



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 8, 2026

Blazingly fast way to build, track and deploy your models!
Large Language Models (LLMs) have become the backbone of modern AI applications, powering everything from chatbots and virtual assistants to research tools and enterprise solutions. However, not all LLMs are created equal—each has unique strengths, limitations, and cost factors. Some excel at reasoning, while others are better at creative writing, coding, or handling structured queries. This is where an LLM Router comes in.
An LLM Router acts like an intelligent traffic controller, automatically directing user prompts to the most suitable model based on the task at hand. Instead of relying on a single model, businesses and developers can optimize performance, accuracy, and costs by routing queries to the right LLM in real time. As AI adoption grows, LLM routing is becoming an essential layer for building scalable, reliable, and efficient AI systems.
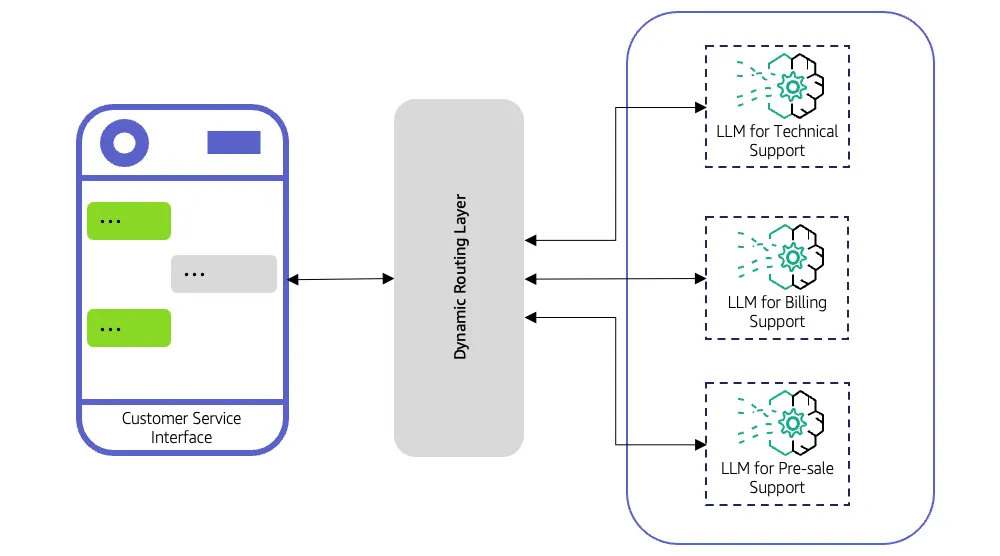
An LLM Router decides which Large Language Model should handle each request. Instead of sending every query to a single model, it evaluates the input, applies routing logic, and forwards it to the most suitable model.
The router can follow simple rules, such as directing code-related queries to a programming-focused model, or use advanced strategies like classifiers, embeddings, or lightweight predictive models to determine which LLM will deliver the best response.
How It Works
This approach eliminates the “one-size-fits-all” problem. Lightweight models handle routine queries efficiently, while complex or reasoning-heavy tasks go to more capable LLMs.
Practically, the router sits between applications and multiple LLMs, optimizing performance, reducing costs, and minimizing dependence on any single provider. This setup ensures that every request reaches the right model while keeping AI systems reliable and flexible.
Companies increasingly rely on Large Language Models for tasks ranging from chatbots and virtual assistants to content creation and data analysis.
Using a single LLM for all tasks, however, creates challenges. Some models respond quickly but lack depth, while others provide accurate results at high latency and cost. Without a way to manage these differences, teams constantly trade off performance, accuracy, and budget.
An LLM Router solves this by intelligently directing requests to the model best suited for the task.
Consider this scenario -
A customer support system receives two types of queries.
