



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
No mundo atual impulsionado por dados, pesquisar grandes volumes de dados para encontrar itens semelhantes é uma operação fundamental usada em várias aplicações, desde bancos de dados a motores de busca e sistemas de recomendação. Este processo, conhecido como pesquisa de similaridade, envolve a identificação de itens que são parecidos com base em certos critérios.
Enquanto as buscas tradicionais em bancos de dados baseadas em critérios numéricos fixos (como encontrar funcionários dentro de uma faixa salarial específica) são diretas, a pesquisa de similaridade aborda consultas mais complexas. Por exemplo, um usuário pode procurar por “sapatos”, “sapatos pretos” ou um modelo específico como “Nike AF-1 LV8”. Essas consultas podem ser vagas e variadas, exigindo que o sistema compreenda e diferencie entre conceitos como diferentes tipos de sapatos.
A pesquisa de similaridade é crucial em muitos campos, incluindo:
O principal desafio na pesquisa de similaridade é lidar com dados em larga escala, compreendendo com precisão os significados conceituais mais profundos dos itens pesquisados. Bancos de dados tradicionais, que dependem de representações simbólicas de objetos, são insuficientes em tais cenários. Em vez disso, precisamos de técnicas mais avançadas que possam lidar com representações semânticas de dados e realizar buscas eficientemente, mesmo em escala.
Ao aproveitar a pesquisa de similaridade, podemos transformar consultas complexas e abstratas em insights acionáveis, tornando-a uma ferramenta poderosa em vários domínios. Nas seções seguintes, aprofundaremos como a pesquisa de similaridade funciona, focando no papel das representações vetoriais, métricas de distância e diferentes algoritmos de busca.
.webp)
Em aprendizado de máquina, representamos objetos e conceitos do mundo real como vetores, que são conjuntos de números contínuos conhecidos como embeddings. Essa abordagem nos permite capturar os significados semânticos mais profundos dos itens. Quando objetos como imagens ou texto são convertidos em embeddings vetoriais, sua similaridade pode ser avaliada medindo a distância entre esses vetores em um espaço de alta dimensão.
Por exemplo, em um espaço vetorial, imagens semelhantes terão vetores próximos uns dos outros, enquanto imagens diferentes estarão mais distantes. Isso possibilita realizar operações matemáticas para encontrar e comparar itens semelhantes de forma eficiente.
.webp)
Vários modelos são usados para gerar esses embeddings vetoriais:
Esses modelos são treinados em grandes conjuntos de dados e tarefas, permitindo-lhes produzir embeddings que representam eficazmente o conteúdo semântico dos itens.
Para determinar o quão semelhantes são dois embeddings vetoriais, usamos métricas de distância. Essas métricas calculam a “distância” entre vetores no espaço vetorial, com distâncias menores indicando maior similaridade.
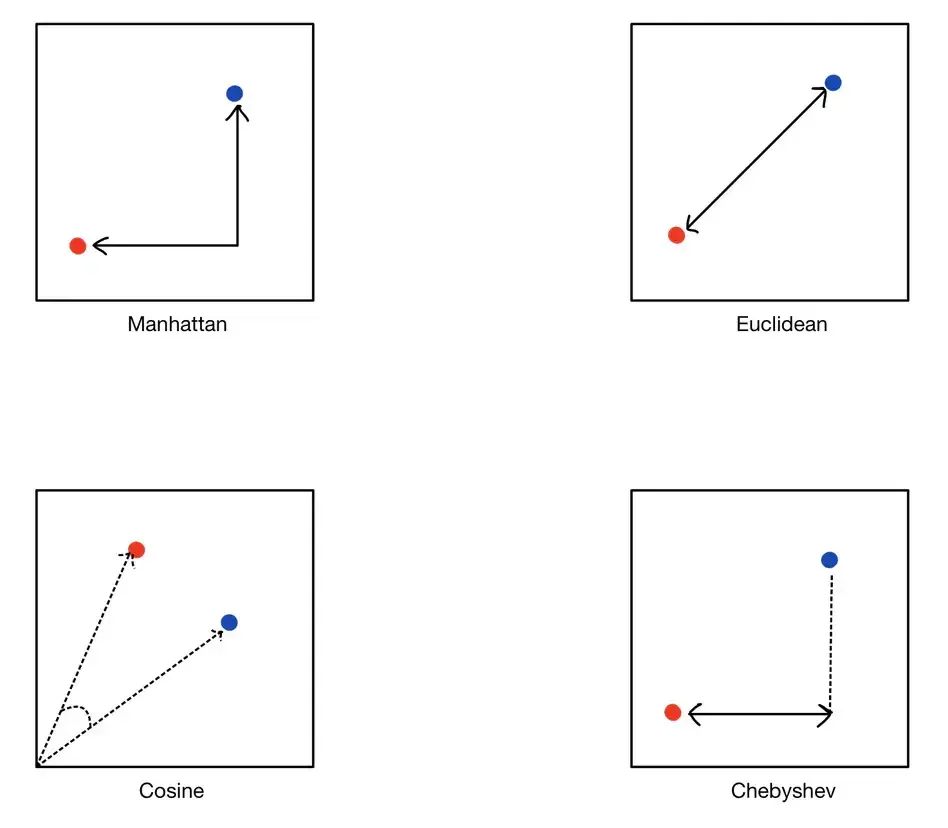
A distância euclidiana mede a distância em linha reta entre dois pontos em um espaço de alta dimensão. É a forma mais intuitiva de medir distância, semelhante à distância geométrica que você mediria com uma régua. É útil quando os dados são densos e o conceito de distância física é relevante.
