



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
"Esgotou a cota da API em 20 minutos" não é uma história mítica de SRE; é uma tarde de terça-feira com um loop mal delimitado. Baldes de tokens, disjuntores e uma cadeia de fallback elegante — tudo imposto no gateway antes que o loop toque um provedor.
429 não é uma falha. É o gateway dizendo a um agente descontrolado para recuar. O agente obedece, o disjuntor aguenta, o orçamento sobrevive ao dia.
Agentes LLM falham de uma forma específica. O incidente de produção mais comum não é um modelo dando a resposta errada; é um agente que decide tentar novamente, e novamente, e novamente, e novamente. Cada nova tentativa é uma chamada completa ao provedor. Cada chamada adiciona ao contexto. O contexto cresce quadraticamente. Tokens são consumidos a uma taxa que o humano na frente do teclado nunca produziria — porque não há humano na frente do teclado.
A aritmética é brutal. Um contexto inicial de 4.000 tokens, dobrando a cada passo porque a saída do passo anterior é anexada, atinge 128.000 tokens no passo 5 e o custo por passo aumentou 32 vezes. No passo 15, o contexto transbordou a janela do modelo e cada chamada está pagando a taxa de contexto máximo. No passo 30, o loop gastou mais do que o salário mensal de um engenheiro competente. O agente nunca percebeu; o trabalho do agente é continuar.
Na primeira vez que a maioria das equipes vê isso, elas veem na fatura do dia seguinte. Na segunda vez, elas implementam a limitação de taxa. O lugar certo para essa limitação de taxa não é a aplicação — é o gateway, onde uma única camada protege cada carga de trabalho, independentemente do framework que iniciou o loop. Uma equipe que coloca o limite dentro de cada agente tem que escrevê-lo novamente para cada agente, perdê-lo em alguns e descobrir os modos de falha individualmente. Uma equipe que o coloca no gateway o escreve uma vez e herda a proteção em todas as cargas de trabalho que chamam um modelo.
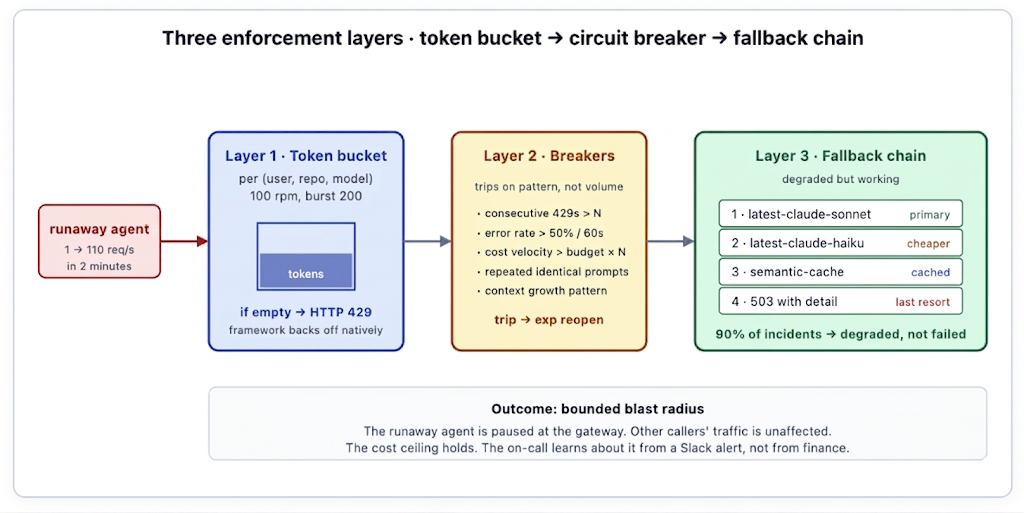
O balde é a primeira linha de defesa. Cada tupla (usuário, repositório, modelo) recebe seu próprio balde — digamos, 100 requisições por minuto com um pico de 200. Os reabastecimentos ocorrem continuamente na taxa configurada. Quando uma requisição chega e o balde está vazio, o gateway retorna HTTP 429 imediatamente, antes que a requisição chegue ao provedor. O 429 carrega um Retry-After cabeçalho indicando quanto tempo o chamador deve esperar.
