



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Toda sexta-feira, digito a mesma coisa:
"Sou Prathamesh. Engenheiro de Software Sênior na TrueFoundry. Trabalhando no serviço de memória. Formato: o que entreguei, o que está em andamento, impedimentos. Mantenha conciso."
Então peço minha atualização semanal.
A IA escreve perfeitamente. Mas na próxima sexta-feira? O mesmo ritual. Ela não vai se lembrar do meu nome, do meu cargo, do meu projeto, ou que mencionei o mesmo impedimento por três semanas seguidas.
Eu mesmo construí este assistente: UI de chat simples, AI Gateway da TrueFoundry no backend. Ele lida com reuniões diárias, e-mails, mensagens do Slack, rascunhos de documentação. É genuinamente útil. Mas cada sessão começa do zero. Não estou usando a memória da IA. Eu sou a memória da IA.
O ChatGPT resolveu isso com memória integrada. Mas quando você constrói sua própria aplicação LLM, essa infraestrutura não existe. Você está por conta própria. A menos que você a construa.
Então eu fiz. TrueMem é uma camada de memória persistente para aplicações de IA. Ela oferece a qualquer LLM uma memória de longo prazo que funciona em várias sessões e até mesmo em diferentes modelos. Chega de se repetir. A IA realmente se lembra.
As soluções óbvias têm problemas óbvios.
A memória integrada do ChatGPT está bloqueada dentro do ecossistema da OpenAI. Você não pode acessá-la programaticamente, usá-la com outros modelos ou auditar o que está sendo armazenado. O AI Gateway da Truefoundry nos ajuda a acessar múltiplos modelos, auditar o que está sendo armazenado. Para quem está construindo suas próprias aplicações, é um ponto de partida inviável.
Geração Aumentada por Recuperação (RAG) resolve um problema diferente. RAG recupera informações de documentos. Ele responde "o que este PDF diz?" A memória do usuário é fundamentalmente diferente. É pessoal, evolutiva e baseada em relacionamentos. Os fatos que partilho numa conversa não são documentos a serem indexados; são contexto que deve moldar cada interação futura.
Expandir as janelas de contexto é a abordagem de força bruta: incluir todo o histórico da conversa. Modelos modernos suportam 128K tokens ou mais, então por que não? Porque os tokens são caros, mais contexto significa inferência mais lenta, e tudo desaparece quando a sessão termina. Está a pagar um prémio pela amnésia com passos adicionais.
O que precisamos é de uma camada dedicada que armazene fatos destilados sobre os usuários permanentemente e recupere apenas o que é relevante para cada consulta. Essa é a lacuna TrueMem preenche.
A memória humana não funciona armazenando cada conversa palavra por palavra. Temos memória de trabalho para a tarefa atual e memória de longo prazo para conhecimento persistente. Os dois sistemas interagem constantemente: as memórias de longo prazo informam como interpretamos novas informações, enquanto novas experiências importantes são consolidadas no armazenamento de longo prazo.
TrueMem espelha esta arquitetura com dois componentes distintos: Memória de Curto Prazo (MCP) para contexto de conversa e Memória de Longo Prazo (MLP) para fatos persistentes do usuário.
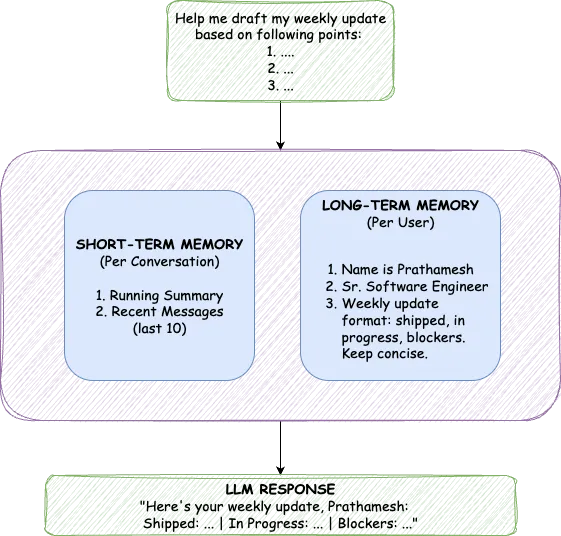
A separação é importante porque estes tipos de memória servem propósitos diferentes. A MCP capta o que está a acontecer agora, o fluxo completo da conversa atual. A MLP armazena fatos destilados que persistem em todas as conversas. A MCP é sempre incluída no contexto; a MLP é recuperada com base na relevância semântica. Tentar resolver ambos com um único mecanismo força um compromisso. A abordagem dupla evita-o completamente.
