
.webp)
July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
In herkömmlichen Softwaresystemen sind Fehler in der Regel explizit. Eine Funktion gibt einen Fehler aus, ein Dienst stürzt ab oder eine Anfrage läuft ab. Das Debuggen ist weitgehend deterministisch. KI-Agenten ändern dieses Modell grundlegend.
Agenten sind von Natur aus nicht deterministisch. Sie denken über Zwischenschritte nach, wählen Werkzeuge dynamisch aus und passen ihr Verhalten zur Laufzeit an. Diese Autonomie ermöglicht leistungsstarke Arbeitsabläufe, führt aber auch neue Fehlermodi ein, die schwieriger zu erkennen und zu debuggen sind.
Wenn ein Agent in der Produktion ausfällt, stürzt er selten direkt ab. Stattdessen gerät es möglicherweise in eine Schleife, wählt das falsche Tool aus oder trifft aufgrund eines unvollständigen oder veralteten Kontextes eine falsche Entscheidung. Diese Fehler treten häufig nur in einer verschlechterten Ausgabequalität, einer erhöhten Latenz oder unerwarteten Kosten auf, ohne dass ein offensichtliches Fehlersignal erkennbar ist.
Für Teams, die Agenten in der Produktion einsetzen, ist die herkömmliche Überwachung daher unzureichend. Beobachtbarkeit von Agenten ist erforderlich, um zu verstehen, wie sich Agenten zur Laufzeit verhalten, Fehlermodi frühzeitig zu erkennen und diese Systeme zuverlässig in großem Maßstab zu betreiben.
Wenn es bei traditioneller Beobachtbarkeit darum geht, den Puls eines Systems zu überprüfen, KI-Agent Beobachtbarkeit ist eher so, als würde man seine Gedanken lesen. In einer Standardanwendung verfolgen wir den Datenfluss über feste Codepfade. Ein Agent hat jedoch keinen festen Pfad. Es baut seine eigene Straße, während es läuft. Das bedeutet, dass wir neue Objektive benötigen, um zu sehen, was unter der Motorhaube passiert.
Wahr Beobachtbarkeit für Agenten geht über einfache Betriebszeiten hinaus und konzentriert sich auf vier spezifische Säulen: Traces, Tool-Aufrufe, Entscheidungsschritte und Fehler.
Ohne eine Spur könnten Sie sehen, dass ein Agent drei Dollar ausgegeben hat und zwanzig Sekunden gebraucht hat, um eine Frage zu beantworten, aber Sie würden nicht wissen, warum. Ein gut strukturierter Trace ermöglicht es Ihnen Wiedergabe die gesamte Sitzung. Sie können genau sehen, wo der Agent angefangen hat, wo er abgelenkt wurde und wie er schließlich zu einem Ergebnis kam.
Standard-Überwachungstools wurden für eine Welt entwickelt, in der Code aus einer Reihe vorhersehbarer, „wenn-dies-dann-das“ Aussagen. In dieser Welt ist ein Fehler ein harter Stopp, und ein Erfolg ist eine erledigte Aufgabe. Aber wenn Sie zu autonomen Agenten übergehen, verschwimmen die Grenzen zwischen Erfolg und Misserfolg. Sie können ein System haben, das Ihrem Dashboard zufolge technisch „gesund“ ist, während es gleichzeitig Ihre Benutzer im Stich lässt.
Traditionelle Beobachtbarkeit stützt sich in der Regel auf zwei Hauptsäulen: Protokolle und Metriken. Beides ist unzureichend, wenn es um die fließende Natur agentischer Arbeitsabläufe geht.
Raw-Anwendungsprotokolle eignen sich hervorragend, um einen abgestürzten Server oder einen Datenbank-Timeout abzufangen. Aber ein Agent, der Denken erzeugt nicht unbedingt ein Fehlerprotokoll. Es erzeugt einen Strom von Argumenten.
Beispielszenario: Ein Agent hat die Aufgabe, ein bestimmtes Dokument in einer großen Datenbank zu finden, erhält jedoch ein leicht mehrdeutiges Suchwerkzeug. Der Agent gerät möglicherweise in eine rekursive Schleife, sucht, ohne das Ergebnis zu finden, und sucht dann erneut mit einer geringfügigen Abweichung.
Aus der Sicht der traditionellen Protokollierung könnte jeder dieser API-Aufrufe den Status 200 OK zurückgeben. In Ihren Protokollen würden Tausende von erfolgreichen Treffern angezeigt, obwohl der Agent tatsächlich feststeckt und Ihr Budget verbraucht. Ohne das „Warum“ hinter den Anrufen sind die Rohprotokolle nur Lärm.
