

July 21, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Für viele Entwicklungsteams ist Amazon SageMaker der Standardstartpunkt für maschinelles Lernen auf AWS. Es bietet ein umfassendes „Lab-in-a-Box“ -Erlebnis, das die Verwaltung der zugrunde liegenden Server überflüssig macht.
Da die Teams jedoch von experimentellen Notebooks zur vollständigen Modellbereitstellung übergehen, entspricht die monatliche Rechnung nicht der Realität. Der Vorteil von „Managed ML“ ist mit einer Prämie verbunden, die die Margen schleichend schmälern kann.
In diesem Leitfaden werden spezifische Komponenten der SageMaker-Preisgestaltung erörtert, der Preisaufschlag für Recheninstanzen aufgezeigt und erklärt, warum kostenbewusste Unternehmen nach Alternativen suchen.
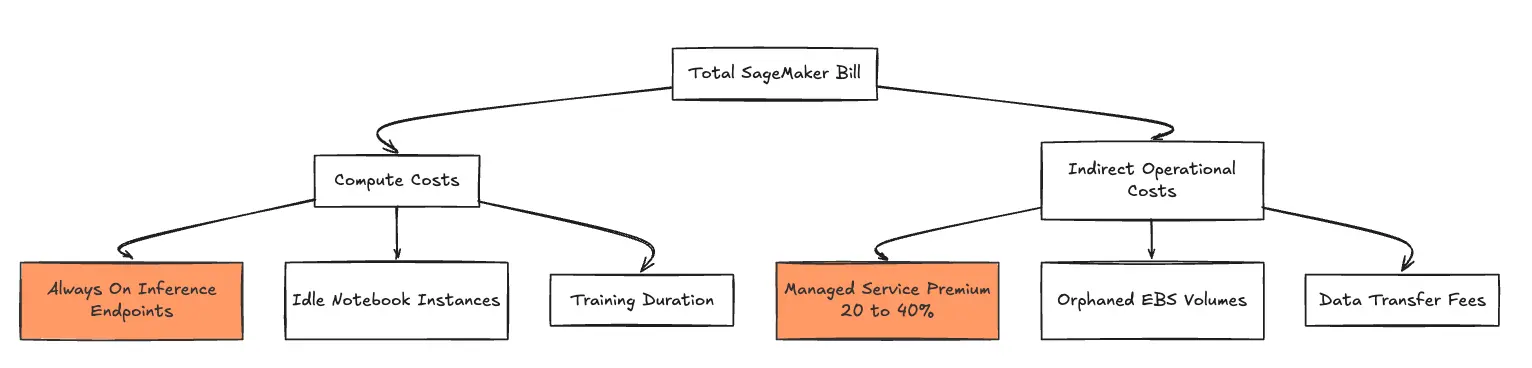
SageMaker bündelt die Preise nicht in einem einzigen Plan. Stattdessen zahlen Sie für jede Phase des ML-Lebenszyklus separat. Wir erklären Ihnen dann die Kostenaufschlüsselung:
SageMaker Studio-Notebooks werden oft mit leichten Texteditoren verwechselt. In Wirklichkeit werden sie als laufende Recheninstanzen abgerechnet.
Die Schulungskosten werden auf der Grundlage des jeweils verwendeten Instanztyps und der Dauer, für die die Ressourcen aktiv bleiben, berechnet.
Für die meisten Produktionsteams ist Inferenz der „Eisberg“ von Amazon SageMaker-Preise—buchhalterisch 70— 80% der Gesamtrechnung.
Einer der größten Treiber von High Kosten für AWS SageMaker ist das Managed-Service-Markup. Während Sie technisch gesehen Amazon EC2-Instances unter der Haube verwenden, wickelt SageMaker sie in eine Verwaltungsebene ein und berechnet dafür eine Prämie.
Die Prämie ist nicht willkürlich; AWS erhebt diese Gebühr, weil sie die schwere Arbeit übernehmen:
Für kleine Teams ohne Plattformingenieure ist dies ein fairer Handel. Im großen Maßstab verwandelt sich diese Komfortprämie jedoch in eine wiederkehrende Steuer auf die Infrastrukturnutzung, die zu sinkenden Renditen führt.
Abgesehen von den Gesamtrechenraten erhöhen mehrere betriebliche Ineffizienzen das Endergebnis SageMaker-Rechnung. Diese Kosten werden oft erst entdeckt, nachdem die Finanzabteilung eine Budgetüberschreitung gemeldet hat.
Jedes Notizbuch und jeder Trainingsjob hängt standardmäßig ein Elastic Block Store (EBS) -Volume an, um Daten und Code zu speichern.
Multi-Model Endpoints (MMEs) versprechen Kosteneinsparungen, da Sie mehrere Modelle auf einem einzigen Container hosten können.
AWS-Spot-Instances bieten Rabatte von bis zu 90%, aber sie sind riskant, wenn es um Rückschlüsse in SageMaker geht.
Wenn Ihre KI-Akzeptanz zunimmt, SageMaker-Preisgestaltung wird immer schwieriger zu prognostizieren und zu optimieren.
