



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Em muitos casos, as equipes desenvolvem prompts de forma descontraída, semelhante a escrever e-mails informais. Este é um processo natural, e não se dá muita atenção a elementos estruturais. Essa abordagem descontraída é apropriada para desenvolvimento exploratório ou até mesmo desenvolver rapidamente um protótipo.
Mas quando se começa a usar um recurso que é construído sobre um Grande Modelo de Linguagem diante de usuários reais, os prompts se tornam um aspecto crítico. Se os prompts não forem bem projetados, isso pode resultar em falha, e as respostas podem não ser consistentes, informações importantes podem não ser incluídas, e as respostas podem não ser confiáveis.
Além disso, a depuração é inesperadamente complexa quando ocorre um problema. Muitas vezes é preciso descobrir se o problema está relacionado ao modelo, à entrada ou até mesmo ao prompt.
Esta publicação abordará o processo exato que criamos para levar os prompts de 'provavelmente bom o suficiente' para 'definitivamente bom o suficiente para produção' com critérios reais, conjuntos de dados de avaliação reais e benchmarks reais em vários modelos. Não é mágica. Apenas engenharia estruturada aplicada a prompts.
Quando a maioria das pessoas pensa em um prompt, elas pensam em uma solicitação simples, como "Resuma este documento" ou "Extraia entidades deste texto". Mas no mundo real, um prompt é muito mais do que isso. É a interface fundamental entre o seu programa e o comportamento do modelo. Um bom prompt criará a persona para o modelo, as regras de engajamento, o formato de saída e o inesperado.
O problema com os prompts é que eles não são testados exaustivamente. Eles são projetados, implementados e depois apenas verificados para ver se funcionam. Você faz uma alteração aqui e adiciona uma regra ali. Então você apenas espera que funcione bem. Às vezes funciona. Geralmente não. Quando falha, simplesmente falha. Você pode nem perceber.
Um bom prompt não é apenas claro, é estruturado. Pense nele como um contrato de API entre você e o modelo. Ele deve definir:
Quando todos esses elementos estão em vigor, o modelo tem tudo o que precisa para ser consistente, confiável e previsível em diferentes entradas e até mesmo em diferentes versões do modelo.

Eis o que vimos acontecer com prompts ruins em implantações reais:
Saídas que parecem corretas, mas não são : O modelo produz uma resposta que parece estar no formato correto, mas contém erros sutis porque a especificação não era clara.
Falhas entre modelos : O prompt funciona para GPT-4, mas apresenta respostas inconsistentes para Claude e modelos OSS. Ninguém o testou em diferentes modelos antes da implantação.
Regressões silenciosas : Mudar uma palavra para corrigir um problema causa outros três problemas que ninguém percebeu até que alguém reclame.
O problema é sempre o mesmo: ninguém tratou o prompt como algo que precisa ser testado e validado. Criamos este processo para resolver isso.
O fluxo de trabalho tem cinco etapas. Cada uma se baseia na anterior. Pule uma e os resultados se tornam rapidamente não confiáveis. Veja como funciona do início ao fim.
Então, antes de fazer qualquer alteração, queremos saber o que está com problemas. Usamos um motor de avaliação estruturado que é executado em cada prompt e o pontua em cinco dimensões diferentes, fornecendo uma pontuação de qualidade geral que varia de 0 a 100.
Não usamos pontuação subjetiva. Temos critérios claros para todas as dimensões. Temos restrições rígidas. Por exemplo, se não houver especificação de saída no prompt, há uma pontuação máxima para a especificação de saída. A pontuação pode ser alta mesmo que as instruções no prompt estejam bem escritas. Se a pontuação for inferior a 75, não está pronto para produção. Se for superior a 90, então é sólido em todas as dimensões.
