

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Die Verbreitung großer Sprachmodelle (LLMs) und agentischer Systeme markiert einen entscheidenden Moment für die Unternehmenstechnologie. Das Innovationspotenzial ist riesig — aber auch die Fallstricke. In vielen Unternehmen verlief die frühe Einführung chaotisch: fragmentiert, nicht verwaltet und unsicher. Einzelne Teams stellen ihre eigenen Verbindungen zu verschiedenen Modellanbietern her, was zu isolierten Experimenten ohne zentrale Aufsicht, Kostenkontrolle oder Sicherheitsstandards führt.
Um von diesen Ad-hoc-Experimenten zu einer kohärenten, unternehmensweiten KI-Strategie zu gelangen, benötigen wir ein durchdachtes Architekturparadigma — eines, das Sicherheit, Governance und Skalierbarkeit vom ersten Tag an berücksichtigt.
Ein idealer Agenten-Applikationsstack in der heutigen Umgebung muss Folgendes bieten:
Schnelle Anwendungsentwicklung — Die föderierte Ausführung mit niedriger Latenz über heterogene Agenten und Umgebungen hinweg verkürzt die Time-to-Value (TTV), sodass Teams schnell produktionsbereite Funktionen bereitstellen können, ohne dass alle Daten oder Berechnungen zentralisiert werden müssen.
Zukunftssichere Flexibilität — ein modularer, interoperabler Stack, der sich an neue Modelle, Protokolle und Agentenmuster anpassen kann, wenn sich die KI-Landschaft weiterentwickelt.
Sicherheit und Konformität als Standard — PII-Maskierung, Durchsetzung von Richtlinien und vollständige Überprüfbarkeit.
Deterministische Operationen an nichtdeterministischen Systemen — Leitplanken, Bewertungsrahmen und Rollback-Pfade, wenn die Ergebnisse abweichen.
Kostenkontrolle mit Token-Granularität — Budgets, Showback/Chargeback und Nutzungsobergrenzen.
Zuverlässigkeit und Portabilität — Failover mit mehreren Modellen, Hybrid-/On-Premise-Bereitstellung und ohne Herstellerbindung über anbieterunabhängige Schnittstellen, exportierbare Artefakte und Pläne für die Replay-to-Switch-Migration.
Tiefe Beobachtbarkeit — Traces, Metriken auf Token-Ebene (TTFT, TPS), Cache-Trefferraten und Nutzungstrends.
Zusammensetzbare Funktionen — Modelle, Tools und Agenten, die über Eingabeaufforderungen miteinander verbunden sind, kein spröder Klebecode.
Geschwindigkeit mit Kontrolle — CI/CD für Models, Agenten und Tools; gestaffelte Rollouts mit Canary- oder A/B-Tests.
Und wir müssen unter Berücksichtigung realer Einschränkungen entwerfen, wie zum Beispiel:
Hier macht Architektur den Unterschied zwischen einer inspirierenden Demo und einem serienreifen System aus. Der Entwurf sollte aus vier wichtigen Ebenen bestehen: Modellen, MCP-Servern, Agenten und Eingabeaufforderungen.
1. Modelle — Unterstützung der Kernintelligenz
Das Herzstück jeder Gen-AI-Anwendung ist das Modell selbst — die Argumentationsmaschine Ihres Systems. Die Herausforderung besteht nicht einfach darin, das „beste“ Modell auszuwählen. Es geht darum, für eine Welt zu entwerfen, in der es zahlreiche Modelle gibt, die sich ständig weiterentwickeln und für unterschiedliche Zwecke geeignet sind.
Ein solider Stack behandelt Modelle wie normale Softwareressourcen: Sie werden versioniert, Daten- und Codeänderungen nachverfolgt und durch Entwicklung, Staging und Produktion bewegt. Beim Routing sollten auch Kosten und Leistung berücksichtigt werden — manchmal ist ein kleineres, billigeres Modell für eine bestimmte Aufgabe die bessere Wahl, als alles auf einem großen, teuren Modell laufen zu lassen.
