



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
O cache de correspondência exata tem sido o padrão correto por trinta anos. É o padrão errado para LLMs, porque o texto é a superfície da intenção, não a intenção em si. O trabalho de um cache semântico é armazenar em cache o que está por baixo.
O cache de API tradicional é uma tabela hash. A requisição é "hasheada", a resposta é indexada pelo hash, e a próxima requisição byte a byte idêntica retorna o valor em cache. O modelo está correto para APIs determinísticas porque o hash captura tudo o que importa em uma requisição. Não há informação na chamada que não esteja em seus bytes.
Cargas de trabalho de LLM quebram essa suposição na superfície. Três usuários em um fluxo de suporte ao cliente perguntam a mesma coisa de três maneiras diferentes:
tráfego de usuários · janela de 60 segundos
-- Usuário A: "Como faço para redefinir minha senha?"
-- Usuário B: "Esqueci minha senha — o que devo fazer?"
-- Usuário C: "Onde fica a página de redefinição de senha?"
Para um cache SHA-256, essas são três chaves, três falhas e três chamadas completas ao provedor. Para o modelo, a intenção é idêntica e a resposta deveria ser idêntica. O cache que "hasheia" texto bruto não é um cache errado; é um cache para a camada de significado errada. O texto é um portador imperfeito de intenção — a mesma intenção tem muitas superfícies — e o cache de correspondência exata indexa a superfície em vez da substância.
A lacuna é grande o suficiente para ser relevante. Um cache que acerta apenas em requisições byte a byte idênticas captura uma pequena fração das chamadas que um cache que acerta na intenção capturaria. Fechar essa lacuna é para o que serve o cache semântico.
Um cache semântico de nível de produção não pode simplesmente incorporar e pesquisar. Ele precisa impor limites de política (diferentes prompts de sistema não devem colidir), respeitar o isolamento de inquilinos e recusar-se a confundir “meu braço esquerdo dói” com “meu braço direito dói”. O gateway TrueFoundry executa um pipeline de quatro estágios que reúne todas as quatro preocupações em um único caminho crítico.
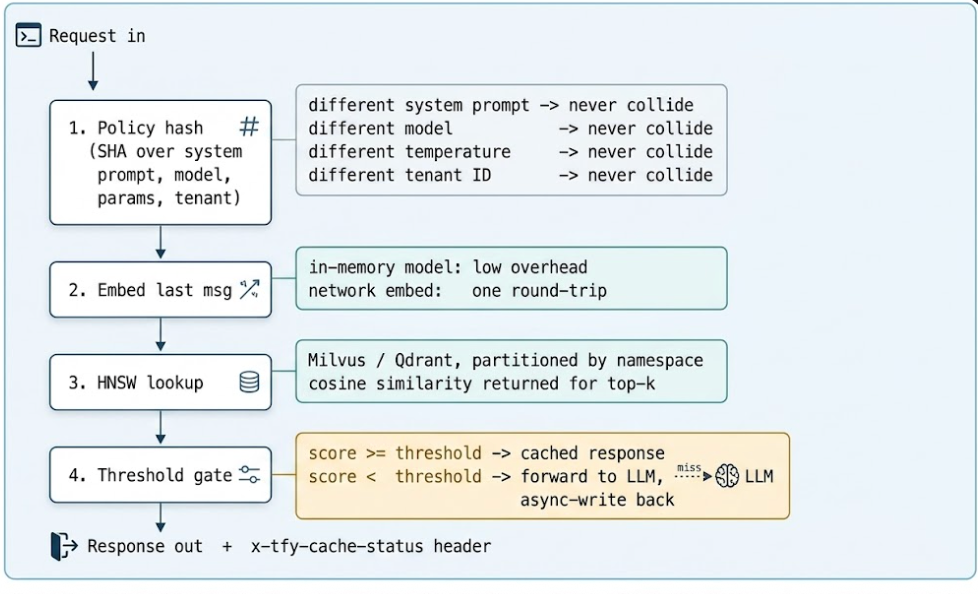
Um detalhe sutil: apenas a última mensagem é comparada semanticamente. Todo o resto — nome do modelo, temperatura, mensagens anteriores, prompt do sistema, ID do inquilino — é "hasheado" exatamente. Se algum desses não corresponder, o cache trata as requisições como diferentes, mesmo que a última linha do usuário seja idêntica palavra por palavra. Esse é o padrão correto. Um contexto de conversa pré-carregado muda o significado mais do que a maioria dos engenheiros espera, e você quer que o cache tenda a não colapsá-los.