A escolha da granularidade importa. Um único balde por usuário é muito grosseiro — um script mal-intencionado bloqueia todo o trabalho legítimo do usuário, incluindo o trabalho de que ele precisa para depurar o script mal-intencionado. Um balde por requisição é muito fino — não há nada para limitar. A tupla (usuário, repositório, modelo) geralmente tem o formato certo: ela isola o repositório descontrolado das outras cargas de trabalho do usuário, permite que a equipe da plataforma defina tetos diferentes para diferentes níveis de modelo (mais permissivos em modelos baratos, mais rigorosos em modelos de ponta) e produz detalhamentos dimensionais úteis no painel de limite de taxa. Algumas equipes adicionam uma quarta dimensão — ID de pipeline ou fluxo de trabalho — para produtos de IA multi-tenant onde o balde deve pertencer ao cliente em nome de quem a requisição é feita, e não à equipe que executa o serviço.
A maioria dos frameworks de agentes interpreta 429 como um sinal padrão de backoff. O agente pausa, espera pela duração sugerida e tenta novamente — exatamente o comportamento que o gateway deseja. Frameworks que não lidam com 429 de forma elegante estão quebrados de outra forma, mas o gateway já fez seu trabalho. O contrato é padrão HTTP: 429 com Retry-After é o que toda biblioteca cliente HTTP sabe como lidar há quinze anos. Equipes que descobrem que seu framework de agente não consegue processar 429 corretamente devem corrigir o framework, não o gateway.
O burst é o parâmetro que é ajustado. Defina o burst muito baixo e cargas de trabalho legítimas com picos (gatilhos de CI, avaliações em lote, horários de pico de chatbots para usuários) atingem 429 falsamente; defina-o muito alto e o limite de taxa não restringe de fato um descontrole. O ponto de partida certo é empírico — observe o formato natural do pico de tráfego legítimo no mês anterior, defina o tamanho do balde para aproximadamente o pico P99 observado e ajuste a partir daí com base em reclamações de falsos positivos.
Baldes de tokens gerenciam o volume. Disjuntores gerenciam padrões. Alguns processos descontrolados passam despercebidos pelo limite do balde, mas exibem outros sinais de comportamento patológico — um agente que obedece ao balde de 100 rpm, mas está fazendo 100 chamadas idênticas por minuto em um loop apertado, ainda é um processo descontrolado, apenas mais lento. O gateway monitora o tráfego recente de cada identidade e dispara quando uma das seguintes condições é atendida:
Cada disjuntor tem sua própria lógica de disparo e reabertura. O efeito combinado é que o comportamento patológico é interrompido rapidamente, sem disparos falsos positivos em tráfego legítimo e em rajadas. O disjuntor é configurado no nível da plataforma e se aplica a cada identidade; os limites são ajustados ao longo do tempo com base na taxa de falsos positivos que a equipe está disposta a tolerar.
A velocidade do custo é o disjuntor que a maioria das equipes subimplementa, porque exige que o gateway saiba o custo de cada requisição em tempo real — tokens de entrada, tokens de saída, tokens em cache, precificação específica do modelo — e o alimente na lógica do disjuntor antes que a próxima requisição seja admitida. O gateway da TrueFoundry calcula o custo por requisição na saída usando a precificação atual do provedor e expõe a taxa de custo em execução ao disjuntor como uma entrada de primeira classe. Uma carga de trabalho que excede sua taxa de custo planejada por um multiplicador configurável dispara; o disjuntor é parametrizado em relação ao orçamento da carga de trabalho, e não contra um valor absoluto em dólares, o que torna o limite durável em relação às mudanças de preço do provedor. Equipes que adaptam a velocidade do custo a um gateway que não conhece nativamente o custo por requisição acabam com tabelas de preços desatualizadas e limites de disjuntor que precisam de recalibração manual a cada trimestre; a versão integrada não tem essa sobrecarga de manutenção.