Die Falle, in die viele tappen, ist die Vielzahl der Modelle: zu viele Modelle, die nicht verfolgt werden, undurchsichtige Upgrades und kein Rollback-Pfad, wenn die Leistung zurückgeht. Architektur bedeutet hier Disziplin — Modelle werden mit der gleichen Strenge behandelt wie der Code der Kernanwendungen.
2. MCP-Server — Standardisierung der Funktionen
Wenn Modelle das Gehirn sind, sind MCP-Server (Model Context Protocol) das Werkzeug. Sie bieten Ihren Agenten standardisierten, unternehmensgerechten Zugriff auf Systeme wie Jira, GitHub, Postgres oder proprietäre APIs.
Anstatt maßgeschneiderter, teamspezifischer Integrationen — jede mit ihren eigenen Macken, Sicherheitslücken und duplizierter Logik — kann ein einziger zertifizierter MCP-Server pro System im gesamten Unternehmen wiederverwendet werden. Typisierte I/O-, Authentifizierungs- und Kontingente werden konsistent, vorhersehbar und sicher.
Wenn Teams diesen Schritt überspringen, folgt Chaos: inkonsistente Sicherheitsrichtlinien, redundante Arbeit und spröde Integrationen, die nicht gemeinsam genutzt oder verwaltet werden können. MCP-Server machen Funktionen kombinierbar und nicht zufällig.
3. Agenten — Die digitale Belegschaft
Agenten sind der Ort, an dem Modelle einsatzbereit werden. Sie sind nicht nur Pipelines — sie sind das digitale Gegenstück zu menschlichen Mitarbeitern, die in der Lage sind, Maßnahmen zu ergreifen, Aufgaben zu koordinieren und Tools zu verwenden.
Ein gutes Agentendesign bedeutet, jedem Agenten eine Identität, Berechtigungen auf der Grundlage der geringsten Rechte und einen klaren Lebenszyklus von der Sandbox bis zur Produktion zu geben. Sie sollten orchestriert sein, die Zusammenarbeit mit mehreren Agenten ermöglichen und über Umgebungen hinweg übertragbar sein.
Das größte Betriebsrisiko ist hier der unkontrollierte Zugriff: Anmeldeinformationen, die in Benutzeroberflächenebenen gespeichert sind, Tools, auf die ohne Grenzen zugegriffen werden kann, und es gibt keine Eigentumsrechte oder SLAs. Gut konzipierte Agenten haben ihre Anmeldeinformationen und Geltungsbereiche stets im Griff — sie sind nicht an den Ort gebunden, an dem sie aufgerufen werden.
4. Eingabeaufforderungen — Die Bedienoberfläche
Mithilfe von Aufforderungen sagen wir Models und Agenten, was zu tun ist. Sie bestehen nicht nur aus reinem Text, sie können auch strukturierte Vorlagen sein, Bewertungsschritte beinhalten und über integrierte Richtlinienprüfungen verfügen.
In einem soliden Setup werden Prompts wie Code behandelt: Sie sind versionskontrolliert, getestet und vor Prompt-Injection oder unbeabsichtigten Änderungen geschützt. Verwenden semantisches Caching kann Zeit und Kosten sparen, indem Antworten für ähnliche Abfragen wiederverwendet werden, anstatt den gesamten Prozess erneut auszuführen.
Wenn Sie Eingabeaufforderungen nicht ordnungsgemäß verwalten, riskieren Sie Sicherheitsprobleme, dass vertrauliche Daten durchsickern oder dass sich Ihre Aufforderungen im Laufe der Zeit langsam auf eine Weise ändern, die Sie nicht geplant hatten. Eine gute Verwaltung gewährleistet ein konsistentes, sicheres und zuverlässiges Verhalten.
Wenn die Hauptebenen — Modelle, MCP-Server, Agenten und Prompts — sorgfältig erstellt und verwaltet werden, wird das System zuverlässiger, skalierbarer und wartungsfreundlicher. In großen Organisationen treten jedoch häufig Probleme bei der Koordination all dieser Teile auf, nicht nur in den einzelnen Teilen selbst.
Zentralisierte Register sind das Bindegewebe des Gen-AI-Stacks: der institutionelles Gedächtnis Dadurch bleiben alle Komponenten auffindbar, konform und interoperabel. Ohne sie riskieren Sie, wieder in das Chaos zurückzufallen, das diese Architektur eigentlich verhindern sollte — Doppelarbeit, Sicherheitslücken und unsichtbares Abweichen von Standards.