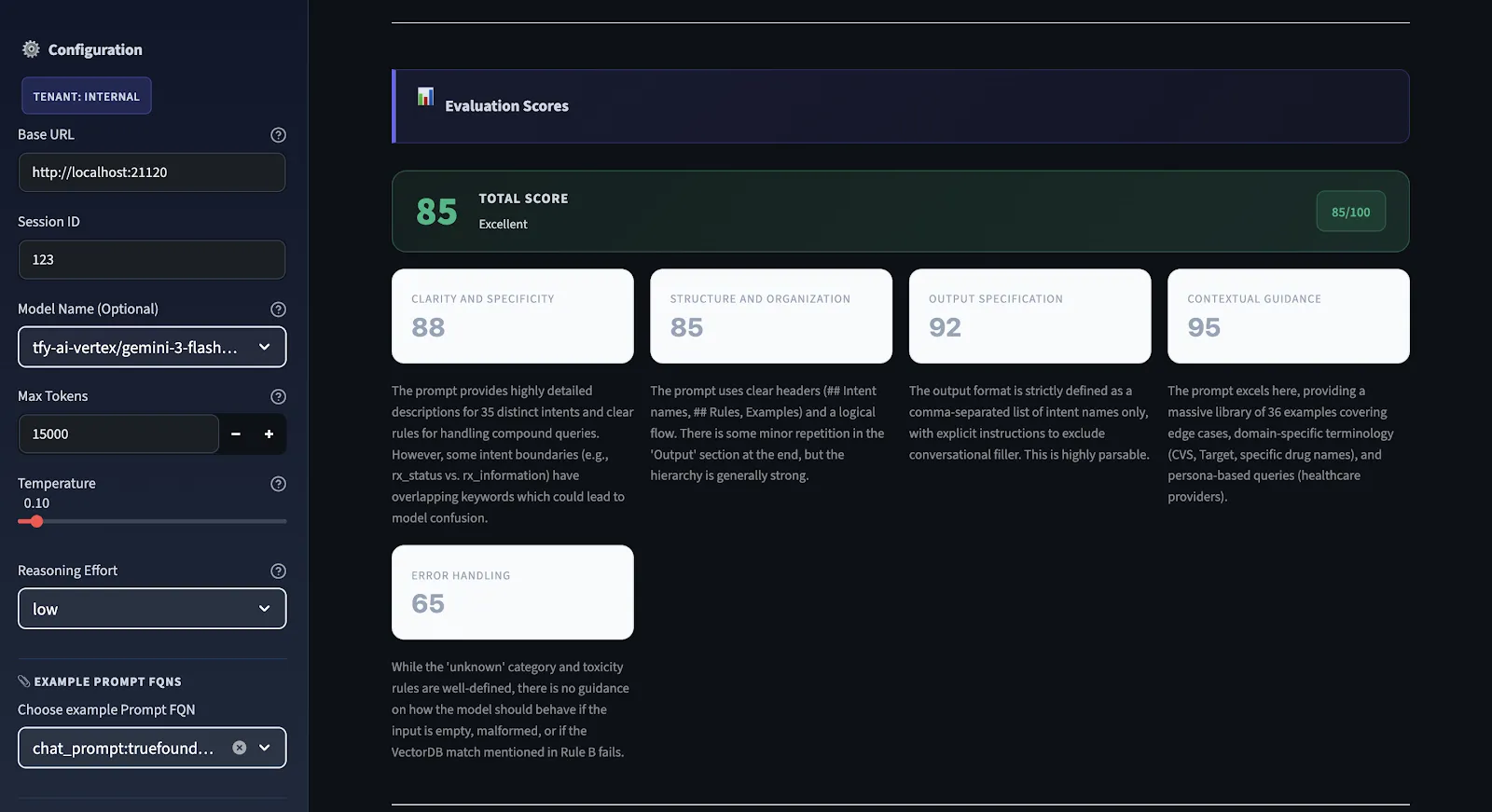
Este é o motor de diagnóstico do fluxo de trabalho. Cada prompt é pontuado de 0 a 100 em cinco critérios específicos. A pontuação geral é a média aritmética de todos os cinco. Veja o que cada um mede e por que é importante:
As instruções são claras o suficiente para que dois modelos diferentes as entendam exatamente da mesma forma? Instruções vagas causam inconsistências mais do que qualquer outro fator isolado. Se você não tem certeza de como um humano pode interpretar seu prompt, provavelmente não tem certeza de como um modelo o interpretará. Se houver mais de uma maneira de um humano interpretá-lo, há mais de uma maneira de um modelo interpretá-lo corretamente ou incorretamente.
O prompt flui logicamente de contexto → instruções → restrições → formato de saída? Um prompt desorganizado força o modelo a descobrir o que importa e em que ordem. Uma boa estrutura facilita o trabalho do modelo e torna suas saídas mais confiáveis.
O formato, estrutura e comprimento da saída esperada estão bem definidos? Se a saída precisar ser analisada por um parser subsequente, não há ambiguidades sobre como a saída será? Isso verifica a condição de erro mais comum: saídas que parecem corretas, mas não podem ser analisadas.