A simple request like “What are your working hours?” doesn’t need a highly advanced model, while a complex technical question about product troubleshooting does. Without an LLM Router, all queries might go to a high-powered, expensive model. This increases cost and slows down response times. With a router, the simple query goes to a fast, lightweight model, while the complex one is routed to a more capable LLM, optimizing speed, cost, and accuracy.
Benefits for Companies
By intelligently routing queries, companies deliver faster, more accurate, and cost-effective AI services. LLM Routers transform AI deployment from a one-size-fits-all approach into a flexible, reliable, and efficient system, making them essential for modern AI infrastructure.
An LLM Router is more than a traffic director, it provides several core functions that make AI systems smarter, faster, and more reliable. Understanding these functions helps organizations design AI workflows that scale efficiently while maintaining quality.
Before any routing happens, the router analyzes incoming queries. It examines metadata, tags, query type, complexity, and sometimes intent or sentiment. This analysis provides context so the router can decide which model is best suited to handle the request. For example, a customer question about billing can be routed to a lightweight general-purpose LLM, while a technical troubleshooting query is sent to a domain-specific model.
The router selects the most appropriate model based on multiple criteria, including:
By considering these factors, the router ensures each request gets the best balance of speed, accuracy, and cost.
When multiple models can handle the same task, the router distributes requests intelligently to avoid overloading any single model. This improves overall system responsiveness and ensures consistent performance during peak usage.
Even the best models can fail, time out, or return low-confidence responses. The router implements fallback mechanisms, automatically rerouting queries to backup models. This ensures continuity and reliability without user disruption.
Advanced routers track usage patterns, model performance, and query outcomes. These insights help teams optimize routing strategies, select better models, and reduce costs over time.
An LLM Router acts as the decision-making hub of multi-model AI systems. By analyzing requests, selecting the right model, balancing load, handling failures, and providing insights, it ensures that every query is processed efficiently, accurately, and reliably. This combination of functions makes LLM Routers a critical component in building robust, scalable, and cost-effective AI solutions.
LLM routers use different strategies to direct queries to the most suitable language model efficiently. These strategies generally fall into three categories: static, dynamic, and hybrid, with advanced systems sometimes incorporating reinforcement learning.
Static routing relies on predefined rules to decide which model handles a query. It ensures consistent routing behavior and is easy to implement.
Dynamic routing adapts in real-time, selecting models based on current system performance and query context.
Hybrid strategies combine static and dynamic approaches for greater flexibility and efficiency.
Some advanced systems use reinforcement learning to continuously improve routing decisions. These routers learn from past queries and model performance, optimizing routing over time for complex or evolving workloads.
An LLM Router provides several key benefits that make AI systems more efficient, reliable, and cost-effective. One of the primary advantages is optimized performance.
By intelligently routing each query to the model best suited for the task, the router ensures that powerful, reasoning-capable models handle complex questions, while lightweight, faster models process simpler requests. This approach balances speed and accuracy, improving the overall user experience.
Another significant benefit is cost efficiency. Without a router, companies may run all queries through high-powered models, which increases operational costs unnecessarily. The router ensures that expensive models are reserved for high-value or complex queries, while routine or repetitive tasks are handled by less resource-intensive models, reducing compute expenses and maximizing ROI.
Reliability also improves with an LLM Router. Advanced routers include fallback mechanisms that automatically redirect queries if a model fails, times out, or returns low-confidence results. This ensures consistent and dependable performance, preventing disruptions in real-time applications like customer support or virtual assistants.
Additionally, LLM Routers provide flexibility. Organizations can integrate multiple models from different providers, choosing the best one for each task.
This reduces dependency on a single vendor and allows teams to experiment with different models as new capabilities emerge.
Finally, routers support scalability. As query volumes grow, the router distributes requests intelligently across models, preventing overload and maintaining smooth system performance.
By combining optimized routing, cost savings, reliability, flexibility, and scalability, an LLM Router transforms AI deployments from a rigid single-model approach into a dynamic, efficient, and resilient system.