Eine robuste Registrierungsebene bietet:
In der Praxis umfasst diese Ebene mehrere spezialisierte Register:
Das Aufzeichnungssystem für Ihre Modelle — Tracking Versionen, Abstammung (Daten, Code, Metriken), Bereitstellungsstatus (dev/shadow/prod) und wer ein Modell bewerben oder verwenden kann. Es ist mit CI/CD-Pipelines verbunden, sodass neue Versionen automatisch registriert werden und sicher über Canary- oder A/B-Tests eingeführt werden können. Neben der Auffindbarkeit erzwingt es auch Disziplin: Es gibt keine „rätselhaften Modelle“ in der Produktion, keine Änderungen, die nicht nachverfolgt werden.
Der Katalog von zertifizierte Tools steht Agenten zur Verfügung und dokumentiert ihre Funktionen, Argumente und Schemas. Es kodiert auch Nutzungsberechtigungen—nicht jeder Agent sollte Zugriff auf Ihre Finanzsysteme oder vertraulichen Datenbanken haben. Ein einmal erstellter MCP-Server kann teamübergreifend wiederverwendet werden, wobei das Gateway die rollenbasierte Zugriffskontrolle auf Toolebene durchsetzt.
Ein Verzeichnis Ihrer digitale Belegschaft— Verfolgung der Identität (UUID), des Besitzers, des Zwecks, der Fähigkeiten, der erlaubten Modelle/Tools und der Anmeldeinformationen jedes Agenten. Es zeichnet den gesamten Lebenszyklus von der Erstellung bis zur Außerbetriebnahme auf und stellt sicher, dass der Zugriff nach den geringsten Rechten am Gateway in Echtzeit erfolgt. Dadurch wird verhindert, dass Agenten häufig zu viele oder veraltete Zugriffsrechte behalten.
Ein versioniertes Repository mit Sicherheitsrichtlinien für Eingabe und Ausgabe, das Folgendes umfasst PII-Maskierung, schnelle Injektionserkennung, aktuelle Grenzen, Toxizitätsfilter, und Faktenüberprüfung Regeln. Richtlinien werden als Code verwaltet, was bedeutet, dass sie schrittweise über Kanarien oder A/B-Tests eingeführt werden können. Gebündelte Richtlinien (z. B. „HIPAA-konformer Chatbot“) können konsistent auf alle Modelle, Agenten und Tools angewendet werden.
Register geben uns das Gerüst für Speicher und Verwaltung. Aber Regierungsführung auf dem Papier bedeutet nichts, wenn sie nicht durchgesetzt wird zur Laufzeit— wo Eingabeaufforderungen gesendet, Tokens verbraucht und Antworten zugestellt werden.
Selbst mit den richtigen Komponenten und gut verwalteten Registern läuft ein modernes KI-System nicht im luftleeren Raum. In der Produktion besteht der eigentliche Test nicht darin, ob Ihre Architektur auf dem Papier gut aussieht — es geht darum, ob sie unter Ausfallbedingungen, variabler Nachfrage und unvorhersehbaren Kosten weiterhin funktioniert.
Hier kommen die „betrieblichen Nuancen“ ins Spiel. Es handelt sich nicht um eigenständige Komponenten, sondern um übergreifende Muster, die dem gesamten Stack Haltbarkeit, Effizienz und Reaktionsfähigkeit verleihen.
Muster für hohe Verfügbarkeit
In einem aktiven KI-System ist ein Ausfall keine Möglichkeit — es ist eine Gewissheit. Modelle werden ausfallen, Endpunkte werden sich ändern und Netzwerke werden sich schlecht benehmen. Die Aufgabe eines Architekten besteht darin, sicherzustellen, dass diese Ereignisse nicht zu Ausfällen für den Benutzer führen.
Einsperren wird durch Übung vermieden, nicht durch Versprechen. Behandeln Sie den Ausstieg als eine Laufzeitdisziplin, nicht als ein Projekt auf der letzten Meile.
Anbieterunabhängiges Gateway — Normalisieren Sie Anforderungs-/Antwortschemas und Capability-Tags, sodass Apps niemals an ein Anbieter-SDK gebunden werden.