Fórmula:
.webp)
Também conhecida como distância L1, a distância de Manhattan soma as diferenças absolutas de suas coordenadas. Essa métrica é adequada para estruturas de dados em grade e pode ser visualizada como a distância total de "quarteirão" que se percorreria entre pontos em uma grade.
Fórmula:
.webp)
A similaridade de cosseno mede o cosseno do ângulo entre dois vetores, focando na sua direção em vez da magnitude. Isso é particularmente útil para dados de texto, onde a magnitude do vetor (frequência de palavras) pode variar, mas a direção (padrão de uso de palavras) é mais importante.
.webp)
A distância de Chebyshev mede a distância máxima entre as coordenadas de um par de vetores. É frequentemente usada em cenários de grade semelhantes a xadrez, onde é possível mover-se em qualquer direção, incluindo diagonalmente.
.webp)
A escolha da métrica de distância correta depende das características e requisitos específicos da aplicação. Aqui estão algumas diretrizes para selecionar a métrica apropriada:
K-Nearest Neighbors (k-NN) é um algoritmo popular usado para encontrar os vetores mais próximos a um determinado vetor de consulta. Veja como funciona e seus prós e contras:
.webp)
Para resolver a ineficiência do k-NN com grandes conjuntos de dados, os métodos de Vizinho Mais Próximo Aproximado (ANN) oferecem uma alternativa mais rápida, embora menos precisa. Os algoritmos ANN visam encontrar uma "boa estimativa" dos vizinhos mais próximos, trocando alguma precisão por velocidade.
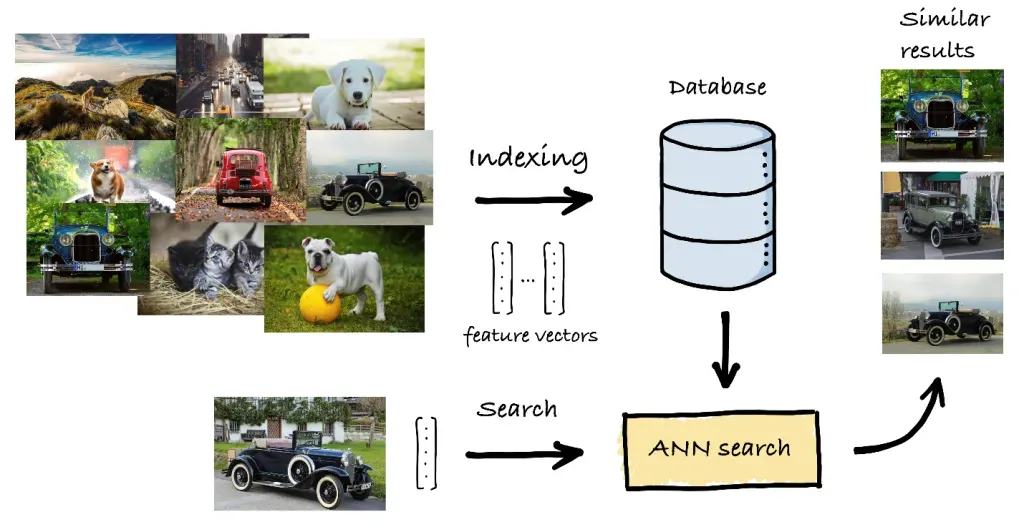
Ao implementar a busca de similaridade na prática, várias bibliotecas e frameworks podem ajudar:
A pesquisa de similaridade tem uma ampla gama de aplicações em diversas áreas, aproveitando a capacidade de encontrar e comparar itens semelhantes de forma rápida e precisa. Aqui estão algumas aplicações principais:
Sistemas de recomendação utilizam a pesquisa de similaridade para sugerir produtos, conteúdo ou serviços com base nas preferências e comportamento do usuário.