Vetores de embedding vivem em um espaço de alta dimensão — 384 dimensões para MiniLM, 768 para BGE-base, 1536 para text-embedding-3-small. Nessa geometria, a distância euclidiana é dominada pela magnitude do vetor, que é principalmente ruído; o que carrega significado semântico é a direção. A similaridade de cosseno normaliza a magnitude calculando o cosseno do ângulo entre dois vetores — é invariante à escala, então dois vetores apontando na mesma direção pontuam 1.0 independentemente do comprimento.
Todo cache semântico moderno usa cosseno. A única vez que você recorreria à euclidiana seria se seu modelo de embedding produzisse vetores unitários normalizados de qualquer forma, caso em que as duas métricas são equivalentes até uma constante e o cosseno ainda é mais simples de entender. Não há carga de trabalho prática onde a euclidiana seja a resposta correta.
A busca ingênua pelo vizinho mais próximo é O(N) — cada consulta compara-se com cada vetor em cache. Com um milhão de entradas, o orçamento de comparação é inviável. HNSW (Hierarchical Navigable Small World) constrói um grafo em camadas onde cada nó se conecta a um pequeno número de vizinhos próximos, com links mais esparsos nas camadas superiores. Uma consulta começa na camada superior, avança de forma gulosa em direção à correspondência mais próxima, desce uma camada e repete. A busca visita O(log N) nós — aproximada, mas tipicamente com 95–99% de recall em comparação com uma busca exata, e ordens de magnitude mais barata. Milvus e Qdrant vêm ambos com HNSW; a TrueFoundry usa o que estiver configurado na implantação.
O cache semântico troca poder computacional por latência e custo do provedor, portanto, o modelo de embedding é a decisão mais importante no sistema. Existem duas opções reais.
Modelos gerenciados — text-embedding-3-small da OpenAI, Cohere, Voyage — oferecem uma forte compreensão semântica entre domínios prontamente. O custo é uma viagem de ida e volta na rede a cada solicitação, o que consome diretamente os ganhos de latência do cache. No TrueFoundry SaaS, o text-embedding-3-small (1536 dimensões) é o padrão e não é configurável pelo usuário; esta é uma escolha deliberada para o nível gerenciado — uma linha de base comprovadamente boa e barata o suficiente para ser amortizada em cada chamada.
Alternativas em memória como BGE-micro (384 dim) ou all-MiniLM-L6-v2 (384 dim) são executadas dentro do processo do gateway, eliminam completamente a dependência de rede e removem a viagem de ida e volta do embedding do caminho da solicitação. No nível on-premise, o modelo de embedding é configurável através do painel (Controles → Configurações → Cache Semântico); a escolha se aplica a todo o gateway. Para cargas de trabalho internas — assistentes de codificação, documentação técnica, fluxos de suporte ao cliente — o ajuste fino de um pequeno modelo local no vocabulário do domínio geralmente é a ação de maior ROI em toda a pilha. “k8s” e “Kubernetes” devem ser incorporados em vetores quase idênticos. Um modelo de propósito geral os trata como primos; um modelo ajustado os trata como sinônimos. A taxa de acertos se ajusta de acordo.
Há uma observação prática sobre as dimensões. Embeddings de dimensões mais altas (1536) carregam mais informações semânticas, mas custam mais para indexar e pesquisar; HNSW com 1536 dimensões consome aproximadamente 4× a memória e 2× o tempo de busca de 384 dimensões. Para a maioria das cargas de trabalho de cache, o ganho marginal de recall de 1536 sobre um modelo de 384 dimensões ajustado é pequeno o suficiente para que as economias operacionais dominem. Comece com 384 e só aumente se a precisão e o recall medidos no tráfego real justificarem.
Tabela 1 — O modelo de embedding é o controle que decide se o cache semântico resulta em ganho de latência ou em latência neutra. Em produção, o caminho em memória é o caminho que se paga.