Zum Umschalten erneut abspielen — Überwachen Sie routinemäßig einen repräsentativen Teil der Produktionsspuren auf einen anderen Anbieter oder ein selbst gehostetes Modell. Verfolgen Sie Deltas in Bezug auf Latenz, Kosten und Qualität, um die Notlösung warm zu halten.
Artefakte öffnen — Speichern Sie Eingabeaufforderungen, Traces, Evalings, Einbettungen und Feinabstimmungen von Datensätzen in exportierbaren Formaten; sorgen Sie dafür, dass Vektorindizes von der Quelle aus rekonstruiert werden können.
Kompatibilitätsmatrix — Pflege einer Lieferanten-/Modell-Scorecard (Latenz/Kosten/Qualität/Funktionen), damit die Routing-Richtlinien datengesteuert bleiben.
Vertrags- und Datenrechte — bevorzuge Begriffe, die einen Gewichtswechsel und ein erneutes Training ermöglichen; verfolge die Herkunft der Datensätze in der Modellregistrierung, damit das Verlassen nicht an der Herkunft hängen bleibt.
Checkliste verlassen — Schlüssel/Konfiguration vom Code entkoppelt, sekundäre Endpunkte vorab überprüft, minimaler Wiederholungsdatensatz definiert, bekannte Lücken dokumentiert.
KI-Workloads sind von Natur aus kostenvariabel, und ohne aktives Management können sich die Kosten in die Höhe treiben. Die Herausforderung besteht darin, Kostendisziplin durchzusetzen, ohne dass es zu Engpässen kommt, die Entwickler oder Benutzer frustrieren.
Diese Nuancen sorgen dafür, dass das System reibungslos läuft, wenn etwas schief geht. Sie helfen auch dabei, die Kosten unter Kontrolle zu halten. Um die Nuancen von Fallback, Redundanz und Kosten zu kombinieren, ist eine einheitliche Steuerungsebene erforderlich. Genau das macht das AI Gateway: Es vereint all diese Teile in einem einzigen, zentralen Teil der modernen GenAI-Architektur.
KI-Gateways regeln Modelle, Agenten, Tools, Eingabeaufforderungen und Tokens. Es ist ein spezialisiertes Middleware-Steuerungsebene für KI-Verkehr — Egress/Reverse-Proxy, der versteht Tokens, Semantik und Tools.
Was es tut
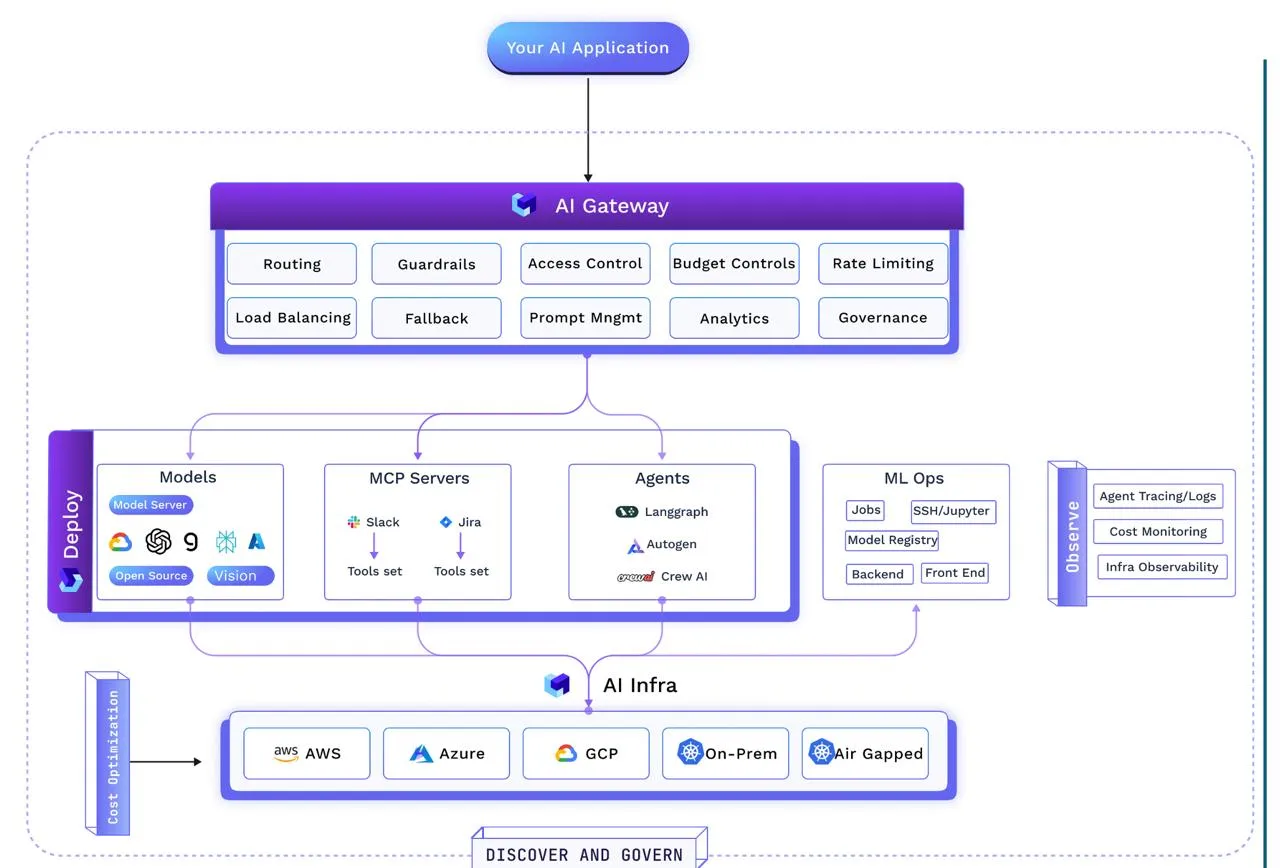
