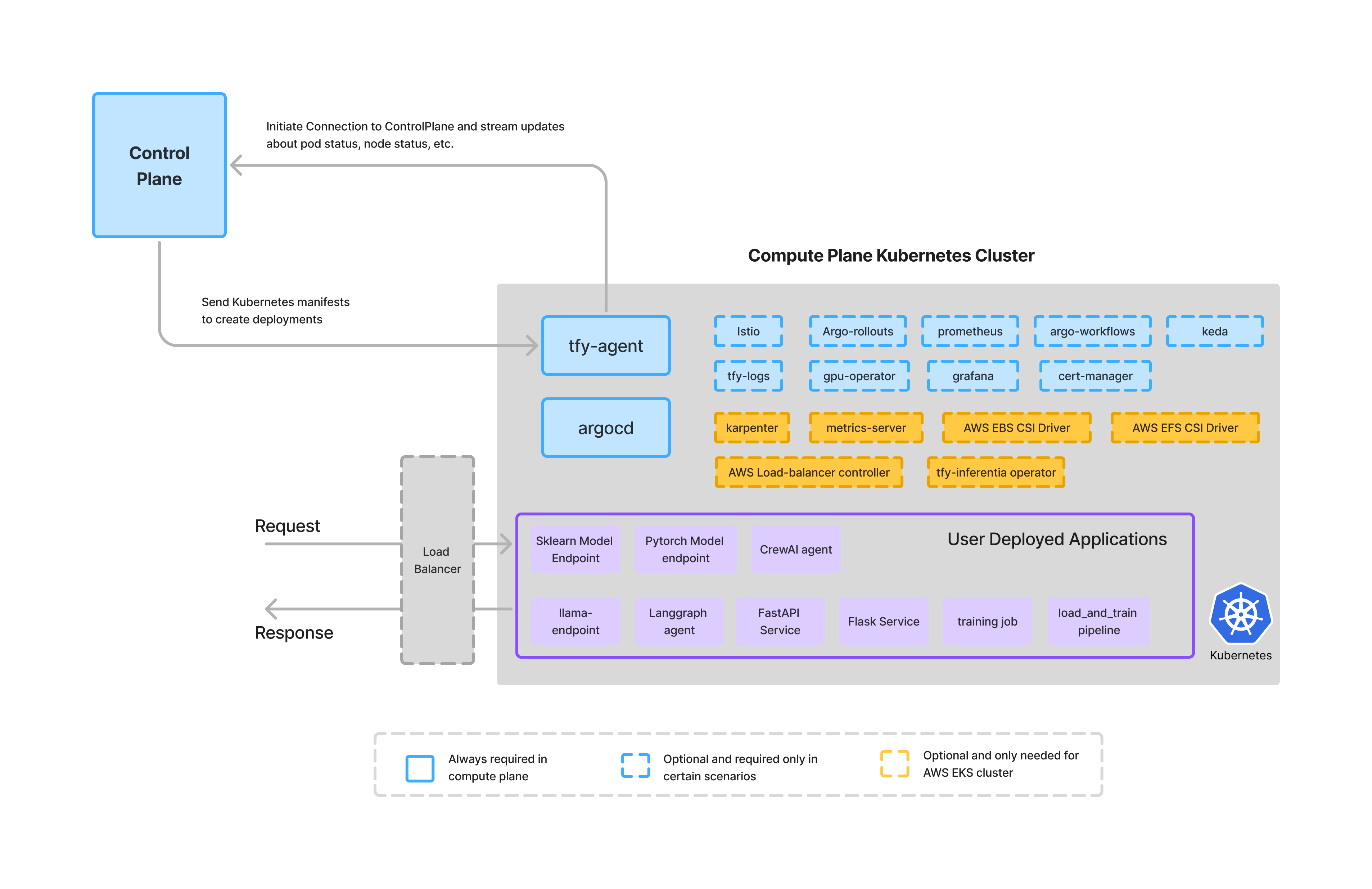
Das Ebene berechnen ist der Ort, an dem Anwendungen, Agenten und Workloads tatsächlich ausgeführt werden.