A pesquisa de similaridade é crucial para recuperar imagens ou vídeos visualmente semelhantes de grandes bancos de dados.
Em PLN, a pesquisa de similaridade ajuda em diversas aplicações baseadas em texto ao encontrar documentos ou frases semanticamente semelhantes.
Detetar atividades fraudulentas encontrando padrões e anomalias que se desviam do comportamento normal.
A pesquisa de similaridade auxilia no diagnóstico médico e na pesquisa genética, comparando dados de pacientes e sequências genéticas.
Um dos principais desafios na pesquisa de similaridade é a natureza das consultas dos utilizadores. As consultas podem variar de termos muito genéricos como "sapatos" a itens muito específicos como "Nike AF-1 LV8". O sistema deve ser capaz de discernir estas nuances e compreender como diferentes itens se relacionam entre si. Isto exige uma compreensão profunda do significado semântico por trás das consultas, que vai além da simples correspondência de palavras-chave.
Outro desafio significativo é a escalabilidade. Em aplicações do mundo real, frequentemente lidamos com conjuntos de dados massivos que podem incluir milhares de milhões de itens. A pesquisa eficiente através de volumes tão grandes de dados requer técnicas avançadas e recursos computacionais poderosos. Os sistemas de bases de dados tradicionais, que são concebidos para correspondências exatas e representações simbólicas, têm dificuldade em ter um bom desempenho nestes cenários.
A busca por similaridade, também conhecida como busca vetorial, desempenha um papel fundamental em diversas aplicações modernas. Ao aproveitar os embeddings vetoriais e métricas de distância sofisticadas, a busca por similaridade nos permite encontrar e comparar itens com base em seu significado semântico. Aqui estão os principais pontos:
Para realmente aproveitar o poder da busca por similaridade, é essencial compreender os princípios subjacentes e escolher as ferramentas e técnicas certas para suas necessidades específicas. Seja você construindo um motor de recomendação, um sistema de recuperação baseado em conteúdo ou um mecanismo de detecção de fraudes, a busca por similaridade pode aprimorar significativamente a precisão e a eficiência de suas soluções.
A busca por similaridade é uma técnica para encontrar itens semelhantes em vastos conjuntos de dados. Ela se baseia em embeddings vetoriais que capturam o significado conceitual dos dados, frequentemente utilizando representações vetoriais e métricas de distância. Este processo é crucial para aplicações como recomendações de produtos e correspondência de texto, permitindo que os sistemas identifiquem informações relevantes de forma eficiente e precisa.
Para realizar uma busca por similaridade, objetos como texto ou imagens são primeiro convertidos em embeddings vetoriais usando modelos especializados. Em seguida, métricas de distância — como a distância Euclidiana ou a Distância de Cosseno — medem a "distância" entre esses vetores em um espaço de alta dimensão. Distâncias menores indicam maior similaridade. Alternativamente, métricas de similaridade como a Similaridade de Cosseno pontuam a proximidade diretamente, onde uma pontuação mais alta (mais próxima de 1) significa maior similaridade.
Um excelente exemplo de busca por similaridade é uma plataforma de e-commerce que recomenda produtos semelhantes ao que um usuário visualizou ou comprou. Isso ajuda os compradores a descobrir itens relevantes sem esforço. A busca por imagens, encontrando fotos visualmente semelhantes em vastos bancos de dados, é outra aplicação chave que utiliza a tecnologia de busca por similaridade.
Em sistemas alimentados por LLM — particularmente em pipelines RAG (Geração Aumentada por Recuperação) — a busca por similaridade funciona em conjunto com o modelo, convertendo texto em embeddings vetoriais que capturam o significado semântico. Uma camada de recuperação pesquisa esses vetores para encontrar o conteúdo mais semelhante a uma consulta, e então passa os resultados para o LLM, medindo a distância entre esses vetores. É crucial para recuperar informações relevantes e gerar respostas conscientes do contexto, aprimorando significativamente a compreensão e a utilidade do modelo para os usuários.
A busca por similaridade é fundamental em diversas aplicações. Ela aprimora as recomendações de produtos no e-commerce, facilita a busca por imagens e vídeos e melhora o processamento de linguagem natural para correspondência de texto. Na área da saúde, auxilia na identificação de casos médicos semelhantes, transformando dados complexos em insights acionáveis em diversos setores.
A busca semântica baseia-se na busca por similaridade para encontrar itens com base em seu significado, e não apenas em palavras-chave. Ela utiliza embeddings de vetor para representar dados semanticamente. Enquanto a busca por similaridade é a técnica para comparar esses vetores, a busca semântica é a aplicação que a utiliza para uma compreensão contextual mais profunda.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