Sobald der Plan definiert ist, die Register eingerichtet sind, die betrieblichen Schutzmaßnahmen integriert sind und das AI Gateway sie in Echtzeit durchsetzt, stellt sich die Frage: Wie betreiben wir das Ding eigentlich?
Hier verlagert sich das Gespräch von der Architektur und Steuerung zur Umsetzung — der Bereitstellungsebene das kann Code und Modelle in die Produktion überführen schnell, behalte sie zuverlässig, und lass sie laufen kosteneffektiv—und das alles, ohne die Betriebsdisziplin zu verletzen.
Geschwindigkeit bedeutet hier nicht, an allen Ecken und Kanten zu sparen. Eine moderne Pipeline bewegt sich innerhalb von Minuten vom Commit zum Cluster: Automatisierte Tests validieren Änderungen, Container packen Modelle, Agenten und MCP-Server in unveränderliche Images, und Manifeste verteilen sie mit konfigurierbaren Strategien an die Entwicklung, das Staging oder die Produktion. Registrierungsupdates stellen sicher, dass das Gateway neue Versionen sofort erkennen und verwalten kann. Ganze Anwendungen — Modell, Backend, Frontend und Tools — können als vorkonfigurierte Stacks bereitgestellt oder sogar von Conversational Deployment Agents gestartet werden.
Zuverlässigkeit ist eingebettet durch Bewährte Verfahren von SRE: sofortige automatische Skalierung und Failover, proaktive Überwachung, Rollback/Versionierung bei Bedarf, unveränderliche Audit-Logs und automatisches Herunterfahren inaktiver Umgebungen oder IDEs.
Richtlinien werden hier ebenfalls durchgesetzt Betriebsregeln wie „keine Produktionsbereitstellung ohne mindestens zwei Replikate“ oder „GPU-Workloads müssen im Leerlauf automatisch heruntergefahren werden“.
Die Kosteneffizienz muss ebenfalls berücksichtigt werden. Die Ebene verwendet nahtlos Spot-Instances mit On-Demand-Fallback, um Kosten zu sparen, skaliert Workloads mit HPA/VPA und Cluster-Autoscaling und nutzt ereignisgesteuerte Skalierung (z. B. KEDA), um Mitarbeiter bei Bedarf sofort online zu bringen und im Leerlauf wieder auf Null zu bringen. Eine Funktion im Autopilot-Stil würde Skalierung oder Platzierungsänderungen in Echtzeit vornehmen und so Kosteneinsparungen mit SLA-Schutz in Einklang bringen.