LLM Routers are increasingly used across enterprises to optimize AI performance, reliability, and efficiency. They enable intelligent query routing, ensuring the right model handles each task based on complexity, domain, and context.
Customer Support Automation
Enterprises handle thousands of customer queries daily, from simple FAQs to complex technical issues. LLM Routers direct routine questions to fast, lightweight models while routing complicated issues to more capable models. This ensures fast, accurate, and consistent responses, improving customer satisfaction and reducing operational strain.
Gestão do Conhecimento e Pesquisa Empresarial
As empresas mantêm grandes repositórios de documentos internos, manuais e políticas. Os roteadores analisam as consultas e as direcionam para modelos otimizados para raciocínio, sumarização ou conhecimento específico do domínio. Os funcionários recebem informações precisas e contextualmente relevantes sem sobrecarregar modelos de alto custo.
Automação de Fluxos de Trabalho e Tarefas
LLMs são amplamente utilizados para geração de relatórios, análise de dados e tarefas de suporte à decisão. Os roteadores atribuem dinamicamente consultas de alta complexidade a modelos poderosos e tarefas rotineiras a modelos mais leves, equilibrando velocidade, precisão e custos de computação em todos os fluxos de trabalho empresariais.
Orquestração Multi-Modelo
As organizações frequentemente implementam múltiplos LLMs em diferentes provedores ou domínios. Os roteadores gerenciam a seleção de modelos, o balanceamento de carga e os mecanismos de fallback, garantindo confiabilidade, flexibilidade e escalabilidade em sistemas de IA de grande escala.
Recomendações de Produtos e Personalização
Para plataformas de E-commerce ou SaaS, os Roteadores LLM podem atribuir tarefas de personalização a modelos treinados no comportamento e contexto do usuário, enquanto delegam recomendações genéricas a modelos mais simples. Isso melhora a precisão e o desempenho das recomendações, ao mesmo tempo em que controla os custos.
Conformidade e Análise de Risco
Em empresas de finanças, jurídicas ou de saúde, as consultas podem exigir estrita adesão a regulamentações ou diretrizes específicas do domínio. Os roteadores podem direcionar consultas sensíveis ou de alto risco para modelos com experiência no domínio, garantindo a conformidade enquanto as tarefas gerais são tratadas por modelos padrão.
Geração e Sumarização de Conteúdo
Para marketing, partilha de conhecimento ou documentação, os Roteadores LLM podem alocar tarefas complexas de criação de conteúdo para modelos de alta qualidade e tarefas mais simples de sumarização ou rascunho para modelos mais rápidos, otimizando a eficiência sem comprometer a qualidade da saída.
Ao aplicar Roteadores LLM nestes diversos cenários, as empresas podem escalar a IA de forma inteligente, mantendo o desempenho, a confiabilidade e a relação custo-benefício em múltiplos fluxos de trabalho e aplicações.
Após explorar como os Roteadores LLM impulsionam uma vasta gama de aplicações empresariais, é importante entender como eles diferem de outro componente chave em sistemas de IA multi-modelo.
Um Roteador LLM está focado no roteamento inteligente de requisições. Sua função principal é analisar as consultas recebidas, avaliar o contexto, a complexidade e os metadados, e então direcionar cada requisição para o modelo mais adequado. Os roteadores frequentemente incorporam estratégias avançadas, como roteamento dinâmico, tomada de decisão sensível ao contexto e mecanismos de fallback para otimizar a precisão, a velocidade e o custo.
Eles são particularmente críticos em ambientes onde as consultas variam amplamente em tipo, domínio ou requisitos computacionais, permitindo que as empresas equilibrem a carga e mantenham alto desempenho.
Um Gateway LLM, por outro lado, atua como um ponto de acesso centralizado para interagir com um ou vários LLMs. Seu papel principal é simplificar a integração, fornecer APIs padronizadas, gerenciar a autenticação, lidar com o controle de taxa (rate-limiting) e monitorar o uso.
