











Fine-Tune Any Model
Fine-tune LLMs and classical ML models using Hugging Face integrations and production-ready templates
No-Code or Full-Code Fine-Tuning
Start fast with a no-code UI or bring your own training scripts for full control and flexibility.
PEFT & Full Fine-Tuning
Support LoRA, QLoRA, and full fine-tuning to balance cost, memory usage, and model performance.
Checkpointing & Versioning
Automatically checkpoint runs, resume training, and version models and datasets for reproducibility.
Built-in Experiment Tracking
Track hyperparameters, metrics, datasets, and outputs across fine-tuning runs.
Adapter Management
Train, reuse, merge, and switch LoRA adapters to speed up fine-tuning and reduce cost.
.webp)
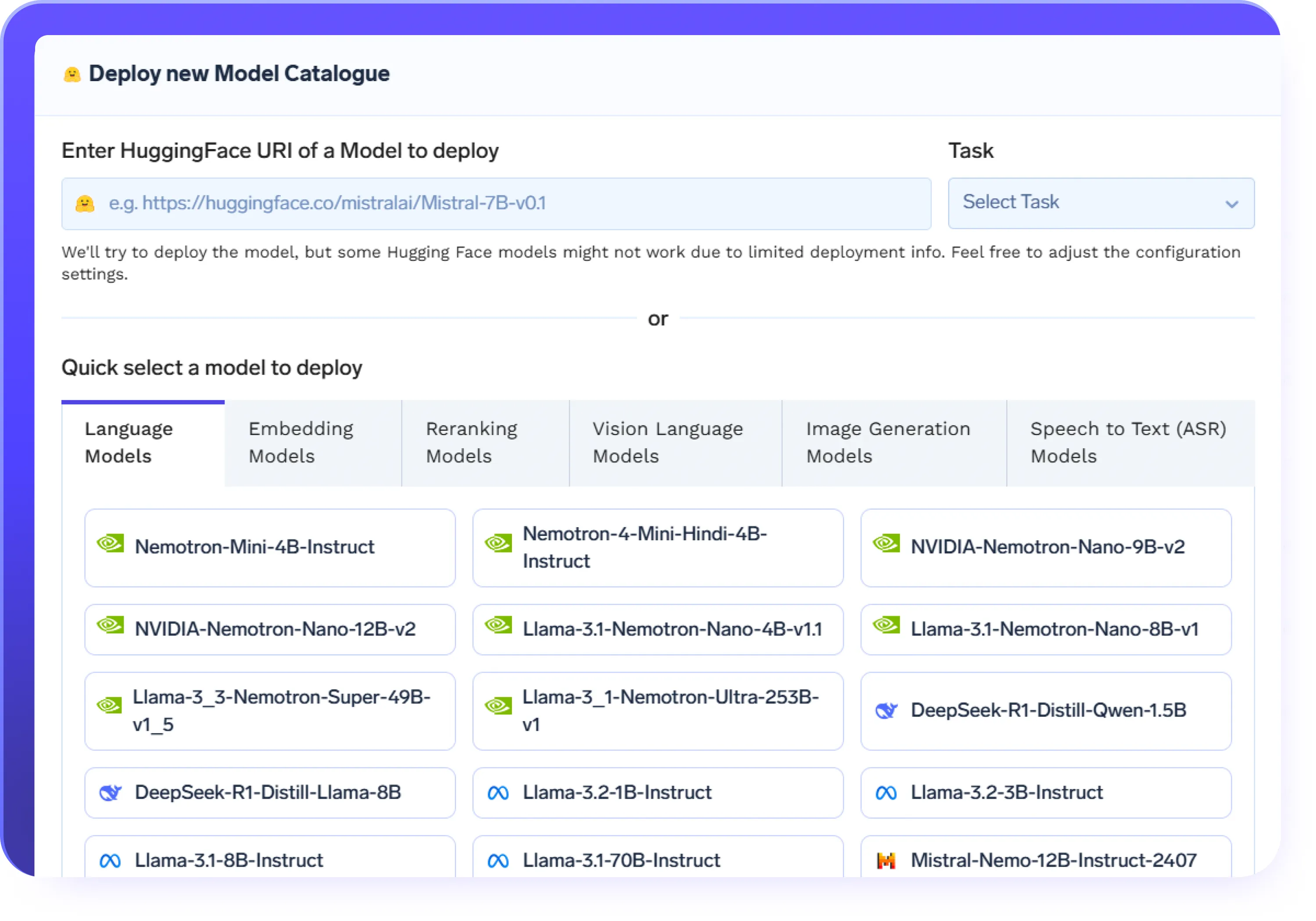
Fine-Tune Any Hugging Face Model / Classical ML Model
- Supports finetuning LLMs like LLaMA, Mistral, BERT, Falcon, and GPT-J
- Start finetuning LLMs in minutes using the built-in Hugging Face model hub
- Preconfigured templates simplify the process of finetuning large language models
- Scalable infrastructure handles everything from small experiments to production-grade LLM finetuning
No-Code or Full-Code - Your Choice
- Fine-tune LLMs using a no-code UI for fast setup and rapid iteration
- Bring your own training scripts with full control in code mode
- Automatically manage infrastructure and resource scaling
- Get full transparency into each finetuning run, with built-in logs, metrics, and version control.