Die Standard-Deployment-Pipeline für einen agentischen KI-Stack sieht so aus:
Artefakte sind OCI-Bilder und Manifeste sind einfache IaC; Endpunkte und Regionen sind parametrisiert. Dadurch bleiben Workloads unabhängig von der Cloud und ermöglichen eine schnelle, richtliniengesteuerte Verlagerung, ohne den Anwendungscode zu berühren.
Wenn das System live ist — Modelle, die auf Kubernetes bereitgestellt, Agenten registriert sind und das Gateway Laufzeitregeln anwendet — ist die Architektur betriebsbereit. Es ist jedoch kein einmaliges Unterfangen, dafür zu sorgen, dass es sicher, effizient und an den Prioritäten des Unternehmens ausgerichtet ist. Workloads werden zwischen Umgebungen hin- und hergeschoben, herunterskaliert und mit neuen Tools und Modellen weiterentwickelt.
Wenn die Governance nicht mit ihnen mitgeht, entsteht ein Schattenverhalten: Agenten laufen ohne Leitplanken, Workloads werden ohne Redundanz bereitgestellt, oder GPUs, die im Leerlauf bleiben und hohe Kosten verursachen. Die Antwort ist im Prinzip einfach, aber in der Praxis leistungsstark —Richtlinien, die mit der Arbeitsbelastung einhergehen.
Außerdem können Guardrails nicht als Ad-hoc-Skripte existieren, die in der Codebasis eines Teams vergraben sind. Das sollten sie sein Richtlinie als Code—versioniert, überprüft und bereitgestellt wie jedes andere Kernartefakt:
Bei Richtlinien geht es nicht nur um KI-Sicherheit. Sie können kodieren organisationsweite Betriebsstandards:
Diese Regeln stellen sicher, dass Ihre Systeme die grundlegenden Zuverlässigkeits- und Effizienzstandards erfüllen standardmäßig, ohne auf manuelle Prüfungen oder Teamspeicher angewiesen zu sein.
In vielen regulierten oder hochsicheren Branchen wird es zu einer Herausforderung, große proprietäre Modelle in der Produktion zu betreiben. Durch die Feinabstimmung eines kleineren, selbst gehosteten Modells wird diese Barriere umgangen und gleichzeitig die Qualität erhalten. Und da sich das Gateway bereits im Datenverkehrsfluss befindet, kann es die Migration bewältigen. Es vergleicht das neue Modell mit dem alten, führt A/B-Tests durch und leitet den Datenverkehr entsprechend weiter, sobald die Leistung konvergiert. Die Verwendung fein abgestimmter Open-Source-LLMs für Anwendungsfälle der Generation AI in großem Maßstab ist auch für Unternehmen kostengünstig.
Beim Gateway geht es nicht nur um Durchsetzung — es ist auch ein Modell Evolution Engine. Durch die Protokollierung qualitativ hochwertiger Interaktionen aus einem großen, teuren Modell wie GPT-4O wird ein Feinabstimmungsdatensatz für ein kleineres, effizientes Modell wie LLama erstellt.
Mit diesem Ansatz können Sie:
Aus der Sicht des Architekten wird das KI-Gateway dadurch zu mehr als einer Durchsetzungsebene — es wird zu einem Modell Evolution Engine, das im Hintergrund Laufzeitdaten in die Grundlage Ihrer kostenoptimierten, produktionsbereiten KI der nächsten Generation umwandelt.