Este prompt fornece ao modelo contexto suficiente para atuar sem fazer suposições? Modelos que precisam fazer suposições sempre farão suposições incorretas. Contexto como terminologia de domínio, informações de limite e contexto eliminarão completamente esse tipo de erro.
Os casos extremos são cobertos? Este prompt especifica o que fazer em casos onde a entrada é ambígua, incompleta ou fora dos limites? Este é o mais comum de ser esquecido e o que causa a maioria dos problemas relacionados à produção. Alucinações, formatos de entrada inesperados, informações ausentes – tudo isso precisa ser abordado neste prompt.
Escala de pontuação: 90–100 está pronto para produção. 75–89 tem lacunas, mas é funcional. 50–74 funciona, mas é pouco confiável. Abaixo de 50 significa problemas estruturais significativos que precisam ser corrigidos antes do lançamento.
Temos as pontuações e explicações para cada critério. Em seguida, produzimos uma versão concreta do prompt aprimorado. As recomendações não são apenas ideias abstratas. Elas correspondem a mudanças reais na estrutura do prompt. Essas mudanças incluem adicionar especificações de saída que estavam faltando, tornar instruções pouco claras mais precisas, dividir questões relacionadas a conteúdo e formato, e explicitar os planos de contingência para casos extremos.
A principal restrição que impomos é a preservação da intenção. Em outras palavras, não estamos reescrevendo o prompt. Em vez disso, estamos preenchendo as lacunas que a avaliação destacou, mantendo a intenção e o domínio originais.
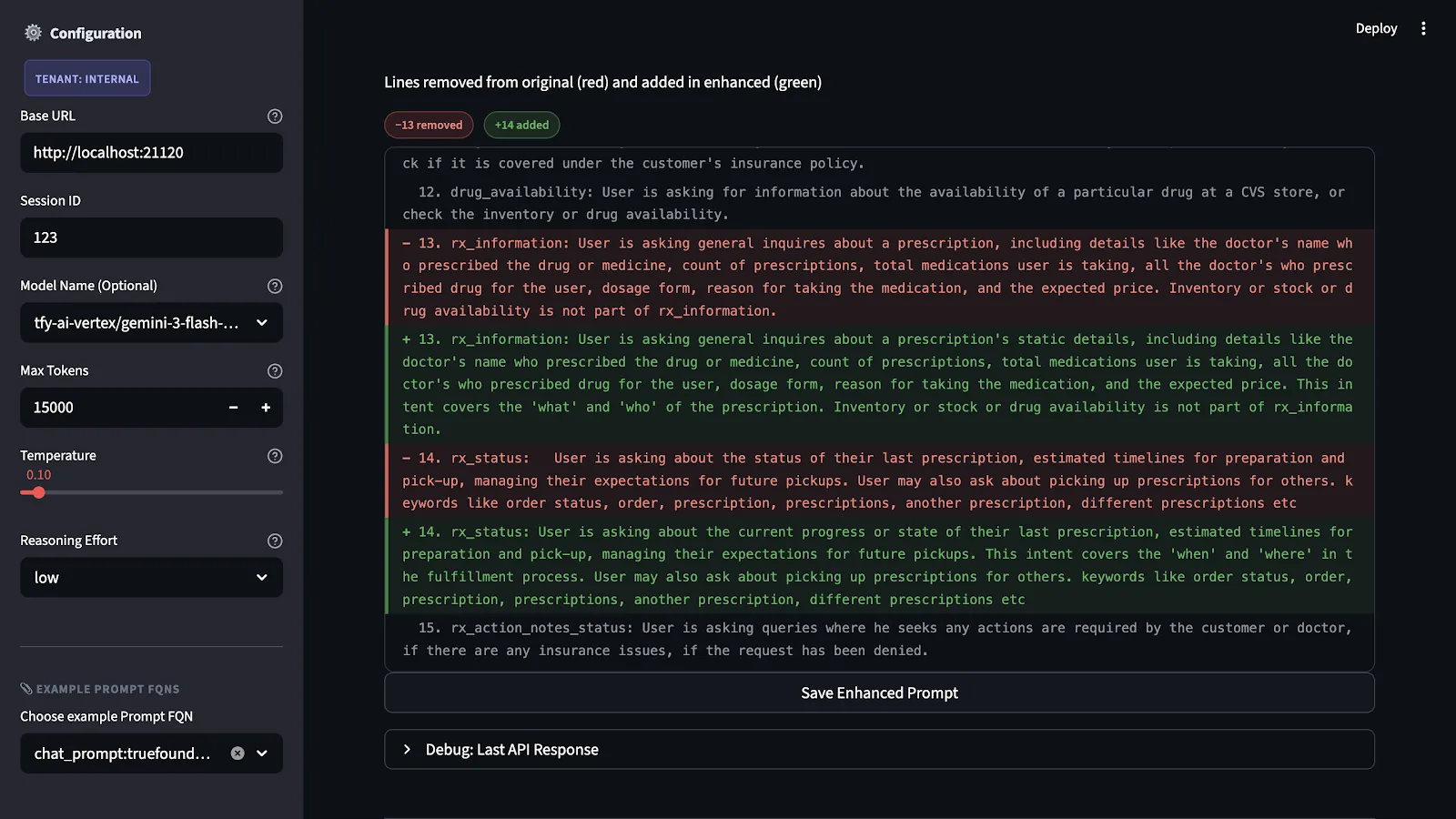
O prompt aprimorado não é executado até que seja testado pela primeira vez. O teste é realizado usando um conjunto de dados de referência que representa todos os cenários e falhas possíveis em relação à aplicação.