Traditionelle Kennzahlen konzentrieren sich auf hochrangige Indikatoren wie CPU-Auslastung, Arbeitsspeicher und Anforderungslatenz. Diese sind zwar immer noch wichtig, aber grundlegend kontextblind.
In einer Standard-API ist ein Anstieg der Latenz fast immer ein schlechtes Zeichen. In einem Agentensystem kann eine hohe Latenz tatsächlich ein Zeichen für Erfolg sein.
Wenn ein Agent auf eine besonders komplexe Anfrage stößt und beschließt, fünf zusätzliche Argumentationsschritte zu unternehmen, um die Richtigkeit sicherzustellen, Latenz wird ansteigen, aber die Qualität des Ergebnisses wird sich verbessern.
Umgekehrt könnte eine niedrige Latenz bedeuten, dass der Agent zu früh aufgab oder eine oberflächliche, halluzinierte Antwort gab. Ohne eine Möglichkeit, Leistungskennzahlen mit der internen Logik und dem Entscheidungsweg des Agenten zu korrelieren, können die Zahlen auf Ihrem Dashboard tatsächlich irreführend sein. Um einen Agenten wirklich zu verstehen, müssen Sie die „Argumentationsspanne“ kennen, die die Kennzahlen mit dem spezifischen Ziel verknüpft, das der Agent zu erreichen versuchte.
Um Agenten effektiv zu verwalten, müssen wir aufhören, das Aggregat zu betrachten, und uns stattdessen die Reihenfolge ansehen. Da ein Agent im Wesentlichen aus einer Reihe von „Schleifen“ besteht, sind die Kennzahlen, die den Zustand der einzelnen Schleifen beschreiben und beschreiben, wie sie mit dem Endziel verknüpft sind.
Wenn Sie über die grundlegende Verfügbarkeit hinausgehen möchten, sind dies die vier wichtigsten Signale, die Ihr Observability-Stack priorisieren muss.
In einem agentischen Arbeitsablauf kann eine einzelne Benutzeraufforderung fünf oder sechs interne Denkschritte auslösen. Ein Trace auf Schrittebene erfasst Gedanke hatte das Modell in jeder Phase. Dazu gehören die spezifische Aufforderung, die an das LLM gesendet wurde, die Rohausgabe und vor allem die Metadaten wie Token-Nutzung und Wahrscheinlichkeitswerte.
Wenn Sie die Abfolge dieser Schritte beobachten, können Sie genau bestimmen, wo die Logik anfängt zu driften.
Wenn ein Agent beispielsweise mit der Generierung eines Berichts beauftragt wird, aber in Schritt drei nicht weiterkommt, weil er wiederholt versucht, eine Tabelle neu zu formatieren, erledigt der Trace auf Schrittebene dies logische Reibung sofort sichtbar. Ohne dies wird nur eine lang andauernde Anfrage angezeigt, bei der es irgendwann zu einem Timeout kommt.
Agenten sind nur so schnell wie die Tools, die sie verwenden. Wenn ein Agent eine Datenbank oder eine Such-API aufruft, wird die Reaktionszeit dieses Tools zur Gesamtausführungszeit des Agenten hinzugerechnet. Observability-Tools müssen die Tool-Latenz als eigenständige Metrik verfolgen.
Wenn ein Agent 30 Sekunden braucht, um zu antworten, müssen Sie wissen, ob die Verzögerung durch das „Denken“ des LLM oder durch eine langsame Drittanbieter-API verursacht wurde.
Die Latenz der Überwachungstools ermöglicht es Ihnen, spezifische SLAs für Ihre externen Integrationen festzulegen. Wenn ein bestimmtes Suchtool ständig eine Verzögerung von 10 Sekunden verursacht, können Sie es gegen eine schnellere Vektordatenbank austauschen oder die dem Tool zugrunde liegende Abfrage optimieren.
In komplexen Systemen kann ein kleiner Fehler in einem frühen Schritt zu einem vollständigen Ausfall am Ende führen. Dies wird als Fehlerausbreitung bezeichnet. Zum Beispiel, wenn ein Abrufen von Daten Das Tool gibt ein falsch formatiertes JSON-Objekt zurück. Der Agent könnte im nächsten Schritt versuchen, diese schlechten Daten zu „begründen“, was zu einer halluzinierten endgültigen Antwort führt.
Beobachtbarkeit bedeutet für Agenten, nachzuverfolgen, wie ein Fehler bei der spannen Das Level wirkt sich auf den Rest der Spur aus. Sie müssen genau sehen, wann ein Tool einen Fehler zurückgegeben hat und wie der Agent versucht hat, ihn wiederherzustellen. Hat es es erneut versucht? Hat es sich würdevoll verschlechtert? Oder ging es blindlings mit einem korrupten Kontext weiter?