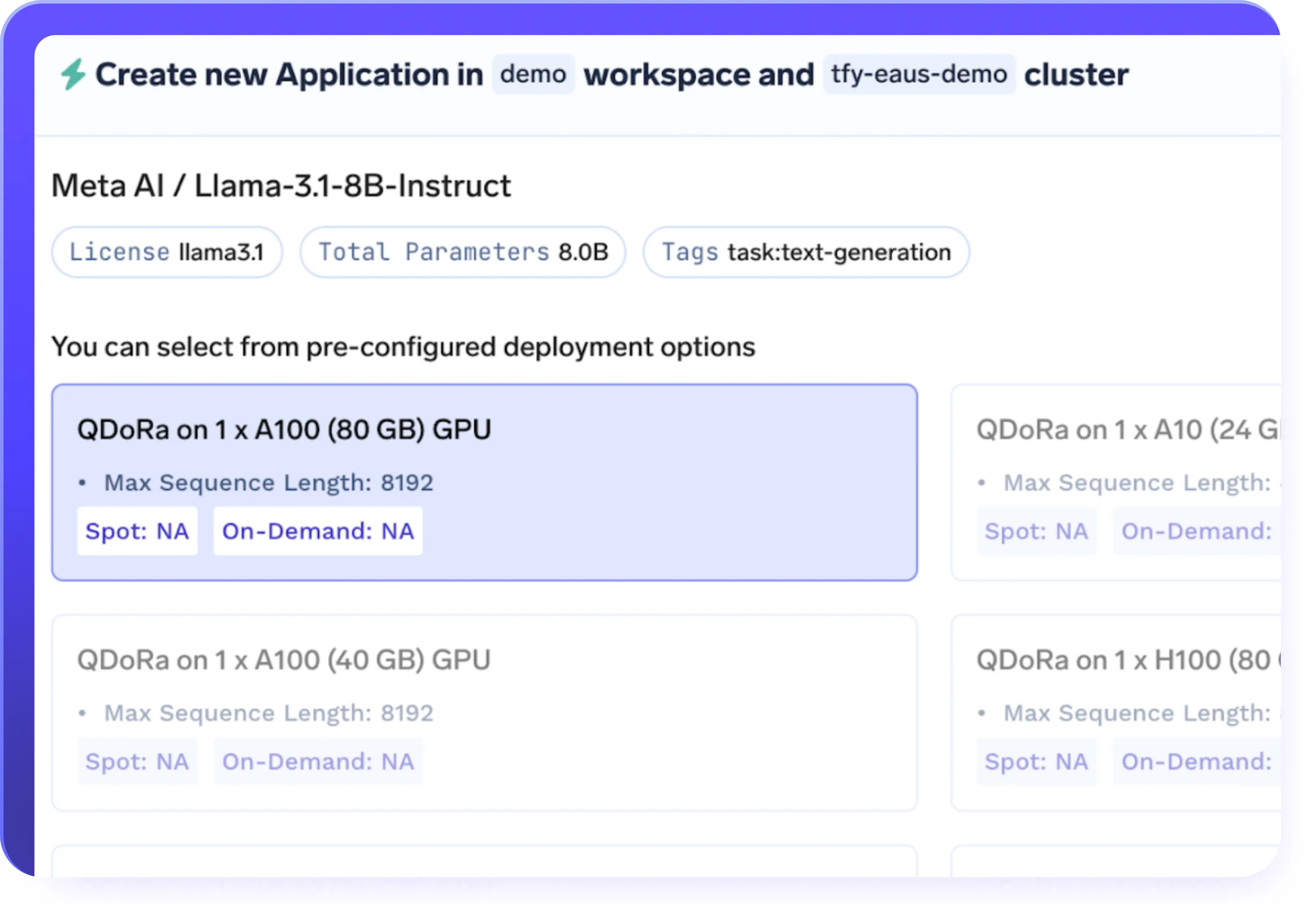
PEFT (LoRA / QLoRA) & Full Finetuning Support
- Support parameter-efficient fine-tuning (LoRA, QLoRA) as well as full-model fine-tuning
- Choose LoRA or QLoRA for faster and more cost-effective fine-tuning of large LLMs
- Reduce GPU memory usage while retaining model quality and performance
- Select the right fine-tuning approach based on model size, cost, and workload needs
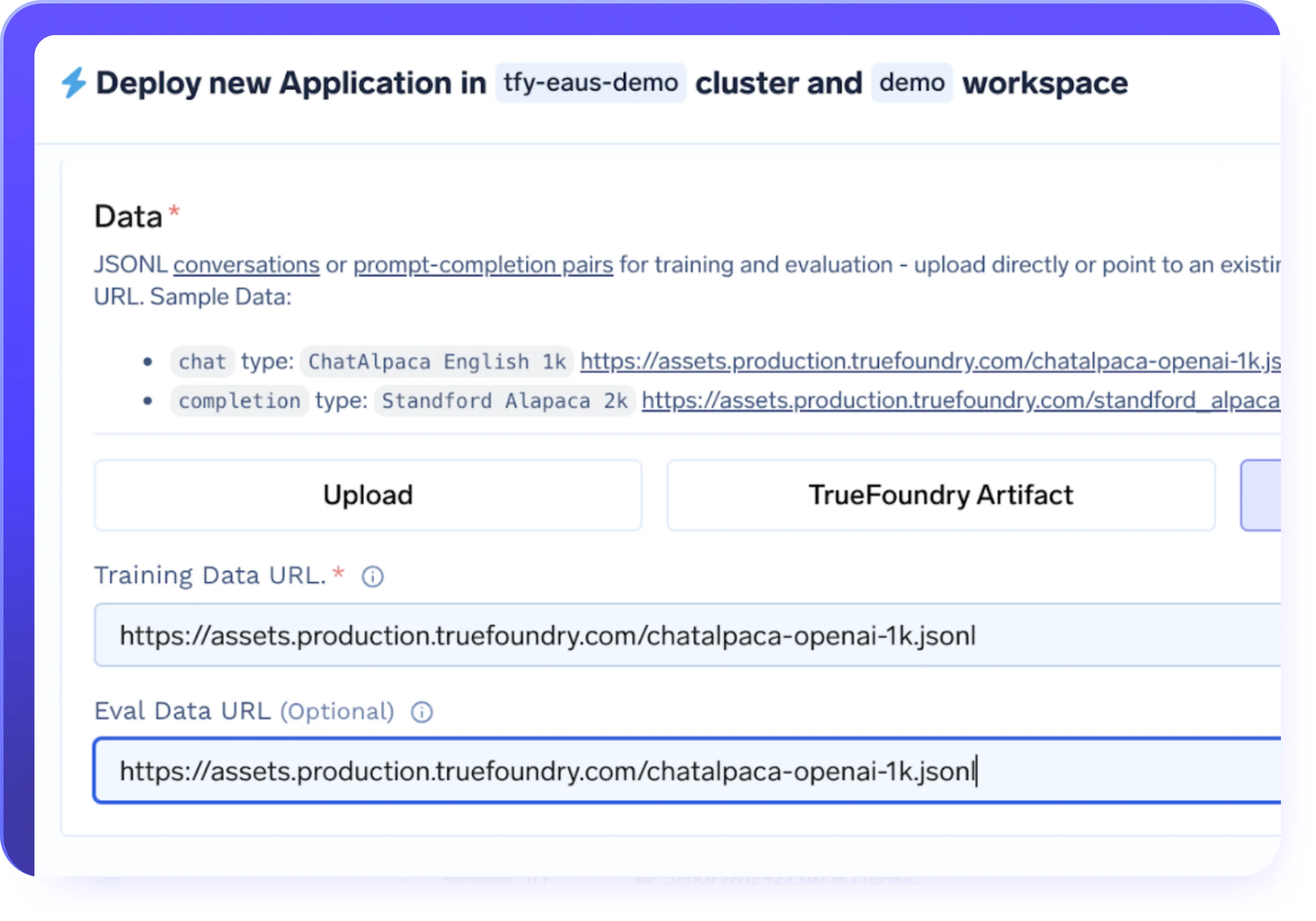
Checkpointing & Versioning
- Save checkpoints automatically during fine-tuning to prevent training progress loss
- Resume interrupted or paused fine-tuning jobs from any checkpoint
- Version models, datasets, and training runs for full reproducibility
- Roll back to previous checkpoints and compare performance across versions
Built-in Experiment Tracking
- Auto-log all training metadata: hyperparameters, metrics, datasets, and outputs
- Compare multiple runs to fine-tune LLMs more effectively
- Integrate with your LLMops stack or use our native visual interface
- Built-in version control ensures reproducibility and auditability
Adapter Management for Efficient LLM Finetuning
- Leverage LoRA adapters to fine-tune models by updating only a small set of parameters.
