Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
9,9
Kostenaspekte bei der Verwendung eines KI-Gateways: Optimierung der KI-Ausgaben von Unternehmen
Die Verwaltung der Kosten für die Nutzung großer Sprachmodelle (LLM) ist für Unternehmen, die KI in großem Maßstab einsetzen, zu einem geschäftskritischen Anliegen geworden. Im Gegensatz zu herkömmlicher Software verwenden LLM-basierte Dienste häufig Token-basierte Preisgestaltung — Anbieter berechnen pro Eingabe-/Ausgabe-Token — was es schwierig macht, die Budgetierung vorherzusagen oder zu kontrollieren. Zu dieser Komplexität tragen mehrere Faktoren bei:
Verschiedene Modellpreise: Jeder LLM-Anbieter (OpenAI, Anthropic, Cohere usw.) oder jede Modellgröße hat seinen eigenen Tarif pro Token, wobei größere Modelle (z. B. GPT-4-Klasse) pro Token deutlich mehr kosten als kleinere.
Unvorhersehbare Nutzungsmuster: Der Token-Verbrauch kann je nach Benutzer, Funktion oder Workflow stark variieren — eine Funktion verwendet möglicherweise stillschweigend zehnmal mehr Tokens als eine andere, und die Nutzung kann aufgrund des Benutzerverhaltens unerwartet ansteigen.
Dynamische Prompt-Pipelines: Fortgeschrittene Anwendungsfälle wie Retrieval-Augmented Generation (RAG), Agenten, die Tools verwenden, oder mehrstufige Ketten können versehentlich die Größe und die Antwortlänge der Eingabeaufforderung erhöhen, wodurch sich die pro Abfrage erforderlichen Tokens (und Kosten) vervielfachen.
Das Ergebnis ist, dass Teams ohne angemessene Transparenz und Kontrollen oft erst erkennen, wie schnell sich die Kosten ansammeln, bis die Rechnung eintrifft. Es ist nicht ungewöhnlich, dass Ausgaben Ballon unerwartet, was die Projektbudgets bedroht und Skalierungsbemühungen behindert. Ein kürzlich veröffentlichter Gartner-Bericht warnt auch davor, dass Mangelnde Kostentransparenz und mangelnde Steuerung können schnell zu Budgetüberschreitungen führen in KI-Initiativen. Kurz gesagt, da Unternehmen LLMs in ihre Produkte integrieren, ist die Kontrolle der Nutzungskosten ebenso wichtig wie die Modellgenauigkeit oder die Verfügbarkeit. Die tokenbasierte Preisgestaltung führt zu Unsicherheiten, die den ROI senken können, wenn sie nicht aktiv verwaltet werden.
Hier kommt das Konzept eines KI-Gateway kommt rein. Ein KI-Gateway entwickelt sich zu einer Schlüsselkomponente, um die Kontrolle über die Nutzung und Ausgaben von LLM zurückzugewinnen. Bevor wir uns mit Kostentreibern und Lösungen befassen, sollten wir definieren, was ein KI-Gateway ist und wie es die Kosten beeinflusst.
Was ist ein KI-Gateway? (Und wie wirkt sich das auf die Kosten aus)
Ein KI-Gateway ist eine spezialisierte Middleware-Ebene, die alle Interaktionen zwischen Ihren Anwendungen und mehreren KI-Modellen oder Anbietern verwaltet. Stellen Sie sich das als ein API-Gateway vor, das speziell für KI-Workloads entwickelt wurde — eines, das modellspezifische Nuancen wie Token-basierte Abrechnung, Inferenzlatenz und dynamisches Routing versteht. Es bietet einen einheitlichen Endpunkt für alle KI-Anfragen und leitet den Datenverkehr auf intelligente Weise an das richtige Modell-Backend weiter, basierend auf Richtlinien für Kosten, Leistung oder Verfügbarkeit.
Das Hinzufügen eines Gateways ist zwar mit einem geringen Aufwand wie Hosting-Kosten und Konfigurationsaufwand verbunden, der jedoch durch die damit verbundene Kontrolle und Transparenz aufgewogen wird. Indem jede Anfrage über eine einzige Ebene weitergeleitet wird, können Unternehmen die Nutzung überwachen, Budgets durchsetzen und in Echtzeit Entscheidungen darüber treffen, welches Modell den besten Kompromiss zwischen Preis und Leistung bietet. Gartner beschreibt KI-Gateways als „intelligente Verkehrssteuerungen“, die Unternehmen dabei unterstützen, die Modellnutzung anwendungsübergreifend zu evaluieren und zu optimieren.
Das KI-Gateway von TrueFoundry fungiert als diese Kontrollebene, die den Zugriff modell- und anbieterübergreifend vereinheitlicht und gleichzeitig Unternehmensrichtlinien wie Zugriffskontrolle, Kostenkontrolle, Caching und Beobachtbarkeit durchsetzt. Dadurch wird der Einsatz von KI von einem unvorhersehbaren Kostenfaktor in ein verwaltetes, messbares und optimierbares System umgewandelt.
Die wichtigsten Kostentreiber bei der LLM-Nutzung
Bei der Verwendung großer Sprachmodelle in der Produktion bestimmen mehrere Schlüsselfaktoren die Gesamtbetriebskosten. Das Verständnis dieser Faktoren ist der erste Schritt zur Verwaltung und Reduzierung der LLM-Kosten:
Modellwahl und Größe: Die Wahl des Modells wirkt sich übermäßig auf die Kosten aus. Größere, fortschrittlichere Modelle (mit einer höheren Anzahl von Parametern oder mehr Funktionen) haben in der Regel viel höhere Kosten pro Token. Beispielsweise können GPT-4- oder andere „Argumentationsmodelle“ pro Token eine Größenordnung mehr kosten als kleinere Modelle. Die Verwendung eines Top-Tier-Modells für jede einzelne Anfrage — einschließlich trivialer Abfragen — wird die Kosten unnötig in die Höhe treiben.