Quando o caminho primário está indisponível — o balde de tokens está limitado, o disjuntor está aberto, o próprio provedor está com uma interrupção — falhar todas as requisições de forma abrupta é o resultado errado. Uma cadeia de fallback configurável serve uma saída degradada em vez disso. A cadeia é uma configuração declarativa, por rota:
# Per-route configuration
fallback_chain:
- model: "claude-4-6-sonnet" # primary
- model: "claude-4-5-haiku" # cheaper, still capable
- source: "semantic-cache" # cached response if similar
- response: 503 # last resort, descriptive errorA cadeia é um controle de configuração, não um comportamento codificado. Rotas diferentes têm cadeias diferentes. Um pipeline de codificação pode ter uma cadeia de 2 etapas (Sonnet → Haiku → 503) porque um resultado Haiku degradado é, às vezes, pior do que uma falha clara. Um chatbot voltado para o usuário pode ter uma cadeia de 4 etapas que inclui o cache semântico como um fallback elegante, porque qualquer resposta é melhor do que nenhuma resposta para o usuário. Um fluxo de trabalho de alto risco (redação jurídica, análise financeira) pode não ter nenhuma cadeia de fallback — o único comportamento aceitável em caso de falha primária é exibir o erro para que um humano possa decidir.
O ponto é que a plataforma decide o que "degradado" significa para cada carga de trabalho, em vez de cada carga de trabalho decidir por si mesma. Na prática, é isso que transforma 90% dos incidentes de "capacidade esgotada" em incidentes "degradados, mas funcionando" — visíveis para a equipe da plataforma, invisíveis para o usuário final. O cache semântico é o membro subutilizado da cadeia na maioria das configurações das equipes; uma carga de trabalho com uma taxa de acerto de cache razoável (digamos, 30%) sobrevive à maioria das interrupções de curta duração, servindo respostas em cache para consultas suficientemente semelhantes.
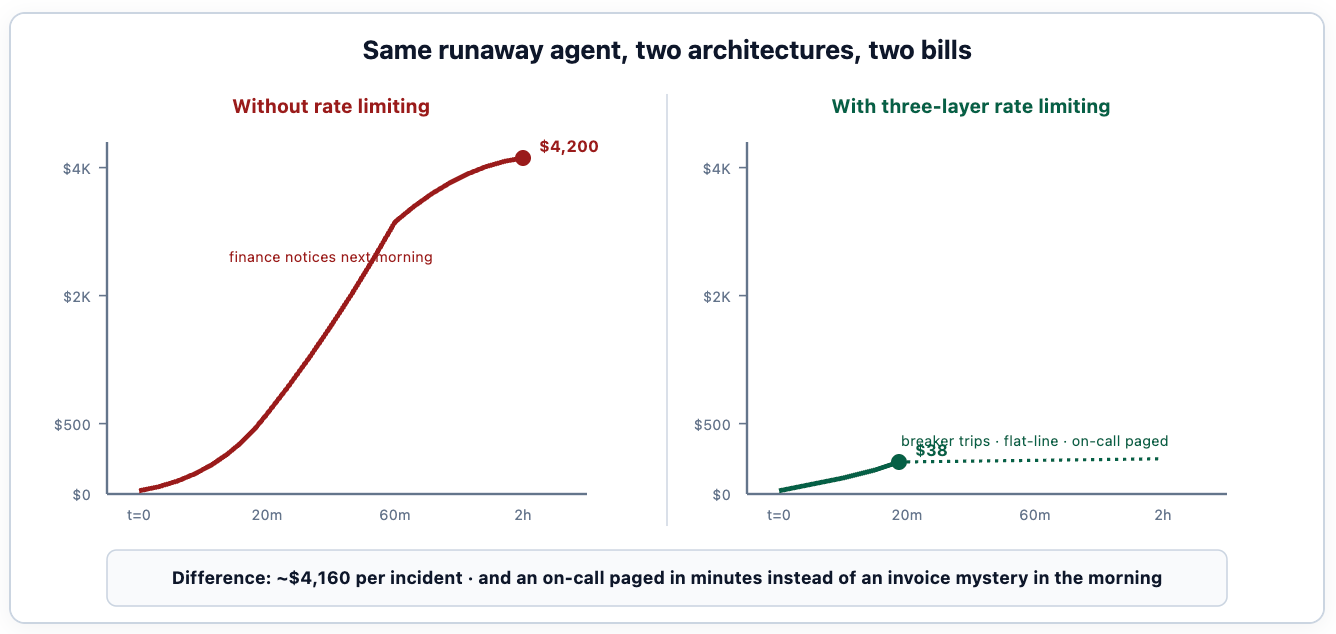
O argumento econômico é o que faz com que o projeto de limitação de taxa seja financiado. Um único incidente descontrolado sem aplicação normalmente custa $2.000-$8.000 até que alguém perceba; o mesmo incidente com as três camadas implementadas custa $20-$100 e produz uma análise pós-incidente tratável em vez de um e-mail de desculpas para o financeiro. O primeiro incidente paga o esforço de engenharia para construir a camada de limitação de taxa de cinco a dez vezes.