O limite de similaridade é o controle deslizante entre economia e risco. Ao diminuí-lo, a taxa de acertos aumenta, o custo diminui — e também a chance de um falso positivo, retornando uma resposta desatualizada ou contextualmente errada. O controle está dentro da solicitação via x-tfy-cache-config:
HTTP · cabeçalho de solicitação
x-tfy-cache-config: {
"type": "semantic",
"similarity_threshold": 0.94,
"ttl": 600,
"namespace": "tenant-123"
}O ponto de partida recomendado pela TrueFoundry é 0.9, com uma faixa que depende da tolerância a acertos de cache incorretos.
Tabela 2 — Faixa de limite. Não há um valor “correto” global; o limite certo é aquele que corresponde ao custo de um falso positivo no seu domínio.
O experimento mental de triagem médica torna o perigo concreto. “Meu braço esquerdo dói” e “Meu braço direito dói” podem obter uma pontuação de 0.91 em um espaço de embedding de propósito geral. Com um limite de 0.90, o cache alegremente retorna o mesmo conselho para duas condições fisicamente opostas. Para um bot de FAQ geral, 0.88 pode ser perfeitamente seguro. Para triagem, é negligência. O limite não é um hiperparâmetro global; é uma codificação por carga de trabalho de quão cara é uma resposta errada.
Escolher um limite é escolher um ponto em uma curva de precisão/recall específica para o seu tráfego. Abaixo está o que essa curva tipicamente se parece para uma carga de trabalho de suporte ao cliente — a sua será deslocada para a esquerda ou direita, mas a forma é a mesma:
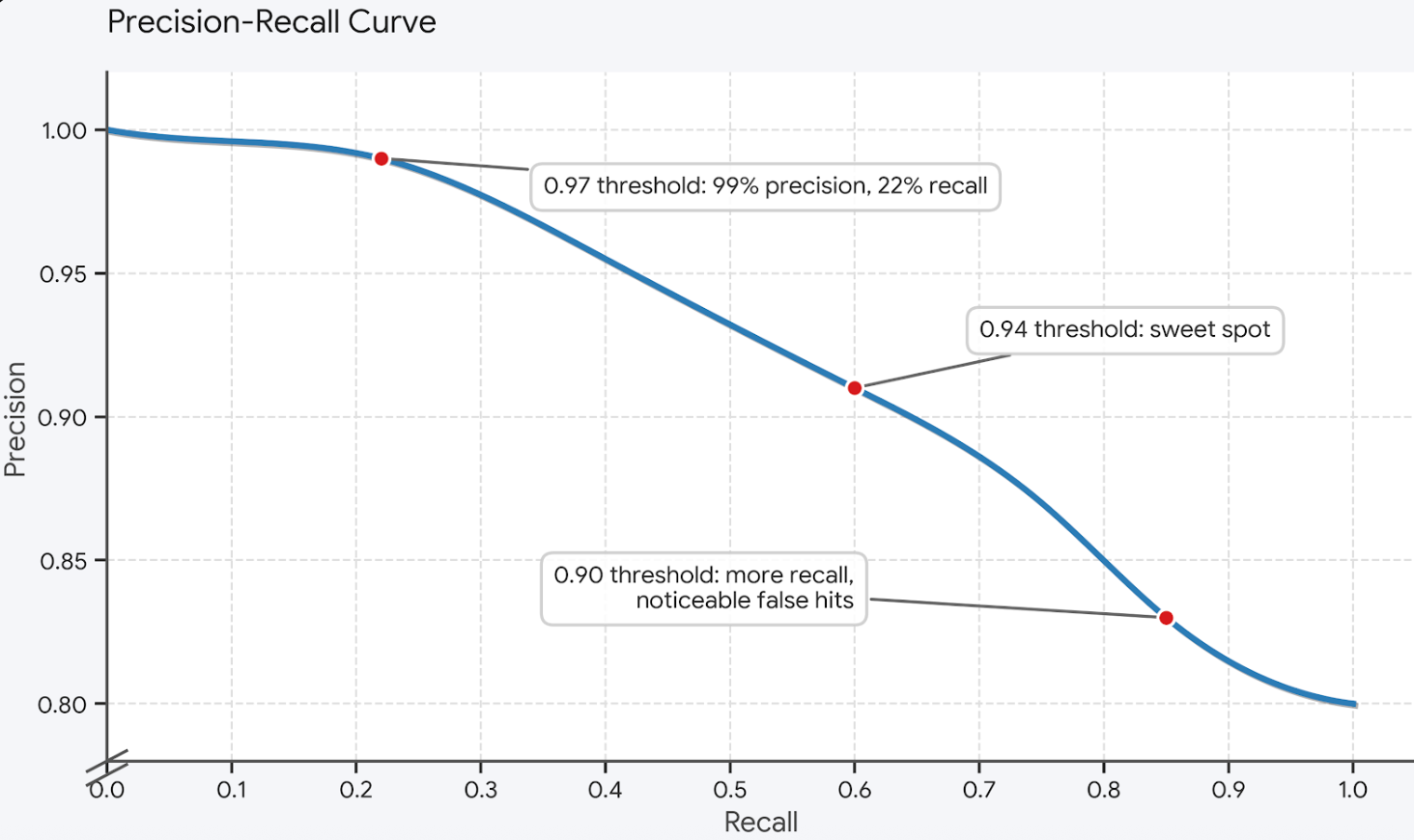
A disciplina correta para escolher um ponto é o modo sombra. Por um período configurável — tipicamente uma semana — o cache calcula similaridades e registra o que teria correspondido em cada limite sem realmente servir respostas em cache. Os engenheiros revisam o log, traçam sua versão da curva acima contra o tráfego real e escolhem um limite que leva os falsos positivos a um nível que a carga de trabalho pode tolerar. O limite não é uma constante global; é um controle de ajuste por carga de trabalho, e os dados de ajuste devem vir do tráfego de produção, não de consultas sintéticas.
Em cada resposta, o gateway retorna três cabeçalhos que tornam este ciclo depurável: x-tfy-cache-status (acerto / falha / erro), x-tfy-cache-similarity-score (a pontuação de cosseno nos acertos) e x-tfy-cached-trace-id (o ID de rastreamento da solicitação original que preencheu a entrada). O terceiro é aquele ao qual você sempre retornará — ele permite rastrear qualquer resposta em cache de volta à conversa que a produziu, que é a única maneira de depurar uma falha.