Die Kosten verteilen sich auf Notebooks, Schulungsjobs, Endgeräte, Speicher und Überwachung (CloudWatch). Da die Budgetkontrolle auf AWS-Kontoebene erfolgt, ist es schwierig, bestimmte Kosten einem bestimmten Modell oder Forschungsteam zuzuordnen. Dieser Mangel an Transparenz führt zu ungenutzten Ressourcen und überlasteten Endgeräten, wodurch die monatlichen Ausgaben auf unbestimmte Zeit in die Höhe getrieben werden.
Teams, die erweiterte Funktionen wie SageMaker Ground Truth, SageMaker Clarify oder SageMaker Debugger für die Modellentwicklung verwenden, stellen häufig fest, dass diese die Gesamtkosten noch komplexer machen.
Oft gibt es einen klaren Wendepunkt, an dem die verwaltete Prämie von SageMaker nicht mehr tragbar ist.
Wenn die monatlichen KI-Ausgaben die Schwellenwert von 10.000 bis 20.000$, das Markup kann nicht mehr ignoriert werden. In dieser Phase streben Führungskräfte im technischen Bereich in der Regel nach reinen Infrastrukturpreisen ohne den verwalteten Overhead. Fortgeschrittene Teams benötigen eine detaillierte Kontrolle über GPU-Typen, Reserved Instances und Sparpläne — Optimierungen, die innerhalb des SageMaker-Ökosystems oft eingeschränkt oder komplexer sind.
Das KI-Gateway von TrueFoundry bietet einen grundlegend anderen Ansatz durch Trennen Orchestrierung von Eigentum an der Infrastruktur.
Anstatt Ihre Rechenleistung mit einem Markup weiterzuverkaufen, orchestriert TrueFoundry Workloads direkt auf Ihren eigenen EKS- (Kubernetes) und EC2-Clustern.
Eine parallele technische Bewertung unserer Orchestrierungsebene im Vergleich zum von AWS verwalteten Ökosystem finden Sie in unserer vollständigen Aufschlüsselung von SageMaker gegen TrueFoundry.
Dieser Vergleich konzentriert sich eher auf die Einheitenökonomie als auf die Merkmalsparität.
Wenn Sie eine detaillierte Analyse der realen Ersparnisse und der Wirtschaftlichkeit pro Einheit auf verschiedenen Ausgabenskalen sehen möchten, schauen Sie sich unsere Kostenvergleich mit SageMaker.
Entscheidungen zur KI-Infrastruktur sollten sich an den langfristigen Kosten- und Betriebszielen orientieren.
Amazon SageMaker ist ideal für:
Wahre Gießerei ist ideal für:
Wenn Sie sich jedoch immer noch zwischen verschiedenen AWS-nativen Diensten für Ihren speziellen Anwendungsfall entscheiden, finden Sie in unserem Leitfaden zu AWS Bedrock im Vergleich zu AWS SageMaker untersucht die wichtigsten Unterschiede in Bezug auf Flexibilität und Verwaltung, die Sie berücksichtigen sollten.
SageMaker eignet sich hervorragend für frühe Experimente, aber langfristiger KI-Erfolg erfordert Kostendisziplin. Wenn Ihre Cloud-Rechnung schneller wächst als die Leistung Ihres Modells, ist es an der Zeit, Ihre Infrastrukturstrategie zu überdenken.
Wenn Sie bereit sind, die hohen Aufschläge von Managed Services hinter sich zu lassen und genau wissen möchten, wie viel Ihr Unternehmen bei der Infrastruktur sparen kann, eine Demo buchen mit TrueFoundry noch heute, um Ihre potenziellen Einsparungen zu berechnen.
Die SageMaker-Preise variieren je nach Region und Nutzung. Sie zahlen separat für Recheninstanzen (pro Stunde), Speicher (GB/Monat) und Datenübertragung. Die Instance-Preise reichen von ein paar Cent pro Stunde für Basis-CPUs bis zu über 28 USD/Stunde für fortgeschrittene GPU-Instances.
Um zu reduzieren Kosten für AWS SageMaker, stellen Sie sicher, dass Sie inaktive Notebook-Instances herunterfahren, Spot-Instances für Trainingsaufgaben verwenden, die richtige Größe Ihrer Inferenzendpunkte festlegen und nicht angehängte EBS-Volumes löschen. Alternativ kann durch die Umstellung auf eine Orchestrierungsplattform wie TrueFoundry das Markup für verwaltete Dienste vollständig entfallen.
SageMaker bietet für die ersten zwei Monate ein kostenloses Kontingent an, das begrenzte Stunden für die Nutzung von Notebooks, Schulungen und Inferenzen zu kleinen Instance-Typen beinhaltet. Sobald diese Grenzwerte überschritten werden, gelten die Standardpreise.
TrueFoundry ist kostengünstiger, da es Ihnen ermöglicht, Workloads auf Ihrem eigenen Cloud-Konto mithilfe von Standard-EC2-Instances auszuführen und so die SageMaker-Aufschläge von 20-40% zu vermeiden. Es bietet auch automatisierte Funktionen zum Herunterfahren ungenutzter Ressourcen und zur zuverlässigen Verwendung von Spot-Instances für Inferenzen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