Este processo é necessário porque alterações em prompts que parecem benéficas em teoria podem causar problemas não intencionais na aplicação. Embora tornar uma especificação de saída mais rigorosa possa causar problemas não intencionais na aplicação devido à sua dependência da flexibilidade do modelo em outras situações, isso pode causar problemas quando combinado com certos tipos de entrada.
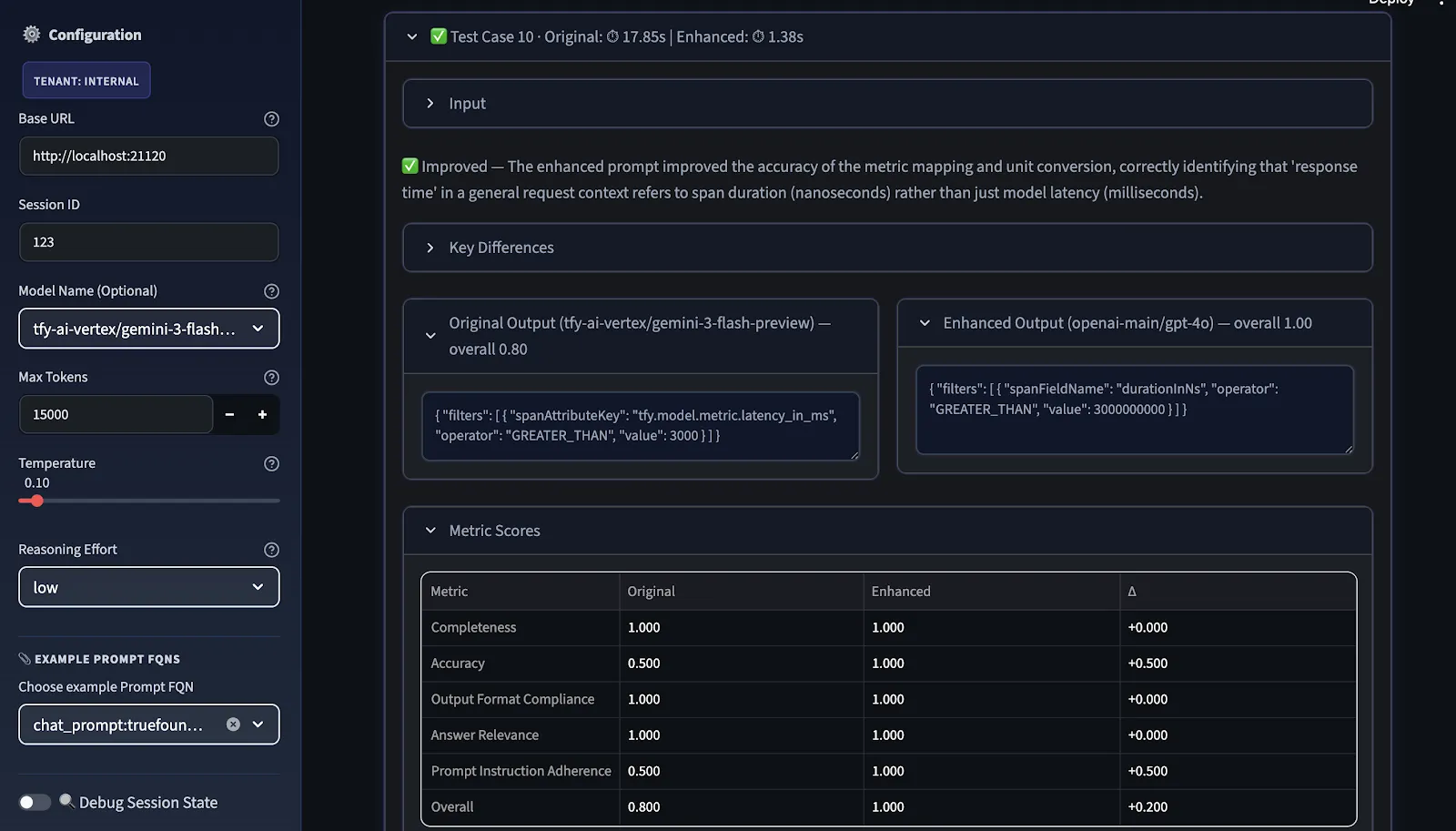
O passo final é o benchmarking. Comparamos os prompts original e aprimorado em duas dimensões:
A pontuação geral é a média aritmética das métricas selecionadas; os usuários podem escolher métricas relevantes antes da avaliação.