O contrato da perspectiva do chamador é padrão HTTP. Os quatro resultados cobrem todos os estados que a camada de limitação de taxa pode produzir, e cada um mapeia para uma remediação bem compreendida. O código do agente não precisa saber que a arquitetura de limitação de taxa existe; ele precisa saber como lidar com 429, 503 e o cabeçalho de identificação do modelo. Três linhas de código de tratamento de erros são suficientes para a maioria dos frameworks de agentes.
Sinais de alerta são disparados apenas quando o disjuntor realmente desarma, não a cada 429. Um 429 é normal; um disjuntor desarmado é anômalo. O engenheiro de plantão recebe um único alerta do Slack, acionável:
[BREAKER TRIPPED] runaway-agent detection on identity=devops-bot/infra-tf
trace_id: 7e9d8a1b
pattern: 110 req/s sustained, repeated identical prompts
cost velocity: $42/min (planned: $4/min)
action taken: requests blocked for 5 min, exponential reopen
suggested mitigation: review pipeline logs at <link>ID de rastreamento, identidade, padrão, custo, mitigação. Tudo o que o engenheiro precisa para decidir se deve estender o disjuntor, aumentar a cota ou contatar a equipe responsável pelo pipeline problemático. O alerta é projetado para ser triado em 30 segundos: em 90% das vezes, o alerta indica um descontrole legítimo e o engenheiro estende o disjuntor, publica no canal da equipe responsável e volta ao que estava fazendo. Em 10% das vezes, é um falso positivo (um pico legítimo que os limites não previram) e o engenheiro aumenta a cota e adiciona o caso à revisão de ajuste de limites.
O formato do alerta é o artefato operacional que é ajustado mais do que os próprios limites do disjuntor. A primeira versão do alerta geralmente é muito prolixa (todos querem saber de tudo) e acaba sendo ignorada; a sétima versão é aquela que contém exatamente os cinco fatos que o engenheiro realmente precisa. A disciplina é tratar o alerta como um produto, tendo o plantonista como usuário.
O formato de alerta padrão da TrueFoundry vem com esses cinco fatos (ID de rastreamento, identidade, padrão, velocidade de custo, link direto para o painel da carga de trabalho) calibrados com base nas lições operacionais da execução desta camada de limite de taxa para os clientes existentes da plataforma. As equipes podem substituir o formato por rota; a maioria não o faz, porque o padrão já é o que teriam alcançado na sétima iteração. O design estrutural é a contribuição — nomear os cinco fatos certos na granularidade correta — e não o esquema YAML que os contém.
