



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
Embora o desenvolvimento de modelos tenha se tornado mais simplificado, a implantação, escalonamento e gerenciamento de modelos de ML em produção continuam sendo um grande obstáculo. As equipes de plataforma são responsáveis por garantir que os modelos de ML possam ser implantados, monitorados, escalonados e otimizados sem problemas em vários ambientes, tudo isso enquanto minimizam os custos de infraestrutura e mantêm a confiabilidade.
As abordagens tradicionais de implantação de ML frequentemente exigem vasta experiência em Kubernetes, gerenciamento manual de recursos de GPU e mecanismos de escalonamento ineficientes, resultando em alta sobrecarga operacional para as equipes de plataforma. Em resposta a esses desafios, a TrueFoundry oferece uma solução de Implantação de ML como Serviço, projetada para automatizar a seleção de infraestrutura, simplificar a implantação, otimizar o desempenho e aprimorar a observabilidade.
A implantação de modelos de ML exige a seleção das instâncias de GPU, servidores de modelo e configurações de Kubernetes corretos. Sem automação inteligente, as equipes de plataforma precisam alocar recursos manualmente, o que leva a implantações propensas a erros e demoradas.
O processo atual frequentemente envolve múltiplas transferências entre cientistas de dados, engenheiros de ML e equipes de DevOps. Engenheiros de plataforma intervêm com frequência para auxiliar com configurações de Kubernetes, escalonamento e monitoramento — criando ineficiências e gargalos.
As implantações tradicionais de ML carecem de mecanismos de autoescalonamento de GPU integrados. Sem escalonamento dinâmico baseado em Requisições Por Segundo (RPS), utilização ou gatilhos baseados em tempo, a infraestrutura é subutilizada (levando a gastos desnecessários) ou superprovisionada (causando gargalos de desempenho).
Escolher a abordagem mais eficiente de serviço de modelo , juntamente com o servidor de modelo correto (por exemplo, vLLM, SGlang, Triton, FastAPI, TensorFlow Serving), exige profunda experiência em benchmarking de desempenho, otimização de memória e balanceamento de carga.
As implantações de ML geram logs, métricas e eventos em múltiplas plataformas. A resolução de problemas de desempenho ou falhas é tediosa, pois os logs estão frequentemente dispersos, dificultando que as equipes de plataforma identifiquem e resolvam problemas rapidamente.
Sem otimização automatizada de recursos, as equipes de plataforma devem monitorar e gerenciar manualmente modelos ociosos, levando a despesas desnecessárias na nuvem. Os métodos tradicionais de implantação de ML não suportam desligamento automático ou escalonamento dinâmico.