A visualização de comparação mostra onde a melhoria é real, onde é específica do modelo e onde é necessária uma iteração adicional antes que o prompt possa ser considerado portátil entre provedores.
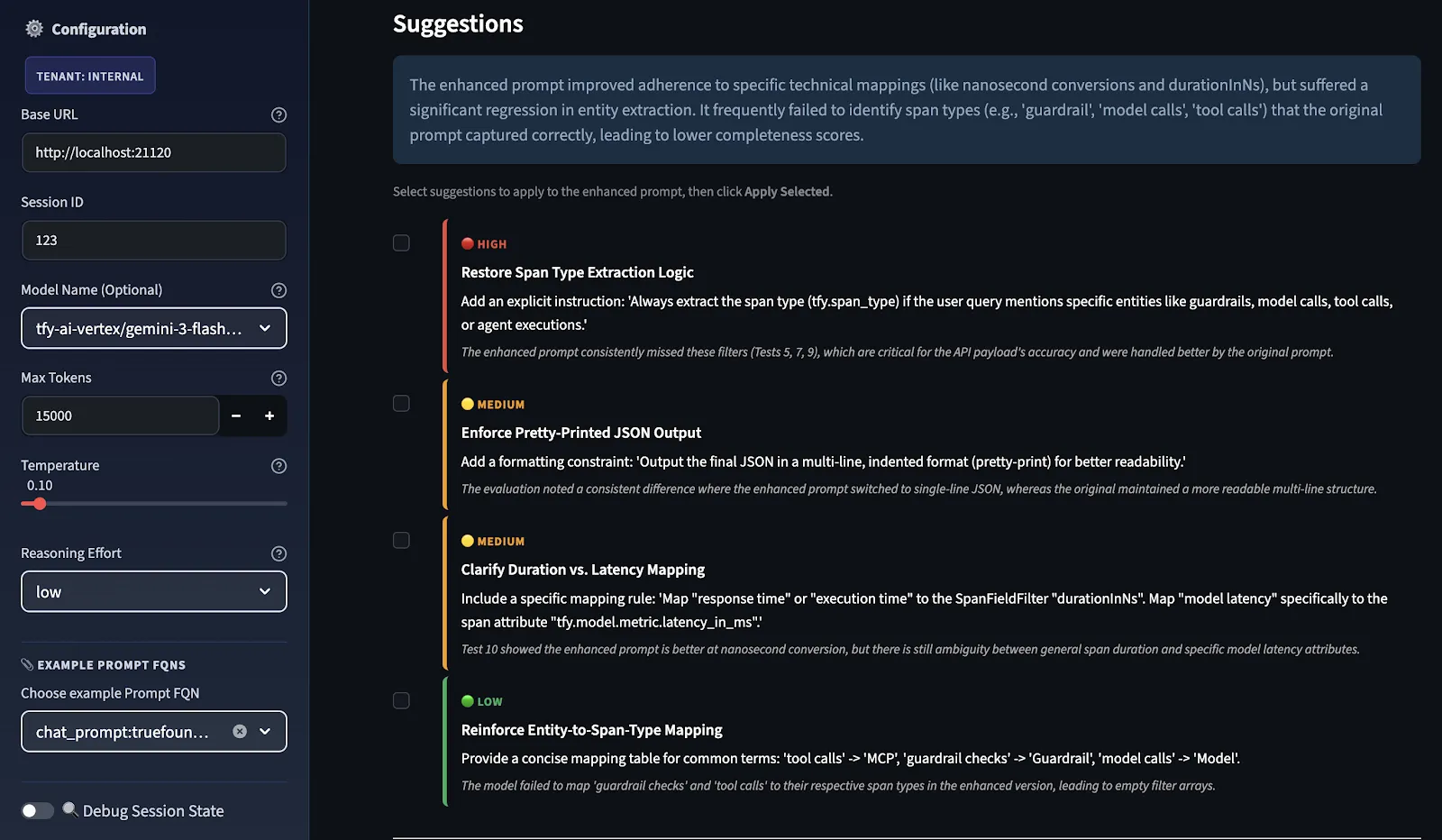
Posteriormente, o LLM Judge pontua ambos os prompts, e sugestões de melhoria são fornecidas em ordem de prioridade, categorizadas como ALTA, MÉDIA e BAIXA com base onde a diferença de pontuação entre o original e o aprimorado foi mais fraca.