Token-Verwendung (Prompt- und Antwortlänge): Die Anzahl der in Aufforderungen gesendeten Token sowie die in den Antworten generierten Token bestimmen direkt die Abrechnung. Lange Konversationen oder Dokumente, besonders lange Kontextfenster oder nicht optimierte Eingabeaufforderungen, die irrelevante Informationen enthalten, sorgen für die Anzahl der Tokens. Funktionen wie die Aufforderung, das Modell ausführlich zu formulieren, oder die Rückgabe ausführlicher Erklärungen können die Nutzung exponentiell erhöhen. Wirksam schnelles Engineering Wenn Sie die Eingabeaufforderungen kurz und die Ergebnisse fokussieren, können Sie die Kosten erheblich senken. Jedes Token ist wichtig, wenn Sie millionenfach Bruchteile eines Cents pro Token zahlen.
Verkehrsaufkommen und Verkehrsmuster: Wie oft und in welchem Umfang KI-Funktionen genutzt werden, wirkt sich natürlich auf die Kosten aus — aber es geht nicht nur um das Gesamtvolumen, sondern auch um das Muster. Starker, unvorhersehbarer Traffic kann zu Spitzenzeiten Kosten verursachen, die das monatliche Budget sprengen. Die Variabilität zwischen Benutzern oder Funktionen bedeutet, dass einige Power-User oder ein internes Tool heimlich den Großteil der Token verbrauchen könnten. Plötzliche Nutzungsspitzen (z. B. eine neue Funktion, die sich viral verbreitet) können zu ungeplanten Rechnungen führen, wenn sie nicht gedrosselt werden. Eine Erhöhung der Nutzung ohne Kostenkontrolle ist ein Rezept für Überschreitungen.
Nutzung mehrerer Modelle und Anbieterauswahl: Viele Teams verwenden eine Mischung von Modellen — zum Beispiel ein Open-Source-Modell für einige Aufgaben und eine proprietäre API für andere oder verschiedene Anbieter für verschiedene Sprachen. Jedes Modell/jeder Anbieter kann unterschiedliche Preiseinheiten haben (einige berechnen pro 1000 Token, andere pro Anfrage usw.) und möglicherweise zusätzliche Gebühren. Wenn ein Team außerdem „sicherheitshalber“ immer das teuerste Modell verwendet, verpasst es Sparmöglichkeiten. Auswahl der Für jede Aufgabe das richtige Modell ist ein wichtiger Kostenhebel: Für eine einfache Abfrage ist kein teures 175B-Parameter-Modell erforderlich, obwohl ein kleineres (und billigeres) Modell ausreichen würde. Umgekehrt könnten einige komplexe Aufgaben die Kosten eines überlegenen Modells rechtfertigen. Die Strategie (oder deren Fehlen), den Verkehr an Modelle weiterzuleiten, ist ein großer Kostentreiber.
Infrastruktur und Gemeinkosten: Es fallen auch Kosten an, die über die Gebühren pro Token hinausgehen. Wenn Sie Open-Source-LLMs selbst hosten, um API-Kosten zu vermeiden, zahlen Sie für die Infrastruktur — GPU-Server, Speicher, Wartung und MLOps-Aufwand. In einer Analyse wurde es kurz und bündig ausgedrückt: „Open-Source-LLMs sind nicht kostenlos — sie verlagern lediglich die Kosten von der Lizenzierung auf Technik, Infrastruktur, Wartung und strategische Risiken.“ Selbst wenn Sie Cloud-APIs verwenden, benötigen Sie möglicherweise zusätzliche Infrastruktur, um Anfragen zu bearbeiten (z. B. den Betrieb eines internen Dienstes oder Gateways, Vektordatenbanken für RAG usw.), was Cloud-Computing-Kosten verursacht. Integrationsaufwand und Entwicklungszeit sind „versteckte“ Kosten, die sich schleichen können.
Lizenz- oder Abonnementgebühren: Bei einigen Modellen und Diensten fallen zusätzlich zur Nutzung feste Gebühren an. Beispielsweise ist für bestimmte KI-APIs für Unternehmen ein monatliches Abonnement oder eine monatliche Verpflichtung erforderlich. Selbst Open-Source-Modelle können Lizenzbeschränkungen haben, die Unternehmen zu kostenpflichtigen Optionen drängen. Wenn Sie ein proprietäres Modell für die Serverplattform verwenden, können Lizenzkosten anfallen. Diese Gebühren müssen bei den Gesamtbetriebskosten für die Nutzung eines bestimmten Modells berücksichtigt werden. Manchmal erfordert ein „billigeres Modell pro Token“ möglicherweise eine teure Lizenz, wodurch Einsparungen zunichte gemacht werden.
Integrations- und Ineffizienzkosten: Schließlich kann die Art und Weise, wie Sie KI in Ihre Systeme integrieren, zu Kostenineffizienzen führen. Redundante Aufrufe, fehlendes Caching oder schlechtes Lastmanagement können zur Verschwendung von Tokens führen. Frühe Anwender in Unternehmen stellten fest, dass die Verwendung eines Standard-API-Gateways oder einer Ad-hoc-Integration zu folgenden Ergebnissen führte erhebliche Kostenüberschreitungen — in einigen Fällen 300% über den ursprünglichen Prognosen — weil die Tools keine KI-spezifischen Optimierungen wie das Zwischenspeichern ähnlicher Eingabeaufforderungen oder den Lastenausgleich zwischen Modellen berücksichtigten. Der Aufbau und die Wartung Ihrer eigenen Infrastruktur für den Zugriff und die Überwachung mehrerer Modelle sind mit Kosten verbunden. Wenn jedes Team KI-APIs unabhängig voneinander aufruft, entgehen Ihnen Skaleneffekte und eine zentrale Überwachung, was häufig zu höheren Gesamtausgaben als nötig führt (z. B. wenn mehrere Teams dasselbe Modell mit derselben Anfrage verwenden und zweimal zahlen).
