



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
É tentador acreditar que o maior desafio com agentes de IA é a inteligência. Por muito tempo, isso foi verdade. Os modelos tinham dificuldade em raciocinar, as ferramentas eram frágeis e as tarefas de várias etapas se desfaziam facilmente. Mas essa fase já ficou para trás.
Agentes modernos já conseguem fazer muito. Eles podem raciocinar em várias etapas, chamar ferramentas, invocar servidores MCP e até coordenar com outros agentes. Com os prompts e modelos certos, muitas equipes podem construir protótipos de agentes impressionantes em um tempo surpreendentemente curto. As demonstrações parecem convincentes. Os resultados iniciais parecem mágicos.
No entanto, quando esses mesmos sistemas são levados ao uso real, eles começam a falhar de maneiras silenciosas e confusas.
Esta é a lacuna que define a economia agente-a-agente emergente. Não uma falta de inteligência, mas uma falta de infraestrutura.
A maioria das implementações iniciais de agentes segue um padrão enganosamente simples. Um usuário envia uma entrada, o agente raciocina sobre ela, opcionalmente chama uma ferramenta e retorna uma resposta. Este fluxo linear é fácil de entender e fácil de depurar. Também se alinha bem com a forma como os desenvolvedores estão acostumados a pensar sobre aplicações.
Mas este modelo esconde uma suposição que não sobrevive ao contato com a realidade: que a execução do agente é de curta duração, isolada e autocontida.
Assim que os agentes começam a interagir com outros agentes, essa suposição se quebra. Um agente delega trabalho a outro. Uma ação de acompanhamento é acionada mais tarde. Uma invocação de ferramenta leva a uma decisão secundária. Os caminhos de execução se ramificam, se unem novamente e, às vezes, pausam completamente.
Neste ponto, o sistema deixa de se comportar como um recurso de aplicação e começa a se comportar como um sistema distribuído composto por componentes autônomos.
Esta transição é sutil, mas crítica. As equipes muitas vezes não percebem que isso aconteceu até que as coisas comecem a dar errado.
Quando os sistemas de agentes enfrentam dificuldades em produção, as falhas raramente são dramáticas. O sistema não falha completamente. Em vez disso, a confiança se desgasta lentamente.
Uma ação é acionada, mas ninguém tem certeza do porquê.
Um agente downstream é executado, mas sob permissões pouco claras.
Os custos disparam sem uma causa óbvia.
Um fluxo de trabalho para na metade, e não há um rastro claro explicando onde ou por quê.
Estas não são falhas de raciocínio. O agente pode ter tomado uma decisão perfeitamente razoável dada a informação que possuía. O problema é que ninguém consegue explicar ou governar de forma confiável o que aconteceu em todo o sistema.
Este é o ponto em que muitas equipas tentam instintivamente "corrigir" o próprio agente, ajustando prompts, trocando modelos ou adicionando mais lógica. Mas essas mudanças raramente abordam a causa raiz, porque o problema não reside dentro do agente.
Ele reside entre os agentes.
Se a inteligência fosse o verdadeiro bloqueador, esperaríamos um padrão simples: modelos melhores levariam a sistemas de produção estáveis. Não é isso que vemos.
O que vemos, em vez disso, é que, à medida que os agentes se tornam mais capazes, os sistemas à sua volta tornam-se mais difíceis de gerir. Mais inteligência leva a mais autonomia, mais comportamentos ramificados e mais efeitos a jusante. Sem a infraestrutura certa, essa capacidade extra, na verdade, aumenta o risco.
A economia agente-para-agente amplifica este efeito. À medida que os agentes começam a chamar outros agentes e a operar em ferramentas e ambientes partilhados, o custo da infraestrutura ausente cresce rapidamente. Identidade, coordenação, aplicação de políticas e observabilidade deixam de ser preocupações opcionais e tornam-se requisitos fundamentais.
É aqui que uma mudança de mentalidade se torna necessária. Os agentes não podem ser tratados como apenas mais uma peça de lógica de aplicação. Num ecossistema de agentes real, os agentes são atores de longa duração que participam em fluxos de trabalho, delegam tarefas e operam sob diferentes autoridades.
Plataformas como Agent Hub da TrueFoundry refletem esta mudança. Em vez de assumir que os agentes são lógicas privadas e incorporadas, o Agent Hub trata-os como componentes registados e detetáveis com interfaces e propriedade explícitas. Os agentes são publicados, versionados e invocados através de uma superfície de controlo partilhada, em vez de se chamarem diretamente através de caminhos de código ad-hoc.