In TrueFoundry ist die Rechenebene:
Dieses Design stellt sicher, dass:
TrueFoundry führt keine Kundenworkloads auf gemeinsam genutzten Computern aus. Stattdessen lässt es sich in die vorhandenen Cluster des Kunden integrieren oder hilft bei der Bereitstellung neuer Cluster, sodass die Ausführung innerhalb der Vertrauensgrenze des Unternehmens erfolgt.
Diese Trennung der Ebenen ermöglicht es TrueFoundry, die Datenresidenz durchzusetzen. ohne Kompromisse:
Da die Durchsetzung am Gateway erfolgt, wo Routing, Wiederholungsversuche, Agenten und Protokolle zusammenlaufen, gilt die Datenresidenz auch unter folgenden Bedingungen:
Dadurch wird die Datenresidenz zu einer Systemeigenschaft, keine Annahme, die an Einsatzdiagramme gebunden ist.
Die Datenresidenz in KI-Systemen ist kein einziger Schalter — sie muss überall durchgesetzt werden Ausführung, Routing und Speicherung. In Wahre Gießerei, wird dies durch drei sich ergänzende Durchsetzungsmodi erreicht, die zusammen den gesamten Lebenszyklus von KI-Daten abdecken.
Jeder Modus befasst sich mit einer anderen Klasse von Aufenthaltsrisiken und kann je nach Unternehmensanforderungen unabhängig oder in Kombination verwendet werden.
Für Organisationen mit den strengsten Wohnsitz- und Compliance-Anforderungen ermöglicht TrueFoundry ein Bereitstellungsmodell, bei dem Daten verlassen niemals die Umgebung des Kunden.
In diesem Modus:
Dies gilt für beide:
Dieser Modus stellt sicher, dass die Ausführung und die Datenpfade vollständig innerhalb der vom Kunden kontrollierten Infrastruktur verbleiben, und bietet so größtmögliche Residenzgarantien und vereinfacht behördliche Prüfungen.