As três camadas se compõem em uma configuração por rota que a equipe da plataforma gerencia. Abaixo está como se parece uma configuração funcional para uma carga de trabalho agêntica de CI/CD — o caso canônico onde o limite de taxa é mais importante porque o mecanismo de ritmo humano está ausente:
name: ci-cd-agent-routing
type: gateway-load-balancing-config
rules:
- id: ci-agent-primary-route
when:
subjects:
- team:platform
models:
- ci-agent
type: priority-based-routing
load_balance_targets:
- target: anthropic/claude-sonnet
priority: 0
retry_config:
attempts: 3
delay: 200
on_status_codes: ["429", "500", "503"]
fallback_status_codes: ["429", "500", "502", "503"]
- target: anthropic/claude-haiku
priority: 1
retry_config:
attempts: 2
delay: 100
- target: cache/semantic-cache
priority: 2
fallback_candidate: trueA configuração é o artefato. É revisada em pull requests, controlada por versão junto com a implantação do gateway e alterada quando a tolerância da equipe muda (um novo tipo de carga de trabalho com diferentes padrões de pico, um teto de custo mais apertado, uma nova opção de modelo na cadeia de fallback). A equipe da plataforma é responsável pelo esquema; equipes de carga de trabalho individuais podem substituir campos específicos para suas rotas dentro dos limites definidos pela equipe da plataforma.
Cada primitiva no manifesto acima — os baldes de token por identidade, os quatro disjuntores nomeados, a cadeia de fallback declarativa, o alerta em formato acionável — é uma primitiva de gateway da TrueFoundry, e não um middleware personalizado. A equipe da plataforma escolhe a granularidade, define os limites, configura a cadeia; não há middleware de limite de taxa para construir, testar e manter. Equipes que implementaram as mesmas três camadas sobre um gateway sem essas primitivas acabam escrevendo as mesmas centenas de linhas de middleware Lua ou Python, o mesmo armazenamento de baldes com suporte Redis, o mesmo formatador de alerta — e descobrem a maioria dos casos de borda (condições de corrida no reabastecimento de baldes, propagação do estado do disjuntor entre réplicas, ordenação da cadeia de fallback sob interrupções parciais) na terceira ou quarta vez que o descontrole ocorre em produção.
Quatro padrões aparecem regularmente nas primeiras tentativas das equipes de implementar limite de taxa, e cada um produz um modo de falha diferente que vale a pena conhecer.
Erro 1: chave de balde com granularidade muito ampla. Um único balde por usuário significa que um agente descontrolado bloqueia o trabalho de depuração do usuário — incluindo o trabalho que ele precisa para encontrar e corrigir o descontrole. A tupla (usuário, repositório, modelo) geralmente é a granularidade correta; equipes que agregam em um nível superior a este acabam com incidentes operacionalmente dolorosos.
Erro 2: sem cadeia de fallback. Uma carga de trabalho que falha abruptamente a cada 429 produz uma experiência de usuário pior do que o necessário. Mesmo que a equipe não queira um modelo de fallback (preocupações com a qualidade são legítimas), servir uma resposta em cache ou uma mensagem de "temporariamente indisponível" é melhor do que um 5xx que o usuário interpreta como "a IA está quebrada".
Erro 3: acionamento de plantão a cada 429. Os 429 são normais — é o sistema funcionando como projetado. Os acionamentos de plantão devem ocorrer apenas quando o disjuntor desarma, não quando o balde limita. Equipes que acionam o plantão a cada 429 acabam ignorando os alertas (porque a maioria é ruído) ou operando com seus baldes configurados tão altos que o limite não restringe nada.