Das Verständnis dieser Kostentreiber zeigt, warum es nicht ausreicht, Teams einfach Zugriff auf eine LLM-API zu gewähren — eine unkontrollierte Nutzung über viele Apps und Benutzer hinweg wird fast unweigerlich zu Überraschungen führen. Je geschäftskritischer und umfassender der Einsatz von KI ist, desto größer ist der Bedarf an Governance.Hier stellen KI-Gateways ihren Wert unter Beweis: Sie zielen direkt auf diese Kostentreiber ab und bieten Mechanismen, um die Kosten einzudämmen, ohne Abstriche bei Leistung oder Zuverlässigkeit zu machen.
Verwaltung und Reduzierung der LLM-Kosten mit einem KI-Gateway
Ein KI-Gateway bietet eine Reihe von Tools und intelligenten Strategien, um die oben genannten Kostentreiber zu bekämpfen. Es dient als zentrale Ebene der Kostenkontrolle für alle KI-Anwendungen. Laut Gartner können KI-Gateways das Risiko mindern von „steigende KI-Kosten aufgrund schlechter Regierungsführung“ indem sie als Kontrollpunkt zwischen KI-Verbrauchern und Anbietern fungiert. Das AI Gateway von TrueFoundry bietet beispielsweise zahlreiche Funktionen zur Überwachung und Optimierung der Kosten. Lassen Sie uns eingehend untersuchen, wie ein KI-Gateway bei der Verwaltung und Reduzierung der LLM-Kosten hilft:
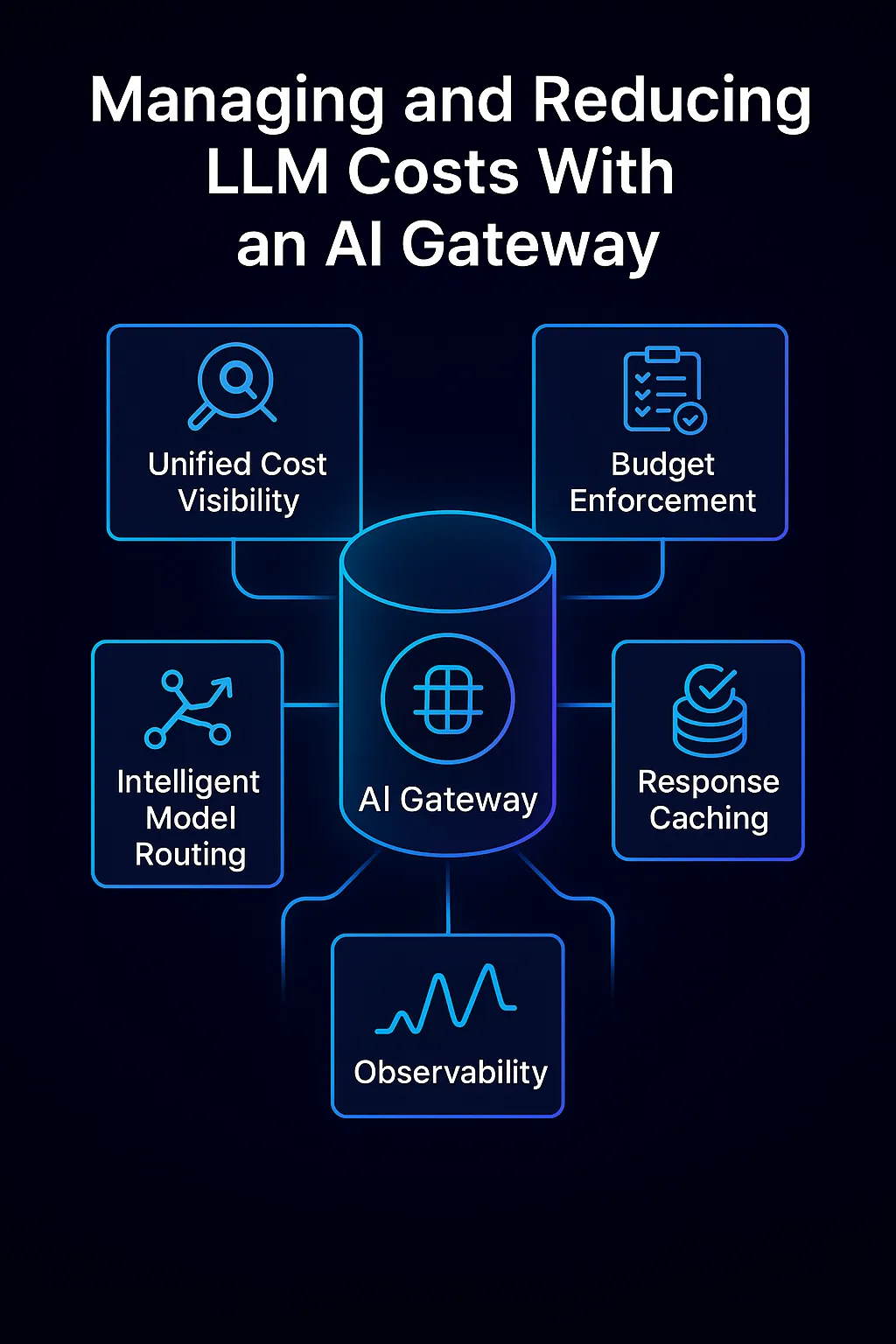
Einheitliche Kostentransparenz: Alle Anfragen werden über das Gateway geleitet, das protokolliert detaillierte Nutzungsmetriken für jeden Anruf — verwendetes Modell, verbrauchte Token, Latenz, Benutzer-/Team-Zuordnung usw. Dadurch erhalten Sie in Echtzeit einen detaillierten Überblick darüber, wohin Ihre Token-Dollars fließen. Führungskräfte können endlich beantworten: „Welche Anwendungen oder Anwendungsfälle machen den größten Teil unserer OpenAI-Rechnung aus?“ mit Präzision. Diese appübergreifende Sichtbarkeit ist fast unmöglich zu erreichen, wenn Teams Models direkt anrufen. Mit einem Gateway erhalten Sie eine eine einzige Quelle der Wahrheit Dashboard für KI-Nutzung und Ausgaben. Diese Transparenz ermöglicht eine Charback-/Showback-Abrechnung (Zuweisung der Kosten an die Abteilungen), was wiederum die Rechenschaftspflicht fördert.