Este reenquadramento não torna os agentes mais inteligentes. Torna o sistema à sua volta operável.
A economia agente-para-agente não está à espera de um avanço no raciocínio. Está à espera de uma infraestrutura que possa suportar a autonomia sem perder o controlo.
Compreender como os sistemas de agentes mudam quando entram em produção, e por que as abordagens tradicionais falham, é o primeiro passo. A partir daí, o papel dos planos de controlo, gateways e APIs de execução explícitas torna-se inevitável. É aí que o verdadeiro trabalho começa.
Quando um sistema de agentes chega à produção, a maioria das equipas já resolveu os problemas óbvios.
Sabem como enviar pedidos a um LLM.
Sabem como ligar ferramentas ou servidores MCP.
Sabem como iniciar um agente e obter uma resposta.
Estas capacidades já não são experimentais. São estáveis, bem documentadas e fáceis de reproduzir. Na verdade, é precisamente por isso que as equipas ganham confiança tão rapidamente. O sucesso inicial cria a impressão de que o sistema está “praticamente pronto”.
A produção é onde essa ilusão se desfaz.
O que a produção realmente faz é expor tudo o que os protótipos convenientemente escondem.
Numa demonstração, um agente geralmente executa isoladamente. Ele lida com uma única solicitação, realiza um pequeno número de ações e sai. Há um único caminho de execução e um único resultado. A depuração é simples porque todo o contexto cabe na cabeça de um desenvolvedor.
Em produção, os agentes não se comportam assim.
Eles executam continuamente.
Eles acionam ações subsequentes.
Eles chamam outros agentes.
Eles operam em ambientes, equipes e permissões.
A execução deixa de ser uma única interação e torna-se um fluxo de trabalho, muitas vezes um que se desenrola ao longo do tempo.
É aqui que os sistemas de agentes começam a se assemelhar a sistemas distribuídos, não porque usem microsserviços ou filas, mas porque o comportamento agora está distribuído por múltiplos atores autônomos.
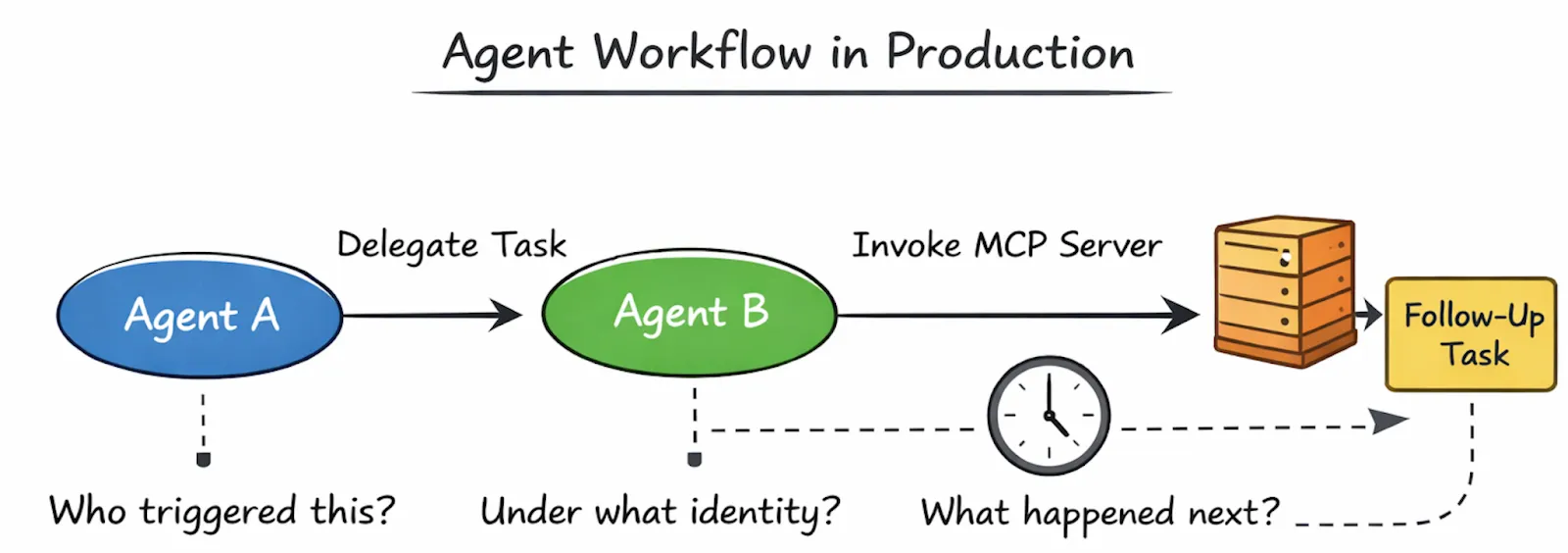
Quando algo dá errado em produção, as equipes não perguntam se o agente era “inteligente o suficiente”. Em vez disso, elas fazem perguntas que soam muito familiares para qualquer pessoa que tenha operado sistemas distribuídos:
O que acionou esta ação?