Erro 4: limites de velocidade de custo definidos como valores monetários estáticos. Um limite estático ("$10/minuto é demais") torna-se obsoleto rapidamente à medida que o tráfego e os preços da equipe mudam. O limite deve ser relativo ao orçamento planejado da carga de trabalho — "10× a taxa planejada" é durável em relação às mudanças de custo; "$10/minuto" é frágil.
A limitação de taxa é uma das poucas mudanças de plataforma em que o risco de implantação é assimétrico: não aplicar é o status quo (com incidentes caros ocasionais), aplicar de forma muito agressiva quebra cargas de trabalho legítimas. A sequência de lançamento deve priorizar a observação primeiro, a aplicação depois.
Semana 1 — Baldes apenas para auditoria, disjuntores apenas para auditoria. Implemente a camada de limitação de taxa com cada limite configurado para "registrar, mas não aplicar". Cada requisição ainda passa; o gateway registra o que teria sido limitado ou o que teria acionado um disjuntor. O painel no final da semana responde às perguntas que a equipe não sabia que precisava: quais cargas de trabalho são intermitentes, quais já exibem assinaturas de loop, quantas requisições/minuto o usuário legítimo mais ocupado realmente produz.
Semana 2 — Habilite apenas o balde de tokens, em uma classe de carga de trabalho. Escolha a classe de maior risco — geralmente pipelines de CI/CD com agentes, onde não há mecanismo de cadência humana. Habilite o balde de tokens com limites definidos para o P99 do tráfego legítimo observado mais uma margem. Monitore por 429s durante a semana. Falsos positivos (cargas de trabalho legítimas atingindo o limite) têm o limite aumentado; na ausência de falsos positivos, a próxima classe de carga de trabalho é habilitada.
Semana 3 — Adicione o disjuntor de custo-velocidade. O disjuntor de custo-velocidade é o que detecta os processos descontrolados lentos que o balde de tokens não consegue. Configure-o para 10x a taxa planejada como padrão; ajuste por carga de trabalho após uma semana de dados de auditoria. Os alertas são configurados, mas roteados apenas para a equipe de plataforma durante a semana 3, não para os plantonistas de produto — o limite ainda está sendo ajustado.
Semana 4 — Outros disjuntores, cadeia de fallback. Adicione o detector de assinatura de loop. Configure cadeias de fallback por rota, em estreita consulta com os proprietários das cargas de trabalho — eles sabem como um estado "degradado" deve ser para o seu caso de uso. O cache semântico é preenchido durante a primeira semana de operação; as taxas de acerto do cache aumentam gradualmente e se estabilizam em torno de 20-40% para a maioria das cargas de trabalho.
Semana 5+ — Estado estável. Os alertas são roteados para o plantonista de produto. O painel de limitação de taxa faz parte da revisão regular da equipe. Novas cargas de trabalho entram por padrão no estado de apenas auditoria e são explicitamente promovidas à aplicação. Os limites são reajustados trimestralmente à medida que os padrões de tráfego mudam; as regras dos disjuntores são estendidas à medida que novos padrões patológicos são descobertos. O sistema funciona como infraestrutura, não como um projeto.
A camada de limitação de taxa é de responsabilidade da equipe de plataforma. Os limites específicos da carga de trabalho são de responsabilidade conjunta com as equipes de carga de trabalho. Definir o limite corretamente é importante porque cada um tem diferentes direitos de decisão e diferentes horizontes de tempo.
A equipe de plataforma é responsável pela arquitetura. Quais disjuntores existem, qual é o formato do alerta, o que o log de auditoria captura, como a configuração é revisada. Estes são estáveis entre as cargas de trabalho; eles mudam raramente. O trabalho da equipe de plataforma é fornecer primitivas, documentá-las e ajustar os padrões.