Haushaltsvollstreckung und Leitplanken: Sichtbarkeit allein reicht nicht aus — das Gateway erzwingt auch Politik um unkontrollierbaren Gebrauch zu verhindern. Sie können definieren Tarifgrenzen und Kontingente (z. B. nicht mehr als N Token oder $X, die pro Tag für einen bestimmten Benutzer oder eine bestimmte Funktion ausgegeben werden) und das Gateway lehnt Anfragen ab oder drosselt sie. Dadurch wird sichergestellt, dass ein fehlerhaftes Skript oder eine unerwartete Nutzungsspitze das Budget nicht sprengen. Sie können auch Folgendes einrichten Budgetwarnungen oder automatische Abschaltung Regeln: Wenn die monatliche Nutzung eines Teams einen bestimmten Schwellenwert überschreitet, kann das Gateway Benachrichtigungen senden oder weitere Anrufe vorübergehend unterbrechen, bis sie genehmigt sind, wodurch überraschende Rechnungen vermieden werden. Darüber hinaus ermöglichen Gateways Zugriffskontrolle und Modellbeschränkungen — Sie könnten beispielsweise zulassen, dass nur teure Modelle wie GPT-4 für bestimmte kritische Workflows verwendet werden, während weniger kritische Anwendungen auf billigere Modelle beschränkt sind. Eine weitere Art von Schutzmaßnahmen ist das Filtern von Eingabeaufforderungen: das Blockieren von Prompts, die extrem lange Ausgaben oder anderweitig kostenineffiziente Anfragen auslösen würden. Durch die zentrale Anwendung dieser Verwaltungsregeln setzen Unternehmen strenge Grenzen für das Kostenrisiko.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Intelligentes Modell-Routing: Die vielleicht größte Kosteneinsparung ist die Fähigkeit des Gateways leitet jede Anfrage dynamisch an das optimale Modell oder den optimalen Anbieter weiter basierend auf dem Kontext. Anstatt einer Standardlösung kann das Gateway Faktoren wie die Komplexität der Abfrage, die erforderliche Genauigkeit, die Latenz und die Kosten auswerten und dann auswählen (oder sogar automatisch wechseln) das Modell, das die Anforderungen am besten erfüllt und die niedrigsten Kosten bietet. Beispielsweise könnte eine einfache Sachfrage durch ein kleineres, billigeres Modell ohne nennenswerten Qualitätsunterschied beantwortet werden, wohingegen eine komplexe Aufgabe einem leistungsfähigeren Modell zugewiesen wird. Diese Art von Modellauswahl in Echtzeit senkt die Kosten, indem Überforderung vermieden wird. Das AI Gateway von TrueFoundry implementiert dies über Regeln für intelligentes Routing und Lastenausgleich: Sie können es so konfigurieren, dass Abfragen standardmäßig an ein Open-Source-Modell wie Mistral gehen, um Geschwindigkeit und niedrige Kosten zu gewährleisten. Wenn die Aufforderung jedoch komplex aussieht oder die Zuverlässigkeit des kleineren Modells gering ist, leitet das Gateway diese Anfrage an ein größeres Modell wie GPT-4 weiter. Bei Hunderttausenden von Anfragen kann dieses adaptive Routing zu massiven Einsparungen führen und gleichzeitig die Gesamtqualität aufrechterhalten. Es überwindet die falsche Dichotomie, entweder ein leistungsstarkes oder ein kostengünstiges Modell zu wählen — Sie können habe beides indem sie alle dort einsetzen, wo sie Sinn machen.