Qual agente tomou a decisão?
Sob qual identidade ele foi executado?
Por que a execução se ramificou aqui?
Por que parou completamente?
Essas perguntas são enganosamente simples e impossíveis de responder de forma confiável sem suporte de infraestrutura.
Na maioria das configurações iniciais de agentes, o contexto de execução reside dentro do próprio agente. Uma vez que um agente chama outro agente, ou invoca uma ferramenta, esse contexto frequentemente desaparece, a menos que cada desenvolvedor o propague cuidadosamente. Com o tempo, os logs se fragmentam, o rastreamento falha e o sistema se torna opaco.
O agente ainda pode estar produzindo resultados, mas o sistema como um todo torna-se difícil de analisar.
A reação natural nesta fase é corrigir o problema localmente. Uma equipe adiciona registro (logging) em torno das chamadas de ferramentas. Outra envolve agentes com verificações de autenticação. Alguém adiciona retentativas em alguns lugares. Nenhuma dessas mudanças está errada por si só.
Mas, em conjunto, elas criam uma teia frágil de código de "cola" onde:
Este é o ponto em que as equipes começam a se sentir atrasadas, não porque os agentes não possam fazer mais, mas porque mudar qualquer coisa tem consequências não intencionais.
O que está emergindo aqui, quer as equipes percebam ou não, é um plano de controle. Acontece que é acidental e mal definido.
É aqui que plataformas como TrueFoundry traçam uma linha clara entre a lógica do agente e a responsabilidade do sistema.
Com o Agent Hub, os agentes não são mais invocados implicitamente através de chamadas de função locais ou dependências ocultas. Eles são registrados, detectáveis e executados através de uma interface compartilhada. Com a Agent API, a execução do agente torna-se explícita, contextual e observável.
Em vez de um agente chamar silenciosamente outro agente, a execução é apresentada como uma operação gerida.
# Using TrueFoundry's Agent API with registered MCP servers
import httpx
response = httpx.post(
"https://{controlPlaneURL}/api/llm/agent/chat/completions",
headers={
"Authorization": "Bearer {TFY_API_TOKEN}",
"Content-Type": "application/json"
},
json={
"model": "openai/gpt-4o",
"messages": [{"role": "user", "content": "Evaluate risk for transaction txn_123"}],
"mcp_servers": [{"integration_fqn": "common-tools", "tools": [{"name": "web_search"}, {"name": "sequential_thinking"}]}],
"stream": True
}
)# Connecting to MCP server through TrueFoundry Gateway
from fastmcp import Client
from fastmcp.client.transports import StreamableHttpTransport
async def main():
url = "https://{controlPlaneURL}/api/llm/mcp/common-tools/server"
transport = StreamableHttpTransport(
url=url,
auth="<tfy-api-token>",
)
async with Client(transport=transport) as client:
tools = await client.list_tools()
result = await client.call_tool("web_search", {"query": "What is Python?"})
return result
Nota: O contrato da API do Agent Hub está atualmente em desenvolvimento ativo. Para a sintaxe e capacidades mais recentes, consulte a documentação da API do Agente.
Isto pode parecer uma pequena mudança, mas tem consequências significativas. A identidade viaja com o pedido. Os limites de execução são claros. As ações a jusante podem ser rastreadas até à sua origem. As políticas podem ser avaliadas antes de o agente ser executado, e não depois de algo correr mal.
O agente ainda raciocina e decide o que fazer. A plataforma gere como essa decisão é executada de forma segura.
Assim que os agentes chegam à produção, os problemas difíceis deixam de ser sobre inteligência. São sobre coordenação, identidade, visibilidade e controlo. Estas preocupações não pertencem ao código do agente, porque se aplicam a agentes, fluxos de trabalho e equipas.
É por isso que muitas equipas procuram um atalho a seguir: colocar um router à frente dos seus agentes e esperar que isso seja suficiente.
Raramente é.