- Reuse pre-trained adapters across projects and domains
- Merge or switch adapters across different tasks, allowing rapid experimentation and modular model design
- Speed up training and reduce costs by training compact adapter modules instead of full LLM weights
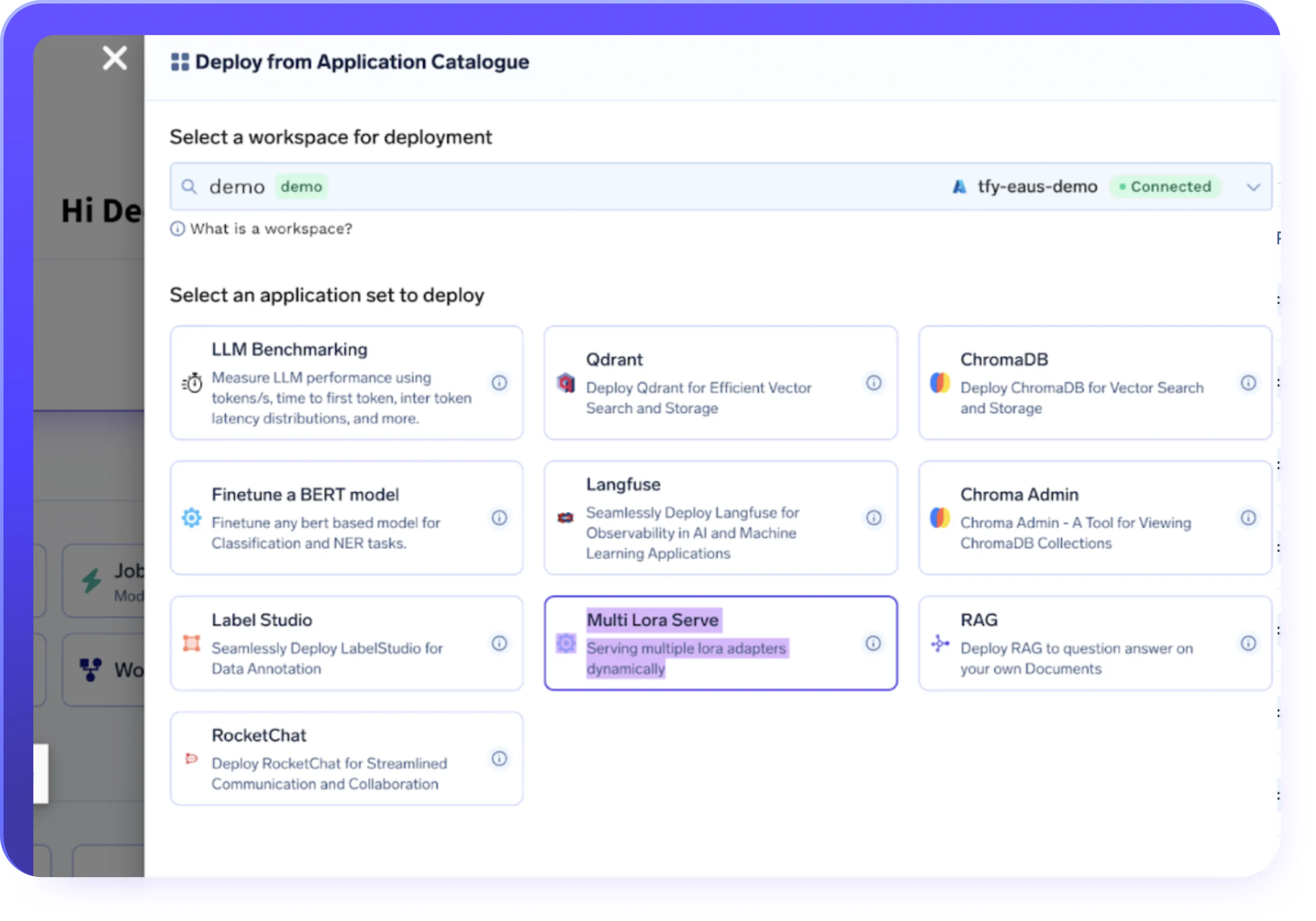
Data & Infra Integrations
- Import datasets from S3, GCS, Azure Blob, or Hugging Face Datasets
- Run fine-tuning jobs on fully managed infrastructure or your own clusters
- Deploy workloads across cloud, hybrid, or on-prem environments
- Use GPU autoscaling, time-slicing, and cost-aware provisioning by default
Made for Real-World AI at Scale
Enterprise-Ready
Deploy a secure AI gateway that keeps your data and models within your cloud / on-prem infrastructure.