A similaridade semântica torna-se perigosa quando a verdade subjacente mudou. “Qual é a taxa de juro atual?” ontem e hoje são semanticamente idênticas e factualmente diferentes. A cache servirá alegremente o número do mês passado com uma pontuação de similaridade de 1.0.
As cargas de trabalho precisam de TTLs específicos para a carga de trabalho. Assistentes de documentação estática utilizam um TTL confortável de vários dias porque a verdade subjacente são os documentos, e os documentos mudam à velocidade dos lançamentos. Aplicações RAG usam invalidação por hash de documento: quando o documento fonte muda, cada entrada de cache derivada dele é automaticamente limpa. Fatos sensíveis ao tempo (taxas, preços, horários) recebem TTLs curtos e rígidos e nunca se unem através de limites diários. Para estes, o cache semântico é frequentemente a ferramenta errada, e você deve recorrer à correspondência exata ou a nenhuma cache.
Vale a pena ser honesto sobre o que o cache semântico não é bom. Qualquer coisa que deva mudar à medida que o mundo muda é um mau material para cache em qualquer limite. A regra de ouro: se um humano notaria que a resposta está desatualizada, a cache também está.
Existe um perigo operacional que vale a pena abordar explicitamente no design: a sobrecarga de cache. Se uma consulta popular expira e mil requisições idênticas chegam no mesmo segundo, uma cache ingénua permitirá que todas as mil passem para o LLM, e depois fará com que todas as mil tentem gravar o resultado de volta. O gateway TrueFoundry usa semântica de 'single-flight' — a primeira requisição que falha adquire um bloqueio por chave; requisições idênticas subsequentes durante a chamada ao LLM esperam por essa única resposta e a reutilizam. A gravação de volta é assíncrona (a resposta é retornada ao cliente imediatamente, o vetor é commitado para Milvus/Qdrant em segundo plano), então as gravações na cache nunca aparecem na latência do caminho da requisição.
Em qualquer implementação SaaS B2B, o inquilino A receber uma resposta em cache gerada para o inquilino B não é um bug. É uma violação. A arquitetura da cache deve ser hostil a esse resultado por design, e não por filtragem posterior.