Dentro de uma única sessão de chat, a IA precisa de se lembrar do que foi discutido há cinco minutos. Este é o trabalho da MCP, e ela mantém dois componentes: um resumo contínuo de mensagens mais antigas e as últimas vinte mensagens em total fidelidade.
À medida que uma conversa avança, monitorizamos continuamente a contagem total de tokens. Quando excede um limite, um processo em segundo plano comprime as mensagens mais antigas no resumo contínuo, mantendo as mensagens recentes intactas.

A sumarização é assíncrona, então os usuários nunca esperam por ela. Quando o limite é excedido, uma tarefa em segundo plano busca mensagens não sumarizadas, combina-as com qualquer resumo existente e gera um resumo abrangente atualizado. Essas mensagens são marcadas como "sumarizadas" e o ciclo continua. A compressão progressiva significa que mesmo conversas de uma hora permanecem dentro de limites de contexto razoáveis.
Mas o contexto da conversa por si só não é suficiente. O que acontece quando o usuário retorna amanhã? É aí que entra a memória de longo prazo.
A MLP armazena fatos sobre os usuários que persistem indefinidamente: seu nome, profissão, preferências, estilo de comunicação e qualquer outra coisa que valha a pena lembrar em várias conversas. Estes não são armazenados como texto bruto. São convertidos em embeddings vetoriais, permitindo a pesquisa semântica de similaridade.
Quando um usuário pergunta "Que linguagem de programação devo usar?", não fazemos correspondência por palavra-chave com memórias armazenadas. Incorporamos a consulta e encontramos memórias semanticamente relacionadas. Memórias como "Usuário prefere Python" e "Trabalha com infraestrutura de ML" surgem porque são conceitualmente relevantes, mesmo sem palavras-chave compartilhadas.
O sistema preenche a MLP através de dois canais. Memórias explícitas vêm de pedidos diretos: "Lembre-se que prefiro marcadores" ou "Não se esqueça que sou alérgico a amendoins." Detectamos frases de gatilho, extraímos o fato central e o armazenamos com importância máxima. Essas memórias nunca são excluídas automaticamente.
Memórias automáticas vêm da análise da conversa. Quando um usuário menciona "Eu tenho liderado a equipe da plataforma de ML", isso é um contexto valioso mesmo sem um pedido explícito para salvar. Após cada interação, um processo em segundo plano examina a conversa e extrai fatos que valem a pena armazenar, cada um marcado com uma pontuação de importância.
As pontuações de importância variam de um a cinco. Um cinco significa informação crítica que nunca deve ser esquecida: instruções explícitas do usuário, preferências fortes, alergias. Um quatro representa fatos pessoais chave como profissão ou localização. Três são contexto geral como hobbies e interesses. Dois cobrem informações temporárias como projetos atuais. Um são detalhes menores. Memórias explícitas recebem automaticamente um cinco; extrações automáticas geralmente pontuam entre um e quatro com base na significância aparente do fato.
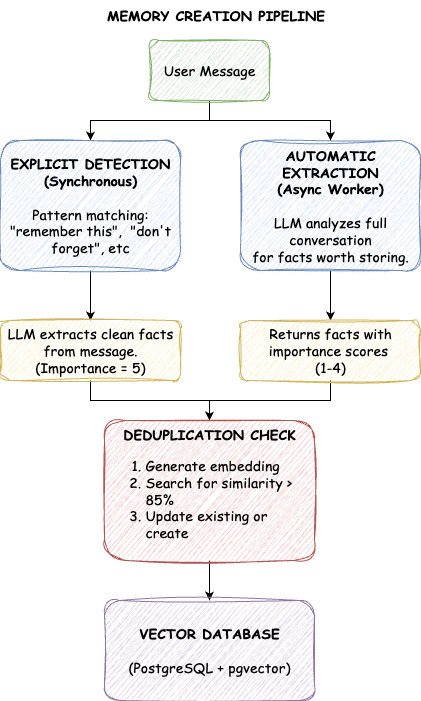
Um desafio surge com a extração automática: e se um usuário disser "Eu gosto de Python" em uma sessão e "Prefiro Python a JavaScript" em outra? O armazenamento ingênuo cria duplicatas. TrueMem resolve isso com deduplicação semântica. Antes de armazenar, procuramos memórias existentes com similaridade acima de 85%. Se uma quase-duplicata existir, nós a atualizamos em vez de criar uma nova entrada. O banco de dados permanece limpo, com cada fato aparecendo exatamente uma vez em sua forma mais completa.