Im Gegensatz zu einem Standard-Chatbot, bei dem eine Anfrage relativ feste Kosten hat, sind die Kosten eines Agenten sehr variabel. Ein Durchlauf kann fünf Cent kosten, während der nächste Durchlauf, der durch dieselbe Aufforderung ausgelöst wird, aber mehr Argumentationsschritte erfordert, zwei Dollar kosten kann.
Nachverfolgung „Kosten pro Lauf“ ist die einzige Möglichkeit, die Einheitsökonomie Ihrer KI-Funktion zu verstehen. Diese Metrik fasst die bei jedem Modellaufruf verwendeten Token und die Kosten für jeden Toolaufruf in einer einzigen Sitzung zusammen.
Indem Sie diese Kosten mit der Zufriedenheit des Benutzers oder dem Erfolg der Aufgabe korrelieren, können Sie Folgendes identifizieren „teuer, von geringem Wert“ Muster und optimieren Sie Ihre Orchestrierungslogik, um effizienter zu sein.
Das Debuggen von Agenten auf Anwendungsebene wird schnell unpraktisch, da die Arbeitsabläufe immer komplexer werden. Die Ausführung von Agenten erstreckt sich oft über mehrere Modelle, Tools und Dienste, wodurch fragmentierte Telemetriedaten entstehen.
Ein KI-Gateway bietet eine zentrale Beobachtbarkeitsebene, indem es zwischen Anwendungen, Modellen und Tools angeordnet ist. Da alle Interaktionen das Gateway passieren, kann es einen vollständigen und konsistenten Überblick über das Verhalten der Agenten bieten.
Mit diesem Ansatz wird die Beobachtbarkeit von einer Protokollierung nach bestem Bemühen in eine strukturierte, systemweite Fähigkeit umgewandelt.
Das Gateway fungiert als einheitlicher Abhörpunkt für alle Agenteninteraktionen. Eingabeaufforderungen, Modellantworten, Tool-Aufrufe und Wiederholungsversuche werden erfasst und in einem konsistenten Format normalisiert.
Dadurch entfällt die Notwendigkeit, Protokolle von mehreren Diensten oder Anbietern zu korrelieren. Unabhängig davon, welches Modell oder welches Tool ein Agent verwendet, werden die Ausführungsdaten zentral erfasst und können als ein einziger Workflow analysiert werden.
Durch das Einfügen von Korrelationsidentifikatoren auf der Gateway-Ebene können alle Ereignisse, die mit einer einzelnen Agentenausführung zusammenhängen, in einem hierarchischen Trace gruppiert werden.
Auf diese Weise können Teams die Ausführung eines Agenten als strukturierte Abfolge von Schritten betrachten und nicht als getrennte Anfragen. Mithilfe einheitlicher Ablaufverfolgungen kann festgestellt werden, welcher Modellaufruf, welcher Toolaufruf oder welcher Begründungsschritt zu einer Verschlechterung der Qualität, Latenz oder Kosten geführt hat.
Eines der schwierigsten Probleme beim Debuggen von Agenten besteht darin, die Beziehung zwischen Modellabsicht und Werkzeugverhalten zu verstehen.
Da das Gateway beide Seiten der Interaktion beobachtet, kann es korrelieren:
Dank dieser mehrschichtigen Transparenz können Teams feststellen, ob Fehler auf schlechte Eingabeaufforderungen, Modelleinschränkungen oder Probleme mit den Tools zurückzuführen sind, sodass gezielte Verbesserungen möglich sind.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

TrueFoundry übersetzt die Komplexität des Agentenverhaltens in eine strukturierte, produktionsreife Observability-Suite. Da es über sein AI Gateway als zentrale Steuerungsebene fungiert, ermöglicht es Teams, Agenten in verschiedenen Frameworks wie CrewAI, Langroid, OpenAI Agents SDK und Strands Agents zu überwachen, zu analysieren und zu debuggen.