Empresas exigem atualizações de modelo com zero tempo de inatividade, mas os métodos tradicionais carecem de atualizações contínuas (rolling updates), lançamentos canary (canary releases) e implantações blue-green (blue-green deployments). Isso aumenta o risco de interrupções de serviço ao implantar novas versões de modelo.
A TrueFoundry elimina esses desafios ao fornecer uma plataforma de implantação de ML totalmente gerenciada, possibilitando implantações self-service, seleção inteligente de recursos, otimização de custos e observabilidade aprimorada. Veja como:
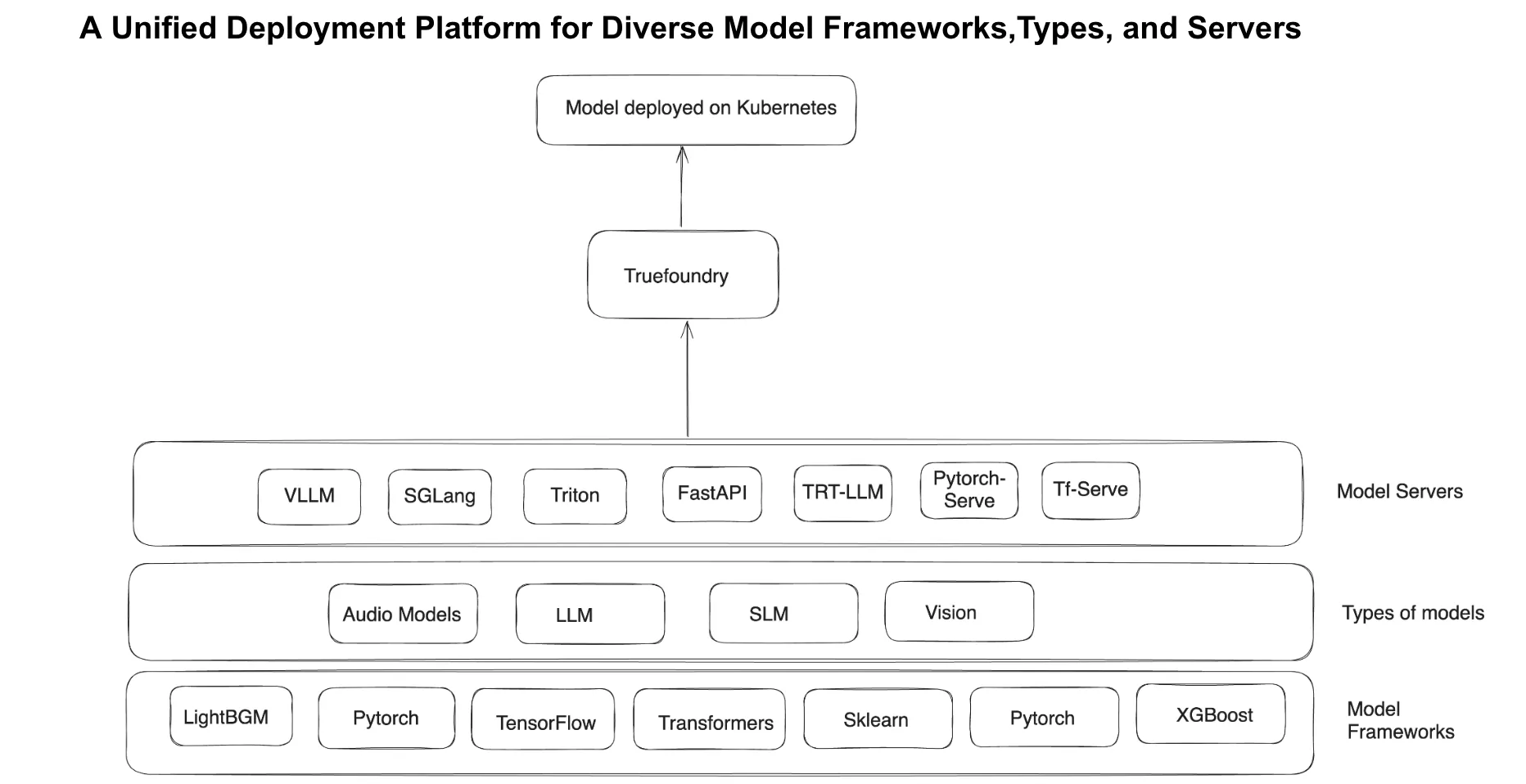
A TrueFoundry permite que as equipes de plataforma implantem modelos de ML com um único clique, eliminando a necessidade de conhecimento em Kubernetes. A plataforma seleciona de forma inteligente as melhores configurações de infraestrutura, escolhendo os tipos de instância de GPU ideais, servidores de modelo e estratégias de escalonamento com base nos requisitos da carga de trabalho.
Além disso, a integração GitOps garante que todas as implantações sejam automatizadas e reproduzíveis, com geração de YAML integrada para fluxos de trabalho CI/CD simplificados. Ao abstrair as complexidades da infraestrutura, a TrueFoundry capacita cientistas de dados e engenheiros de ML a implantar modelos de forma independente, reduzindo a carga operacional sobre as equipes de plataforma.
O autoescalonamento avançado baseado em GPU da TrueFoundry ajusta dinamicamente os recursos com base na demanda em tempo real. Os modelos escalam para cima e para baixo com base em RPS, utilização de GPU ou gatilhos agendados, garantindo desempenho ideal e eficiência de custos. A plataforma também oferece:
Além disso, a TrueFoundry suporta estratégias de implantação avançadas, incluindo atualizações contínuas (rolling updates), lançamentos canary (canary releases) e implantações blue-green (blue-green deployments), permitindo que as equipes de plataforma lancem novas versões de modelo com zero tempo de inatividade.
A TrueFoundry oferece observabilidade centralizada, disponibilizando logs, métricas e eventos em um só lugar, melhorando significativamente a eficiência da solução de problemas. Este painel unificado ajuda as equipes de plataforma a:
O roteamento persistente (sticky routing) para LLMs aumenta ainda mais o throughput em 50%, garantindo um tratamento eficiente de solicitações, enquanto o suporte a catálogo de modelos (currently integrated with Hugging Face) oferece uma maneira fácil de gerenciar versões e registros de modelos.
Além disso, as sugestões automatizadas de infraestrutura da TrueFoundry otimizam as configurações de CPU, memória e autoescalonamento com base nos padrões de tráfego, simplificando ainda mais o gerenciamento de implantação.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