A equipe de carga de trabalho é responsável pelos parâmetros. O tamanho do bucket para a carga de trabalho deles, a ordem da cadeia de fallback, o limite de velocidade de custo. Estes são específicos da carga de trabalho e mudam à medida que os requisitos da carga de trabalho evoluem. A equipe da plataforma revisa as mudanças (uma carga de trabalho que solicita um bucket enorme gera uma conversa, não uma aprovação automática), mas a equipe da carga de trabalho tem a propriedade operacional.
O plantão é revezado entre plataforma e produto. Chamadas da camada de limitação de taxa vão para uma rotação compartilhada. Engenheiros de plataforma lidam com chamadas onde o problema é a infraestrutura da plataforma (a lógica do disjuntor em si está errada); engenheiros de produto lidam com chamadas onde o problema é a sua carga de trabalho (o descontrole está no código deles). A passagem de bastão é o conteúdo do alerta; se o alerta diz "seu fluxo de trabalho entrou em loop 200 vezes em 5 minutos, aqui está o rastreamento", o engenheiro de produto é o respondedor certo.
O padrão que falha é a plataforma ser proprietária de tudo de ponta a ponta. Engenheiros de plataforma não sabem o que "degradado, mas aceitável" significa para o chatbot de suporte ao cliente; engenheiros de produto não têm visibilidade sobre os sinais de toda a plataforma. A divisão é o que torna o modelo operacional sustentável.
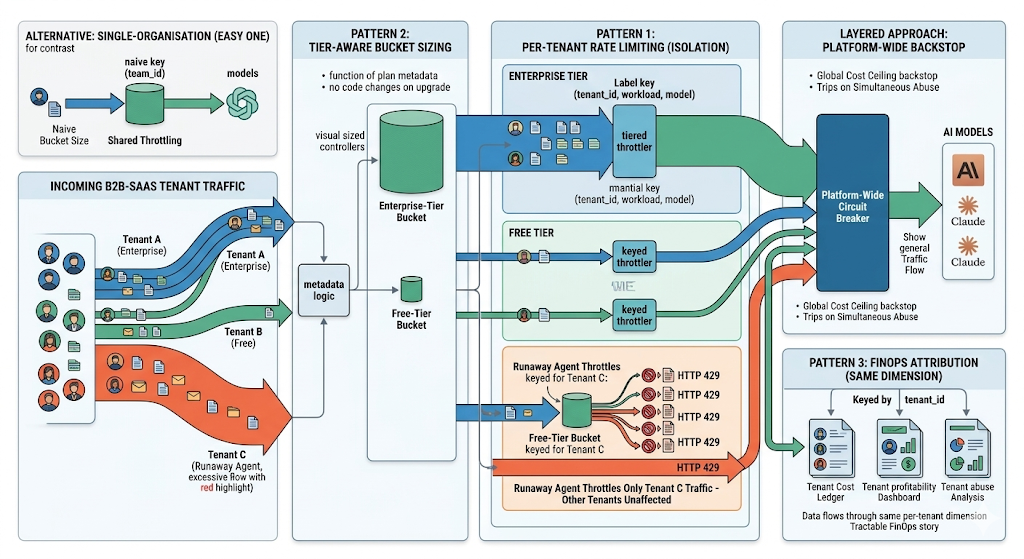
O caso de organização única, onde cada chamador pertence a uma equipe, é o mais fácil. Muitas implantações de IA em produção são multi-inquilino: um produto B2B-SaaS oferece recursos de IA aos seus próprios clientes, cada um dos quais pode produzir tráfego de forma arbitrária. A camada de limitação de taxa precisa isolar os inquilinos uns dos outros e aplicar camadas de preços por inquilino sem alterar a arquitetura.
O padrão que funciona adiciona o inquilino como outra dimensão na chave do bucket. O bucket é chaveado por (inquilino, carga de trabalho, modelo) — o agente descontrolado de um inquilino limita apenas o tráfego desse inquilino; outros inquilinos não são afetados. O teto de custo geral da plataforma fica acima dos tetos por inquilino; um único inquilino que excede seu nível atinge seu bucket primeiro, e o disjuntor de toda a plataforma fornece um suporte para o caso em que vários inquilinos estão se comportando mal simultaneamente.