A privacidade é tratada através da transparência. Os usuários podem visualizar, editar e excluir qualquer memória armazenada. Todas as memórias são estritamente isoladas por usuário. Para implantações empresariais, todo o sistema funciona na sua infraestrutura. Nada sai do seu ambiente.
E quanto à precisão da extração? Vários mecanismos abordam isso: a pontuação de importância significa que as extrações automáticas são podadas antes das memórias explícitas; os usuários podem revisar e corrigir erros; e informações corretas reforçadas em várias conversas acumulam maior importância, enquanto extrações incorretas pontuais desaparecem através da poda natural.
Ter memórias armazenadas é apenas metade do problema. Quando um usuário envia uma mensagem, precisamos do subconjunto certo: não tudo, apenas o que é relevante. Um usuário avançado pode ter 150 fatos armazenados; incluir todos eles sobrecarregaria a janela de contexto.
O processo incorpora a mensagem do usuário, realiza uma pesquisa de similaridade de cosseno e retorna os dez principais resultados. Isso leva menos de 10 milissegundos com a indexação adequada.
Uma exceção: novos usuários. Se alguém tiver menos de dez memórias, incluímos todas elas, independentemente da similaridade. No início de um relacionamento, cada pedaço de contexto importa. Assim que a contagem excede dez, mudamos para a recuperação puramente baseada em similaridade.
Esta recuperação faz parte de um fluxo maior de preparação de contexto e precisa ser rápida.
Uma camada de memória só é útil se não adicionar latência perceptível. Os usuários são sensíveis a atrasos; mesmo 200 milissegundos parecem lentos. Nosso objetivo era abaixo de 80ms para a preparação do contexto.
A chave é a paralelização. A preparação do contexto envolve várias operações independentes: gerar um embedding, buscar mensagens recentes, verificar gatilhos explícitos e pesquisar memórias de longo prazo. Em vez de executá-las sequencialmente, nós as disparamos em paralelo.
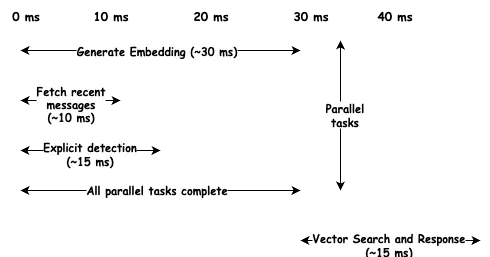
A geração de embedding é a mais lenta, com cerca de 30 milissegundos, mas é executada em paralelo com consultas de banco de dados que são concluídas em 10ms. Pagamos pela operação mais longa, não pela soma. A latência total fica em torno de 45ms, bem abaixo do objetivo.
Operações pesadas, como sumarização e extração de memória, são executadas assincronamente após o envio da resposta. O usuário nunca espera; o processamento ocorre em workers em segundo plano. Essa separação entre o caminho síncrono rápido e o caminho assíncrono lento é essencial para uso em produção.
Com a memória funcionando de forma confiável, um benefício inesperado surgiu: havíamos construído acidentalmente algo agnóstico ao modelo.
Aqui está o que não prevíamos. Uma vez que a memória reside fora do modelo, você não está mais preso a um único provedor.
Mudar de GPT-4 para Claude? Sua memória persiste. Usar modelos diferentes para tarefas diferentes, como raciocínio complexo com um e escrita criativa com outro? Todos eles compartilham a mesma compreensão de você. Ajustar um modelo personalizado? Ele herda os relacionamentos de usuário existentes desde o primeiro dia.
A camada de memória torna-se sua constante; os modelos tornam-se intercambiáveis.