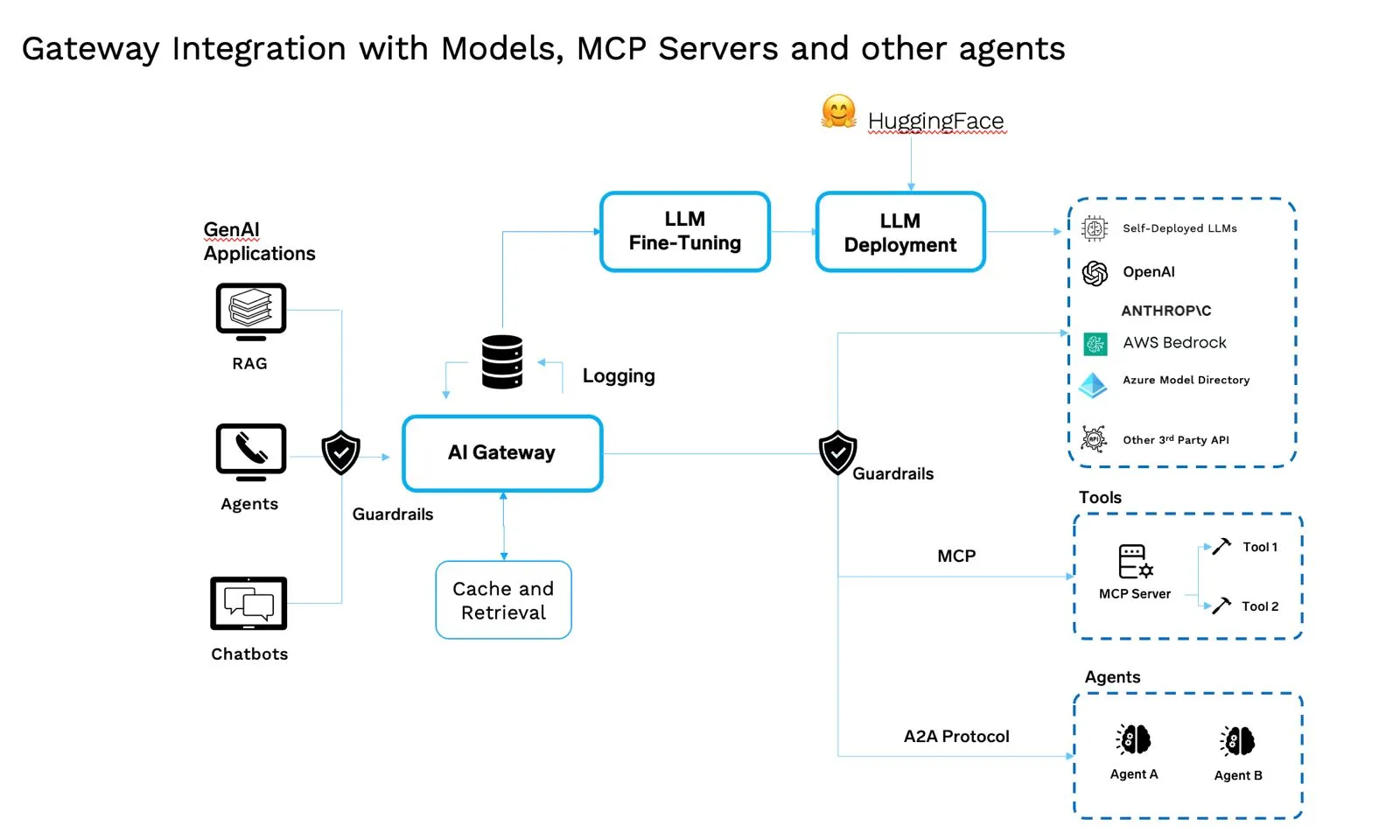
Wenn Sie den Stapel als Ganzes betrachten, liegt der Wert nicht in den einzelnen Teilen, sondern darin, wie sie zusammenarbeiten. Modelle müssen verfolgt und versioniert werden. MCP-Server stellen sie auf konsistente Weise zur Verfügung. Die Agenten bringen Argumente und Entscheidungen mit. Aufforderungen geben ihnen klare Anweisungen. Registries stellen sicher, dass Sie wissen, was wo läuft. Betriebliche Richtlinien sorgen für Sicherheit und Wirtschaftlichkeit. Kubernetes bietet Ihnen die Skalierbarkeit und Zuverlässigkeit, um alles auszuführen.
Das AI Gateway befindet sich oben, um diese beweglichen Teile zu koordinieren, aber die wahre Stärke liegt in der Integration — jede Ebene ist miteinander verbunden, verwaltet und beobachtbar. Das macht aus einer Sammlung von Tools ein System, dem Unternehmen tatsächlich vertrauen und auf dem sie aufbauen können.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.









.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