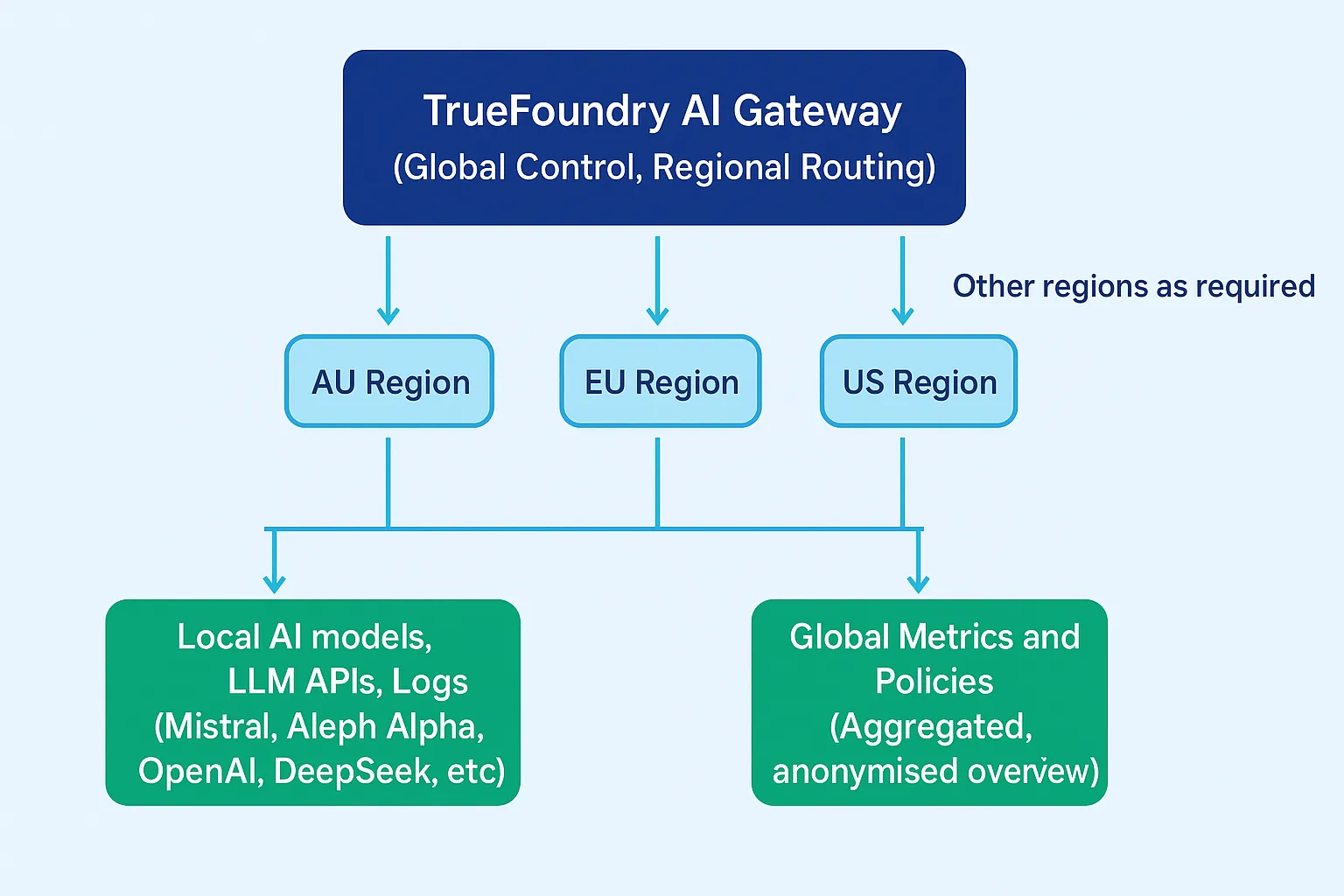
Viele Unternehmen müssen global agieren und gleichzeitig sicherstellen, dass Daten für eine bestimmte Geografie überschreiten niemals Zuständigkeitsgrenzen.
TrueFoundry erzwingt dies durch regionsspezifische AI Gateway-Bereitstellungen:
Anwendungen wählen explizit aus, welcher regionale Gateway-Endpunkt verwendet werden soll. Das macht die Datenresidenz zu:
Wenn für eine Anfrage kein residenzkonformer Ausführungspfad existiert, wird das Gateway schlägt fehl, die Anfrage wird geschlossen anstatt es in eine andere Region weiterzuleiten. Dadurch wird sichergestellt, dass Verfügbarkeitsmechanismen niemals die Absicht zur Einhaltung der Vorschriften außer Kraft setzen.
Inferenz und Ausführung sind nur ein Teil der Geschichte von Data Residency. Protokolle, Traces, Aufforderungen und Telemetrie enthalten oft ebenso vertrauliche Informationen und müssen denselben Aufenthaltsregeln folgen.
TrueFoundry ermöglicht es Unternehmen, die Ansiedlung auf der Speicherebene durchzusetzen, indem sie:
Dadurch ist es möglich:
Da diese Speicheroptionen direkt in das AI-Gateway und die SDK-Konfiguration integriert sind, unterliegen Observability-Daten denselben Residenzgarantien wie der Inferenzverkehr.
Jeder Erzwingungsmodus löst ein anderes Problem:
Zusammen stellen sie sicher, dass die Datenresidenz durchgesetzt wird:
Dieser mehrschichtige Ansatz ermöglicht es TrueFoundry, die Datenresidenz von einem Best-Effort-Konfiguration in ein überprüfbare, zur Laufzeit erzwungene Systemeigenschaft.