O dimensionamento de bucket sensível ao nível é o segundo padrão. O cliente do nível gratuito recebe um bucket menor do que o cliente do nível empresarial; os tamanhos dos buckets são derivados do plano do inquilino. Quando um inquilino atualiza os planos, o tamanho do bucket é atualizado sem alterações no código — o nível é metadados na identidade do inquilino, o tamanho do bucket é uma função do nível. Equipes que codificam os tamanhos dos buckets no código da aplicação acabam reescrevendo-os toda vez que os preços mudam; equipes que os derivam dos metadados do inquilino herdam o comportamento correto automaticamente.
O terceiro padrão: a atribuição de custo por inquilino flui através da mesma dimensão. Se o bucket é chaveado por inquilino, o livro-razão de custos é chaveado por inquilino, o log de auditoria é chaveado por inquilino, o painel de limitação de taxa é chaveado por inquilino. A história de FinOps da plataforma (quais inquilinos são os mais caros, quais são lucrativos, quais estão abusando do sistema) torna-se rastreável a partir dos mesmos dados que a camada de limitação de taxa já estava produzindo.
Comece pela forma natural do tráfego — observe o pico P99 para a carga de trabalho no mês anterior e dimensione o bucket aproximadamente lá. Ajuste com base na taxa de falsos positivos (cargas de trabalho legítimas reclamando de 429s) e na taxa de disparo do disjuntor (descontrole escapando do bucket). O bucket é um parâmetro por carga de trabalho; um tamanho não serve para todos.
Não — eles se complementam. Os limites do provedor são absolutos; os limites do gateway são por identidade e mais granulares. O limite do provedor pode dizer "100.000 requisições/minuto em toda a organização"; o limite do gateway diz "100 requisições/minuto para este pipeline de CI". Ambos se aplicam; o limite do gateway geralmente será acionado primeiro para cargas de trabalho individuais.
Configure um bucket maior para essa carga de trabalho. Uma carga de trabalho que se sabe precisar de 1.000 rpm recebe um bucket dimensionado de acordo; o limite é por carga de trabalho, não para toda a plataforma. A disciplina é revisar o bucket maior com a equipe da plataforma antes de concedê-lo, não conceder capacidade ilimitada por padrão.
Sim. Uma resposta de streaming que dura dois minutos consome um token de bucket no momento da requisição, mas gera um custo significativo durante a duração do stream. O disjuntor de velocidade de custo lida com este caso; a camada de bucket de tokens é aumentada com um monitor de custo de streaming que pode cancelar o stream se a velocidade de custo exceder o limite no meio do stream.
Sim — o disjuntor de custo-velocidade inclui "detecção de picos": uma única requisição cujo custo excede N vezes o custo médio da carga de trabalho (tipicamente 50× ou 100×) dispara o disjuntor, mesmo que nenhum padrão de taxa seja visível. Isso detecta o caso em que um agente envia uma requisição com estouro de contexto que custa $50 em vez dos usuais $0.05.
Implemente primeiro no modo somente auditoria — o disjuntor calcula se teria disparado, mas não bloqueia de fato. Após uma semana, a equipe terá uma distribuição real: quais cargas de trabalho teriam disparado, com que frequência e em que condições. Ajuste os limites com base nos dados somente de auditoria e, em seguida, habilite a aplicação. A semana de somente auditoria é um seguro barato contra falsos positivos.
Não — a cadeia de fallback assume o controle. Se a cadeia de fallback se esgotar, o aplicativo recebe um HTTP 503 limpo com um corpo de erro estruturado que pode exibir para o usuário. Falhas não ocorrem no gateway; elas acontecem em código de aplicação mal gerenciado que não sabe o que fazer com um 503. A solução é o tratamento de erros no lado da aplicação, não alterações no gateway.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