Compliance & Security
SOC 2, HIPAA, and GDPR standards to ensure robust data protectionGovernance & Access Control
SSO + Role-Based Access Control (RBAC) & Audit LoggingEnterprise Support & Reliability
24/7 support with SLA-backed response SLAs
VPC, on-prem, air-gapped, or across multiple clouds.
No data leaves your domain. Enjoy complete sovereignty, isolation, and enterprise-grade compliance wherever TrueFoundry runs


Real Outcomes at TrueFoundry
Why Enterprises Choose TrueFoundry






3x
faster time to value with autonomous LLM agents
80%
higher GPU‑cluster utilization after automated agent optimization

Aaron Erickson
Founder, Applied AI Lab
TrueFoundry turned our GPU fleet into an autonomous, self‑optimizing engine - driving 80 % more utilization and saving us millions in idle compute.
5x
faster time to productionize internal AI/ML platform
50%
lower cloud spend after migrating workloads to TrueFoundry

Pratik Agrawal
Sr. Director, Data Science & AI Innovation
TrueFoundry helped us move from experimentation to production in record time. What would've taken over a year was done in months - with better dev adoption.
80%
reduction in time-to-production for models
35%
cloud cost savings compared to the previous SageMaker setup
.webp)
Vibhas Gejji
Staff ML Engineer
We cut DevOps burden and simplified production rollouts across teams. TrueFoundry accelerated ML delivery with infra that scales from experiments to robust services.
50%
faster RAG/Agent stack deployment
60%
reduction in maintenance overhead for RAG/agent pipelines
.webp)
Indroneel G.
Intelligent Process Leader
TrueFoundry helped us deploy a full RAG stack - including pipelines, vector DBs, APIs, and UI—twice as fast with full control over self-hosted infrastructure.
60%
faster AI deployments
~40-50%
Effective Cost reduction of across dev environments
.webp)
Nilav Ghosh
Senior Director, AI
With TrueFoundry, we reduced deployment timelines by over half and lowered infrastructure overhead through a unified MLOps interface—accelerating value delivery.
<2
weeks to migrate all production models
75%
reduction in data‑science coordination time, accelerating model updates and feature rollouts
.webp)
Rajat Bansal
CTO
We saved big on infra costs and cut DS coordination time by 75%. TrueFoundry boosted our model deployment velocity across teams.
Frequently asked questions
What is LLM finetuning and why is it important?
How does TrueFoundry simplify LLM finetuning?
- No-code & full-code workflows: Use an intuitive UI or custom training scripts
- Built-in experiment tracking: Auto-log hyperparameters, metrics, and model versions
- Infrastructure orchestration: Run jobs on TrueFoundry-managed infra or your own cloud/VPC
- Support for PEFT methods: Native support for LoRA and QLoRA-based finetuning
- Checkpointing & versioning: Resume training seamlessly and maintain reproducibility
- Adapter management: Reuse, merge, or deploy adapters across multiple tasks/models
What types of models can I fine-tune on TrueFoundry?
- Decoder-based LLMs (e.g., LLaMA, GPT-J, Falcon, Mistral)
- Encoder models (e.g., BERT, RoBERTa, DistilBERT)
- Encoder-decoder models (e.g., T5, FLAN-T5)
Can I bring my own dataset and training code?
- Bring your own datasets from S3, GCS, Azure, Hugging Face Hub, or local files
- Bring your own code via custom training scripts (PyTorch, Transformers, PEFT, etc.)
- Or use pre-built templates for common finetuning workflows
How does TrueFoundry support LoRA and QLoRA finetuning?
- Use our UI to configure LoRA layers and hyperparameters
- Save and deploy LoRA adapters independently of base models
- Merge adapters with base models for deployment or offline inference
- Reduce GPU memory usage drastically—ideal for enterprises optimizing infra spend
Can I deploy finetuned models from TrueFoundry into production?
- Deploy models with vLLM, SGLang, or other inference servers
- Expose your model as an API with integrated rate limiting and RBAC
- Monitor real-time latency, token usage, and performance
- Use adapters for fast deployment or merge with base model for standalone inference

GenAI infra- simple, faster, cheaper
Trusted by 30+ enterprises and Fortune 500 companies