Compreender por que essa abordagem falha é o próximo passo para entender como deve ser uma infraestrutura de agente real.
Assim que as equipas percebem que o seu sistema de agentes está a tornar-se difícil de gerir, o primeiro instinto é geralmente pragmático: adicionar um router à frente dos agentes.
Esta abordagem parece familiar. Gateways de API e routers são bem compreendidos. Funcionaram para microsserviços, então por que não reutilizar o mesmo padrão para agentes? Coloque uma camada de roteamento à frente, decida qual agente chamar e siga em frente.
Por um curto período, isto funciona. Depois, o sistema começa a dobrar-se de formas que o router nunca foi projetado para lidar.
Os routers são construídos para um mundo muito específico. Eles assumem que os pedidos são de curta duração, os caminhos de execução são maioritariamente lineares e a identidade é uniforme ou resolvida uma vez na extremidade. Eles encaminham o tráfego de forma eficiente, mas não compreendem a intenção.
Os sistemas agente-para-agente violam estas suposições quase imediatamente.
Os agentes não respondem apenas a pedidos. Eles iniciam ações, delegam trabalho a outros agentes e desencadeiam efeitos secundários que se desenvolvem ao longo do tempo. Uma única decisão pode ramificar-se em múltiplas execuções a jusante, algumas imediatas, outras atrasadas. A identidade já não é um único cabeçalho; é algo que precisa de ser preservado e considerado em várias etapas.
A router pode encaminhar uma requisição. Não consegue explicar por que essa requisição existe.
À medida que os sistemas de agentes crescem, as equipes começam a transferir mais responsabilidade para o roteador. Regras de autenticação são adicionadas. A seleção de modelos é codificada nas rotas. Verificações de políticas são codificadas diretamente na lógica de roteamento. O contexto é montado usando cabeçalhos e convenções.
Nada disso parece errado isoladamente. Mas, com o tempo, o roteador se torna um depósito para preocupações que não deveria lidar. Ele se transforma em um ponto de estrangulamento frágil onde:
Ironicamente, o roteador que deveria simplificar o sistema se torna o que atrasa a todos.
A questão mais profunda é que os sistemas de agentes não precisam apenas de gerenciamento de tráfego. Eles precisam de governança.
As equipes de segurança e conformidade não perguntam qual rota foi acessada. Elas perguntam quem acessou o quê, sob qual autoridade e por quê. As equipes de produto não querem apenas saber para onde uma requisição foi; elas querem entender como uma decisão se propagou entre agentes e ferramentas. Os operadores precisam ver como o custo e o comportamento evoluem em todo um fluxo de trabalho, não apenas na borda.
Essas perguntas não podem ser respondidas apenas pelo roteamento, porque dependem de intenção, delegação e ações derivadas. Esses conceitos não vivem naturalmente em um roteador.
É aqui que a distinção entre um roteador e um plano de controle se torna clara.
Com TrueFoundry’s Agent Hub, os agentes não são endpoints anônimos por trás de uma tabela de roteamento. Eles são entidades nomeadas e registradas com interfaces e propriedade explícitas. Quando um agente invoca outro, ele o faz através de uma camada de execução gerenciada, em vez de um salto de rede opaco.
A API do Agente reforça essa separação. A execução não está oculta por trás de uma rota; é uma operação explícita com identidade, metadados e avaliação de políticas incorporados. O gateway impõe regras de forma consistente, enquanto preserva o contexto nas interações entre agentes.
Isso não remove a flexibilidade. Pelo contrário, a restaura. Ao manter o roteamento focado no tráfego e mover a governança para uma infraestrutura dedicada, as equipes podem evoluir o comportamento do agente sem transformar sua camada de roteamento em um monólito frágil.
“Apenas um roteador” falha não por ser mal implementado, mas por estar resolvendo o problema errado. Sistemas agente-para-agente não são roteadores de requisições com endpoints mais inteligentes. São sistemas distribuídos com comportamento autônomo.
Uma vez que as equipes aceitam isso, a próxima percepção surge naturalmente: sistemas de agentes se comportam como sistemas distribuídos, mas com riscos maiores.
Quando as equipes percebem que um roteador não é suficiente, outro padrão geralmente começa a surgir por si só. Pequenos pedaços de lógica de coordenação começam a aparecer em todos os lugares. Um agente adiciona verificações de permissão antes de chamar uma ferramenta. Outro incorpora lógica de repetição ao invocar um agente downstream. Uma terceira equipe adiciona log personalizado para rastrear o que aconteceu depois que uma ação foi acionada.