Zwischenspeichern von Antworten: Eine weitere Kostenoptimierung ist Zwischenspeichern wiederholte oder häufige KI-Antworten. Wenn mehrere Benutzer dieselbe Frage stellen oder Ihr System wiederholt identische Abfragen stellt, kann ein AI-Gateway eine zwischengespeicherte Antwort zurückgeben, anstatt das Modell erneut aufzurufen und diese Token vollständig zu speichern. Sogar das Zwischenspeichern von Teilergebnissen (wie teure Zwischenschritte) kann helfen. Dies ist besonders nützlich für Backend-Aufgaben oder Apps, bei denen dieselbe Aufforderung häufig verwendet wird. Caching reduziert nicht nur die Kosten, sondern verbessert auch die Latenz für diese Abfragen. True Foundry's Gateway unterstützt sowohl einfaches Caching als auch fortgeschrittenere semantisches Caching — wobei semantisch ähnliche Eingabeaufforderungen als Cache-Treffer behandelt werden können. (Semantisches Caching muss mit Bedacht verwendet werden, da kleine Unterschiede bei den Eingabeaufforderungen die Antwort verändern können. In den richtigen Szenarien kann es jedoch die Cache-Trefferquoten erhöhen und die Kosten senken.) Studien haben gezeigt, dass semantische Caching-Mechanismen die LLM-API-Kosten um bis zu senken können 70% in Anwendungsfällen in Unternehmen. In der Praxis bietet selbst ein einfacherer Cache für identische Anfragen ein erhebliches Kostenpolster für Apps mit hohem Volumen
Beobachtbarkeit und Erkennung von Anomalien: Da das Gateway alle Anfragen überwacht, kann es auch erkennen anomale Nutzungsmuster das könnte auf einen Bug oder Missbrauch hindeuten. Wenn in dieser Stunde beispielsweise das Fünffache der Token-Nutzung als in der letzten Stunde angezeigt wird oder eine Anwendung plötzlich beginnt, das Modell mit großen Aufforderungen zu spammen, werden das Gateway (und seine integrierten Dashboards) diese Anomalie aufdecken. Früherkennung bedeutet, dass Sie eingreifen können, bevor das Budget aufgebraucht wird. Die Beobachtbarkeit trägt auch zur Zuverlässigkeit bei: Sie verfolgt Fehlerraten und Latenzen und hilft so, kostenbedingte Verlangsamungen von Modellproblemen zu unterscheiden. Einige Gateways, wie die von TrueFoundry, lassen sich in Tools wie OpenTelemetry integrieren, sodass Sie LLM-Nutzungsmetriken mit Ihrem gesamten Monitoring-Stack zusammenführen können. Diese ganzheitliche Beobachtbarkeit stellt sicher, dass Sie die Kosten aufrechterhalten und Leistungsziele. Es ermöglicht auch interne Rückbuchungen — da die Nutzung zentral protokolliert wird, können Sie Teams für ihren Teil der KI-Rechnung zur Rechenschaft ziehen und ihnen so Anreize bieten, effizient zu arbeiten.
Wie ein KI-Gateway die LLM-Kosten verwaltet und reduziert, indem es einheitliche Transparenz, Budgetdurchsetzung, intelligentes Modellrouting, Caching und Beobachtbarkeit in einer Steuerungsebene kombiniert.
All diese Funktionen sorgen zusammen dafür, dass Kostendisziplin ohne ständige manuelle Überwachung durchgesetzt wird. Durch die Verwendung eines KI-Gateways Das Kostenmanagement wird proaktiv und automatisiert: du hast Kosten Grenzen an Ort und Stelle, damit Sie nicht zu viel ausgeben können, Sie haben Einblicke in Echtzeit um die Nutzungsmuster anzupassen, und Sie haben automatisierte Optimierungen (Routing, Caching) Ineffizienzen im Handumdrehen ausgleichen. Dadurch wird aus einer möglicherweise undurchsichtigen, außer Kontrolle geratenen Kostenstelle ein kontrollierter Versorgungsbetrieb.
Das AI Gateway von TrueFoundry ist ein Beispiel für diese Kostenkontrollen in der Praxis. Es bietet integrierte Dashboards zur Kostenverfolgung, Konfiguration der Budgetpolitik, Routing mit mehreren Modellen Regeln und Caching-Mechanismen, alles konfigurierbar über eine unternehmensfreundliche Oberfläche. Das Ergebnis ist, dass Unternehmen mehr KI-Anwendungsfälle nutzen können ohne die Angst vor unvorhersehbaren Rechnungen. Natürlich bringt der Einsatz eines solchen Gateways einige Überlegungen zu Leistung und Architektur mit sich, auf die wir als Nächstes eingehen werden.
Abwägen von Kosten, Genauigkeit, Latenz und Komplexität
Jede Strategie zur aggressiven Kostenreduzierung muss gegen andere technische und geschäftliche Anforderungen abgewogen werden. Kompromisse sind unvermeidlich. Im Zusammenhang mit LLM-Implementierungen sind Kosten, Genauigkeit (oder Qualität der Ergebnisse), Latenz (Reaktionsgeschwindigkeit) und architektonische Komplexität die wichtigsten Aspekte, die es abzuwägen gilt. Ein KI-Gateway hilft dabei, diese Kompromisse zu bewältigen, aber es ist wichtig, sie zu verstehen, um die richtigen Richtlinien festzulegen:
Kosten im Vergleich zu Genauigkeit: Qualitativ hochwertigere Modelle bedeuten in der Regel höhere Kosten, aber nicht jede Aufgabe erfordert Überlegungen auf GPT-4-Ebene. Ein kleineres 7B-Modell kann die Frage „Was ist die Hauptstadt von Frankreich?“ beantworten so genau wie ein Vorzeigemodell, aber keine komplexe Rechtsfrage. Der Schlüssel ist, das zu benutzen Routing-Intelligenz des Gateways um zu entscheiden, wann erstklassige Genauigkeit den Preis wert ist. Leiten Sie alltägliche Aufgaben kleineren Modellen zu und reservieren Sie High-End-Modelle für komplexe Überlegungen. Im Laufe der Zeit helfen Analysen dabei, diese Schwellenwerte zu verfeinern und das Gleichgewicht zwischen akzeptabler Genauigkeit und erheblichen Kosteneinsparungen herzustellen.
Kosten im Vergleich zu Latenz: Billigere Modelle liefern oft auch schnellere Antworten, insbesondere wenn sie lokal gehostet werden. Naives Routing mit mehreren Modellen kann jedoch zu Latenz führen, wenn das System ein Modell ausprobiert und dann auf ein anderes zurückgreift. Das Gateway von TrueFoundry mildert dies mit latenzbasiertes und lastbewusstes Routingund stellt sicher, dass Anfragen ohne unnötige Sprünge an das am schnellsten realisierbare Modell weitergeleitet werden. Die Architektur verursacht nur wenige Millisekunden an Overhead (~3—4 ms pro Anfrage) — was im Vergleich zu Modellinferenzzeiten vernachlässigbar ist, sodass Teams an Effizienz gewinnen, ohne die Benutzererfahrung zu beeinträchtigen.