A integração permanece mínima: buscar contexto antes da chamada LLM, registrar a interação depois. Duas chamadas de API transformam qualquer modelo sem estado em um com memória persistente. Sem bloqueio de SDK, sem integração complexa. Apenas endpoints HTTP que se encaixam em qualquer arquitetura.
Claro, as memórias não podem crescer para sempre. Um sistema sem gerenciamento de ciclo de vida se afogaria em fatos desatualizados.
Cada memória tem uma pontuação de importância de um a cinco. Instruções explícitas recebem cinco. Fatos pessoais importantes recebem quatro. Contexto geral recebe três. Informações temporárias recebem dois. Detalhes menores recebem um.
Quando a contagem excede um limite flexível (150 por padrão), a poda é ativada. O sistema nunca toca em memórias de importância quatro ou superior. Entre as memórias de menor importância, ele remove as de menor pontuação primeiro, usando a idade como critério de desempate.
Instruções explícitas do usuário sobrevivem indefinidamente. Extrações automáticas de baixo valor são recicladas para abrir espaço para novas informações. A memória permanece relevante sem curadoria manual.
Um usuário abre um chat e digita: "Ajude-me a redigir minha atualização semanal, com base nos seguintes pontos..."
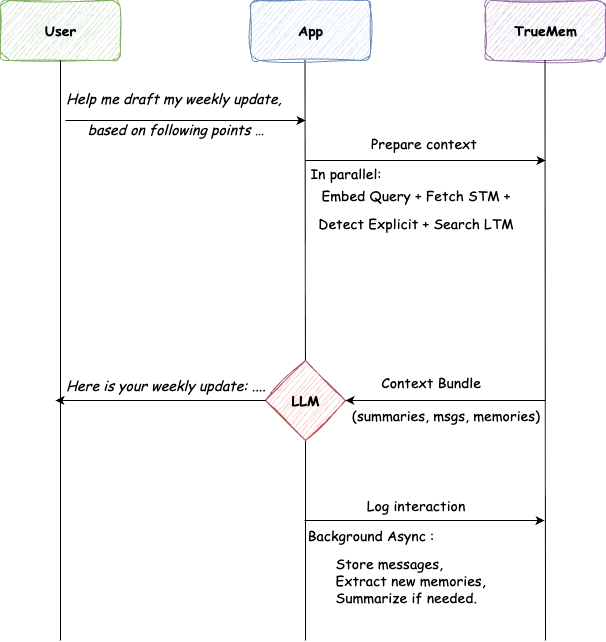
O aplicativo chama o TrueMem para contexto. O TrueMem reúne STM e LTM relevantes, incluindo "Nome é Prathamesh", "Engenheiro Sênior de ML", "Trabalhando no serviço de memória". Isso leva 45 milissegundos.
O LLM gera uma resposta personalizada: "Aqui está sua atualização semanal, Prathamesh..." Sem rituais. Sem reintrodução. A IA sabe quem está perguntando.
Após responder, o aplicativo registra a interação. Processos em segundo plano armazenam mensagens, extraem novos fatos e atualizam resumos conforme necessário. O trabalho pesado acontece de forma invisível.
Escolhemos PostgreSQL com pgvector em vez de bancos de dados vetoriais dedicados por razões pragmáticas. A maioria das equipes já usa Postgres. As memórias ficam junto aos dados do usuário com garantias ACID completas. Para coleções por usuário de 100-200 vetores, o pgvector oferece pesquisa de similaridade em menos de 10ms. Para memória com escopo de usuário, é a escolha certa.
Os processos em segundo plano são executados em filas baseadas em Redis porque as chamadas LLM levam segundos, tempo demais para bloquear requisições. Os workers podem tentar novamente falhas, operações em lote e escalar independentemente sem afetar a latência percebida pelo usuário.
Lembra daquele ritual de sexta-feira? "Eu sou Prathamesh. Engenheiro de Software Sênior. Trabalhando no serviço de memória."
Com o TrueMem, acontece uma vez. A IA lembra. A atualização da próxima sexta-feira simplesmente funciona. O rascunho do e-mail do próximo mês já sabe minha assinatura. O contexto está sempre lá.
Melhor ainda: mude para um modelo diferente, e a memória é transferida. O assistente diário se torna agnóstico ao modelo sem trabalho extra.
Esse é o objetivo. IA que lembra de você. Não porque você continua lembrando-a, mas porque ela realmente lembra.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