Nenhuma dessas mudanças está errada. Na verdade, são respostas práticas a problemas reais. Mas, em conjunto, elas apontam para algo mais profundo: o sistema está sem um plano de controle.
Um plano de controle não se trata de fazer o trabalho. Trata-se de decidir como o trabalho é permitido que aconteça.
Em um sistema agente-para-agente, há perguntas que simplesmente não pertencem à lógica do agente:
Quem tem permissão para invocar este agente?
Sob quais condições?
Usando quais ferramentas ou servidores MCP?
Com que nível de visibilidade e auditabilidade?
Quando essas decisões são incorporadas diretamente nos agentes, elas são duplicadas e se desviam com o tempo. Dois agentes que deveriam se comportar da mesma forma divergem lentamente. As políticas são aplicadas de forma inconsistente. A depuração torna-se um palpite, pois nenhum lugar único reflete como o sistema é realmente governado.
Este é exatamente o problema Agent Hub da TrueFoundry que foi projetado para resolver.
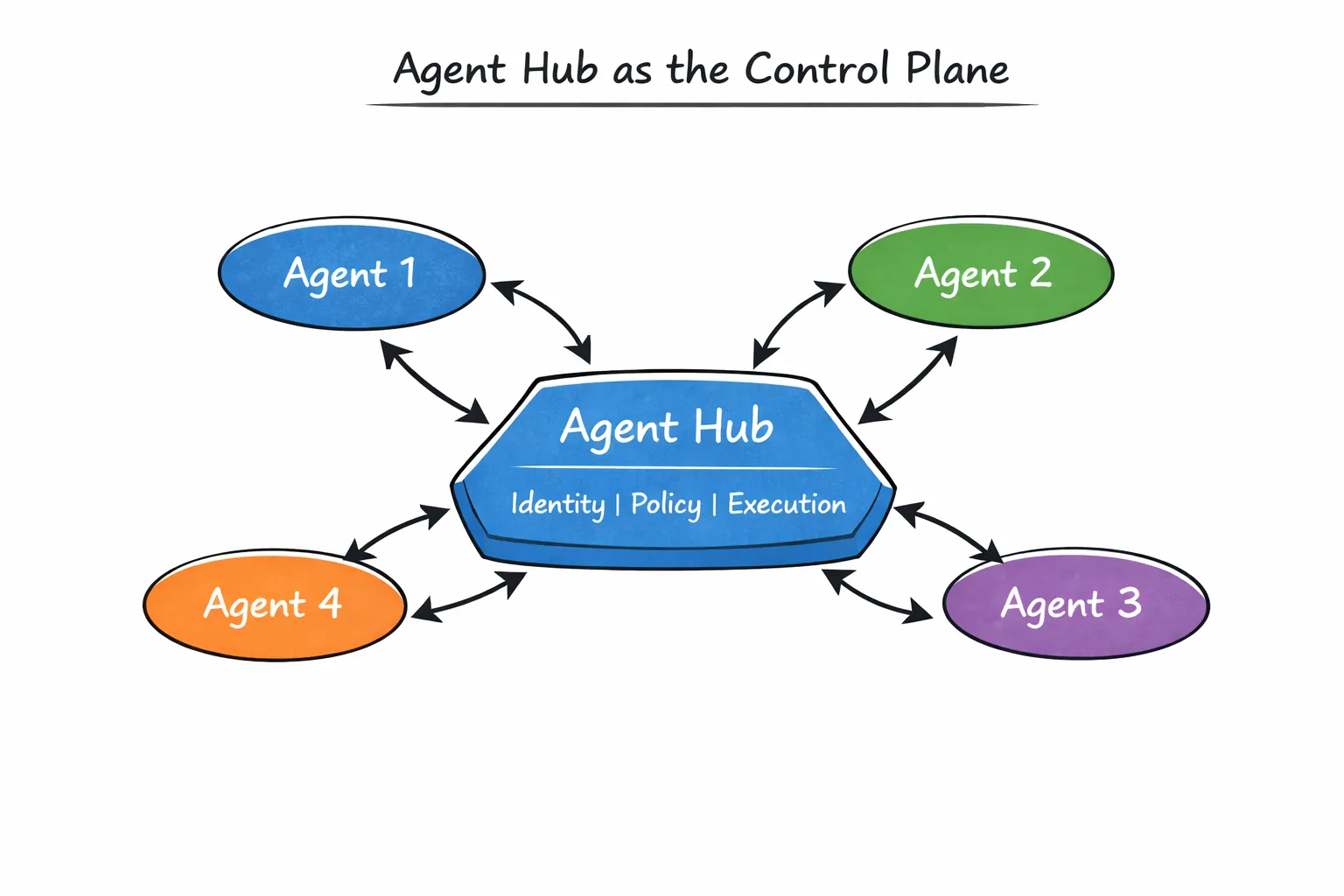
O Agent Hub trata os agentes não como detalhes de implementação privados, mas como entidades registradas e detectáveis dentro de um sistema compartilhado. Ele oferece recursos, incluindo:
Cada agente é publicado com uma interface clara, propriedade e limite de execução. Outros agentes não o "acessam" por meio de caminhos de código ad-hoc. Eles o invocam explicitamente.