In Wahre Gießerei, die Datenresidenz wird durchgesetzt durch mehrere, explizite Ebenen innerhalb des AI Gateways, die jeweils eine andere Klasse von Laufzeitrisiken adressieren.
Diese Ebenen arbeiten zusammen, um sicherzustellen, dass die Aufenthaltsgarantien unter realen Bedingungen gelten.
In KI-Systemen gelten Datenresidenzgarantien nur, wenn sie durchgesetzt werden zur Laufzeit, auf jedem Ausführungspfad, nicht nur im stationären Betrieb. In Wahre Gießerei, das AI Gateway ist der Durchsetzungspunkt, an dem Routing-Entscheidungen, Wiederholungsversuche, Agentenausführung und Beobachtbarkeit zusammentreffen.
Die folgenden Mechanismen erklären wie die Datenresidenz deterministisch durchgesetzt wird im TrueFoundry AI Gateway.
Modelle in TrueFoundry sind registriert bei explizite Regionenaffinität. Das AI Gateway bewertet Wohnsitzbeschränkungen vor dem Routing jede Anfrage und wählt nur Modellendpunkte aus, die für die zulässige Region des Workloads in Frage kommen.
Dies verhindert:
Weil der Wohnsitz behandelt wird als harte Routing-Beschränkung, keine Präferenz, nicht konforme Modelle werden niemals in Betracht gezogen — auch wenn sie verfügbar oder schneller sind.
Wiederholungen und Failoverpfade sind die häufigsten Ursachen für stille Verstöße gegen den Datenspeicherort in KI-Systemen.
Das AI Gateway von TrueFoundry erzwingt:
Dadurch wird sichergestellt, dass Verfügbarkeitsmechanismen niemals die Absicht zur Einhaltung von Vorschriften außer Kraft setzen. Wenn kein konformer Pfad verfügbar ist, schlägt das System explizit fehl, anstatt Daten regionsübergreifend weiterzuleiten.
Bei agentischen Workloads muss die Datenresidenz überall konsistent bleiben Modellinferenz und nachgelagerter Werkzeugaufruf.
TrueFoundry erzwingt:
Dadurch entfällt ein üblicher Fehlermodus, in dem die Inferenz zwar konform bleibt, Agenten jedoch Daten indirekt über Tools oder MCP-Server in anderen Regionen preisgeben.
Observability-Pipelines werden in Data Residency-Designs häufig übersehen, obwohl sie häufig Folgendes enthalten hochsensible Daten.
Das AI Gateway von TrueFoundry stellt sicher, dass:
Dies schließt eine der hartnäckigsten Residenzlücken in KI-Systemen, in denen Inferenzen konform sind, Logs und Traces jedoch nicht.
Diese Durchsetzungsmechanismen gelten einheitlich für:
Weil Durchsetzung passiert vor der Hinrichtung, Data Residency wird zu einem überprüfbare Systemeigenschaft, keine Best-Effort-Konfiguration, die an die Platzierung der Infrastruktur gebunden ist.
Die meisten Verstöße gegen die Datenresidenz in KI-Systemen werden nicht durch offensichtliche Fehlkonfigurationen verursacht. Sie entstehen aus Randfälle und Ausnahmepfade die selten getestet werden, bis etwas schief geht.
Im Folgenden sind die häufigsten Ausfallszenarien aufgeführt, mit denen Unternehmen konfrontiert sind, und wie TrueFoundry KI-Gateway wurde entwickelt, um sie zu verhindern.
Was passiert in vielen Systemen
Ein regionaler Modellendpunkt ist nicht mehr verfügbar. Das AI Gateway versucht es automatisch erneut oder führt einen Failover zum nächsten verfügbaren Endpunkt durch, häufig in einer anderen Region.
Unter dem Gesichtspunkt der Verfügbarkeit sieht das nach Erfolg aus.