Você seleciona quais sugestões aplicar como recomendação, e o sistema as envia de volta através do mesmo pipeline de aprimoramento para produzir um prompt aprimorado e refinado. Este ciclo de feedback melhora continuamente o prompt, reavaliando-o e refinando-o.
Estas não são sugestões gerais; são específicas para casos de teste. A razão é que o modelo Avaliador está avaliando o desempenho dos seus prompts originais e dos seus prompts aprimorados nos seus casos de teste. Estas sugestões que você está vendo estão diretamente relacionadas ao que faltou na sua avaliação de caso de teste. Se você adicionasse casos de teste adicionais a esta avaliação, poderia ver sugestões diferentes.
Você pode repetir este processo quantas vezes forem necessárias. Cada ciclo usa o prompt aprimorado anteriormente como a nova linha de base, permitindo que as melhorias se acumulem. O prompt refinado final pode ser baixado diretamente da interface do usuário e implantado usando True Foundry Gateway.
Quando falamos sobre engenharia, há algo em que muitas vezes não pensamos. A questão é que modelos como Gemini, GPT-5, Claude e LLaMA não entendem as coisas da mesma forma. Isso ocorre porque todos foram treinados de maneiras que aprenderam de diferentes conjuntos de informações e foram feitos para fazer as coisas de forma um pouco diferente. Então, quando lhes perguntamos algo, eles podem nos dar respostas diferentes. Isso não é porque a pergunta seja ruim. É porque cada modelo tem sua própria maneira de fazer as coisas.
Alguns modelos são muito bons em seguir as regras e fazer o que dizemos. Modelos GPT-4, por exemplo, podem ser muito literais. Modelos LLaMA podem ser mais generativos. Tentam preencher as lacunas. Modelos Claude podem ser bons em lidar com perguntas complicadas. Outros modelos podem ser melhores em responder a perguntas simples.
A única maneira de saber como um prompt se comporta entre modelos é testá-lo. E a única maneira de tornar esse teste sistemático é ter um fluxo de trabalho de avaliação como este.
Uma vez que seu prompt é avaliado, aprimorado e testado, você precisa de um sistema para gerenciá-lo ao longo do tempo — versionamento, implantação específica do ambiente e a capacidade de reverter alterações ruins sem reimplantar todo o seu aplicativo.
É aqui que entra o AI Gateway da TrueFoundry. A TrueFoundry oferece um sistema centralizado de gerenciamento de prompts com versionamento integrado — cada alteração em um prompt é rastreada, e você pode referenciar versões específicas usando aliases legíveis por humanos como v1-prod ou v2-staging. O Gateway resolve a versão do prompt em tempo de execução, o que significa que as atualizações de prompt não exigem mais reimplantações de código.
À medida que o fluxo de trabalho foi aplicado a uma variedade de prompts e projetos, vários pontos-chave tornaram-se evidentes:
O objetivo que buscamos é tornar a qualidade dos prompts tão mensurável e auditável quanto qualquer outra parte da sua pilha de software. Isso significa testes de regressão automatizados para prompts quando a versão do modelo subjacente muda, versionamento de prompts integrado ao seu pipeline de implantação e painéis de avaliação que oferecem visibilidade sobre o desempenho dos prompts ao longo do tempo.
A engenharia de prompts não é mais considerada uma arte, mas uma ciência. Organizações que a tratam como tal e implementam um processo formal para avaliação, iteração e testes estarão mais bem posicionadas para construir sistemas de IA mais confiáveis do que aquelas que não o fazem. O processo descrito neste fluxo de trabalho é um esforço nesse sentido.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