Isso muda a natureza das interações entre agentes. Em vez de dependências ocultas, os relacionamentos tornam-se visíveis. Em vez de confiança implícita, a execução flui por uma camada gerenciada.
Uma forma útil de visualizar isso é colocar o Agent Hub no centro do sistema:
À medida que os sistemas crescem, os fluxos de trabalho raramente permanecem simples. Um agente pode se especializar em recuperação, outro em avaliação, outro em tomada de decisões. Esses agentes não se substituem; eles colaboram.
O Agent Hub oferece suporte a isso explicitamente por meio de subagentes e fluxos de trabalho multiagente. Em vez de codificar a lógica de orquestração diretamente em um único "mega-agente", as equipes podem compor fluxos de trabalho encadeando agentes de forma controlada.
Isso tem dois efeitos importantes. Primeiro, mantém os agentes individuais focados e compreensíveis. Segundo, centraliza a lógica de coordenação para que as alterações na forma como os agentes interagem não exijam a reescrita de cada agente envolvido.
O sistema torna-se mais fácil de evoluir, não mais difícil.
Outro benefício discreto de um plano de controle centralizado é a visibilidade. Em muitas organizações, os agentes proliferam mais rapidamente do que a governança. As equipes constroem o que precisam, copiam credenciais e implementam agentes onde quer que possam. Com o tempo, ninguém tem certeza de quantos agentes existem, a que dados eles acessam ou quem os possui.
O Agent Hub oferece uma superfície compartilhada onde os agentes são registrados e descobertos. Isso não atrasa as equipes; oferece-lhes um padrão seguro. Quando o caminho oficial é fácil e visível, há muito menos incentivo para construir agentes nas sombras.
É importante deixar claro o que um plano de controle não é. Não é um lugar onde toda a lógica reside, nem um gargalo que as equipes devem negociar para cada mudança. O Agent Hub não diz aos agentes o que pensar. Ele define como os agentes participam do sistema.
Os agentes ainda raciocinam de forma independente. As equipes ainda entregam rapidamente. Mas as regras de engajamento, identidade, invocação e coordenação são tratadas de forma consistente em todo o ecossistema.
Essa separação é o que torna os sistemas de agentes sustentáveis à medida que crescem.
Uma vez que um plano de controle existe, a peça final do quebra-cabeça torna-se óbvia: a execução precisa ser imposta e observada em tempo de execução. É aí que entram os gateways e as APIs de agente explícitas, e é isso que veremos a seguir.
Uma vez que um plano de controle existe, uma pergunta torna-se inevitável: onde esse controle é realmente imposto?
Em sistemas de agentes, as decisões sobre identidade, política e roteamento não importam a menos que sejam aplicadas em tempo de execução, no exato momento em que um agente tenta agir. É aqui que os gateways e as APIs de agente explícitas se tornam críticos. Sem eles, um plano de controle é apenas consultivo. Com eles, torna-se real.
Um dos modos de falha mais comuns em sistemas de agentes é a execução invisível. Um agente chama outro agente como uma função local. Esse agente invoca uma ferramenta. Um efeito colateral ocorre. Tudo “funciona”, mas ninguém consegue ver claramente o que aconteceu ou por quê.
O problema não é que a execução esteja errada. É que ela está oculta.
Da TrueFoundry API de Agente força a execução do agente a ser explícita. Em vez de chamadas implícitas enterradas no código, as interações dos agentes tornam-se operações de primeira classe. Cada invocação carrega identidade, contexto e intenção consigo, e flui pela mesma infraestrutura todas as vezes.