Ao contrário dos roteadores, os gateways geralmente não tomam decisões inteligentes de seleção de modelo; eles fornecem acesso uniforme e controles operacionais para facilitar implantações multi-modelo. Os gateways se concentram mais na gestão em nível de infraestrutura, segurança e escalabilidade, em vez da otimização em nível de consulta.
Principais diferenças
Roteadores e gateways frequentemente trabalham juntos em arquiteturas em camadas. O gateway fornece um ponto de entrada seguro e padronizado para as aplicações, enquanto o roteador fica atrás dele, tomando decisões inteligentes de seleção de modelo. Essa combinação permite que as empresas alcancem tanto o controle operacional quanto o tratamento otimizado de consultas.
Compreender a distinção entre Roteadores LLM e Gateways LLM ajuda as organizações a implantar sistemas de IA multi-modelo de forma eficaz.
Roteadores impulsionam um desempenho inteligente e sensível ao contexto, enquanto gateways garantem acesso seguro, escalável e confiável, criando uma base robusta para a IA empresarial.
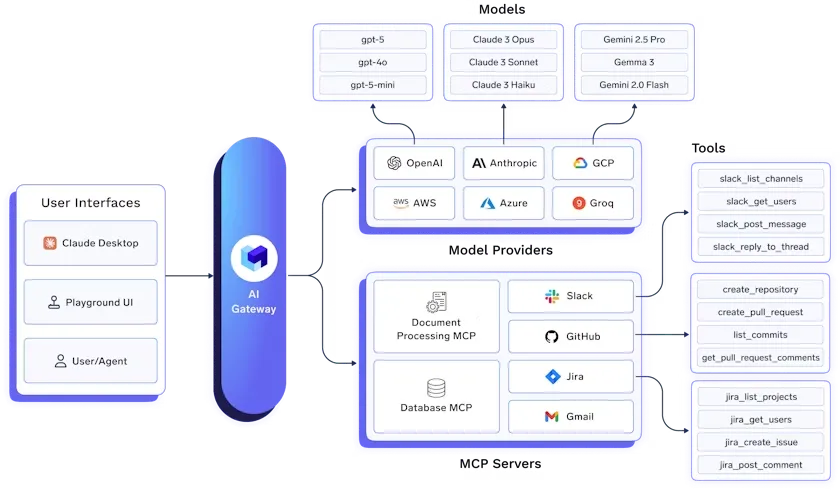
O Gateway LLM TrueFoundry é uma plataforma pronta para empresas que unifica o acesso a todos os principais modelos de linguagem grandes (LLMs) através de uma API única, segura e de alto desempenho.
Ele simplifica a infraestrutura de GenAI ao integrar mais de 250 modelos, incluindo OpenAI, Anthropic Claude, Gemini, Groq, Mistral e frameworks de código aberto, sem exigir alterações no código. As equipes podem usar uma API consistente para cargas de trabalho de chat, conclusão, embedding e reranking, enquanto centralizam a autenticação e o gerenciamento de chaves de API.
Principais Recursos:
À medida que as empresas dependem cada vez mais de múltiplos Grandes Modelos de Linguagem, ferramentas como Roteadores LLM e Gateways LLM tornaram-se indispensáveis para gerenciar IA em escala. Roteadores LLM trazem inteligência ao sistema, analisando cada consulta e garantindo que ela chegue ao modelo mais adequado para a tarefa. Isso melhora o desempenho, reduz custos e aumenta a confiabilidade, especialmente em fluxos de trabalho complexos e de alto volume.
Os Gateways, por sua vez, fornecem a espinha dorsal para acesso seguro e padronizado aos modelos, simplificando a integração, monitorando o uso e aplicando controles operacionais.