Kosten und architektonische Komplexität: Das Hinzufügen eines KI-Gateways führt zu einer zusätzlichen Infrastrukturebene, bietet aber auch Transparenz, Leitplanken und Zuverlässigkeit, die bei Einzelmodell-Setups nicht fehlen.Für kleine Teams oder Prototypen können direkte Modellanrufe ausreichen. Aber wenn die Nutzung immer größer wird, werden zentralisiertes Routing, Caching und Kostenkontrolle unverzichtbar.
Letztlich ist das Ausbalancieren dieser Faktoren eine fortlaufende Übung. Es empfiehlt sich, die Auswirkungen Ihrer Maßnahmen zur Kosteneinsparung auf die Qualität der Modellausgabe und die Benutzererfahrung kontinuierlich zu überwachen (wozu die Beobachtbarkeit des Gateways beiträgt) und die Regler (Routing-Regeln, Cache-Einstellungen usw.) entsprechend anzupassen. Das Schöne am AI-Gateway-Ansatz ist, dass Sie haben Diese Knöpfe zum Umdrehen — Sie sind nicht auf ein einheitliches Modell festgelegt. Sie können die Ausgaben in bestimmten Bereichen erhöhen oder verringern und gleichzeitig das beibehalten, was für Ihre Bewerbung am wichtigsten ist, sei es die Reaktionszeit oder die Antwortgenauigkeit.
Best Practices für die LLM-Kostenoptimierung mithilfe eines Gateways
Um den größtmöglichen Nutzen aus einem KI-Gateway zu ziehen, sollten Unternehmen die Technologie mit soliden Nutzungsstrategien kombinieren. Hier sind einige praktische Best Practices zur Optimierung der LLM-Kosten bei gleichbleibender Leistung:
1. Optimieren Sie Eingabeaufforderungen und Ausgaben. Schneiden Sie unnötige Tokens ab und konzentrieren Sie sich auf die Eingabeaufforderungen. Bei zu langen oder ausführlichen Anweisungen werden Tokens verschwendet. Strukturierte Formate — wie Aufzählungspunkte oder JSON-Schemas — sorgen dafür, dass die Antworten präzise und vorhersehbar sind. Überprüfen und kürzen Sie häufig vorkommende Eingabeaufforderungen, die jedem Anruf vorangestellt werden. Diese „Null-Kosten-Optimierung“ senkt direkt die Ausgaben.
2. Verwenden Sie Routing für hybride Modelle. Setzen Sie auf eine abgestufte Modellstrategie: Leiten Sie einfache Abfragen oder Abfragen mit geringem Einsatz an kleinere, günstigere Modelle weiter, komplexe an Premium-Modelle. Viele Teams folgen einem 90/10-Muster — 90% des Traffics an schnelle, kostengünstige Modelle; 10% an qualitativ hochwertige Modelle für kritische Aufgaben. TrueFoundry Gateway automatisiert dies durch regelbasiertes oder ML-basiertes Routing und stellt so sicher, dass Sie nie zu viel für Funktionen bezahlen, die Sie nicht benötigen.
3. Anrufe stapeln und parallelisieren. Wenn Sie pro Token oder pro Anruf bezahlen, minimieren Sie den Aufwand, indem Sie mehrere Aufforderungen in einer Anfrage zusammenfassen. Mit der Batch-Inferenz-API von TrueFoundry können Sie verwandte Aufgaben gruppieren — ideal für regelmäßige Aufgaben wie das Zusammenfassen großer Dokumentensätze. In einigen Fällen können parallele Anfragen sowohl an günstige als auch an teure Modelle gesendet werden, wobei die teurere Anfrage storniert wird, wenn die erste ein zufriedenstellendes Ergebnis liefert.
4. Hochfrequente Abfragen zwischenspeichern. Verwenden Sie Ergebnisse wieder, anstatt sie neu zu berechnen. Das Gateway unterstützt sowohl exaktes als auch semantisches Caching, wobei ähnliche Eingabeaufforderungen frühere Antworten wiederverwenden können. Selbst geringe Cache-Trefferraten können erhebliche Token-Ausgaben einsparen und gleichzeitig die Latenz verbessern — ein großer Gewinn bei wiederholten Workflows oder häufigen Abfragen.
5. Feinabstimmung oder Spezialisierung von Modellen. Bei sich wiederholenden, domänenspezifischen Aufgaben kann die Feinabstimmung eines kleineren Modells oder die Integration von RAG (Retrieval-Augmented Generation) die Eingabeaufforderungen verkürzen und die Anzahl der Tokens reduzieren. Die Plattform von TrueFoundry unterstützt die Feinabstimmung und benutzerdefinierte Bereitstellung und hilft Teams dabei, Präzision und Effizienz in großem Maßstab in Einklang zu bringen.
6. Nutzen Sie Open-Source-Modelle oder selbst gehostete Modelle. Bei hohen Volumina kann es günstiger sein, Open-Weight-Modelle auf dedizierten GPUs zu hosten, als pro API-Aufruf zu zahlen. Das Gateway ermöglicht eine nahtlose Hybridbereitstellung. Dabei wird ein Teil des Datenverkehrs an selbst gehostete Modelle weitergeleitet, während gleichzeitig einheitliche Protokollierungs- und Richtlinienkontrollen beibehalten werden. Dieses Hybrid-Setup kann zu erheblichen Kosteneinsparungen führen und gleichzeitig die Flexibilität wahren.
Zusätzlich zu diesen Praktiken immer
überwachen und iterieren
. Nutze die Daten vom Gateway, um zu sehen, welche Strategien die größte Wirkung haben (z. B. Cache-Trefferraten, durch Routing gespeicherte Token usw.) und passe sie entsprechend an. Kostenoptimierung ist kein einmaliges Ausprobieren und Vergessen, aber das Gateway gibt Ihnen die Tools an die Hand, um sie zu einem kontinuierlichen, überschaubaren Aufwand zu machen und nicht zu einer Überraschung bei der Brandbekämpfung.