# TrueFoundry Agent API - explicit, governed agent execution
import httpx
response = httpx.post(
"https://{controlPlaneURL}/api/llm/agent/chat/completions",
headers={
"Authorization": "Bearer {TFY_API_TOKEN}",
"Content-Type": "application/json"
},
json={
"model": "openai/gpt-4o",
"messages": [{"role": "user", "content": "Search for information about Python"}],
"mcp_servers": [
{"integration_fqn": "common-tools", "tools": [{"name": "web_search"}]}
]
}
)Nota: O contrato da API do Agent Hub está atualmente em desenvolvimento ativo. Para a sintaxe e capacidades mais recentes, consulte a documentação da API do Agente.
Esta chamada pode parecer simples, mas representa uma grande mudança arquitetónica. O agente já não atua de forma isolada. A sua execução é mediada, rastreada e governada.
Em sistemas tradicionais, os gateways são frequentemente tratados como roteadores de tráfego. Em sistemas de agentes, essa perspetiva é demasiado limitada. Os gateways não estão apenas a encaminhar pedidos, eles estão a aplicar a intenção.
O AI Gateway da TrueFoundry situa-se entre agentes, modelos e servidores MCP. Cada execução de agente passa por ele. Isto permite que o sistema avalie políticas antes que algo aconteça: se um agente tem permissão para ser executado, quais ferramentas pode aceder, qual modelo deve usar e o que deve ser registado ou restringido.
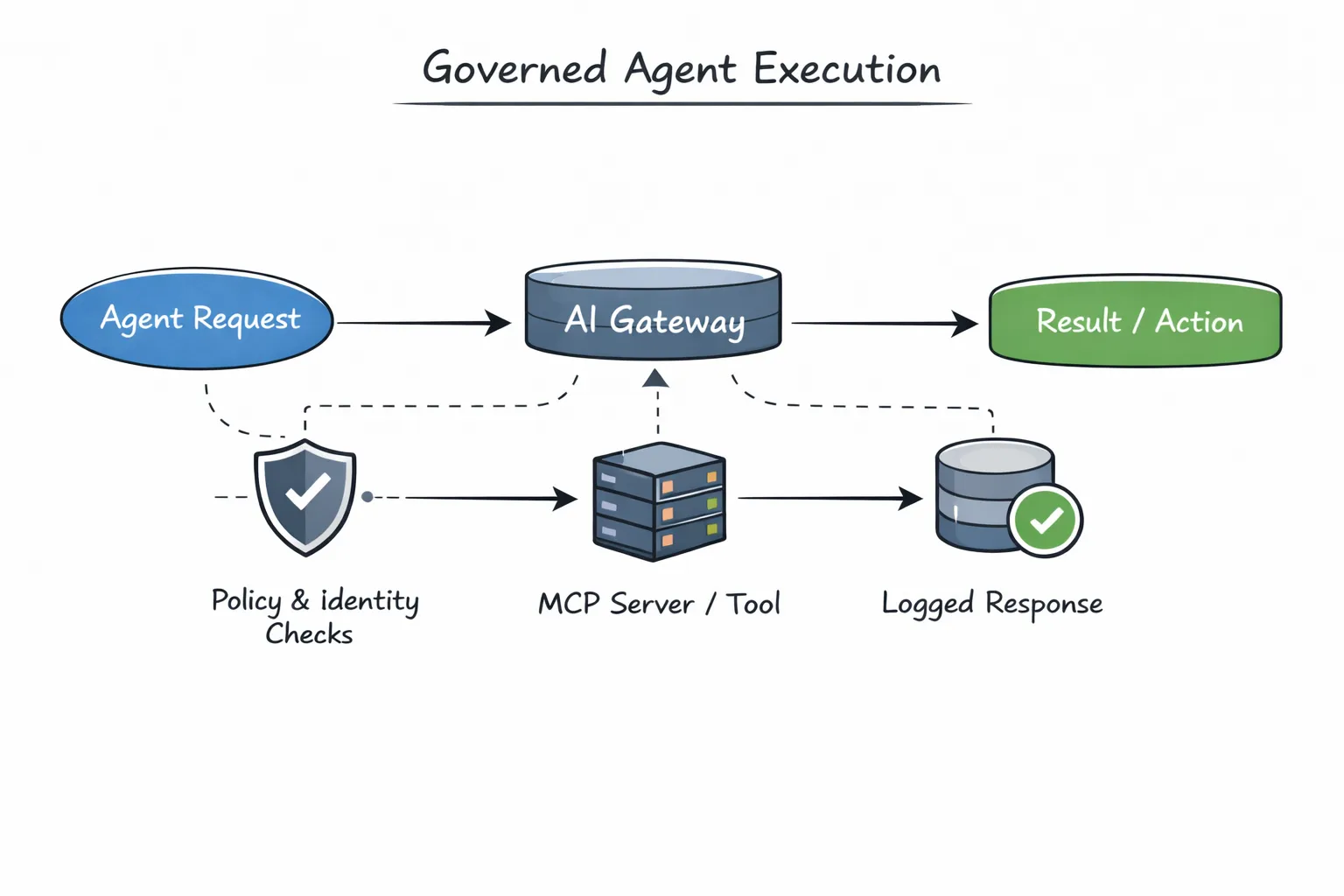
Como toda a execução flui através de um gateway partilhado, a aplicação torna-se consistente por predefinição. Não há necessidade de cada agente reimplementar verificações de acesso, novas tentativas ou registo. Essas preocupações ficam onde devem, fora da lógica do agente.