Juntos, esses componentes formam uma arquitetura de IA em camadas que equilibra inteligência com eficiência operacional. Ao combinar as capacidades de tomada de decisão dos roteadores com a confiabilidade estrutural dos gateways, as organizações podem maximizar o valor de múltiplos LLMs, mantendo a escalabilidade e o controle.
A adoção de Roteadores LLM não é mais opcional; é uma necessidade para empresas que visam fornecer serviços de IA rápidos, precisos e econômicos. Compreender seu papel, juntamente com os gateways, capacita as equipes a projetar infraestruturas de IA robustas que atendam às diversas necessidades de negócios.
À medida que os modelos de IA continuam a evoluir e se multiplicar, dominar o roteamento inteligente e o acesso estruturado será fundamental para empresas que buscam permanecer competitivas no cenário de IA em rápido avanço.
O roteamento LLM funciona avaliando as solicitações recebidas em relação a lógicas predefinidas, embeddings semânticos ou regras de classificação. O sistema roteia o tráfego com base no contexto, precisão necessária ou latência do provedor upstream. Um gateway centralizado gerencia essas configurações complexas para automatizar a seleção de modelos e o failover sem exigir alterações manuais de código para cada atualização de modelo.
A classificação de roteamento LLM usa um modelo altamente eficiente para categorizar prompts antes da execução da inferência. Esta etapa identifica a intenção, como saudações simples versus tarefas de codificação complexas. A classificação automatizada evita a superutilização de modelos de ponta caros, filtrando consultas de baixa complexidade para alternativas menores, mais rápidas e mais econômicas.
A TrueFoundry unifica os recursos de roteamento LLM e AI Gateway, mesclando a orquestração de tráfego com governança e segurança. A plataforma gerencia failover de modelo, limitação de taxa e roteamento consciente de custos dentro de um único plano de controle centralizado. Esta infraestrutura garante que as implantações de IA corporativas sejam altamente resilientes e econômicas para ambientes de produção em larga escala.
Os principais roteadores LLM incluem TrueFoundry para orquestração de nível empresarial, LiteLLM para uma API proxy unificada e Martian para seleção automatizada de modelos. Outras opções líderes do setor incluem Portkey para guardrails avançados, Helicone para observabilidade extremamente rápida e OpenRouter para acesso simples a centenas de modelos de código aberto e fechado.
Roteadores LLM examinam metadados, tipo e contexto da consulta para escolher um modelo. Os fatores de seleção incluem expertise no domínio, capacidade de raciocínio, latência e custo. Consultas simples vão para modelos leves, tarefas complexas para modelos de alta capacidade. Roteadores avançados podem usar embeddings ou classificadores preditivos para roteamento de modelo inteligente em tempo real.
As funções principais de um roteador LLM incluem análise de solicitações, seleção inteligente de modelos, balanceamento de carga, tratamento de fallback e monitoramento. Os roteadores distribuem consultas por múltiplos LLMs, redirecionam solicitações com falha e monitoram o desempenho. Isso garante que as tarefas sejam processadas de forma eficiente, os modelos sejam otimamente utilizados e o sistema permaneça confiável e escalável em fluxos de trabalho de IA corporativos.
Os tipos comuns de roteadores LLM incluem roteamento baseado em regras, roteamento baseado em custo, roteamento baseado em desempenho e roteamento baseado em tarefas. Roteadores baseados em regras seguem condições predefinidas, roteadores baseados em custo escolhem modelos mais baratos, roteadores baseados em desempenho selecionam modelos com melhor precisão ou velocidade, e roteadores baseados em tarefas enviam solicitações para modelos especializados em tarefas como codificação, chat ou sumarização.
O roteamento LLM é feito analisando a solicitação do usuário e direcionando-a para o modelo mais adequado. Os desenvolvedores definem regras ou usam algoritmos que consideram fatores como tipo de tarefa, custo, latência e capacidade do modelo. Uma camada de roteamento avalia a entrada e envia automaticamente a consulta para o LLM apropriado.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