Der Ansatz von TrueFoundry zur Kostenverfolgung und -kontrolle
Die Kostenoptimierung ist zwar eine universelle Herausforderung bei LLM-Bereitstellungen, Das KI-Gateway von TrueFoundry macht daraus einen strukturierten, messbaren und kontinuierlichen Prozess. Anstatt sich auf manuelle Budgetierung oder verstreute Kostenberichte zu verlassen, integriert TrueFoundry die Governance direkt in die Infrastrukturebene und stellt so sicher, dass jede KI-Interaktion in Echtzeit protokolliert, bewertet und zugeordnet wird. Diese einheitliche Infrastruktur ermöglicht eine strukturierte LLM-Lösung zur Kostenverfolgung, sodass Unternehmen ihre Ausgaben auf Modell-, Team- und Workflow-Ebene mit vollständiger Transparenz überwachen können.
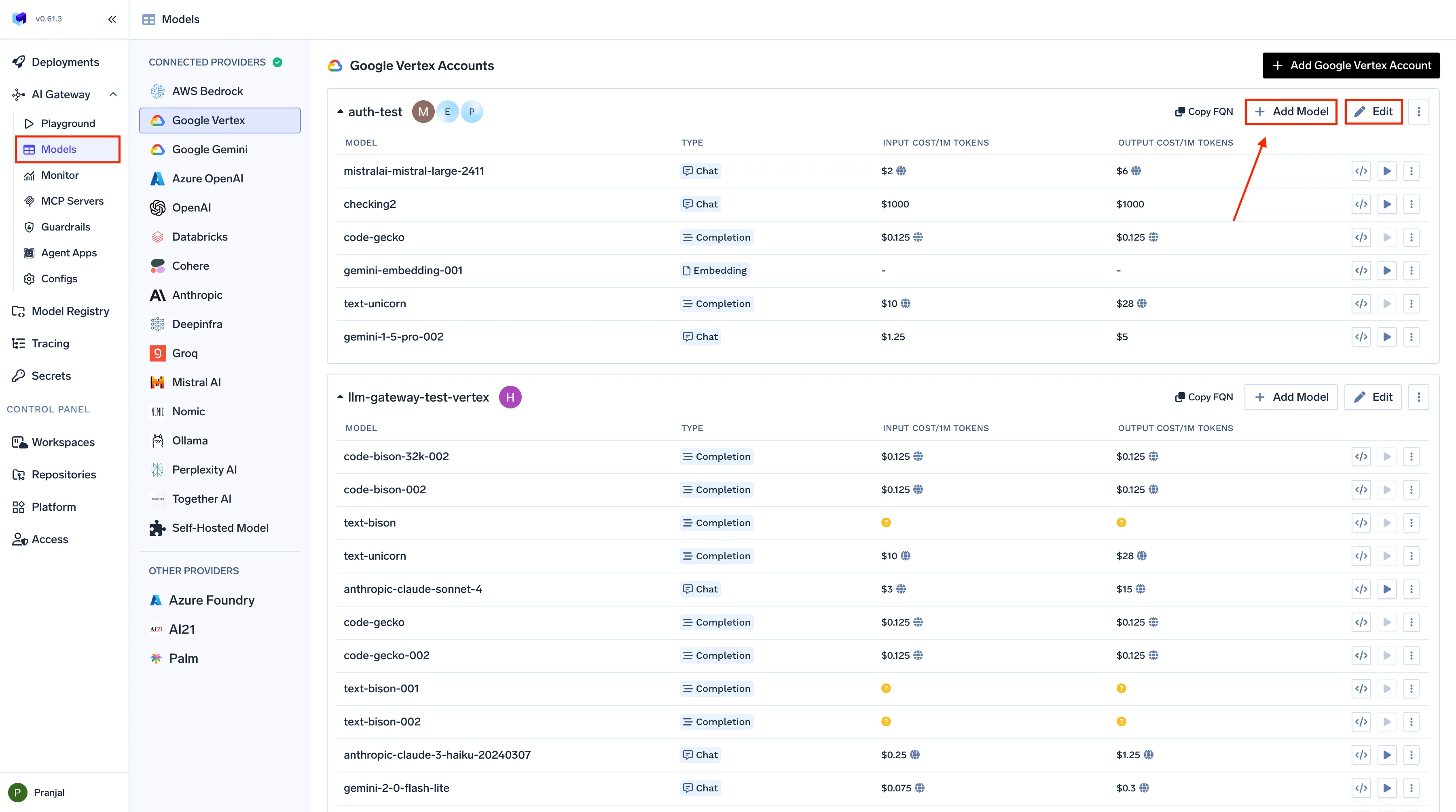
Die Schnittstelle zur Konfiguration der Modellkosten von TrueFoundry
1. Kostenzuweisung in Echtzeit
Jede Anfrage, die das Gateway von TrueFoundry durchläuft, erfolgt automatisch etikettiert und bepreist. Das System kombiniert die Anzahl der Eingabe-/Ausgabe-Tokens mit modellspezifische Preisdaten, unabhängig davon, ob es sich um öffentliche APIs oder von Unternehmen ausgehandelte Tarife handelt — um die genauen Kosten pro Inferenz zu berechnen. Teams können diese Metriken filtern nach Modell, Team, Umgebung oder Benutzerund bietet einen genauen Überblick darüber, wer oder was die Ausgaben antreibt. Das macht es einfach, Kosten zuzuweisen, interne Rückbuchungen vorzunehmen oder den ROI für KI-Funktionen zu begründen.