O TrueFoundry isola as entradas de cache em dois níveis e o utilizador não precisa de se preocupar com o primeiro.
O Nível 1 é suficiente para a maioria das equipas. O Nível 2 é a alavanca que você usa quando uma conta virtual se expande para muitos utilizadores finais a jusante — um SaaS que atua como proxy para requisições LLM em nome dos seus próprios clientes, por exemplo — e uma cache por cliente é o que os seus compromissos de residência de dados exigem. De qualquer forma, não há um pool de vetores global de onde possa haver vazamento. Esta é a implementação que satisfaz os revisores SOC 2 e HIPAA.
Anthropic e OpenAI lançaram ambos o cache do lado do prompt: o provedor faz o hash de um prefixo do prompt do sistema e reutiliza o estado interno em acertos de cache, cobrando menos pelos tokens de entrada em cache. Esta é uma camada diferente da que temos discutido, e as duas se compõem.
O cache de prompt do provedor reduz o tempo para o primeiro token e diminui o custo dos tokens de entrada em cache, mas o modelo ainda gera uma conclusão nova. O cache semântico do gateway elimina completamente a chamada ao modelo. A maioria das equipas que beneficia de um beneficia de ambos, e a cache do lado do gateway é a alavanca maior — melhoria de latência de ordem de magnitude em acertos, eliminação total de custos e uma camada que a organização pode depurar, auditar e ajustar sem envolvimento do provedor. A cache do provedor é opaca; a cache do gateway é sua.
Existe uma antiga observação em sistemas distribuídos: as caches preservam a correção apenas na camada de significado que foram projetadas para capturar. Uma cache de página funciona porque as páginas são a unidade de correção. Uma cache de consulta funciona porque consultas idênticas produzem resultados idênticos. Uma cache de LLM que faz hash de texto está a fazer cache na camada de significado errada, e o erro aparece na forma de falhas onde deveriam ser acertos.
O cache semântico é o trabalho de mover a chave da cache de texto para intenção. Ele precisa de mais infraestrutura (um modelo de embedding, um índice de vetor, um limiar) porque a intenção é um objeto mais abstrato do que uma string. Mas é a abstração correta para a carga de trabalho, e uma vez que a camada de cache corresponde à camada de significado, as economias deixam de parecer uma otimização e começam a parecer a arquitetura certa desde o início.
Não. O cache semântico é um superconjunto estrito — a correspondência exata é apenas a similaridade de cosseno 1.0. No TrueFoundry, definir o tipo de cache como semântico também retorna acertos de correspondência exata. Executar ambas as camadas separadamente é infraestrutura duplicada que complica a invalidação, e o gateway as trata como uma única camada.
Apenas se você usar um modelo de embedding hospedado em rede em uma carga de trabalho onde a maioria das chamadas não acerta o cache. O objetivo de executar um pequeno modelo em memória nos nós do gateway é manter o custo do embedding bem abaixo do limite onde anularia o ganho nos acertos. Na camada SaaS, o modelo de embedding padrão é o text-embedding-3-small, que adiciona aproximadamente uma viagem de ida e volta na rede; esse é o custo de operar nenhuma infraestrutura de embedding por conta própria.
Execute o modo sombra por pelo menos uma semana. Não lance um limite sem ver o que ele teria servido contra o seu tráfego real. A mesma pergunta pontuada de forma ligeiramente diferente em dados sintéticos e em dados de produção é a surpresa que acaba com carreiras — e é totalmente evitável com um log e um notebook Jupyter.
O cache é decidido antecipadamente, antes que a chamada do modelo comece. Em caso de acerto, a resposta é retornada imediatamente sem interrupção no streaming. Em caso de erro, a resposta de streaming é capturada assincronamente e confirmada de volta ao cache após a conclusão da chamada — não há uma compensação entre streaming e cache para gerenciar.
O gateway reverte para encaminhar cada requisição para o provedor LLM. Os erros de cache custam o que teriam custado sem o cache; nada é comprometido. O único sinal operacional é o cabeçalho x-tfy-cache-status: error nas respostas, ao qual um alerta do painel deve ser conectado. A confiabilidade do caminho da requisição supera a disponibilidade da camada de cache.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