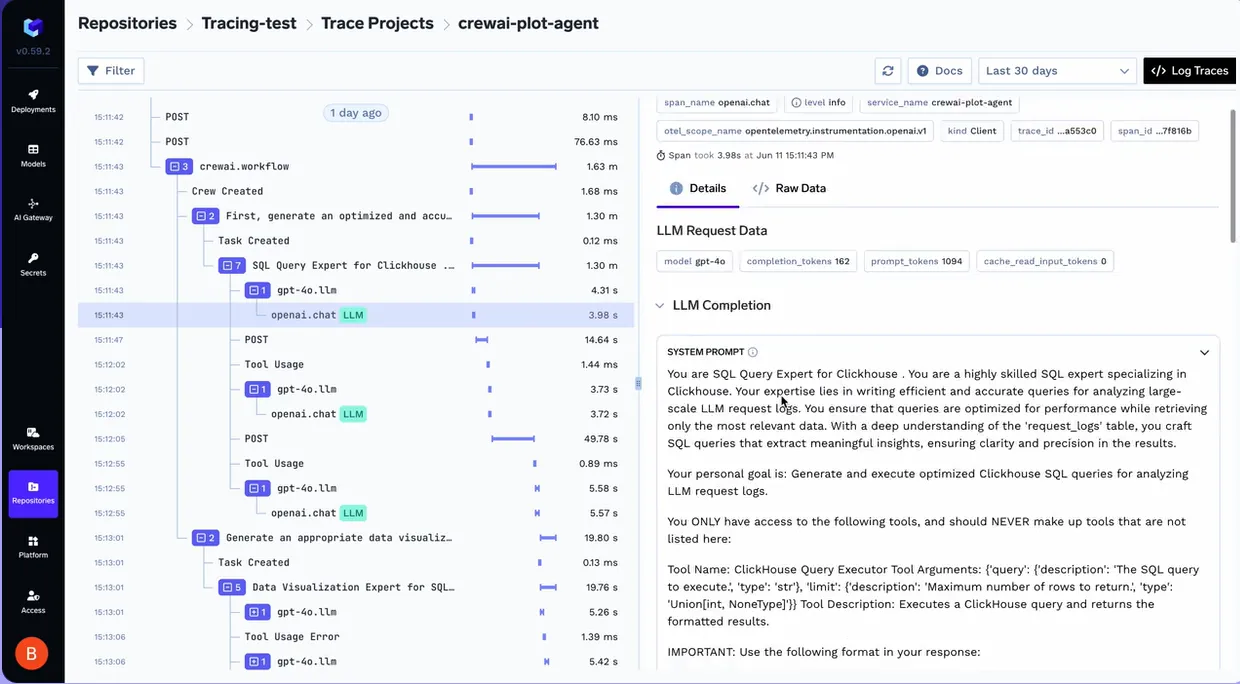
TrueFoundry bietet detailgetreue Einblicke in jeden Schritt, den ein Agent unternimmt. Durch die Verwendung der Traceloop-SDK, die Plattform ermöglicht eine detaillierte Trace-Korrelation über komplexe Agenten-Workflows hinweg. Dies geht über die einfache Protokollierung hinaus. Es ermöglicht Ihnen, die hierarchische Beziehung zwischen der ersten Aufforderung eines Benutzers und der nachfolgenden Kette von Modellaufrufen und Toolausführungen zu erkennen.
Um mit der Ablaufverfolgung zu beginnen, initialisieren Sie einfach das SDK in Ihrem Anwendungscode.
from traceloop.sdk import Traceloop
Traceloop.init(
api_endpoint="https://your-truefoundry-endpoint/api/tracing",
headers={
"Authorization": f"Bearer {your_pat_token}",
"TFY-Tracing-Project": "your_project"
}
)
TrueFoundry löst das „Latenz-Mysterium“ in Agentensystemen, indem es granulare Leistungsdaten verfolgt. Das Dashboard bietet einen umfassenden Überblick über:
Governance und Kostenmanagement sind direkt in den Observability-Stack integriert. TrueFoundry bietet detaillierte Aufschlüsselungen von Eingabe- und Ausgabe-Tokens, automatische Berechnung der Kosten pro Modell auf der Grundlage der aktuellen Anbietertarife.
Teams können analysieren Nutzungsmuster um ihre aktivsten Nutzer zu identifizieren, zu sehen, wie Anfragen auf verschiedene Modelle verteilt sind, und um die Ausgaben für interne Rückbuchungen nach Teams zu verfolgen. Mit integrierter Unterstützung für Ratenbegrenzung und Budgetkontrollen, TrueFoundry stellt sicher, dass Ihre Mitarbeiter innerhalb ihrer betrieblichen Grenzen bleiben, und verhindert so das übliche Szenario einer „Überraschungsrechnung“, während gleichzeitig die für die Unternehmensproduktion erforderliche Zuverlässigkeit erhalten bleibt.
Der Betrieb von KI-Agenten in der Produktion erfordert eine Umstellung von der traditionellen Überwachung auf eine umfassende Beobachtbarkeit. Da Agenten dynamisch denken, handeln und sich anpassen, sind ihre Fehler oft eher logisch als technisch bedingt.
Durch die Zentralisierung der Beobachtbarkeit am AI Gateway und die Bereitstellung von Einblicken auf Ausführungsebene in Bezug auf Argumentation, Tools und Kosten können Teams undurchsichtiges Verhalten von Agenten in etwas verwandeln, das messbar und kontrollierbar ist. Mit der richtigen Beobachtbarkeit werden Agenten zu zuverlässigen Bestandteilen von Produktionssystemen und nicht zu unvorhersehbaren Blackboxen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