2. Konfigurierbare Modellpreise und Budgets
TrueFoundry ermöglicht es Unternehmen, benutzerdefinierte Preisgestaltung pro Modell, indem das interne Tracking mit den tatsächlichen Anbieterverträgen oder den selbst gehosteten Rechenkosten in Einklang gebracht wird. Administratoren können auch erstellen Budgetschwellen oder Kontingente für jede App oder Umgebung. Wenn die Ausgaben ein definiertes Limit überschreiten, kann das Gateway automatische Warnmeldungen auslösen oder sogar eine vorübergehende Drosselung durchsetzen, um die Kosten ohne manuelles Eingreifen einzudämmen.
3. Integrierte Beobachtbarkeit
TrueFoundry exportiert Kosten- und Nutzungsdaten nach Prometheus und OpenTelemetry, das sich nahtlos in bestehende Monitoring-Pipelines integrieren lässt. Dadurch können KI-Kosten-, Latenz- und Zuverlässigkeitskennzahlen in denselben Dashboards angezeigt werden, die für die Infrastruktur- und Anwendungsüberwachung verwendet werden. Das Ergebnis ist ein einzelne Glasscheibe wo Konstruktions-, Finanz- und Produktteams einen einheitlichen Überblick über Leistung und Ausgaben haben.
4. Verwaltung durch Design
Weil jeder Anruf beinhaltet Metadaten-Tagging (Team, Projekt und Umgebung) können Organisationen eine strukturierte, abteilungsübergreifende Rechenschaftspflicht einführen. Kombiniert mit Rollenbasierte Zugriffskontrolle (RBAC) und Berechtigungen auf Modellebene, wodurch sichergestellt wird, dass Modelle mit hohen Kosten oder hohem Risiko nur zugelassenen Teams zugänglich sind. Diese Leitplanken sorgen für Einhaltung, Haushaltsdisziplin und Transparenz automatisch — nicht manuell.
Wenn ein KI-Gateway möglicherweise nicht gerechtfertigt ist
KI-Gateways bieten in großem Maßstab einen immensen Mehrwert, aber nicht jedes Unternehmen benötigt sofort eines. Für kleine Teams oder Projekte in der Anfangsphase, die ein einziges Modell und geringe Anforderungsvolumen verwenden, kann die Bereitstellung eines vollständigen Gateways einen unnötigen Aufwand bedeuten. Ein Prototyp, der ein OpenAI-Modell mit ein paar tausend Token pro Tag aufruft, kann einfach mit direkten API-Aufrufen und grundlegender Überwachung verwaltet werden.
Branchenrichtlinien deuten darauf hin, dass, wenn die Nutzung begrenzt ist (Zehntausende von Tokens pro Monat) und die Anforderungen an die Einhaltung von Vorschriften oder Zuverlässigkeit minimal sind, ein einfacher Proxy oder manuelles Tracking ausreichen können. Der wahre Vorteil des Gateways zeigt sich, wenn die Workloads je nach Modell und Anbieter skaliert oder diversifiziert werden. Wenn Ihr Unternehmen immer noch mit LLMs experimentiert oder nur über eine minimale Infrastruktur verfügt, konzentrieren Sie sich zunächst auf die Iteration, planen Sie jedoch im Voraus. Das Gateway von TrueFoundry kann beispielsweise effizient herunterskaliert werden und bietet frühzeitige Transparenz und Governance ohne aufwändige Einrichtung. Kurz gesagt, bewerten Sie Ihre Reife und Umfang der KI: Für Anwendungsfälle mit nur einem Modell und geringem Volumen kann ein Gateway verfrüht sein. Mit zunehmender Akzeptanz wird es für Kostenkontrolle, Zuverlässigkeit und langfristige Governance schnell unverzichtbar.
Fazit
Die Kontrolle der LLM-Kosten in Unternehmensumgebungen ist komplex, aber KI-Gateways wurden entwickelt, um genau das zu lösen. Anstatt die Kosten dem Zufall zu überlassen, bietet ein Gateway wie True Foundry's bettet die Kostenkontrolle direkt in Ihre KI-Architektur ein. Durch zentralisiertes Tracking, Budgetplanken, intelligentes Routing und Caching wird die Kostenkontrolle zu einer integrierten Funktion und nicht zu einer Nebensache.
Bericht über Unternehmen, die KI-Gateways verwenden Reduzierung der Inferenzkosten um 40— 60%, zusammen mit höherer Zuverlässigkeit und Sicherheit. Insbesondere TrueFoundry's Gateway bietet Rechenschaftspflicht durch Design — Bereitstellung detaillierter Einblicke, Kostenzuweisung und Rückbuchungen für Teams — und Risikominderung im großen Maßstab über automatische Limits und Failsafes. Es bietet auch volle Transparenz in Nutzungsmuster, damit kein Kosten- oder Latenzproblem unbemerkt bleibt.
Durch die Vereinheitlichung der Richtlinien über Regionen und Teams hinweg gewährleistet das Gateway eine konsistente Governance und Compliance — entscheidend für Branchen, die mit sensiblen Daten umgehen. Das Ergebnis: KI-Projekte gehen von der Erprobung zur Produktion über, und zwar mit vorhersehbaren Ausgaben und betrieblicher Sicherheit.
Kurz gesagt, KI-Gateways sorgen für eine nachhaltige Einführung von LLM. Token-basierte Preisgestaltung mag unvorhersehbar sein, aber mit der zentralen Kontrollebene von TrueFoundry können Unternehmen ihre Ausgaben optimieren, Leitplanken durchsetzen und verantwortungsbewusst skalieren. Auf diese Weise koexistieren Innovation und Haushaltsdisziplin — und machen KI zu einer regulierten, effizienten und unternehmensgerechten Funktion.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last































.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