Aus Compliance-Sicht handelt es sich um einen stillen Verstoß.
Wie TrueFoundry das verhindert
Dies stellt sicher, dass Verfügbarkeitsmechanismen setzen niemals die Residenzpolitik außer Kraft.
Was passiert in vielen Systemen
Einige Modelle werden regional bereitgestellt, während andere (häufig Backups oder neuere Modelle) global gehostet werden. Durch Routing-Richtlinien werden unbeabsichtigt Modelle ausgewählt, die nicht in der Region ansässig sind.
Wie TrueFoundry das verhindert
Dadurch sind Residenzgarantien widerstandsfähig gegenüber Modellfluktuation und Experimenten.
Was passiert in vielen Systemen
Die Inferenz wird lokal ausgeführt, aber die Agenten rufen Tools oder MCP-Server auf, die in anderen Regionen eingesetzt werden, wodurch eine indirekte Datenverlagerung entsteht.
Wie TrueFoundry das verhindert
Dadurch bleibt der Wohnsitz bei allen Inferenzen konsistent. und nachgelagerte Ausführung.
Was passiert in vielen Systemen
Eingabeaufforderungen, Antworten und Traces werden häufig standardmäßig an zentrale Protokollierungs- oder Überwachungsdienste außerhalb der Region exportiert.
Wie TrueFoundry das verhindert
Dies schließt eine der am häufigsten übersehenen Compliance-Lücken in KI-Systemen.
Wohnsitzgarantien sind nur dann sinnvoll, wenn sie verifiziert und nachgewiesen. TrueFoundry ermöglicht es Unternehmen, die Datenresidenz durch Sichtbarkeit und Überprüfbarkeit der Laufzeit, keine nachträglichen Annahmen.
Das AI Gateway bietet Einblick in:
Dadurch können die Teams bestätigen, dass jeder Ausführungspfad blieb konform.
Für Konformitäts- und Sicherheitsüberprüfungen stellt TrueFoundry Folgendes zur Verfügung:
Das macht es möglich Nachweis des Wohnsitzes bei Audits, anstatt sich allein auf Architekturdiagramme zu verlassen.
Ein entscheidender Vorteil der Durchsetzung auf Gateway-Ebene ist die Testbarkeit.
Unternehmen können:
Dies macht den Wohnsitz von einer statischen Anforderung zu einer kontinuierlich überprüfbare Systemeigenschaft.
In modernen KI-Systemen kann die Datenresidenz nicht allein durch Bereitstellungsentscheidungen gewährleistet werden. Dynamisches Routing, Wiederholungsversuche, Agenten-Workflows und Observability-Pipelines führen alle Ausführungspfade ein, bei denen Daten im Hintergrund regionale Grenzen überschreiten können.
Das KI-Gateway ist die einzige Ebene mit ausreichendem Kontext, um dies zu verhindern. Sie sieht jede Inferenzanforderung, jeden Wiederholungsversuch, jede Agentenaktion und jede vom System ausgegebene Spur. Wenn der Wohnsitz hier nicht durchgesetzt wird, kann er auch an keiner anderen Stelle einheitlich durchgesetzt werden.
In Wahre Gießerei, Datenresidenz wird behandelt als Laufzeit-Systemeigenschaft. Die Ausführungswege sind durch das Design begrenzt, Ausnahmefälle scheitern und die Durchsetzung ist beobachtbar und überprüfbar. Dadurch sind Residenzgarantien nicht nur im stationären Zustand, sondern auch bei Ausfall, Skalierung und Veränderung widerstandsfähig.
Für Unternehmen, die KI in regulierten oder multiregionalen Umgebungen einsetzen, ist diese Unterscheidung wichtig. Die Datenresidenz ist kein Kontrollkästchen mehr, sondern eine architektonische Verpflichtung. Und das AI Gateway ist der Ort, an dem dieses Engagement real wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