O acesso a ferramentas é onde os sistemas de agentes frequentemente se tornam perigosos. As ferramentas podem escrever dados, acionar sistemas externos ou realizar ações irreversíveis. Quando os agentes chamam ferramentas diretamente, as credenciais e a lógica de acesso tendem a ser copiadas, criando riscos de segurança e conformidade.
A API do Agente integra servidores MCP através do gateway, o que significa que as ferramentas são invocadas sob condições controladas. Quer um servidor MCP esteja registado na plataforma ou seja fornecido externamente, o acesso é mediado, autenticado e observável. Os agentes obtêm as capacidades de que precisam sem transportar segredos ou contornar políticas.
Isto é especialmente importante em fluxos de trabalho de agente para agente, onde a decisão de um agente pode desencadear múltiplas invocações de ferramentas a jusante.
Outro benefício da execução explícita é a visibilidade. Como as invocações de agentes fluem através de uma API e gateway partilhados, torna-se possível rastrear o comportamento de ponta a ponta. As equipas podem ver qual agente iniciou uma ação, quais agentes e ferramentas a jusante estiveram envolvidos, quanto tempo a execução demorou e onde os custos se acumularam.
Em sistemas de agentes, o custo não é apenas uma preocupação de faturação, é um sinal comportamental. Uma pequena mudança no raciocínio pode ramificar-se em muitas chamadas. Sem observabilidade, as equipas perdem a capacidade de compreender ou controlar essa amplificação.
A execução explícita restaura essa compreensão.
O objetivo das APIs e gateways de agentes não é limitar o que os agentes podem fazer. É tornar o comportamento autónomo operável.
Os agentes ainda raciocinam de forma independente. Eles ainda colaboram e delegam. Mas o fazem dentro de um sistema que pode aplicar regras, explicar resultados e evoluir de forma segura ao longo do tempo.
Neste ponto, o padrão central fica claro. Sistemas agente-a-agente não escalam apenas com base na inteligência. Eles escalam quando a autonomia é combinada com uma infraestrutura que pode governá-la.
Isso nos leva à pergunta final: o que realmente determina o sucesso em uma economia agente-a-agente a longo prazo?
À medida que as capacidades dos agentes continuam a melhorar, a inteligência se tornará a parte menos interessante do sistema. Modelos melhores serão mais fáceis de acessar. Técnicas de prompt se espalharão rapidamente. O que parece avançado hoje se tornará o padrão amanhã.
O verdadeiro diferencial não será o quão inteligentes são os agentes individuais. Será se os sistemas ao seu redor podem suportar a autonomia sem perder o controle.
As economias agente-a-agente introduzem uma nova classe de complexidade. Decisões se propagam entre agentes. Ações desencadeiam efeitos a jusante. Custos e riscos se amplificam mais rápido do que os humanos podem intervir. Sem infraestrutura, esses sistemas se tornam opacos, frágeis e difíceis de confiar.
O que torna os sistemas de agentes sustentáveis não é mais lógica dentro dos agentes, mas clara separação de responsabilidades:
É aqui que as plataformas fazem a diferença.
O Agent Hub e a Agent API da TrueFoundry não tentam tornar os agentes mais inteligentes. Eles fornecem a camada de infraestrutura que faltava, permitindo que os sistemas de agentes se comportem como sistemas distribuídos bem governados, em vez de coleções imprevisíveis de scripts. Os agentes se tornam detectáveis, compondo-se e operáveis. A autonomia se torna algo em que as equipes podem confiar.
A economia agente-a-agente não será vencida por soluções pontuais ou demonstrações inteligentes. Será construída por plataformas que tornam a autonomia confiável em escala. A inteligência se tornará uma commodity. A infraestrutura será o diferencial.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




